һ Flumeר��֮������ܹ�����
1��Flume����
1.1��Flume����
? Flume��һ�ֲַ�ʽ�ġ��߿ɿ��ĺ߿��õķ���,������Ч���ռ����ۺϺ��ƶ�������־���ݿ����
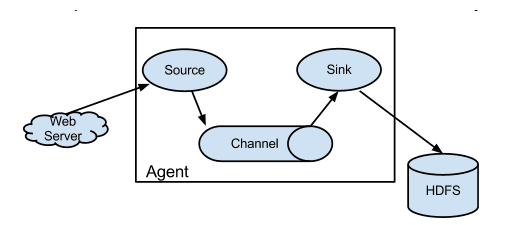
- Flume��һ�������Ļ�������������ϵ�ṹ��
1.2��Flume����
(1)֧���Զ���Source
? flume ֧������־ϵͳ�ж��Ƹ������ݷ��ͷ�,�����ռ����ݡ�
(2)֧�����ݼ���
? flume֧�ֶ����ݽ��м���,��д���������ݽ��ܷ�(�����ı���HDFS��Hbase��)������ ��
(3)�¼��������ݵ�λ
? flume �����������¼�(Event)�ᴩʼ�����¼��� Flume �Ļ������ݵ�λ,��Я����־����(�ֽ�������ʽ)����Я����ͷ��Ϣ,��Щ Event �� Agent �ⲿ�� Source ����,�� Source �����¼��������ض��ĸ�ʽ��,Ȼ�� Source ����¼�����(��������) Channel �С����� Channel ������һ��������,���������¼�ֱ�� Sink ��������¼���
(4)�߿ɿ���
? ���ڵ���ֹ���ʱ,��־�ܹ������͵������ڵ��϶����ᶪʧ��Flume�ṩ�����ּ���Ŀɿ��Ա���,��ǿ�������ηֱ�Ϊ:
- end-to-end:�յ�����agent���Ƚ�eventд��������,�����ݴ��ͳɹ���,��ɾ��;������ݷ���ʧ��,�������·��͡�
- Store on failure:��Ҳ��scribe���õIJ���,�����ݽ��շ�crash����ʱ,������д������,���ָ���,�������͡�
- Best effort:���ݷ��͵����շ���,�������ȷ����
1.3��Flumeʹ�ó���
? ʵʱ��ض�ȡ���������������ش��̵�����,������д�뵽HDFS��Kafka�����δ���������ȥ��
- 1��webserver������־;
- 2����־ͨ��flume��װ��Agent���вɼ�;
- source:��������Դ
- channel:�������ݻ���Ĺܵ�;
- sink:����Ŀ�ĵ�
- 3�������������HDFS/HBASE/KAFKA�ϡ�
2��Flume�ܹ����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-yFHTtXjw-1652500698450)
2.1��Event
? Event��Flume�����ݴ����������λ,flume�����ݴ����������ʹ��Event�����ݷ�װ�������д���ġ�
-
����:����������,��������־��¼�� avro �����,������ı��ļ�ͨ����һ�м�¼��
-
���:Event��Header��Body,Headerʹ��k-v��ŵ�Event��������Ϣ;Body���ֽ������γɴ洢������Ϣ��
Event: { headers:{} body: 68 61 64 6F 6F 70 hadoop }
2.2��Agent
? Agent�����ݴ���(����-����-����)��ʽ,Agent��һ��JVM����,flume �� Agent Ϊ��С�Ķ������е�λ,������������������:Source��Chanel��Sink��
2.3��Source
? Source�Ǹ���������ݵ�Flume Agent�����,Source������Դ����������͡����ָ�ʽ����־����,����avro��thrift��exec��spooling directory��netcat��tailder���Լ�Custom Source��
2.4��Channel
? Channel��Ϊ��Source��Sink֮��Ļ�������Channel����Source��Sink�����ڲ�ͬ�������ϡ�Channel���̰߳�ȫ��,����ͬʱ�������Source��д����������Sink�Ķ�ȡ������
- Flume Channel�ٷ��ṩ:memory��jdbc��kafka��file���Լ�Custom Channel��
2.5��Sink
? Sink������ѯChannel�е��¼��������Ƴ�����,������Щ�¼�����д�뵽�洢��������ϵͳ�����߱����͵�����һ��Flume Agent��
- Sink���Ŀ�ĵ�:hdfs��loggeer��avro��thrift��ipc��file��hbase��solr���Զ���Custom Sink
2.6��Flume NG�ܹ�
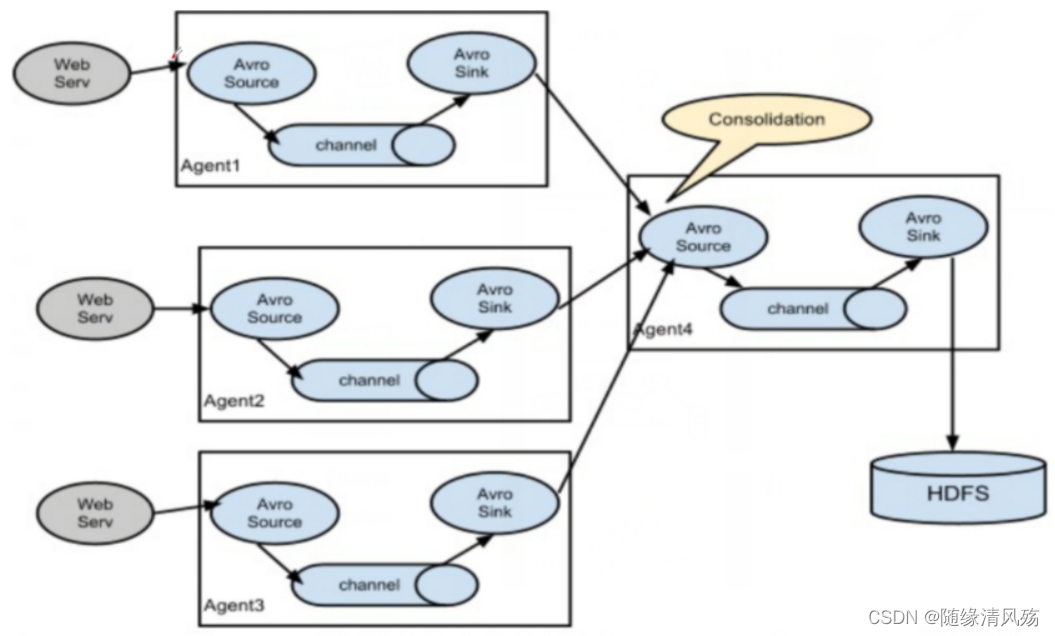
(1)ÿ��web server������־�ļ�
(2)ÿһ̨web server����Ӧ�Ľڵ��Ͽ���һ������,�ֱ��ӦAgent1,Agent2��Agent3;
? Avro Sources���������л�,д�뵽channel,֮����������Avro Sink,��Avro sink����ʽ�������������ν��д�����
(3)���ε�avro Source�������ε�Avro Sink������,�ھ������ε�Flume���ܵ�HDFS�С�
3��Flume��װ����
3.1������
- ������������
https://www.apache.org/dyn/closer.lua/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
3.2���ϴ�����ѹ
- �ϴ������Ի������ѹ
tar -xzvf apache-flume-1.9.0-bin.tar.gz -C /opt/module/flume

3.3�����û�������
sudo vim /etc/profile.d/my_env.sh
- ����������������
export FLUME_HOME=/opt/module/flume/apache-flume-1.9.0-bin
export PATH=$PATH:$FLUME_HOME/bin
- ʹ�����ļ���Ч
source /etc/profile.d/my_env.sh
- ��֤�汾
flume-ng version

3.4��ɾ������Jar��
rm /lib/guava-11.0.2.jar
�� Flumeר��֮��ҵ���������������ʾ
1�����Ű���֮��ӡ�˿�����
1.1����������
? ʹ�� Flume ����һ���˿�,�ռ��ö˿�����,����ӡ������̨��
1.2���������
(1)ͨ��netcat��������4444�˿ڷ�������;
(2)Flume��ر�����4444�˿�ͨ��Flume��Source�˶�ȡ����;
(3)Flume����ȡ����ͨ��Sink��д������̨��

1.3��������Ϣ
(1)��װ netcat ����
sudo yum install -y nc
(2)�ж� 44444 �˿��Ƿ�ռ��
sudo netstat -nlp | grep 44444
(3)�� flume Ŀ¼�´��� job �ļ��в����� job �ļ��С�
mkdir job
cd job/
(4)�� job �ļ����´��� Flume Agent �����ļ� flume-netcat-logger.conf��
vim flume-netcat-logger.conf
(6)�� flume-netcat-logger.conf �ļ��������������ݡ�
������������:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(6)����Flume�����˿�
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
- ����˵��:
- �Cconf/-c:��ʾ�����ļ��洢�� conf/Ŀ¼
- �Cname/-n:��ʾ�� agent ����Ϊ a1
- �Cconf-file/-f:flume ����������ȡ�������ļ����� job �ļ����µ� flume-telnet.conf �ļ���
- -Dflume.root.logger=INFO,console :-D ��ʾ flume ����ʱ��̬�� flume.root.logger ��������ֵ,��������̨��־��ӡ��������Ϊ INFO ������־�������:log��info��warn�� error��

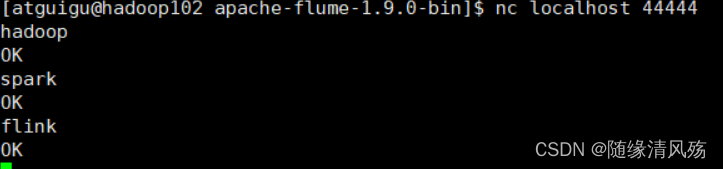
(7)ʹ��netcat��������4444�˿ڷ�������
nc localhost 44444
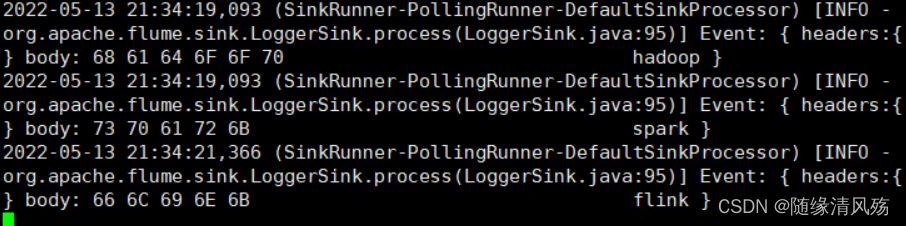
(8)Flume����ҳ����
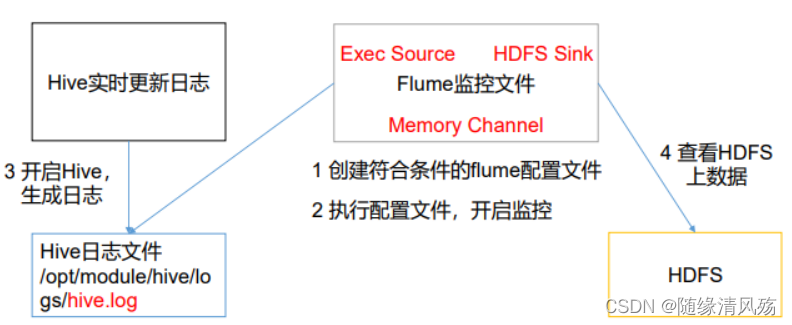
2�����Ű���֮ʵʱ��ص������ļ�
2.1����������
? ʵʱ���Hive��־,���ϴ���HDFS��
2.2���������
(1)��������������flume�����ļ�;
(2)ִ�������ļ�,�������
(3)����Hive,������־
(4)�鿴HDFS������
- Hiveʵʱ������־·��:/opt/module/hive/logs/hive.log
2.3��ʵ�ֲ���
(1)�����ļ���д
? Ҫ���ȡ Linux ϵͳ�е��ļ�,�͵ð��� Linux ����Ĺ���ִ��������� Hive ��־�� Linux ϵͳ�����Զ�ȡ�ļ�������ѡ��:exec �� execute ִ�е���˼����ʾִ�� Linux ��������ȡ�ļ���
vim flume-file-hdfs.conf
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9820/flume/%Y%m%d/%H
#�ϴ��ļ���ǰ
a2.sinks.k2.hdfs.filePrefix = logs-
#�Ƿ���ʱ������ļ���
a2.sinks.k2.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a2.sinks.k2.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a2.sinks.k2.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a2.sinks.k2.hdfs.batchSize = 100
#�����ļ�����,��֧��ѹ��
a2.sinks.k2.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a2.sinks.k2.hdfs.rollInterval = 60
#����ÿ���ļ��Ĺ�����С
a2.sinks.k2.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
(2)HDFS����Flume���Ŀ¼
hadoop fs -mkdir -p /flume
(3)����Flume
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf

(4)���� Hadoop �� Hive ������ Hive ������־
bin/hive
(5)�鿴HDFS�Ͻ��

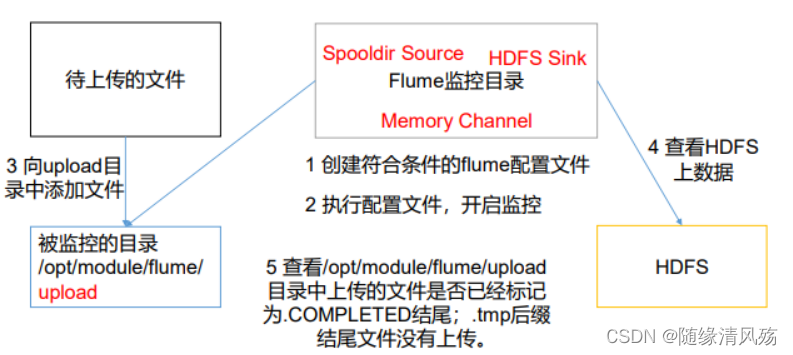
3��ʵʱ���Ŀ¼�¶�����ļ�
3.1����������
? ʹ��Flume��������Ŀ¼���ļ�,���ϴ���HDFS
3.2���������
(1)��������������flume�����ļ�
(2)ִ�������ļ�,�������
(3)��uploadĿ¼�������ļ�
(4)�鿴HDFS������
(5)�鿴/opt/module/flume/uploadĿ¼�ϴ����ļ��Ƿ��Ѿ����Ϊ.COMPLETED��β;.tmp����β�ļ�û���ϴ���
3.3��ʵ�ֲ���
(1)���������ļ�
vim flume-dir-hdfs.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#����������.tmp ��β���ļ�,���ϴ�
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:8020/flume/upload/%Y%m%d/%H
#�ϴ��ļ���ǰ
a3.sinks.k3.hdfs.filePrefix = upload-
#�Ƿ���ʱ������ļ���
a3.sinks.k3.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a3.sinks.k3.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a3.sinks.k3.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a3.sinks.k3.hdfs.batchSize = 100
#�����ļ�����,��֧��ѹ��
a3.sinks.k3.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a3.sinks.k3.hdfs.rollInterval = 60
#����ÿ���ļ��Ĺ�����С����� 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
(2)��������ļ�������
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf
- ˵��:��ʹ�� Spooling Directory Source ʱ,��Ҫ�ڼ��Ŀ¼�д������������� ��;�ϴ���ɵ��ļ�����.COMPLETED ��β;������ļ���ÿ 500 ����ɨ��һ���ļ��䶯��

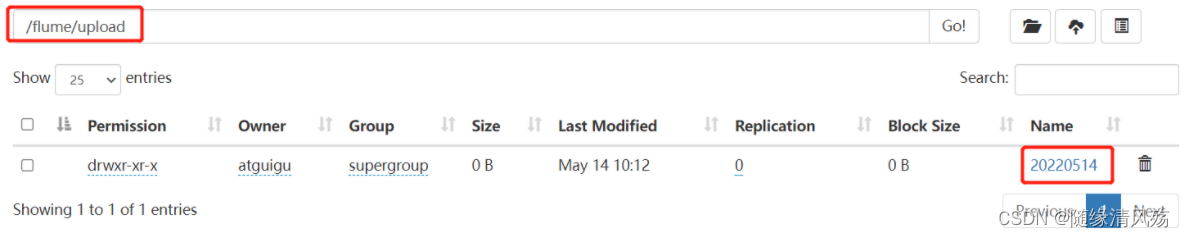
(3)����Ŀ¼�������ļ�
mkdir upload
touch atguigu.txt
touch atguigu.tmp
touch atguigu.log
(4)�鿴HDFS�ϵ�����
4��ʵʱ���Ŀ¼�µĶ�����ļ�
- �ص�:����Source����
- Exec source �����ڼ��һ��ʵʱ�ӵ��ļ�,����ʵ�ֶϵ�����;
- Spooldir Source �ʺ�����ͬ�����ļ�,�����ʺ϶�ʵʱ����־���ļ����м�����ͬ��;
- Taildir Source �ʺ����ڼ������ʵʱ�ӵ��ļ�,�����ܹ�ʵ�ֶϵ�������
4.1����������
? ʹ��Flume��������Ŀ¼��ʵʱ���ļ�,���ϴ���HDFS
4.2���������
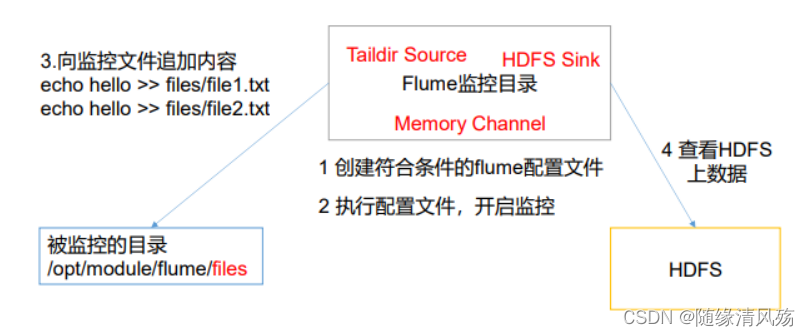
4.3��ʵ�ֲ���
(1)���������ļ�
vim flume-taildir-hdfs.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = TAILDIR
a3.sources.r3.positionFile = /opt/module/flume/tail_dir.json
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/flume/files/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/flume/files2/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path =
hdfs://hadoop102:9820/flume/upload2/%Y%m%d/%H
#�ϴ��ļ���ǰ
a3.sinks.k3.hdfs.filePrefix = upload-
#�Ƿ���ʱ������ļ���
a3.sinks.k3.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a3.sinks.k3.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a3.sinks.k3.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a3.sinks.k3.hdfs.batchSize = 100
#�����ļ�����,��֧��ѹ��
a3.sinks.k3.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a3.sinks.k3.hdfs.rollInterval = 60
#����ÿ���ļ��Ĺ�����С����� 128M
a3.sinks.k3.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
(2)��������ļ�������
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-taildir-hdfs.conf
(3)��files�ļ��������ļ�
mkdir files
cd files/
#��files�ļ��������ļ�
echo hello >> file1.txt
echo atguigu >> file2.txt
(4)�鿴HDFS�ϵ�����
������ Flumeר��֮������&������������
1������������
1.1��Flume���̷���
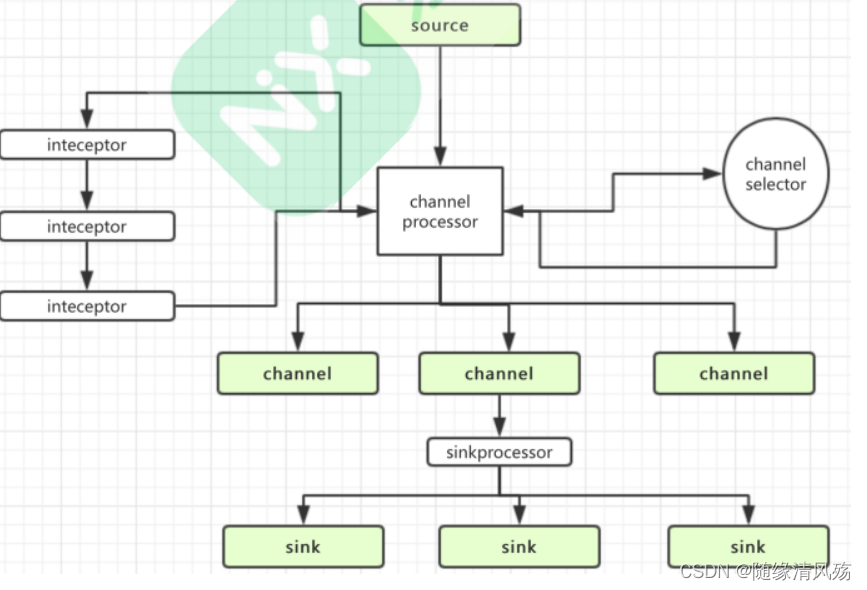
(1)Source�������ݺ����ݷ�װ��Event����
(2)Event���ݶ���Inteceptor�������ݽ��и���
(3)����Channel selectorȷ��EventҪ�����Ǹ�Channel
(4)Channelͨ��SinkProcessor�ַ�����ӦSink
1.2��Flume�����ݴ��ݹ�������
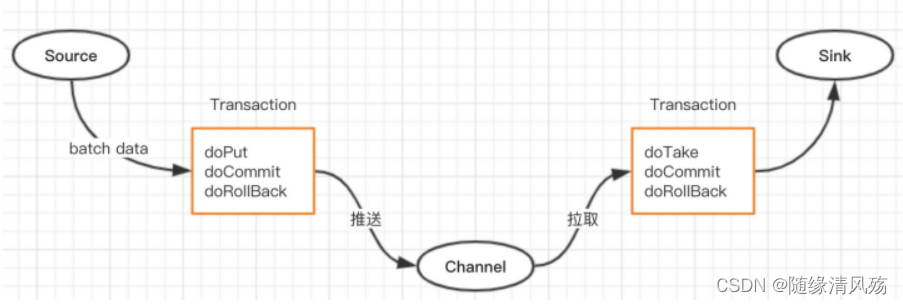
(1)������������
- doPut:��������д�뵽��ʱ������ putList doCommit,���Channel�����Ƿ����;
- ��������:��putList������ݷ��͵�Channel doRollBack��;
- ��������:�����ݻع���PutList��
(2)��ȡ��������
- doTake:�����ݶ�ȡ����ʱ������takeList,��������Ƿ��ͳɹ���
- �ɹ�:��Event��takeList���Ƴ�
- ʧ��:��TakeList�е����ݻع���Channel��
2��Flume���˽ṹ
2.1������
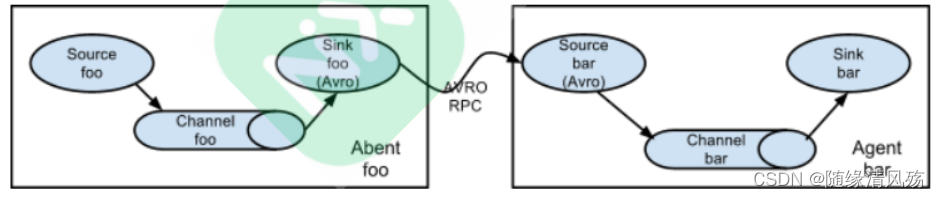
? �������ǽ����Flume˳��������,�������Source��ʼ�����յ�Sink���͵�Ŀ�Ĵ洢ϵͳ��
- ע������:��ģʽ�������Žӹ����flume����,flume�����������Ӱ�촫��Ч��,����һ�����������ij���ڵ�Flume崻�,��Ӱ����������ϵͳ��
2.2�����ƺͶ�·����
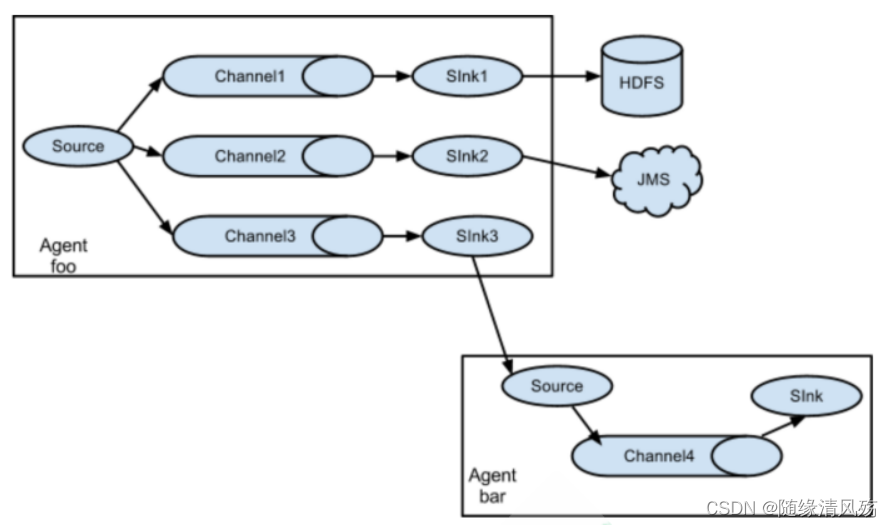
? Flume֧�ֽ��¼�����һ������Ŀ�ĵ�,��1�Զ�ģʽ��
- ע������:����ģʽ���Խ���ͬ���ݸ��Ƶ����Channel��,���߽���ͬ���ݷַ�����ͬChannel��,sink����ѡ���Ͳ�ͬĿ�ĵء�
2.3�����ؾ������ת��
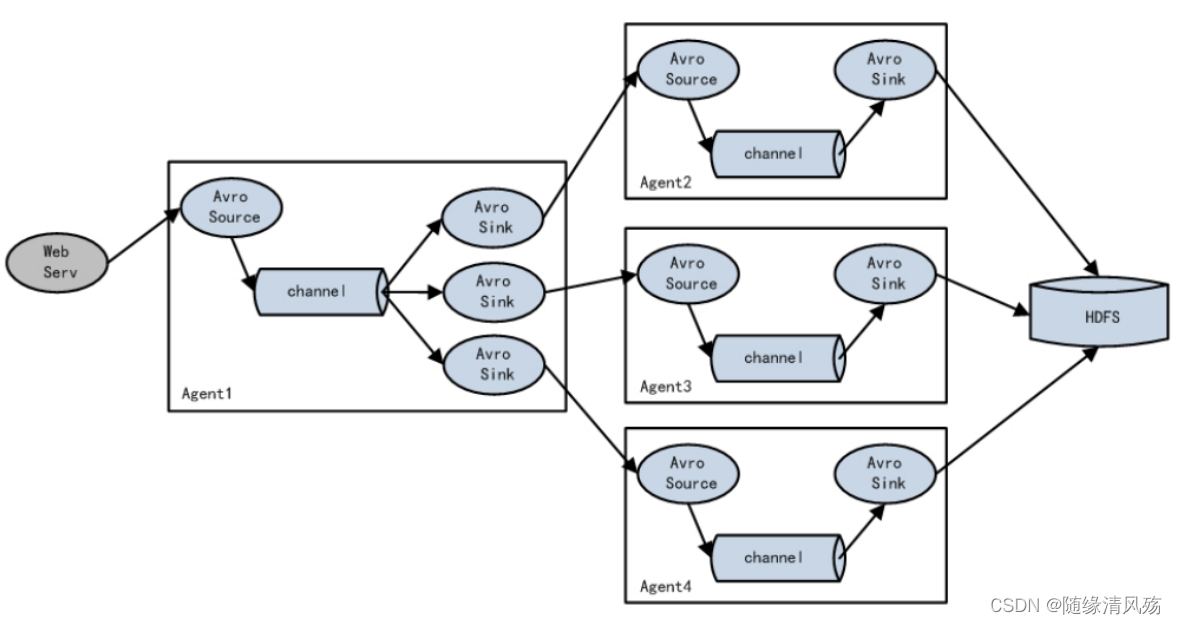
(1)���ؾ���
? �����sink���Ϸ�Ϊһ��sink��,sink����ϲ�ͬ��SinkProcessor��������Ծ��ȵķַ���ָ��Ŀ¼��������agentʵ����
a1.sinkgroups.g1.processor.type =load_balance
a1.sinkgroups.g1.processor.backoff=true
(2)����ת��
? ������agent,��agent�������ݵIJɼ������䡢���,����agentһֱ��������״̬,һ����agent崻�,����agent����,������agent�Ĺ���,ֱ����agent�ָ���
2.4���ۺ�
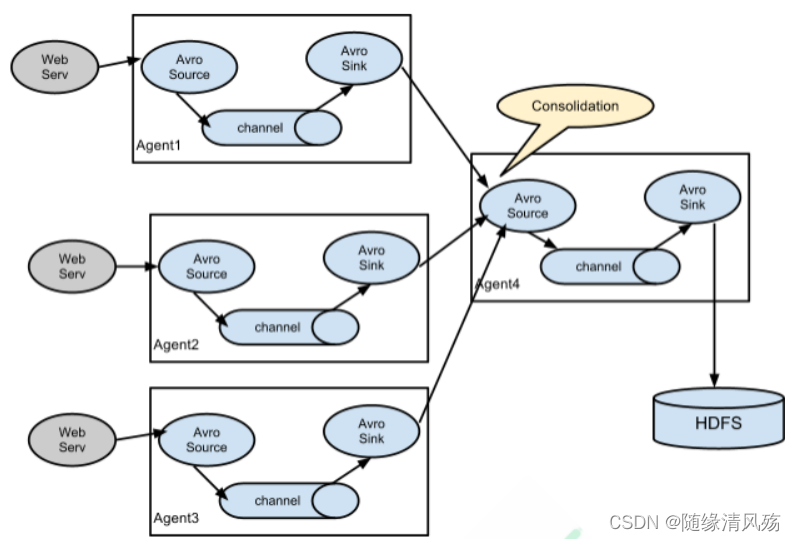
? ÿ̨����������һ�� flume �ɼ���־,���͵�һ�������ռ���־��flume,���ɴ� flume �ϴ��� hdfs��hive��hbase ��,������־������
3������ʵս֮��·����(��channel)
3.1����������
? nginx��������־������Ҫ���������ʹ��,��δ���һ�����ݷ�������ϵͳ��ʹ��?
3.2���������
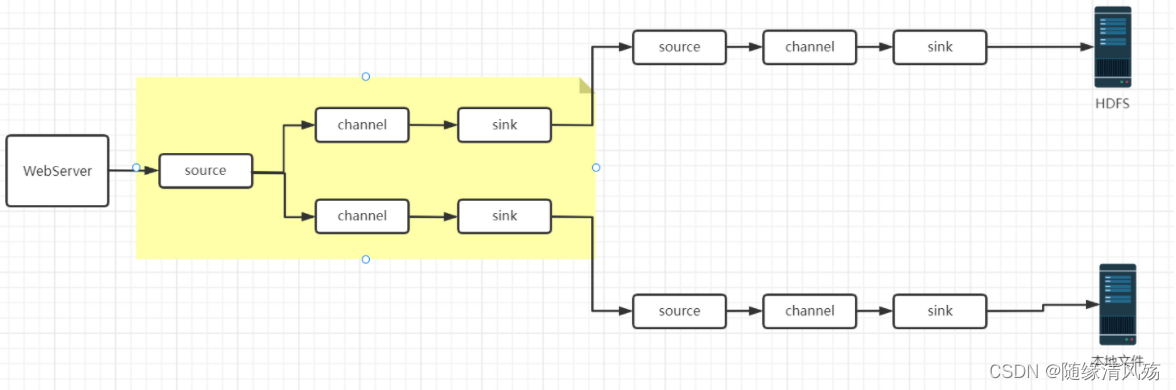
3.3������ʵ��
(1)����Ŀ¼
#�����ļ���
mkdir group1
cd group1
(2)����flume1�����ļ�
- ����:���� 1 ��������־�ļ��� source ������ channel������ sink,�ֱ����� flume-flume-hdfs �� flume-flume-dir��
#�����ļ�
vim flume-file-flume.conf
#�ļ���������
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# �����������Ƹ����� channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink �˵� avro ��һ�����ݷ�����
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
(3)����Flume2�������ļ�
- ����:�����ϼ� Flume ����� Source,����ǵ� HDFS �� Sink��
vim flume-flume-hdfs.conf
#�ļ���������
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
# source �˵� avro ��һ�����ݽ��շ���
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop102:9820/flume2/%Y%m%d/%H
#�ϴ��ļ���ǰ
a2.sinks.k1.hdfs.filePrefix = flume2-
#�Ƿ���ʱ������ļ���
a2.sinks.k1.hdfs.round = true
#����ʱ�䵥λ����һ���µ��ļ���
a2.sinks.k1.hdfs.roundValue = 1
#���¶���ʱ�䵥λ
a2.sinks.k1.hdfs.roundUnit = hour
#�Ƿ�ʹ�ñ���ʱ���
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#���ܶ��ٸ� Event �� flush �� HDFS һ��
a2.sinks.k1.hdfs.batchSize = 100
#�����ļ�����,��֧��ѹ��
a2.sinks.k1.hdfs.fileType = DataStream
#�������һ���µ��ļ�
a2.sinks.k1.hdfs.rollInterval = 30
#����ÿ���ļ��Ĺ�����С����� 128M
a2.sinks.k1.hdfs.rollSize = 134217700
#�ļ��Ĺ����� Event ������
a2.sinks.k1.hdfs.rollCount = 0
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
(4)����flume3�������ļ�
- ����:�����ϼ� Flume ����� Source,����ǵ�����Ŀ¼�� Sink��
- ע������:����ı���Ŀ¼�������Ѿ����ڵ�Ŀ¼,�����Ŀ¼������,�����ᴴ���µ�Ŀ ¼��
vim flume-flume-dir.conf
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/data/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
(5)�ֱ�ִ�������ļ�
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf
(5)����Hive�����ļ�
- HDFS������

- ���ش����ļ�
4������ʵս֮����ת��(��Sink)
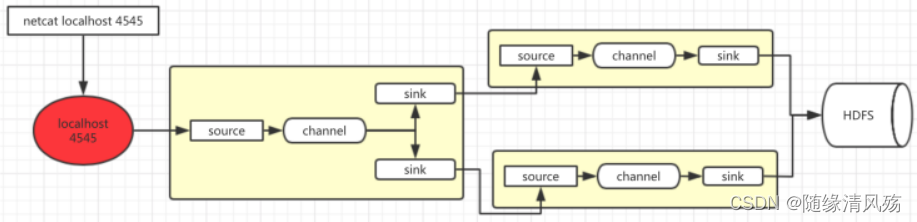
4.1����������
? ʹ��Flume1���һ���˿�,��sink���е�sink�ֱ�Խ�Flume2��Flume3,����FailoverSinkProcessor,ʵ�ֹ���ת�ƹ��ܡ�
4.2���������
4.3������ʵ��
(1)����Ŀ¼
mkdir group2
cd group2
(2)����flume1�����ļ�
- ����:���� 1 �� netcat source �� 1 �� channel��1 �� sink group(2 �� sink),�ֱ����� flume-flume-console1 �� flume-flume-console2��
vim flume-netcat-flume.conf
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
(3)����Flume2�����ļ�
- ����:�����ϼ� Flume ����� Source,����ǵ����ؿ���̨��
vim flume-flume-console1.conf
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
(4)����flume3�����ļ�
- ����:�����ϼ� Flume ����� Source,����ǵ����ؿ���̨��
vim flume-flume-console2.conf
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
(5)�ֱ�ִ����������ļ�
bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console
bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf
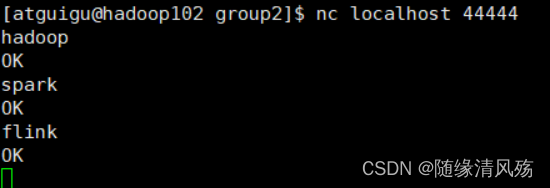
(6)ʹ��netcat��������44444�˿ڷ�������
nc localhost 44444
#�˿ڱ�ռ��
#1.�鿴�˿��Ƿ�ռ��
netstat -anp |grep [�˿ں�]
#2.�鿴ռ�õĽ���
lsof -i:[�˿ں�]
#3.�رս���
kill -9 [����PID]
(7)��������
-
����:��flume-console2��������ʱ��,netcat����ֻ�ᷢ�͵�flume-console2�С�
-
��������
-
���ͽ��:flume-console2��ӡ���
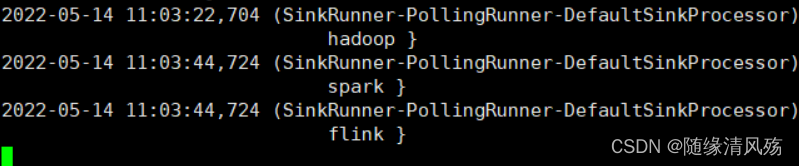
- ���ͽ��:flume-console1����ӡ���

(8)����ת��
- ����:��flume-console2���ֹ��Ϻ�,���ݷ��͵�flume-console1.
#ɱ��flume-console2�Ľ���
kill -9 pid
- netcat��������
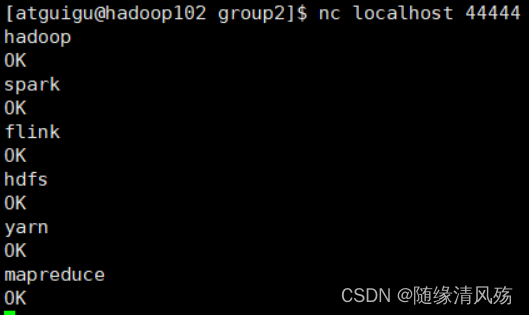
- flume-console1�Ľ�������ӡ
5������ʵս֮�ۺϲ���
5.1����������
? �������Բ�ͬ����������־���ݲɼ������洢��HDFS�ۼ���һ����д���
5.2���������

5.3������ʵ��
������
�� Flumeר��֮����������
1������Flume���̲ɼ������ݺ�,���ﲻֱ���͵�Ŀ�ĵ�?
(1)���ε�Flume������ʮ���Ӵ�,ֱ������Ŀ�ĵ�,Ŀ�ĵ�ϵͳ�������ز��˸߲����ķ���ѹ��崻�;
(2)���ε�Flume���ɼ����������������Flume��,����Flume���̽���������Ŀ�ĵ�;
(3)����Flume������Ϊ����,һ�㶼��������
2��Flume�ṹ����
(1)Source:Ĭ���е�Avro(�����˿�),thrift��Exec(ִ��linux����)��JMS��SpoolingDirctory(����Ŀ¼)�����������kafka;
(2)������:����events,����ͷ,����json����ʽ���headers:{��keys��:��values��}:ʱ���(ͷ������ʱ���),����(ͷ��������������IP),��̬(ͷ������ָ��KV),�������(���·���������)
(3)Channel:����Memory��File��JDBC��Kafka������;
(4)������:�Զ���������,ͬ��
(5)Sink:����HDFS,hive,Avro,Hbase,kafka������
3��Flume HA����(�߿��û���)
(1)���ؾ���
? flumeNGͨ������sinkgroups�������DZ�ڵ�ֵ�һ��,Ȼ�����ø������ø��ؾ���,��DZʱ���Զ�ѡ��ڵ�,����ڵ�崻���ѡ�������ڵ�:�����ں�̨����ʱ��ѯ���β�ѯ,ÿ��sink�ͳ�ȥ��ѹ����������һ�¡�
(2)�������
? ����������event(��������),ʹ����������������ֱ���source��channel��channel��sink֮��,ʧ��ʱ�Ὣ�������ݶ��ع���source��channel�������ԡ�
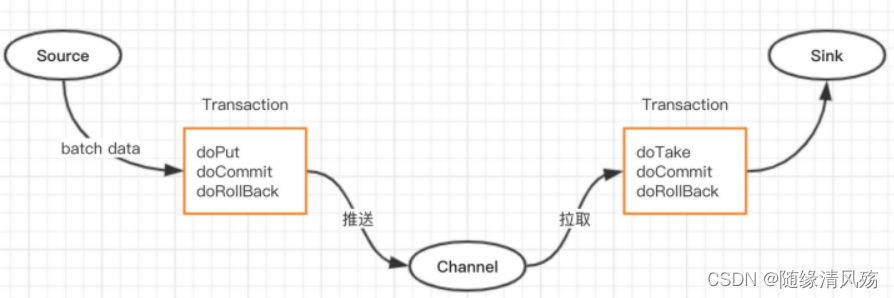
- Put����:source��channel֮��
- Take����:channel��sink֮��
4��Flume�����ݶ�ʧ&�ظ�����
(1)���ݶ�ʧ����
- ��Channel ���� memoryChannel,agent 崻��������� ��ʧ,���� Channel �洢��������,���� Source ����д��,δд������ݶ�ʧ
(2)�����ظ�
- �����Ѿ���Sink����,����û�н��յ���Ӧ,Sink���ٴη�������,���������ظ�
? �ܵ���˵,Flume ���ᶪʧ����,�����п���������ݵ��ظ�,���������Ѿ��ɹ��� Sink ����, ����û�н��յ���Ӧ,Sink ���ٴη�������,��ʱ���ܻᵼ�����ݵ��ظ�
5��Flume��channelѡ��
- ע������:Channel�����Ϊevent��ת��ʱ������,�洢source�ռ�����û�б�sink��ȡ��Event
(1)memory:��д�ٶȿ�,���Ǵ洢������С,Flume���̹ҵ���������崻������������ᵼ�����ݶ�ʧ;
(2)File:��ص�����,���sink�Ѿ��ύ��ɵ�����,�����ɾ��file;
(3)Kafka
-
��־�ռ���:ֻ����Source�����kafka���,����Ҫ������Sink���
- �ټ�������־�ֻ��������Ľ�����
- ����Ч���ͷ������ڴ桢���̵���Դ��ʹ����
-
��־��۲�:ֻ����kafkachannel��sink,����Ҫ������Source
6��Flume����������
(1)����
- Source��eventд�뵽channel֮ǰ����ʹ����������event���и�����ʽ�Ĵ���
- source��channel֮������ж��������,�����ò�ͬ������ж���������
(2)����������:ETL����������������������
(3)�Զ�������������
- ��ʵ�ֽӿ�intercept
- ����д�ĸ�����(��ʼ��,��������event,�������event-���ô�������event����,close������Դ�ͷ�-flume���ᴦ������״̬)
- ��ʵ�־�̬�ڲ���builder,������ز���
- �������Զ������������,�ϴ���flume��libĿ¼��
- ������flume�ĺ��������ļ�
7��Flume���Ϸ���
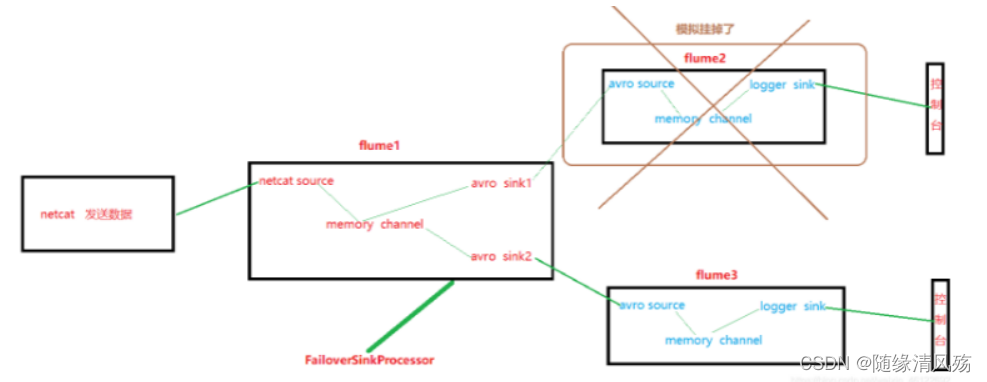
? ���ؾ������ת�Ʒ���:����sink��,ͬһ����sink�����ж����sink,��ͬsink֮��������óɸ��ؾ�������ת����
8��Flume�Ż�
(1)Flume�ڴ�����Ϊ4G:ʵ�ʿ�����,��flume-env.sh������JVMheapΪ4G�����
(2)FileChannel�Ż�:DataDirsָ����·��,ÿ��·����Ӧ��ͬӲ��,����Flume��������:Checkpoint��backCheckpointDirҲ���������ڲ�ͬӲ�̶�ӦĿ¼,��֤checkpoint������,�ɿ��ٻָ�
(3)Sink�Ż�:HDFSSinkС�ļ�����
- ����HDFS��������С�ļ�,������ز����ﵽЧ������
- ��tmp�ļ��ﵽ128Mʱ�����������ʽ�ļ�;
- ��tmp�ļ�������10�����������ļ���

