
大数据技术AI
Flink/Spark/Hadoop/数仓,数据分析、面试,源码解读等干货学习资料
114篇原创内容
公众号
1、Kafka-Kraft架构
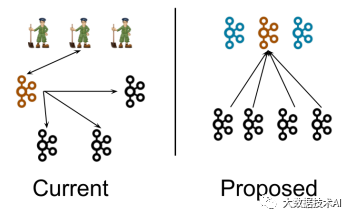
左图为Kafka现有架构,元数据在zookeeper中,运行时动态选举controller,由controller进行Kafka集群管理。
右图为kraft模式架构(实验性),不再依赖zookeeper集群,而是用三台controller节点代替zookeeper,元数据保存在controller中,由controller直接进行Kafka集群管理。
这样做的好处有以下几个:
-
Kafka不再依赖外部框架,而是能够独立运行;
-
controller管理集群时,不再需要从zookeeper中先读取数据,集群性能上升;
-
由于不依赖zookeeper,集群扩展时不再受到zookeeper读写能力限制;
-
controller不再动态选举,而是由配置文件规定。这样我们可以有针对性的加强controller节点的配置,而不是像以前一样对随机controller节点的高负载束手无策。
2、Kafka-Kraft集群
2.1 解压一份kafka安装包
[duo@hadoop01 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/data/
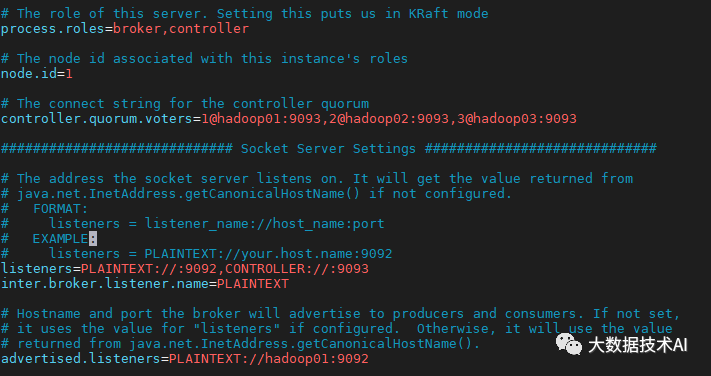
2.2 在hadoop01上修改config/kraft/server.properties配置文件
[duo@hadoop01 kraft]$ vim server.properties
#kafka的角色(controller相当于主机、broker节点相当于从机,主机类似zk功能)
process.roles=broker, controller
#节点ID
node.id=2
#controller服务协议别名
controller.listener.names=CONTROLLER
#全Controller列表
controller.quorum.voters=2@hadoop01:9093,3@hadoop02:9093,4@hadoop03:9093
#broker对外暴露的地址
advertised.Listeners=PLAINTEXT://hadoop01:9092
hadoop01:
hadoop02:
hadoop03:
2.3 分发kafka
[duo@hadoop01 data]$ xsync kafka_2.12-3.0.0/
-
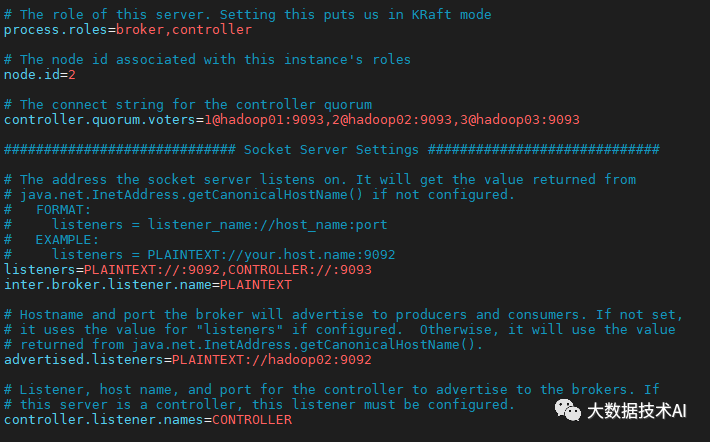
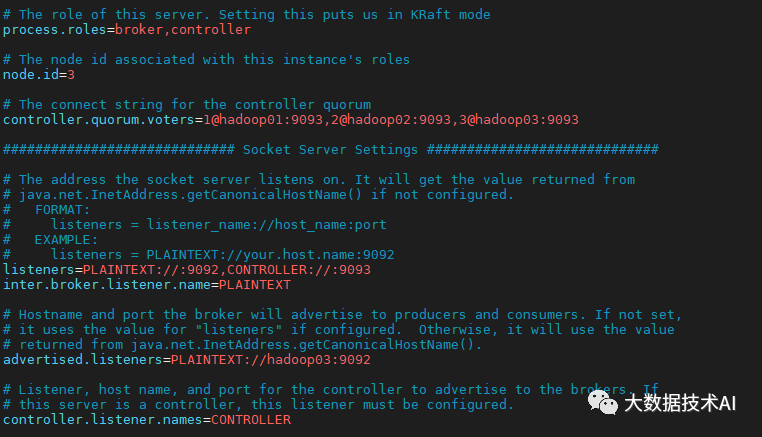
在hadoop02和hadoop03上需要对node.id相应改变,值需要和controller.quorum.voters对应。
-
在hadoop02和hadoop03上需要根据各自的主机名称,修改相应的advertised.Listeners地址。
2.4 初始化集群数据目录
(1)首先生成存储目录唯一ID。
[duo@hadoop01 kafka]$ bin/kafka-storage.sh random-uuid
IbY24Ky1Tjq-rUY6AMayxw
(2)用该ID格式化kafka存储目录(三台节点)。
[duo@hadoop01 kafka]$ bin/kafka-storage.sh format -t IbY24Ky1Tjq-rUY6AMayxw -c /opt/data/kafka_2.12-3.0.0/config/kraft/server.properties
[duo@hadoop02 kafka]$ bin/kafka-storage.sh format -t IbY24Ky1Tjq-rUY6AMayxw -c /opt/data/kafka_2.12-3.0.0/config/kraft/server.properties
[duo@hadoop03 kafka]$ bin/kafka-storage.sh format -t IbY24Ky1Tjq-rUY6AMayxw -c /opt/data/kafka_2.12-3.0.0/config/kraft/server.properties

2.5 启动kafka集群
[duo@hadoop01 kafka]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[duo@hadoop02 kafka]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties
[duo@hadoop03 kafka]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties



2.6 停止kafka集群
[duo@hadoop01 kafka]$ bin/kafka-server-stop.sh
[duo@hadoop02 kafka]$ bin/kafka-server-stop.sh
[duo@hadoop03 kafka]$ bin/kafka-server-stop.sh
3、Kafka-Kraft集群启动停止脚本
1)在/home/duo/bin目录下创建文件kafka_craft.sh脚本文件
[duo@hadoop01 bin]$ vim kafka_craft.sh
脚本如下:
#! /bin/bash
case $1 in
"start"){
for i in hadoop01 hadoop02 hadoop03
do
echo " --------启动 $i kafka-------"
ssh $i "/opt/data/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/data/kafka_2.12-3.0.0/config/kraft/server.properties"
done
};;
"stop"){
for i in hadoop01 hadoop02 hadoop03
do
echo " --------停止 $i kafka-------"
ssh $i "/opt/data/kafka_2.12-3.0.0/bin/kafka-server-stop.sh "
done
};;
esac
2)添加执行权限
[duo@hadoop01 bin]$ chmod +x kafka_craft.sh
3)启动集群命令
[duo@hadoop01 ~]$ kafka_craft.sh start
4)停止集群命令
[duo@hadoop01 ~]$ kafka_craft.sh stop
4、测试kafka-craft集群
创建topic:

生产数据:

消费数据:



