对于目前来讲,对数据的处理主要集中在两个方面,一种是联机事务处理 OLTP(on-line transaction processing),另一种是联机分析处理 OLAP(On-Line Analytical Processing)。
OLTP:是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,典型的是银行 ATM 存取款,金融证券方面的实时更新等,这些操作都比较简单,主要是对数据库中的数据进行 DML 操作,操作主体一般是产品的用户,并且 OLTP 事务性非常高,一般都是高可用的在线系统,如上述的银行金融方面。
OLAP :有的时候也叫 DSS 决策支持系统,也就类似于我们说的数据仓库,它使分析人员能够迅速、一致、交互地从数据的各个方面来观察信息,以达到深入理解数据的目的。通过分析 DW 中的数据来得出一些结论性的东西(比如报表),从各方面观察信息,也就是从不同的维度分析数据(站在维度的角度看待事实),因此 OLAP 也称多维分析。
两者的对比如下图所示:
| 属性对比 | OLTP (例如mysql) | OLAP (例如hive) |
|---|---|---|
| 操作对象 | 数据库 | 数据仓库 |
| 读特性 | 每次查询只返回少量记录 | 对大量记录进行汇总 |
| 写特性 | 随机、低延时写入用户的输入 | 批量导入大量的数据 |
| 数据时效 | 当前最新的数据 | 当前历史的聚集的数据 |
| 操作粒度 | 记录级 | 多表join分析 |
| 使用场景 | 用户,Java EE项目 | 数据分析师,为企业决策提供支持 |
| 具体工作内容 | 简单的事务 | 复杂的查询 |
| 时间要求 | 具有实时性 | 分离线数仓和实时数仓 |
| 数据量 | GB | TB到PB |
| 数据操作 | 支持DDL,DML | 一般不支持更新和删除 |
| 主要功能 | 查询或改变现状 | 报表,统计预测 |
然而对于 即席查询 而言,一般情况下它是与 OLAP 做对比的,这里说明一下在数仓中我们一般都是对数据进行一个批处理(基本上对前一天数据处理),并且是针对固定的数据有一个明确的分析指标的。例如,下图是一张订单表的数据:
| 订单ID | 下单地区 | 下单品类 | 下单时间 | 下单金额 |
|---|---|---|---|---|
| 1001 | 华北 | 电子 | 12月 | 456 |
| 1002 | 华东 | 食品 | 11月 | 489 |
| 1003 | 西南 | 居家 | 2月 | 491 |
| 1004 | 东北 | 电子 | 4月 | 659 |
| 1005 | 西北 | 宠物 | 11月 | 369 |
| 1006 | 华北 | 食品 | 2月 | 159 |
何为一个明确的分析指标?按照上述所说的,从维度的角度看待事实(事实指的是度量值,在这张表中为金额),我们可以按照7个维度来度量金额,也即是下表所列出的内容。
| 维度 | 度量值 | 分析指标 |
|---|---|---|
| 品类 | 金额 | … |
| 时间 | 金额 | … |
| 地区,品类 | 金额 | … |
| 地区,时间 | 金额 | 什么地区,什么时间销售了多少金额 |
| 品类,时间 | 金额 | … |
| 地区,品类,时间 | 金额 | 什么地区,什么品类,什么时间销售了所少金额 |
通过上面表的展示,也就是从不同的维度来围绕度量值分析
对于数仓的这种分析情况,我们一般都是有固定的套路的,比如说
select area, time from table group by area, time;
这种查询也称作为 固化查询
指对一些固化下来的取数、看数的需求,最终通过数据产品的形式提供给用户,从而提高数据分析和运营的效率,这类需求的 SQL 基本上有固定的模式
然而不幸的事情发生了。平时的工作中,上述的固化查询你搞的好好的,这时候老板突然来了一个需求,但是范围并不属于上述的那种有固定模式的 SQL ,我们把这类需求称为 即席查询 (Ad hoc queries)
即席查询:是指用户根据自己的需求,灵活的选择查询的条件,然后系统能够根据用户的选择,生成返回响应的结果,例如返回用户自定义的统计报表。
即席查询 的特点: 即席查询 与 固化查询 最大的不同是,普通的 固化查询 是定制开发的(即查询语句是预先写好的,不会临时发生变化),而即席查询是由用户自定义查询条件的。随时可以更改。
对于 即席查询 和 OLAP 可以参考下图的关系图
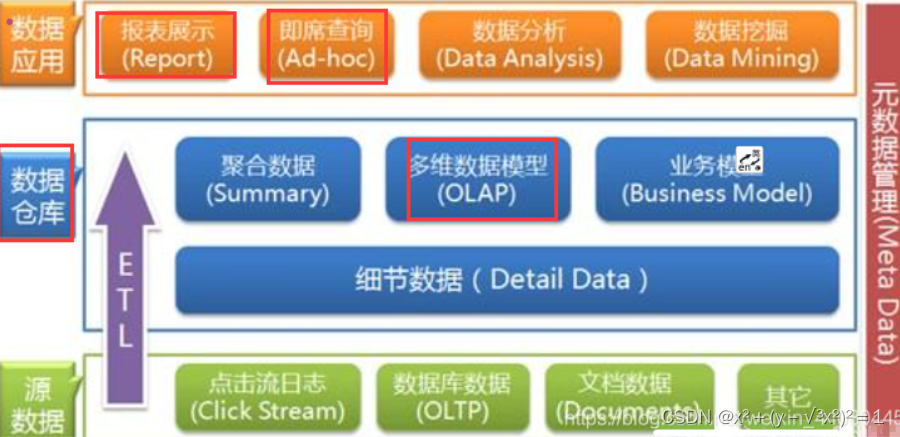
对于 即席查询 和 固化查询 的总结:
即席查询 与 固化查询 从SQL语句上来说,并没有本质的差别。它们之间的差别在于,固化查询在系统设计和实施时是已知的,所有的查询可以在系统实施的过程中,通过建立索引、分区等技术来优化这些查询,使得这些查询的效率很高。而 即席查询 是用户临时生产的需求,无法人工预先地优化这些查询,这类查询一般需要数据库内部实时地自动优化,所以 即席查询 也是评估数据仓库的一个重要指标。在一个数据仓库系统中,即席查询使用的越多,对数据仓库的要求就越高,对数据模型的对称性的要求也越高。
最后为什么不用hive做即席查询?
即席查询目的很明确,就是要快,所提即所得,即提出来这个需求立马要看到结果。数仓传统的hive做即席查询那肯定是不行的,MR跑完数据估计天都黑了。所以也迫使新的框架要研发出来,这里例举出市面上常用的几款即席查询的框架:Druid、Kylin、Presto、Impala、Spark SQL、ClickHouse、Doris 等。
几款框架的对比:
1、Druid:是一个实时处理时序数据的 OLAP 数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
2、Kylin:核心是 Cube ,Cube是一种预计算技术,基本思路是预先对数据进行多维索引,分别对不同的维度进行组合,形成可能出现的查询 Cube ,当然,针对无意义的维度组合可以进行剪枝操作。使得数据量变小,查询时只扫描索引而不访问原始数据从而提速。
3、Presto:它没有使用 Mapreduce,大部分场景下比 Hive 快一个数量级,其中的关键是所有的处理都在内存中完成。支持多个数据源。同时针对可以将不同的数据源进行 join 操作。
4、Impala:基于内存计算,速度快,支持的数据源没有 Presto 多。
5、SparkSQL:是 Spark 用来处理结构化数据的一个模块,它提供一个抽象的数据集 DataFrame 和 DataSet,并且是分布式 SQL 的查询引擎。它还可以实现 Hive on Spark ,使用 Spark 引擎读取 Hive 的元数据信息,从而操作 Hive 里的数据。
6、ClickHouse:ClickHouse 不依赖任何第三方组件,采用的是列式存储。支持多个存储的引擎,用户可以根据不同的表来选择不同的存储引擎。同时底层还实现了向量化引擎。
7、Doris :不依赖任何第三方组件,也是一个列存的数据库。使用 MySQL 协议,兼容 MySQL 语法,使用 MySQL 语法可对 Doris 数据库进行查询。新版本也实现了向量化引擎。
参考:https://blog.csdn.net/likino666/article/details/103165292
参考:https://blog.csdn.net/weixin_44080445/article/details/119171865

