前言
HBase是一个分布式、可扩展、支持海量数据存储的NoSQL数据库。底层物理存储是以Key-Value的数据格式存储的,HBase中的所有数据文件(默认)都存储在Hadoop HDFS文件系统上。
Hbase数据模块

- Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
- Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
- Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column - Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
#表的创建
create ‘t1’,{NAME=>’c1’,VERSIONS=>2},{NAME=>’c2',VERSIONS=>1}
# 添加数据:
put ‘t1’,’r1’ ,’c2:2’,’1-2/2’.
put ‘t1’,’r1’ ,’c2:1’,’1-2/1’
put ‘t1’,’r1’ ,’c1:3’,’1-1/3’.
put ‘t1’,’r1’ ,’c1:2’,’1-1/2’.
put ‘t1’,’r1’ ,’c1:1’,’1-1/1’
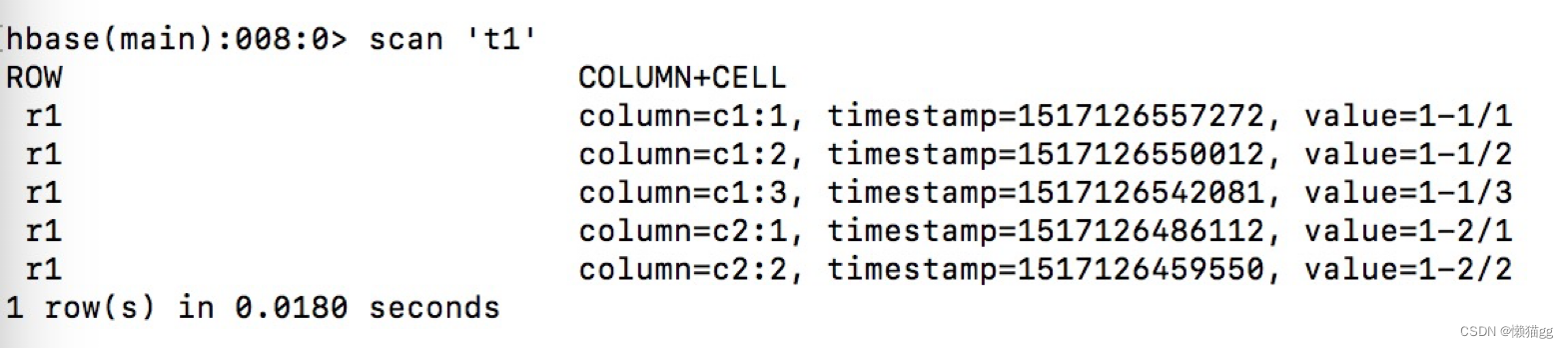
- 从图左下脚 1 row in 0.018 seconds , 代表查1行数据花了0,018 seconds (看上去有5行,其实只有一行)
- Timestamp从下往上分别代表着’图1’的 t3-t7, 也就是 value的插入时间
- column=c1:1 ,c1为列簇,c1为列
个人理解:
- 列簇的作用,相当于我们传统的“窄表”,即 t1表中有两张表分别名为”c1”,”c2”.
- ”c1”表中用1,2,3,三列;“c2”表中,用1,2二列。
- 它们共用着相同的主键”r1”
版本的概念
从建表语句中发现VERSIONS这关键字什么用?
## 建表语句
create ‘t1’,{NAME=>’c1’,VERSIONS=>2},{NAME=>’c2’,VERSIONS=>1}
# 继续执行:
put ‘t1’,’r1’ ,’c2:2’,’2-2/2’.
put ‘t1’,’r1’ ,’c2:1’,’2-2/1’.
put ‘t1’,’r1’ ,’c1:2’,’2-1/2’.
put ‘t1’,’r1’ ,’c1:1’,’2-1/1’

c1:1,c1:2分别有两条,其它仅一条,c1:3是因为只插入了一次数据,c2:1,c2:2是因为创表的时候限制了他版本
Hbase 架构

- zookeeper:记录一些基本信息
- Hmaster:负责table和Hregion的管理工作
- HRegionServer:负责响应客户请求,向文件系统中写数据
- Hregion:相当于表的概念
- Hlog:用户操作日志
- store:列簇
- MemStore:用户写入数据首先会放入Memstore,当Memstore满了以后会flush成一个storeFile
- StoreFile:当StoreFile数量增长到一定的阈值,会触发compact合并
- HFile:storefile的实现
zookeper
zookeper做为强一致性的分布式数据库,其在HBASE的作用
- 存储Meta表地址,可以更快的查询到哪张表有数据,存储Hmaster地址,确定要哪些Hmaster
- 当Hmaster失效时,可从备用中选择出来Hmaster,保证只有一个在运行
- 存储所有region寻址入口
- 利用watch功能监控Region Server状态,并通知Hmaster
- 存储表结构信息

- meta-region-server存储Meta表的地址(0.96之前是root-region-server,然后通过ROOT找到meta)
- master当前正在使用的Hmaster信息
- Backup-masters备份的hmaster信息
- Rs 所有region的信息状态
- Table 中存储表结构信息
client查询流程

- Client使用RPC机制,对于管理类操作与Hmaster通信,对于数据读写与HRegionServer通信。
- Client访问数据之前需要访问zk,找到meta地址,然后再到Meta表,最后才能找到用户数据位置去访问
- Client会维护一些Cache数据,防止每次去取,比如region位置信息
Hmaster
每HMaster在功能上主要负责Table表和HRegion的管理工作,具体包括:
- 管理用户对Table表结构的增、删、改、查操作;
- 管理HRegion服务器的负载均衡,调整HRegion分布;
当一台服务器上,HRegion过多,HRegion会被调到另一台机子上 - 在HRegion分裂后,负责新HRegion的分配;
- 在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
注:因为底层用的是hdfs,RegionServer的Hregion信息都存在ZK中,这边的迁移Hregion是比较轻松的
得出:Hbase扩展容,扩展了机子是比较方便的。
HRegion

- 当用户需要更新数据的时候,数据首先被提交到HLog文件里面,数据会被分配到对应的HRegion服务器上提交修改,数据到来时首先更新到MemStore中,当到达阔值之后再更新到对应的storeFile(Hfile)中。每一个Store包含了多个StoreFile,StoreFile负责的是实际数据存储,为HBase中最小的存储单元。
- HLog文件用于故障恢复。例如某一台HRegionServer发生故障,那么它所维护的HRegion会被重新分配到新的机器上。这是HLog会按照HRegion进行划分。新的机器在加载HRegion的时候可以通过HLog对数据进行恢复。
- Hbase中不涉及数据的删除和更新操作,所有数据均通过追加的方式进行更新。数据的删除和更新,在HBase合并的时候进行。当Store中StoreFile的数量超过设定的阔值时将触发合并操作,该合并操作把多个StoreFile文件合并成一个StoreFile。
当一个HRegion变得太过巨大,超过了设定的阔值时,HRegion此HRegion拆分为两个,并且报告给Hmaster让它决定由哪台HRegion服务器来存放新的HRegion
Hfile

它在Hbase中的地位,相当于class文件在JAVA虚拟机中的地位。HFile的组成分成四部分
- Scanned Block(数据block)
- Non-Scanned block(元数据block)
- Load-on-open(在hbase运行时,HFile需要加载到内存中的索引、bloom filter和文件信息)
- trailer(文件尾)其中Version是Hfile的版本号,目前有(v1,v2,v3),图为V2版本节构中
Hfile的结构复杂在这里就不做过多的解释了。里面主要包含 B+索引树,bloom 过滤器
Hfile中的B+树

在数据量不大的时候只有最上面一层,数据量大了之后开始分裂为多层,最多三层,他没有Mysql(B+)树复杂的分裂。如图所示。最下面一层为数据层,存储用户的实际keyvalue数据。这个索引树结构类似于InnoSQL的聚集索引,只是HBase并没有辅助索引的概念。
- 用户输入rowkey为fb,在root index block中通过二分查找定位到fb在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为root index block常驻内存,所以这个过程很快。
- 将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index ‘d’和’h’之间,接下来访问索引’d’指向的叶子节点。
- 同理,将索引’d’指向的中间节点索引块加载到内存,一样通过二分查找定位找到fb在index ‘f’和’g’之间,最后需要访问索引’f’指向的数据块节点。
- 将索引’f’指向的数据块加载到内存,通过遍历的方式找到对应的keyvalue。
Hfile中的bloom filter

如图:
x1的哈希 010010001000
x2的哈希 000010100010
sum数组 010010101010
x3的哈希 010000101000 问x3是否在sum里, 答 没有
x4的哈希 010000100010 问x4是否在sum里,答 不一定
bloomFilter算法可以判断 XX数据一定不在 XX容器里,不能肯定一定在XX容器里
在不等于的搜索,他可以过滤一大部份东西
hbash的存储过程
通过对t1表的物理查询,并使用hfile命令反解析文件

看下文件路径,表示查看t1表c1列簇的数据
# 执行新增语句,插入一条为“r2”的数据
put ‘t1’,’r2’ ,’c1:1’,’888’.
文件没有变多,并且文件里的数据仍然和上一而PPT里面一样,怎么回事?这是MemStore搞的鬼,所以执行下flush “t1”

多了一份文件叫XXXaa,就存着我们刚刚新增的数据
结论:当MemStore满的时候,持久化的操作只是简单的把数据导到一文件中
Hbase 中的删除和更新是不存在的!
- 比如说我现在想把,“r1-c1:1-1-1/1”. 删除或更新:
- 我只要往执行 put ‘t1’,’r1’ ,’c1:1’,’3-1/1’ 把”r1-c1:1-1-1/1”给挤出去

再去那文件查看下,原来的二个文件不见了,只剩下一个文件了
原来Hbase有一后台进程,当到达一定条件的时候会合文件,执行 flush ‘t1’.然后再 major_compact ‘t1’ 合并文件
结论:
Hbase直接删除数据不是在我们执行的时候,而是在文件合并的时候。。
Hbase的写入模型就是一颗LMS树
LMS树
Hbase为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存(Menstore)中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。

LSM Tree优化方式:
a、Bloom filter: 就是个带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
b、compact:小树合并为大树:因为小树他性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了
hbaser的查找过程
- Hbase先去zookeeper获取meta所在的地址
- meta表帮忙定位Rowkey所在的region地址
- 连接这个RegionServer取出数据

meta表中主要关注,rowkey,info:regioninfo,info:server,Info:regioninfo
- rowKey=表名+开始Key+region创建时间+region标识(encoded)
- server就是记录服务地址
- ragioninfo, 记录region中rowkey的范围 [Startkey,ENDKEY]
下图中很明显可以看出我们的t1表被分为三个regionInfo,[’’,r1)[r1,r12)[r12,’’)


到具体的region中
- 查询memstore,即写内存是否存储rowkey数据,如果有就返回,没有进行第二步查询;
- 查询region server的读缓存BlockCache 是否存在rowkey对应数据,如果有就返回,没有的话就行进行第三步查询。
- 在HFile里面根据rowkey查询数据,不管有没有都返回到client。
RowKey的设计
- Hbase 的设计主要是rowkey的设计,所有数据是按照rowkey的字典顺序来存储的.
- HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
- rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
设计RowKey三大原则
- 长度原则:原因一是数据的持久化文件HFile中是按照KeyValue存储的,如果RowKey过长比如100字节,1000万列数据光RowKey就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响HFile的存储效率;原因二是memstore将缓存部分数据到内存,如果RowKey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此RowKey的字节长度越短越好原因三是目前操作系统大都是64位,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性
- 散列原则:如果RowKey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将RowKey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer实现负载均衡的几率,如果没有散列字段,首字段直接是时间信息,将产生所有数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
- 唯一原则:RowKey是按照字典排序存储的,因此,设计RowKey时候,要充分利用这个排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
个人理解:rowkey有像Mysql的联合索引,联合索引越前面的是越重要要的。Region的拆分功能是Hbase的一大亮点,但那只能根据RowKey拆分。可以把这功能想象是COBAR中间件,总不可以 设置一时间字段为COBAR路由,当要要查XX天的数据时,只能等一台机子查询,其它几台看着。RowKey的底层是B+树,B+树和B树的区别是取数方便。比如,你只想取一家店的订单,你没必要要分发到各台机子上去取,然后再把结果集合起来。 散列原则和唯一性原理,表面上看起来有冲突,但想想又是没冲突的(只差100条数据有必要几台一起干吗?查几W 的数据,为什么不让其它机子一起干)
当可选条件很多的时候,甚至我们一开始都不能确定的条件,这种方式还可靠吗?
搜索引擎+HBASE,由搜索引擎来定位Rowkey.
总结
HBase在HDFS上面做了一层合并树对文件进行管理,使用hdfs支持数据时间更新。
HBase在通过自己管理了一张路由表Meta,来对大表进行拆分
HBase借助HDFS来保证数据的可靠性

