1.概述
HBase是Hadoop数据库,一种分布式、可扩展的大数据存储。当您需要对大数据进行随机、实时的读/写访问时,推荐使用HBase。该项目的目标是在商用硬件集群上托管非常大的表――数十亿行 X 数百万列。HBase 是一个开源、分布式、版本化、非关系型数据库,基于 Google 的Bigtable 等的结构化数据的分布式存储系统开发。正如 Bigtable 利用 Google 文件系统提供的分布式数据存储一样, HBase 在 Hadoop 和 HDFS 之上提供了类似 Bigtable 的功能。
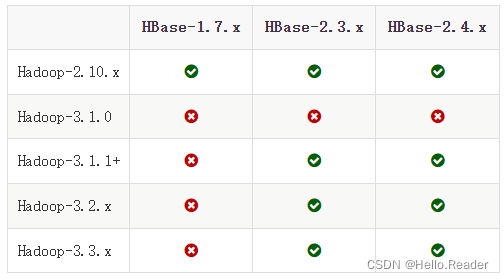
2.匹配版本
此处匹配版本示意图是搬运官网图片,我这里使用的是Hadoop3.2.3+Hbase3.0.0.alpha版本
3.环境配置
环境准备3台Ubuntu服务器,我使用的是ubutun22版本,配置虚拟机,如果是云服务器可以直接进行忽略。
3.1配置服务器节点
创建新虚拟机
选择自定义高级,点击下一步
选择虚拟机硬件功能,一般默认就行,然后点击下一步
点击下一步,选择稍后安装操作系统,此处的iso文件可以忽略,因为笔者之前安装过,初次是没有默认路径的。

选择客户机操作系统,本次是linux――ubuntu64位,点击下一步

点击下一步,进入命名虚拟机页面,修改主机名,并且选择安装目录,此处我们选择的是D盘,用户可以根据自己的盘符情况进行选择
点击下一步,进入处理器配置页面,这里默认就行,可以根据自己的机器进行调配。
点击下一步,进入内存分配页面,这里用户可以自行调节,一般默认就行。
点击下一步,进入网络类型选择页面,这里可以根据自己的情况进行配置,笔者这里选择了默认配置
点击下一步,进入选择I/O控制器类型页面,这里可以根据自己需求进行配置,笔者选择默认推荐。
点击下一步,进入硬盘选择页面,这里笔者选择默认SCSI,当然用户可以根据自己的需求进行配置
点击下一步,进入选择磁盘页面,创建新虚拟磁盘。
点击下一步,进入指定磁盘容量页面,自己可以根据自己的磁盘大小进行调节。笔者这里使用的50GB,将虚拟磁盘拆分成多个文件。
点击下一步,进入指定磁盘文件目录
点击下一步,进入已创建好虚拟机页面
点击完成,完成虚拟机创建
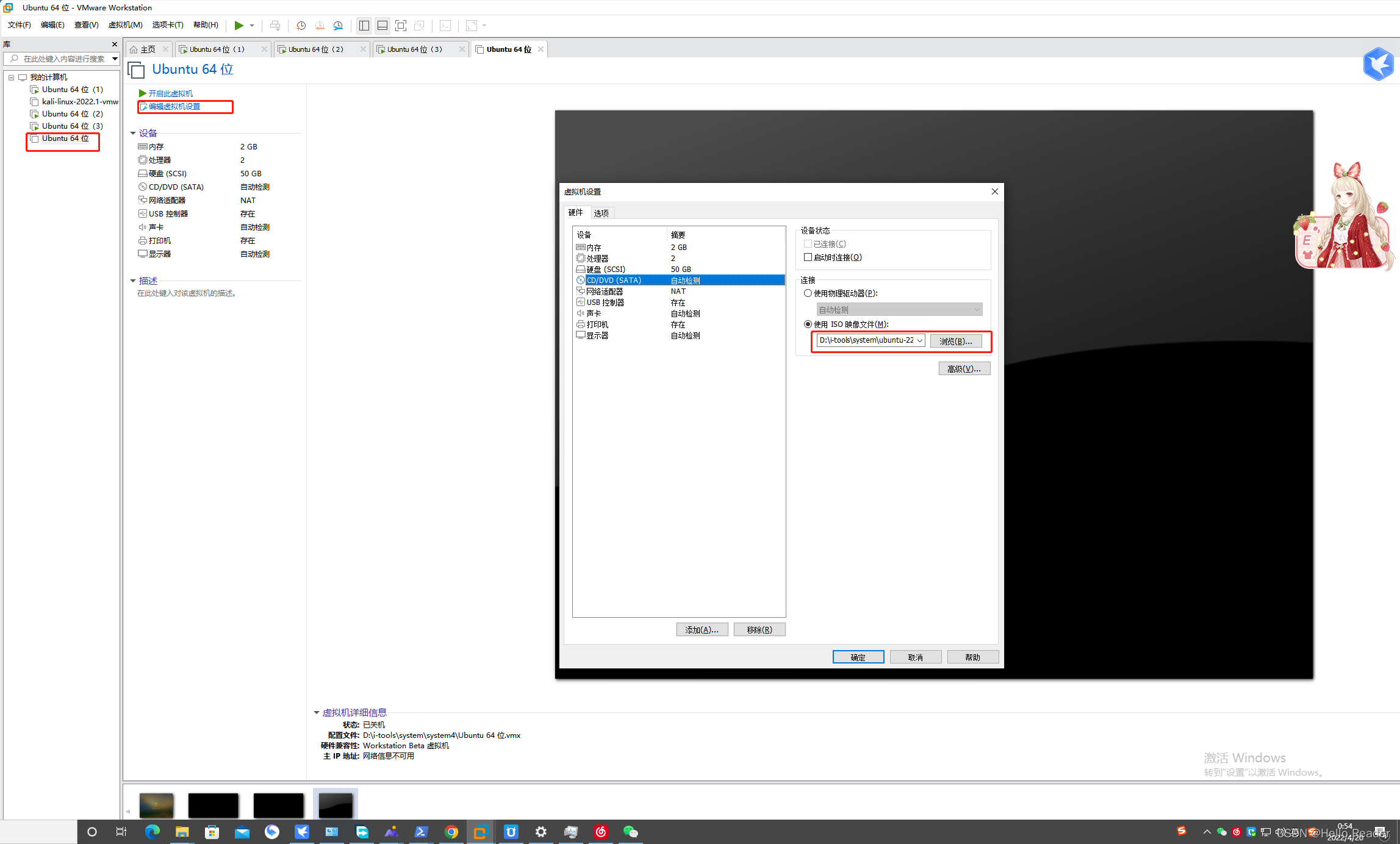
点击编辑虚拟机,配置系统镜像文件进行启动iso。点击确定完成配置
当启动出现如下图,情况时候别慌。
配置连接状吗,确定保存重启。
进入选择安装页面,如下图所示。不同版本的ubuntu界面可能会有差异过没事。根据具体选项进行配置即可。
选择OEM Install(for manufacturers),根据提示进行操作系统安装即可。安装成功后进行克隆系统,此处的Ubuntu64位(2)、(3)由(1)克隆而生成。,克隆步骤如下
点击下一步,进入克隆源页面
点击下一步,进入克隆虚拟向导页面,选择创建完整克隆。
点击下一步,设置新克隆虚拟名称及系统位置,点击完成即可。这里不进行创建。因为笔者的机器限制。后面讲解用ubuntu64位(1),(2),(3)进行讲解
3.2上传需要安装的文件
使用xshell、MobaXterm、VMwareTools上传附件进行测试,笔者这里使用的是Mobaxtem。此处安装步骤省略。
1.选择SSH进行连接
2.连接服务器上传文件
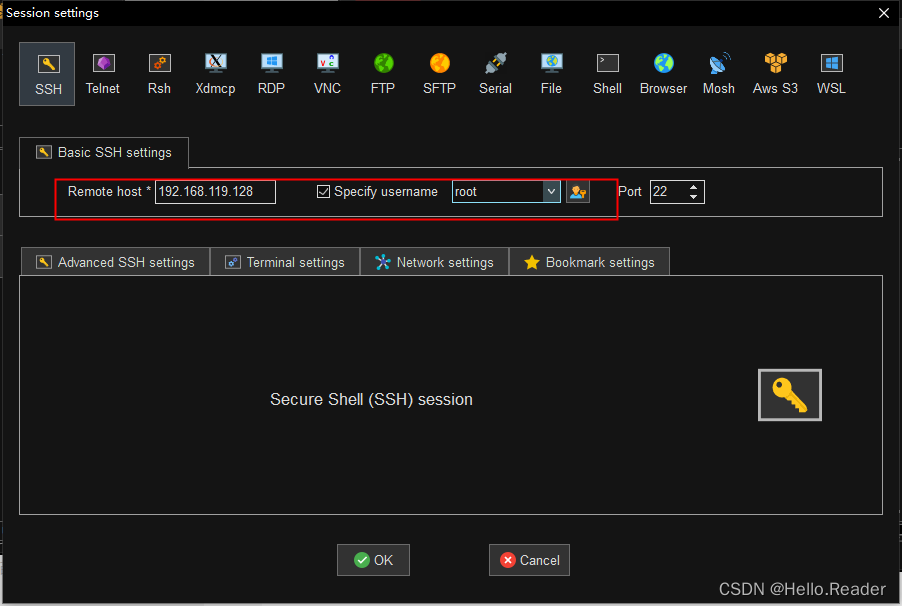
输入密码,连接成功
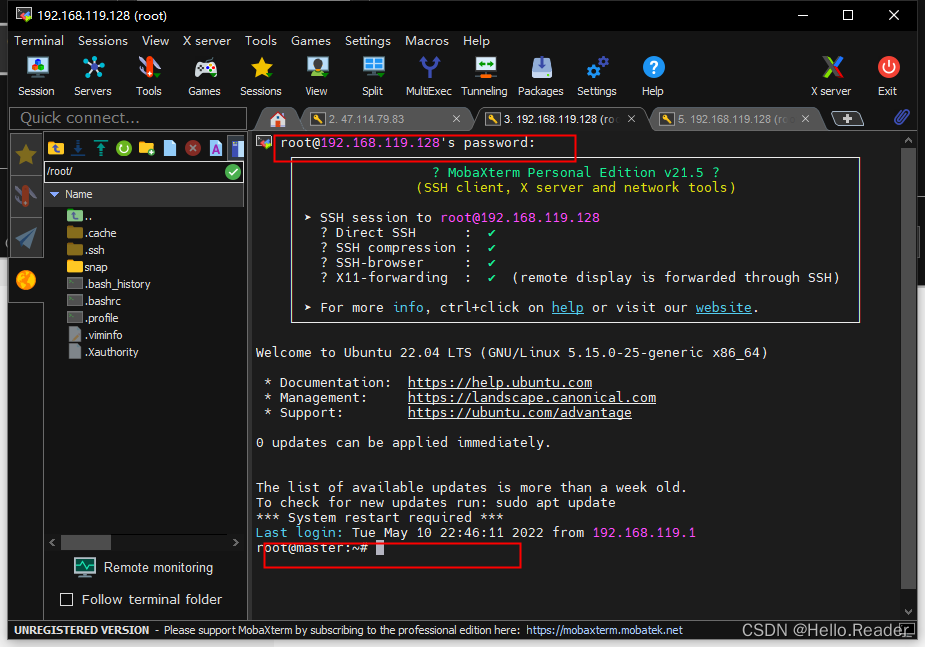
使用sudo hostnamectl set-hostname master修改hostanem名称,此处系统已经修改过,修改后重启即可**(Ubuntu系统)**;修改后如上图所示。
3.3 hosts文件配置
vi /etc/hosts
再输入,对每台服务器都进行配置
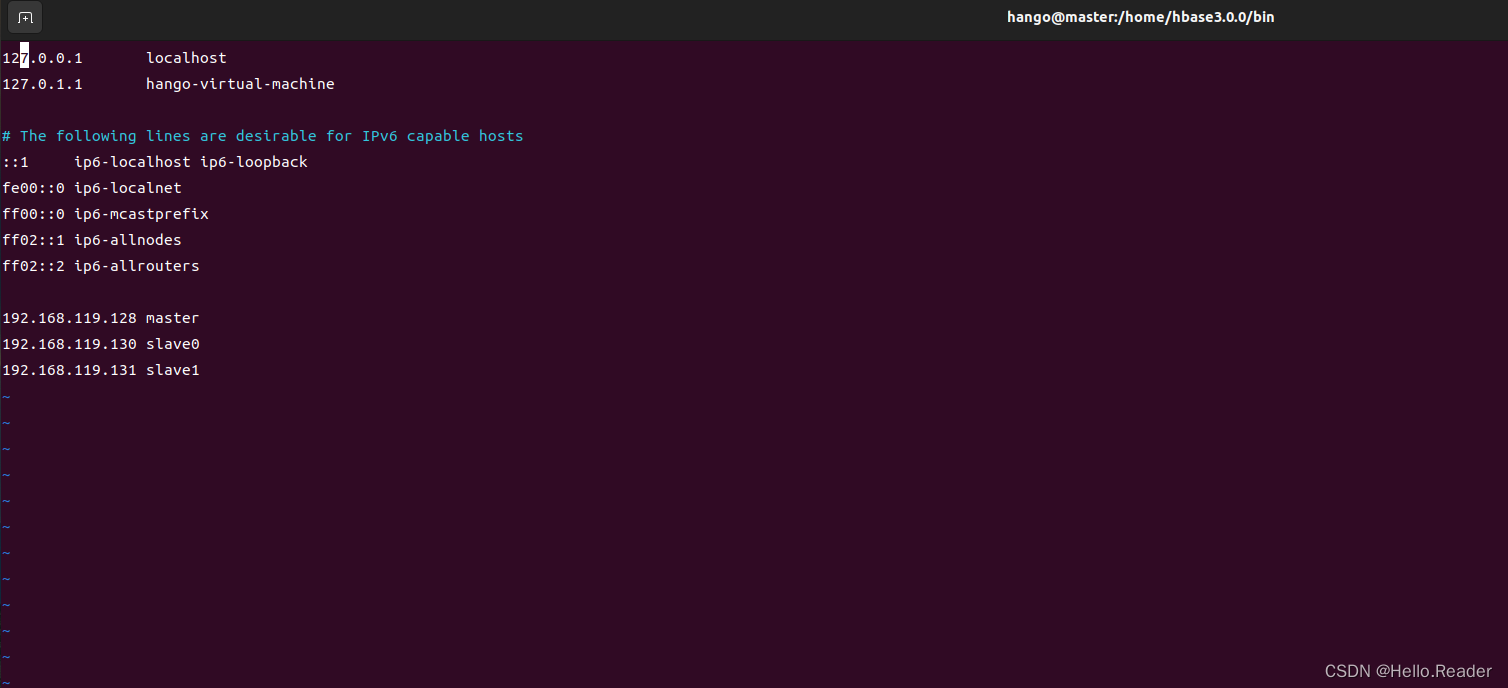
3.4免密钥登录配置
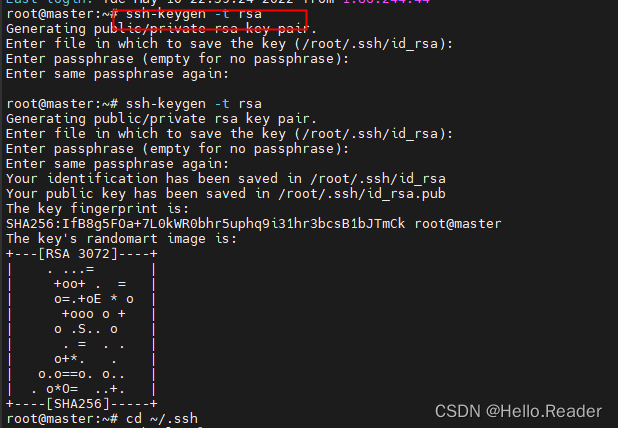
首先在master服务器输入下面命令
ssh-keygen -t rsa
然后按四次回车,出现下面内容
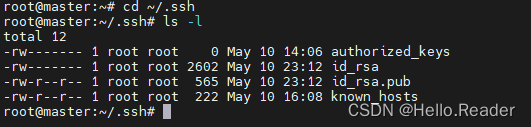
然后输入下面命令进入ssh文件夹
cd ~/.ssh
输入下面命令可以看文件夹里面的内容
ls -l
然后输入下面命令把公钥文件发送到自己和其它服务器
发送给自己,如下图所示表示成功,使用如下命令
ssh-copy-id -i id_rsa.pub root@master

然后再分别发送给slave0和slave1
root@master:~/.ssh# ssh-copy-id -i id_rsa.pub root@slave0
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "id_rsa.pub"
The authenticity of host 'slave0 (192.168.119.130)' can't be established.
ECDSA key fingerprint is SHA256:IwMb7VSNk/mF8A3WL7JWsIDefYHy4Iwg3zFom2bOIUY.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave0's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@slave0'"
and check to make sure that only the key(s) you wanted were added.
root@master:~/.ssh# ssh-copy-id -i id_rsa.pub root@slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "id_rsa.pub"
The authenticity of host 'slave1 (192.168.119.131)' can't be established.
ECDSA key fingerprint is SHA256:iXJ6OqjtR2laaIXCW+O7lUsqSOW1LAWKDcVdTEAclYY.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@slave1'"
and check to make sure that only the key(s) you wanted were added.
验证是否成功
在master服务器输入下面的命令,都不需要输入密码,就说明成功了,注意每执行完一条命令都用exit退出一下再执行下一条
ssh master
ssh slave0
ssh slave1
root@master:~/.ssh# ^C
root@master:~/.ssh# ssh master
Welcome to Ubuntu 20.04.4 LTS (GNU/Linux 5.4.0-108-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Welcome to Alibaba Cloud Elastic Compute Service !
Last login: Tue May 10 23:30:09 2022 from 192.168.119.1
root@master:~# ^C
root@master:~# ssh slave0
Welcome to Ubuntu 20.04.4 LTS (GNU/Linux 5.4.0-108-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Welcome to Alibaba Cloud Elastic Compute Service !
Last login: Tue May 10 23:26:47 2022 from 192.168.119.1
root@slave0:~# exit
logout
Connection to slave0 closed.
root@master:~# ssh slave1
Welcome to Ubuntu 20.04.4 LTS (GNU/Linux 5.4.0-108-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Welcome to Alibaba Cloud Elastic Compute Service !
Last login: Tue May 10 23:28:40 2022 from 192.168.119.1
root@slave1:~# exit
logout
Connection to slave1 closed.
4.安装JDK
.先下载jdk压缩包上传至服务器(xftp、winscp、MobaXterm)
Ubuntu JDK安装(本人博客)
压缩包自行去官网进行下载,此处演示版本为jdk1.8
4.1.解压jdk压缩包
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/local/jdk1.8
注:如果提升没用目录则进行创建目录,命令如下
mkdir /usr/local/jdk1.8
4.2 编辑/etc/profile,命令如下:
vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.8/jdk1.8.0_131 #jdk安装目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
source /etc/profile #(重新加载环境)
输入java、javac和java -version验证,如果都出现一大堆代码说明配置成功了,如果其中有一个或多个出现不是内部或外部命令,也不是可运行的程序或批处理文件等类似语句,就说明配置失败了,需要重新配置jdk环境

这样就安装好master服务器的jdk了,但是还没有安装好slave0和slave1的jdk,我们可以用下面命令把master中的jdk复制到slave0上面
scp -r /usr/local/jdk1.8 root@slave0:/usr/local
这时已经把jdk复制到slave0了,但是slave0的环境变量还没有配置,我们同样可以使用下面命令来复制环境变量
scp -r /etc/profile root@slave0:/etc/profile
然后在slave0中输入下面内容使环境变量生效
source /etc/profile
java -version
验证下,这样 slave0中的jdk就安装成功了,slave1,与slave0类似,这里不做演示
5.hadoop安装与环境配置
先用下面的命令给data文件夹中新建一个hadoop文件夹
mkdir /data/hadoop
把hadoop-3.3.1.tar.gz 复制到hadoop文件夹(从左边本地拖过去即可)
使用下面命令进入到hadoop文件夹
cd /data/hadoop
使用下面命令把hadoop-3.3.1.tar.gz 进行解压
tar -zxvf hadoop-3.3.1.tar.gz
使用下面命令把hadoop-3.3.1文件夹重命名成hadoop
mv hadoop-3.3.1 hadoop
5.1.配置hadoop-env.sh
该文件设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前执行的环境当成远程服务器。所以这里设置的目的是确保Hadoop能正确的找到jdk。
先用cd回到主目录

然后输入下面命令进入该文件所在的文件夹
cd /data/hadoop/hadoop/etc/hadoop

用ls就可以看到该文件

然后输入下面命令打开该文件
vi hadoop-env.sh
然后修改成下面的内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_162/
5.2配置core-site.xml
先用下面的命令给data文件夹中hadoop下新建一个hadoopdata文件夹
mkdir /data/hadoop/hadoopdata
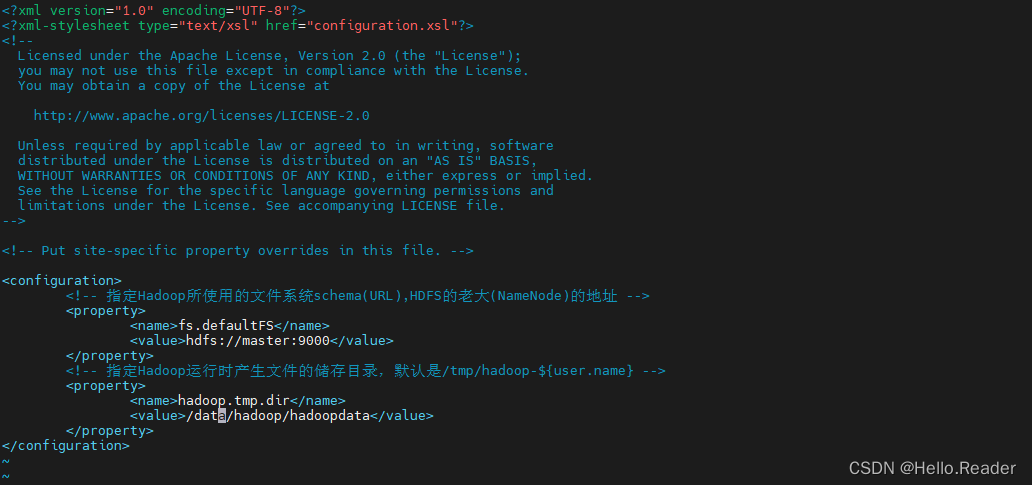
core-site.xm所在的目录和上面的目录一样,所以直接使用下面命令打开该文件即可
<!-- 指定Hadoop所使用的文件系统schema(URL),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的储存目录,默认是/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/hadoopdata</value>
</property>
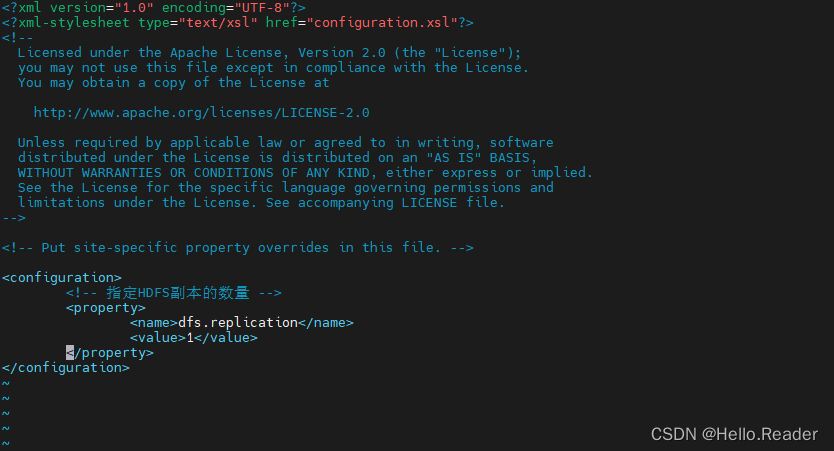
5.3配置hdfs-site.xml
hdfs-site.xml所在的目录和上面的目录一样,所以直接使用下面命令打开该文件即可
vi hdfs-site.xml
接着把下面命令写入中,注释不用写
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
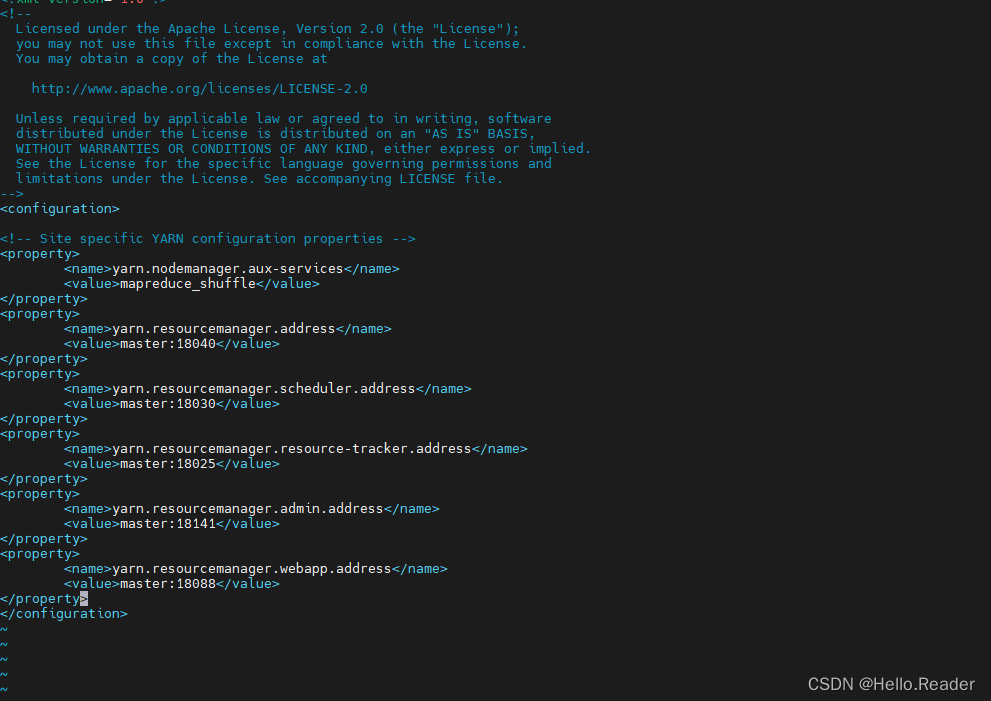
5.4配置yarn-site.xml
yarn-site.xml所在的目录和上面的目录一样,所以直接使用下面命令打开该文件即可
vi yarn-site.xml
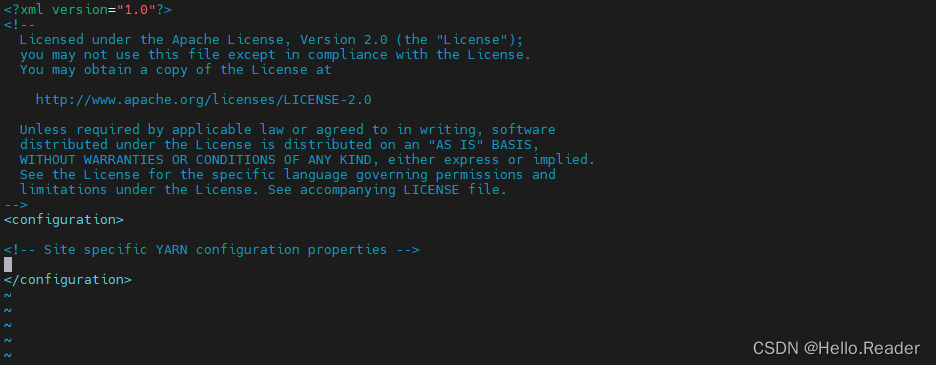
接着把下面命令写入中,里面自带的注释不用删除
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
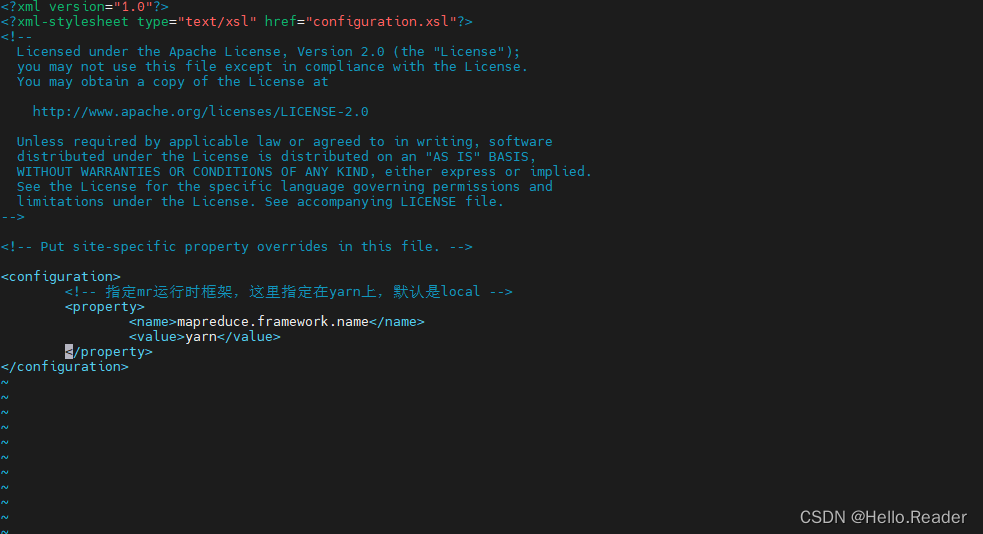
5.5配置 mapred-site.xml
使用下面命令打开该文件
vi mapred-site.xml
接着把下面命令写入中,注释不用写
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5.6配置Slaves(3.0以上变为workers)
slaves文件给出了Hadoop集群的Slave节点列表。改文件十分重要,因为启动Hadoop的时候,系统总是根据当前slaves文件中Slave节点名称列表启动集群,不在列表中的Slave节点便不会被视为计算节点
wrkers(3.0以上)所在的目录和上面的目录一样,所以直接使用下面命令打开该文件即可
vi workers(slaves)
把下面代码写进去(删掉localhost)
master
slave0
slave1
5.7配置Hadoop环境变量
先用cd命令回到总目录

输入下面命令开始配置
vim /etc/profile
把下面命令输入进去
export HADOOP_HOME=/data/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
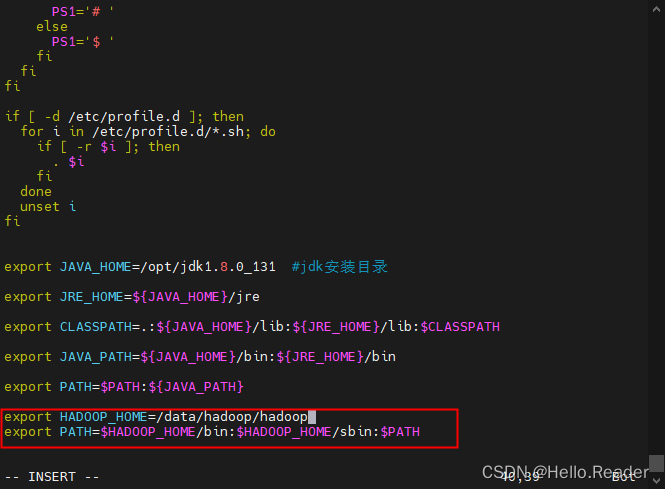
然后保存退出输入下面内容使环境变量生效
source /etc/profile
5.8给slave0和slave1复制Hadoop
用下面命令就可以把master的Hadoop复制到slave0上
scp -r /data/hadoop root@slave0:/data
用下面命令把master的Hadoop复制到slave1上
scp -r /data/hadoop root@slave1:/data
接着用下面命令把master的环境变量复制到slave0上
scp -r /etc/profile root@slave0:/etc/profile
然后在slave0中输入下面内容使环境变量生效
source /etc/profile
slave1与slave0类似,这里不做演示
5.9格式化文件系统
在master中输入下面命令格式化文件系统,其余俩台服务器不用,注意该命令只能使用一次
cd /data/hadoop/hadoop/bin
hadoop namenode -format
5.10启动Hadoop
在master服务器上,先用下面命令进入Hadoop的sbin目录
cd /data/hadoop/hadoop/sbin
然后输入下面命令启动
start-all.sh
报错解决办法:
进入sbin目录
cd /data/hadoop/hadoop/sbin
在里面修改四个文件
vi start-dfs.sh
vi stop-dfs.sh
vi start-yarn.sh
vi stop-yarn.sh
注意是在文件开始空白处
对于start-dfs.sh和stop-dfs.sh中:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
这样就解决了
解决后重新启动,各个结点显示如下信息
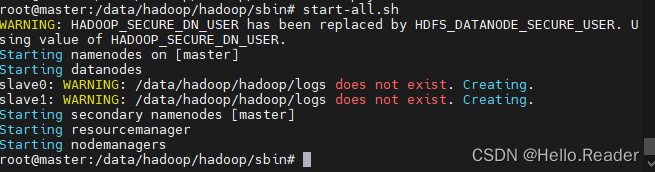
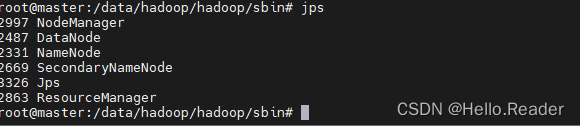
在浏览器中输入
localhost:9870

6.Hbase安装与配置
master节点
新建hbase文件夹
mkdir /data/hbase
把hbase-3.0.0-alpha-2-bin.tar.gz复制到hbase文件夹(home文件夹,提前已经用Xft上传)
使用下面命令进入到hbase文件夹
cd /data/hbase
使用下面命令把hbase-3.0.0-alpha-2-bin.tar.gz进行解压
tar -zxvf hbase-3.0.0-alpha-2-bin.tar.gz
重命名文件夹
mv hbase-3.0.0-alpha-2 hbase

6.1配置环境变量
在/etc/profile文件中配合环境变量,命令如下
vim /etc/profile
#添加下面两个参数
export HBASE_HOME=/data/hbase/hbase
export PATH=$HBASE_HOME/bin:$PATH
配置生效
source /etc/profile
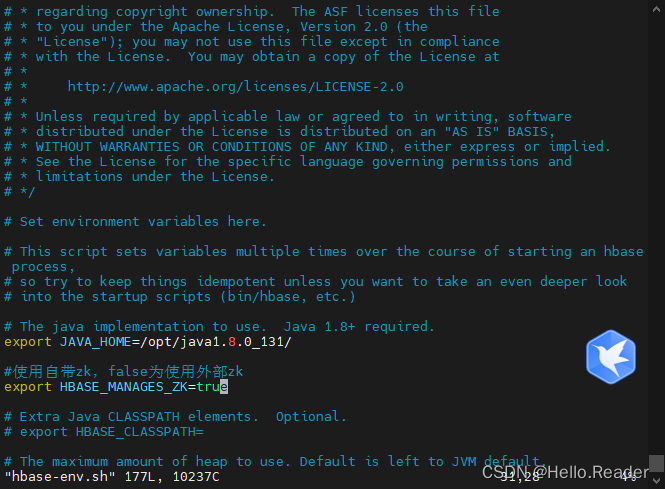
6.2配置hbase-env.sh
cd /data/hbase/hbase/conf
vim hbase-env.sh
然后修改成下面的内容
export JAVA_HOME=/opt/jdk1.8.0_131/
#使用自带zk,false为使用外部zk
export HBASE_MANAGES_ZK=true
6.3配置hbase-site.xml
新建hbase及zookeeper数据文件夹
cd /data/hbase
mkdir hbasedata
cd hbasedata
mkdir zookeeper
{$HBASE_HOME}/conf/hbase-site.xml
cd /data/hbase/hbase/conf
vi hbase-site.xml
<!--将本地文件系统更改为HDFS实例的地址,即hbase产生的数据将位于hdfs集群上 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<!--hbase依赖于zookeeper,指定zookeeper产生的数据位置 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/hbase/hbasedata/zookeeper</value>
</property>
<property>
<name>hbase.master</name>
<value>master</value>
</property>
<!--该属性默认为true -->
<!--指示HBase以分布式模式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指示使用zk的主机地址,奇数个 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave0,slave1</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
6.3配置regionservers
修改{$HBASE_HOME}/conf/regionservers,原文件内容为localhost
vi regionservers
slave0
slave1
6.3 配置高可用备份master(可以不配)
在conf下创建backup-masters文件并添加备用master节点信息
slave0
6.4 配置zookeeper服务所在的节点,在hbase-site.xml下添加
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave0,slave1</value>
</property>
6.4 给slave0和slave1复制Hbase
用下面命令就可以把master的Hbase复制到slave0上
scp -r /data/hbase root@slave0:/data
用下面命令就可以把master的Hbase复制到slave1上
scp -r /data/hbase root@slave1:/data
接着用下面命令把master的环境变量复制到slave0上
scp -r /etc/profile root@slave0:/etc
然后在slave0中输入下面内容使环境变量生效
source /etc/profile
slave1与slave0类似,这里不做演示
6.4 启动Hbase
先启动hdfs
sh /data/hadoop/hadoop/sbin/start-dfs.sh
再启动Hbase
cd /data/hbase/hbase/bin
start-hbase.sh
访问web页面
127.0.0.1:16010(master:16010也可)
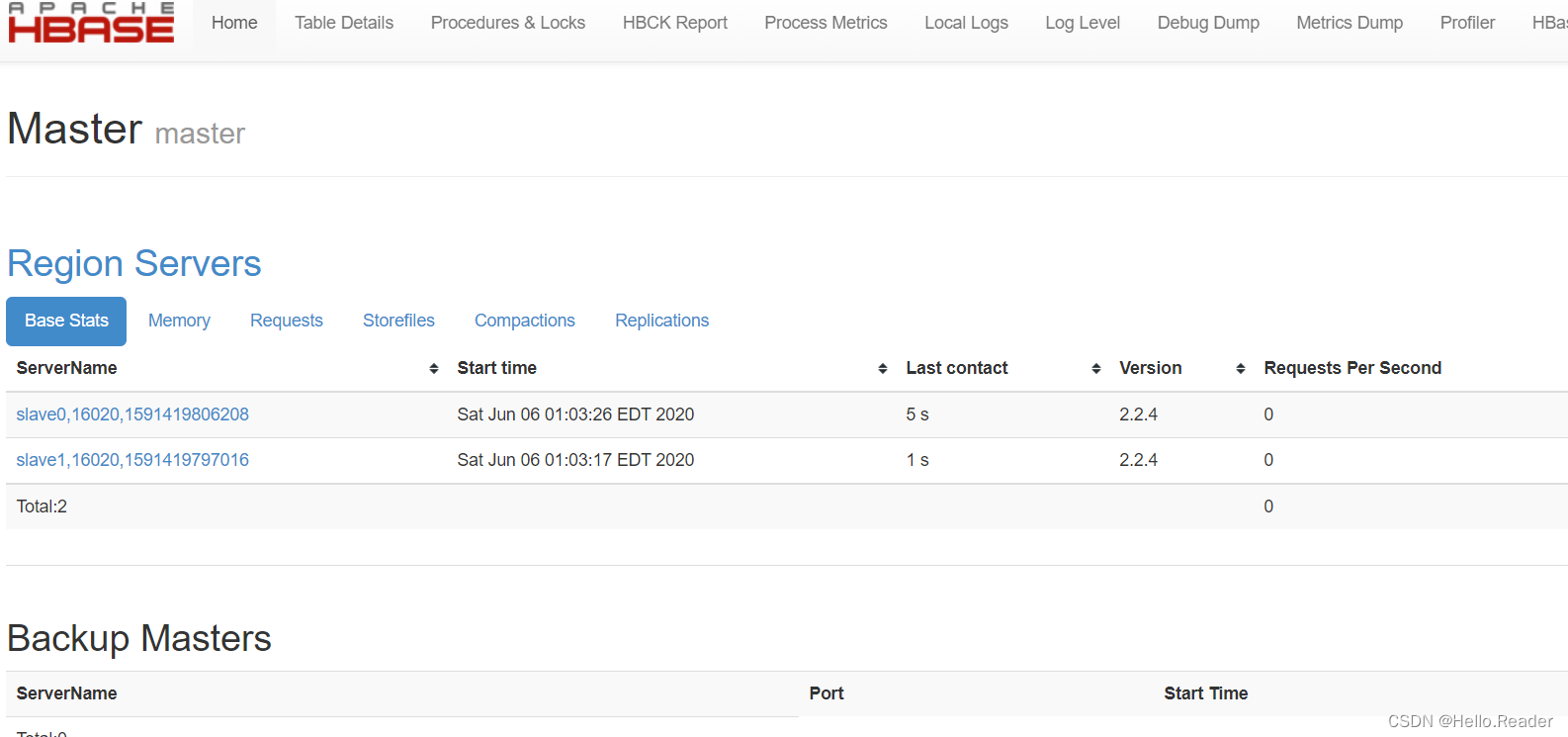
大功告成!!!
7.错误指南
有两种情况和原因
情况一:
WARN concurrent.DefaultPromise: An exception was thrown by
org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$6.operationComplete()
java.lang.Error: Couldn't properly initialize access to HDFS internals.
Please update your WAL Provider to not make use of the 'asyncfs' provider.
WAL(Write-Ahead-Log)需要指定写入模式(WALFactory),有defaultProvider、asyncfs、filesystem、multiwal四种选项。
https://hbase.apache.org/devapidocs/org/apache/hadoop/hbase/wal/WALFactory.html
解决方法:
在hbase-site.xml文件添加属性
vim /hbase/conf/hbase-site.xml
添加以下内容:
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value> <!--也可以用multiwal-->
</property>
情况二:
WARN [RS-EventLoopGroup-1-1] concurrent.DefaultPromise: An exception was thrown by
org.apache.hadoop.hbase.io.asyncfs.FanOutOneBlockAsyncDFSOutputHelper$4.operationComplete()
java.lang.IllegalArgumentException: object is not an instance of declaring class
其中的1-1也可能是其它数值
原因和解决方法:
只启动成功了Master(HMaster)和部分RegionServer,有1个或多个RegionServer没启动成功。
有可能是以下错误(解决方法也在里面):

