1,redis的复制是什么
对于redis来说,单机的布置是当然不够的,这时候就需要多个redis节点,当有多个节点的时候,就要确定谁是主机,谁是从机,还有数据的一致性问题。为了维护数据的一致性问题,从机就要从主机复制数据,要使两台机器的数据处于同一个阶段,这就是redis的复制。在执行slaveof(现在采用replicaof)命令后就会进行复制。
从机A的Ip地址:端口号 slaveof 主机B的ip地址:端口号
2,旧版redis的复制功能
redis的复制功能是分为两个部分,一个是同步操作,一个是命令传播机制。
同步
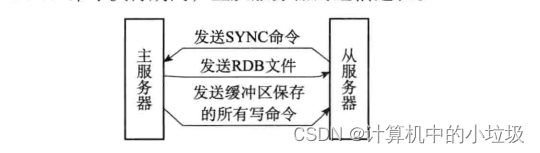
从服务器向主机发送同步的操作是需要使用SYNC命令来完成的。其步骤如下:
1)从机向主机发送SYNC命令。
2)收到SYNC命令后的主机执行bgsave命令,创建一个子进程,子进程创
建一个RDB文件,把当前主机的状态保存到文件中。同时还创建一个缓冲
区,记录在生成RDB文件的时候所记录的写命令。
3)主机RDB文件生成后。把RDB文件发送给从服务器,从机载入这个文件。
4)把缓冲区的命令也发送个从机。
命令传播
在进行同步过后,主机有写入的操作,这时候就会使得数据不一致。这个时候就采用命令传播,把主机执行过的命令再次发送给从机。
旧版本复制得缺点
复制分为两种,
- 初次复制,从机从0开始复制
- 断线后复制,在初次复制得时候,断线了,然后连接上了,重新复制,所以要重新进行一次全局复制,效率低
SYNC是一个非常消耗资源的操作
1),在主机生成RDB文件得时候,会大量得消耗CPU,IO,内存等资源。
2),当发送RDB文件得时候,会消耗大量得网络资源,带宽等。
3),当从服务器接收到RDB文件进行读取得时候,主线程会被阻塞。
3,新版的复制
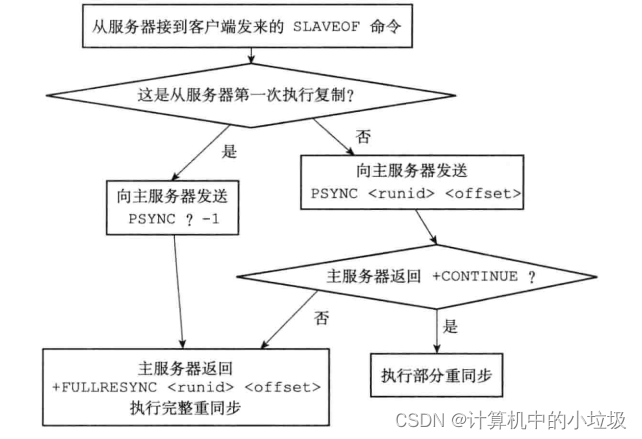
对于新版复制,redis采用得是PSYNC操作
PSYNC分为完整重同步,和部分完整重同步。在初次复制得时候,采用的是完整,这和SYNC是没有区别得。在断线复制时采用得时部分重新同步,就是接着上次断线的地方继续复制,不需要重新来一遍。
部分完整重同步的实现
由以下三部分构成:
1)主从两机的复制偏移量
2)主机的复制积压缓存区
3)服务器的运行ID
复制偏移量
当进行复制的时候,主从两机都会维持一个复制偏移量offset
当主机向从机传播N个字节的数据的时候,就会在偏移量上加上N,
当从机接收N个字节数据的时候,就会在从机的偏移量上加上N。
所以判定两个数据是否一致的时候,就可以比较偏移量的大小是否相同
复制积压缓冲区
复制积压缓冲区是主机维护的一个固定大小的队列(默认是1M),这个队列中存储的是最近这1m主机发送的数据,当然这个大小你是可以设置的,设置的太小,没什么用,设置太大,浪费内存。

这个队列中维护着发送的字节值,每个字节值对应着主机上的复制偏移量。
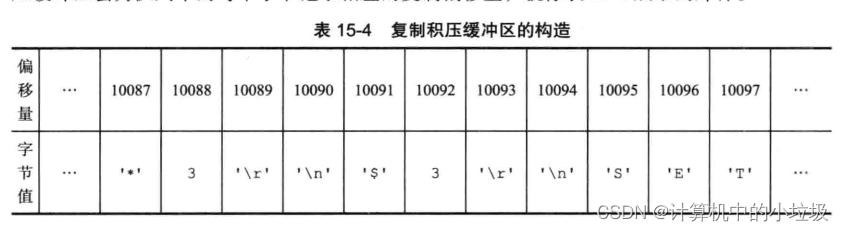 当出现断线重连后,会进行判断:
当出现断线重连后,会进行判断:
- 如果从机的offset在这个队列中,那么就执行部分重同步操作。
- 如果在的话,就进行全部重同步操作。
运行ID
每个redis服务器都会有自己对应的一个40位随机组成的16进制组成的字符id。当进行初次复制的时候,主机会把自己的id发送给从机,当断线重连后,从机会验证主机的id,如果两次id是一样的,执行上述操作,如果两个id不一样,就执行完整重同步
执行PSYNS的完整步骤