数据仓库Hive的安装和使用
一、试验目的要求
【实验要求】
- 完成Hive工具的安装和配置
- Hive.工具能够正常启动运行
- Hive控制台命令能够正常使用
- 能够正常操作数据库、表、数据
【实验目的】 - 掌握数据仓库工具Hive的安安装和配置
二、试验环境
- 五台独立PC机或虚拟机
- 主机之间有有效的网络连接
- 每台主机内存2G以上,磁盘剩余空间20G以上
- 已完成MySQL数据库平台搭建
- 在安装MySQL服务节点的PC机或虚拟机操作
- 软件版本:选用Hive的2.1.1版本,软件包名为apache-hive-2.1.1-bin.tar.bz
依赖软件 - Hive工具使用JDBC方式连接MySQL数据库,需要利用到MySQL数据库连接工具软件,选用该软件的5.1.42版本,软件包名为mysql-connector-java-5.1.42-bin.jar

三、试验内容
任务一 Hive工具安装和配置
注意:Hive安装过程的所有操作步骤都需要使用admin用户进行。
本项步骤只在集群中Cluster-01主机上进行操作即可。
1.# su admin
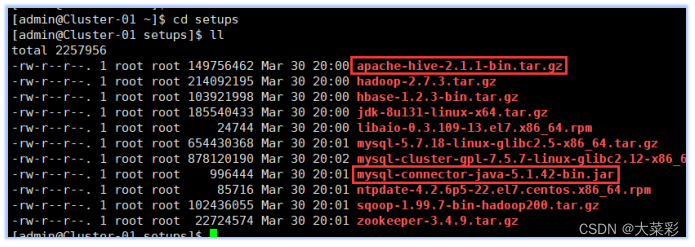
$ mkdir setups #我们以前创建过,如果提示已存在,则直接上传软件包即可,首先,我们把相关软件包apache-hive-2.1.1-bin.tar.gz和mysql-connector-java-5.1 .42-bin.jar上传到admin用户家目录的新建“setups"目录下。
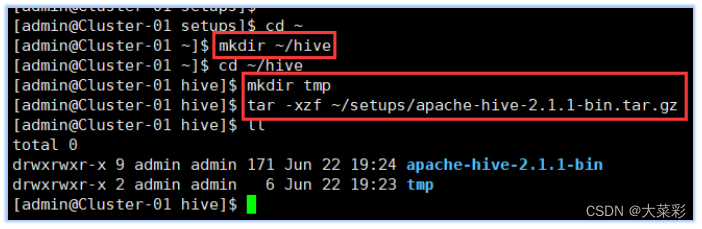
$ mkdir ~/hive #创建用于存放Hive相关文件的目录
$ cd ~/hive #进入该目录
$ mkdir tmp #创建Hive的本地临时文件目录“tmp’
$ tar -xzf ~/setups/apache-hive 2.1.1-bin.tar.gz #将软件包解压解包到“hive"目录下
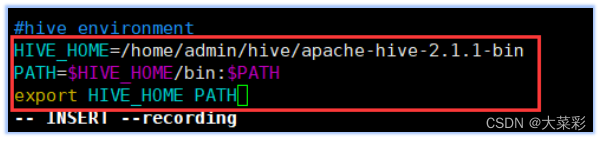
2. $ vi ~/.bash_ profile #配置Hive相关的环境变量

对配置文件进行修改,在文件末尾添加以下内容:
3. $ source ~/.brash_profile
$ echo $HIVE HOME
$ echo $PATH#查看新添加和修改的环境变量是否设置成功,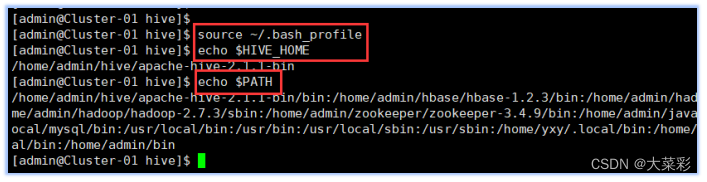
以及环境变量的值是否正确。
4. $ cd ~/hive/apache-hive-2.1.1-bin/conf #进 入Hive的配置文件目录
Hive的配置文件默认都被命名为了模板文件,需要对其进行拷贝重命名之后才能使用:
$ cp hive-env.sh.template hive-env.sh
$ cp hive-log4j2.properties.template hive-log4j2.properties
$ cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
$ cp hive-default.xml.template hive-site.xml

5. $ vi hive-env.sh#对配置文件进行修改,找到相关配置项并对其值进行修改
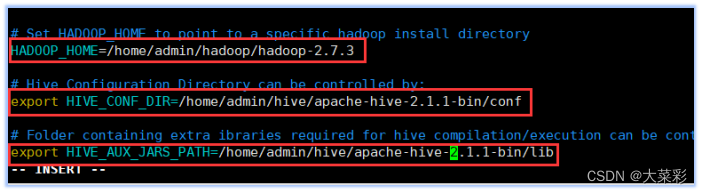
(1)找到配置项“HADOOP_ HOME”,该项用于指定Hadoop所在的路径,将其值改为以下内容:HADOOP_ HOME=/ home/ admin/hadoop/hadoop-2.7.3
(2)找到配置项“HIVE_ CONF_ DIR” ,该项用于指定Hive的配置文件所在的路径,将其值改为以下内容:
export HIVE_ CONF_ ,DIR=/home/admin/hive/apache-hive-2.1.1-bin/conf
(3)找到配置项“HIVE_ AUX JARS_ PATH ”该项用于指定Hive的lib文件所在的路径,将其值改为以下内容:
export HIVE_ AUX_ JARS_ _PATH=/home/admin/hive/apache-hive-2.1.1-bin/lib

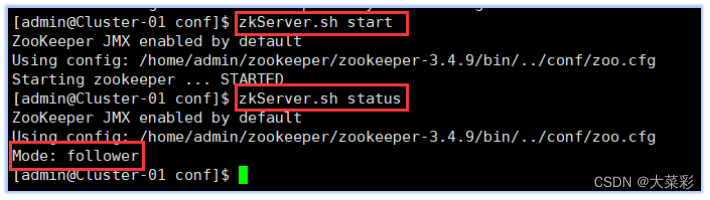
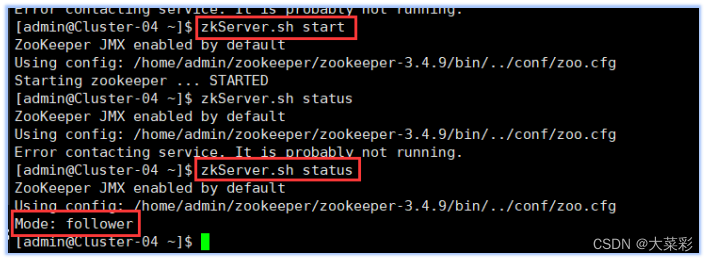
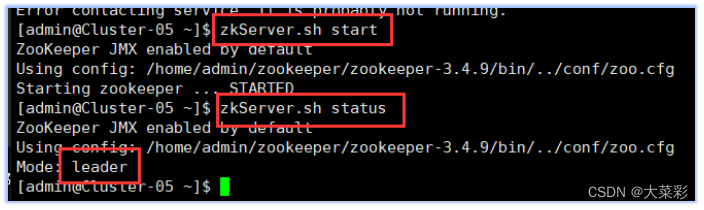
6.以下所有操作使用专门用于集群的用户admin进行。启动HBase集群之前首先确保Zookeeper集群已被开启状态。(实验5台 )Zookeeper的启动需要分别在每个计算机的节点上手动启动。如果家目录下执行启动报错,则需要进入zookeeper/bin目录执行启动命令。启动HBase集群之前首先确保Hadoop集群已被开启状态。(实验5台)Hadoop只需要在主节点执行启动命令。
(1)在集群中所有主机上使用命令“
z
k
S
e
r
v
e
r
.
s
h
s
t
a
t
u
s
,
若
集
群
中
只
有
一
个
“
l
e
a
d
e
r
”
节
点
,
其
余
的
均
为
“
f
o
l
l
o
w
e
r
”
节
点
,
则
集
群
的
工
作
状
态
正
常
。
否
则
执
行
zkServer.sh status,若集群中只有一个“leader” 节点,其余的均为“follower”节点,则集群的工作状态正常。否则执行
zkServer.shstatus,若集群中只有一个“leader”节点,其余的均为“follower”节点,则集群的工作状态正常。否则执行zkServer.sh start 在主节点上使用
s
t
a
r
t
?
a
l
l
.
s
h
,
在
备
用
节
点
上
执
行
y
a
r
n
?
d
a
e
m
o
n
.
s
h
s
t
a
r
t
r
e
s
o
u
r
c
e
m
a
n
a
g
e
r
命
令
。
(
2
)
在
主
节
点
,
查
看
J
a
v
a
进
程
信
息
,
若
有
名
为
“
N
a
m
e
N
o
d
e
"
、
“
R
e
s
o
u
r
c
e
M
a
n
a
g
e
r
”
的
两
个
进
程
则
表
示
H
a
d
o
o
p
集
群
的
主
节
点
启
动
成
功
。
在
每
台
数
据
节
点
,
若
有
名
为
“
D
a
t
a
N
o
d
e
"
和
“
N
o
d
e
M
a
n
a
g
e
r
"
的
两
个
进
程
,
则
表
示
H
a
d
o
o
p
集
群
的
数
据
节
点
启
动
成
功
。
(
3
)
在
主
节
点
上
执
行
start-all.sh,在备用节点上执行yarn-daemon.sh start resourcemanager命令。 (2)在主节点,查看Java进程信息, 若有名为“NameNode"、“ ResourceManager”的两个进程则表示Hadoop集群的主节点启动成功。在每台数据节点,若有名为“DataNode"和“NodeManager"的两个进程,则表示Hadoop集群的数据节点启动成功。 (3)在主节点上执行
start?all.sh,在备用节点上执行yarn?daemon.shstartresourcemanager命令。(2)在主节点,查看Java进程信息,若有名为“NameNode"、“ResourceManager”的两个进程则表示Hadoop集群的主节点启动成功。在每台数据节点,若有名为“DataNode"和“NodeManager"的两个进程,则表示Hadoop集群的数据节点启动成功。(3)在主节点上执行start-hbase.sh命令,使用“jps”查看,主机节点和备用节点若有“Hmaster”,数据节点若有“HResourceManger”表示Hbase启动成功。
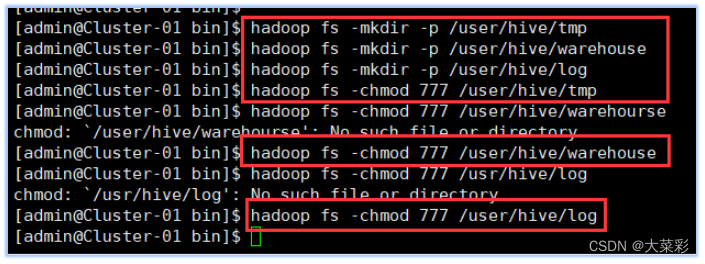
7. #在HDFS中分别创建Hive的“临时文件目录“tmp”
$ hadoop fs -mkdir -p /user/hive/warehouse #在HDFS中分别创建Hive的数据存储目录“warehouse"
$ hadoop fs -mkdir -P /user/hive/log #在HDFS中分别创建Hive的日志文件目录“log’
$ hadoop fs -chmod 777 /user/hive/tmp #添加三个目录的用户组写权限
$ hadoop fs -chmod 777 /user/hive/warehouse
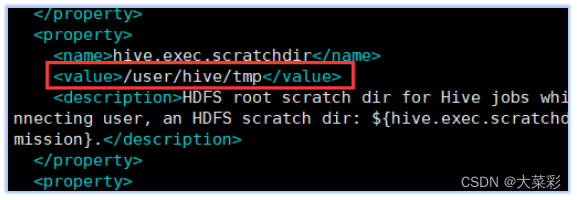
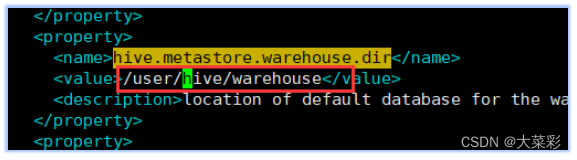
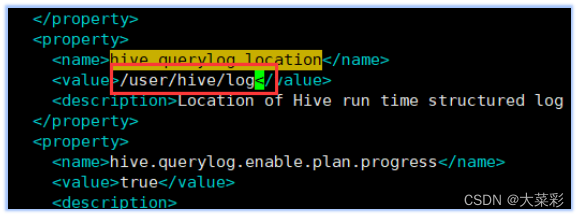
8.进入到该文件中,对配置文件进行修改

找到下面name所标识的属性,分别修改value标签中的值:
9.下面一步操作步骤需要在root用户进行。
在管理结点(cluster-01)上执行ndb_ mgmd -f /usr/local/mysql/etc/config.ini 命令
在数据节点(cluster-02,cluster-03)执行ndbd,
在SQL(cluster-04,cluster-05)结点执行service mysql start命令来开启MySql集群。



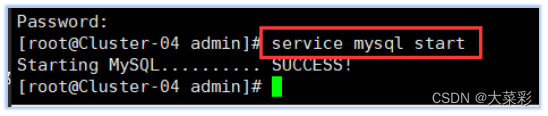

10.在集群中cluster-04主机上进行以下操作:
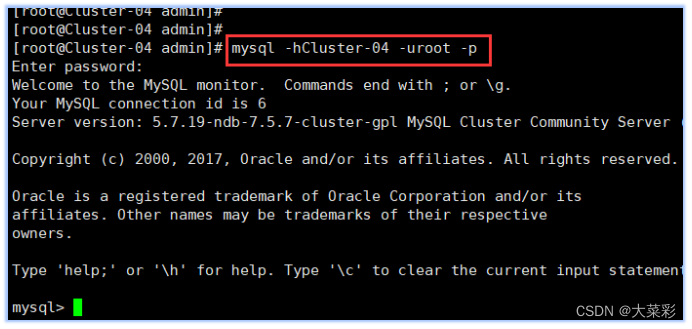
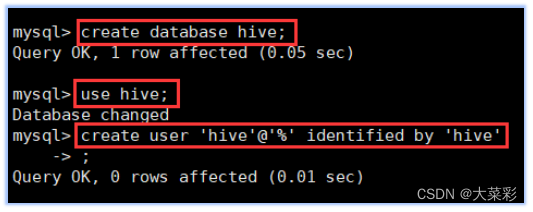
在控制台执行以下命令进行数据库的创建:
CREATE DATABASE hive; (创建数据库hive )
USE hive; (切换到新创建的hive数据库)
CREATE USER ‘hive’@‘%’ IDENTIFIED BY ‘hive’; (创建数据库用户hive)
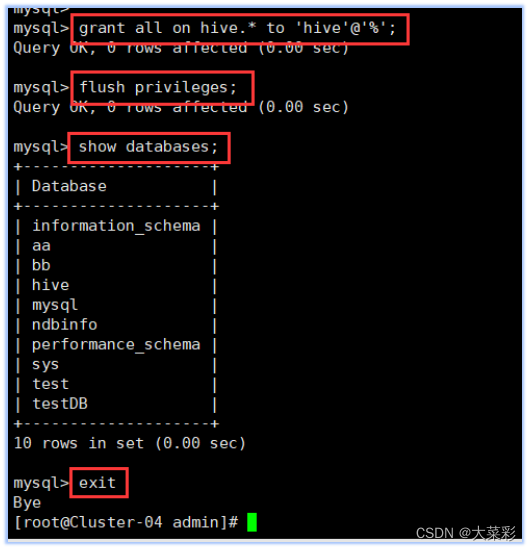
GRANT ALL ON hive.* TO ‘hive’@‘%’; (设置hive数据库的访问权限,hive用户拥有所有操作权限并支持远程访问)
FLUSH PRIVILEGES; (刷新数据库权限信息)
show databases:
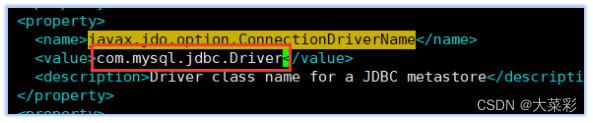
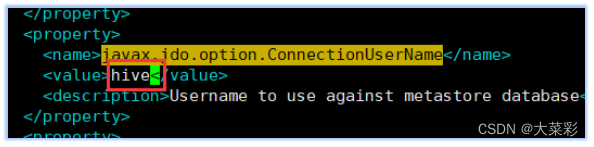
11.$ vi ~/hive/apache-hive 2.1.1-bin/conf/hive- site.xml.添加MySQL连接的相关配置文件。


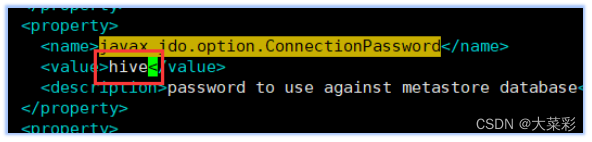
12.将MySQL的数据库连接工具包添加到Hive的“lib”目录下。

13.添加MYSQL连接的相关配置信息。



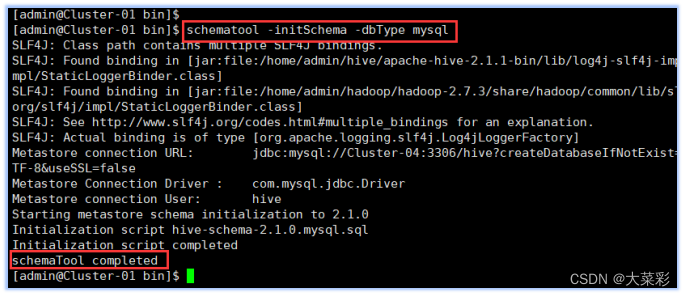
14.对Hive进行初始化
任务二 Hive工具启动和验证
注意:Hive安装过程的所有操作步骤都需要使用admin用户进行。
本项步骤只在集群中Cluster-01主机上进行操作即可。
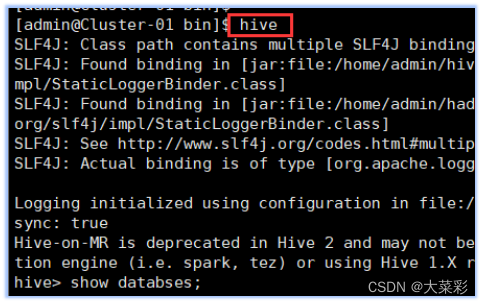
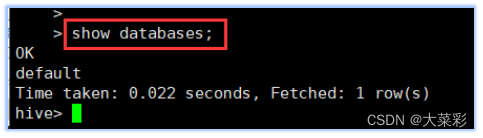
1.启动Hive,并查看当前的数据库列表。
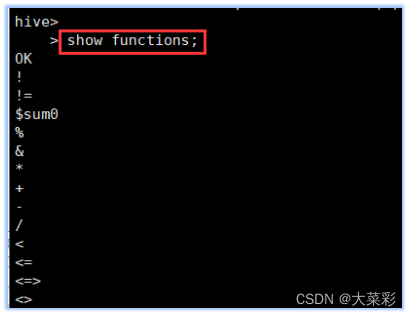
2.查看Hive的功能函数。
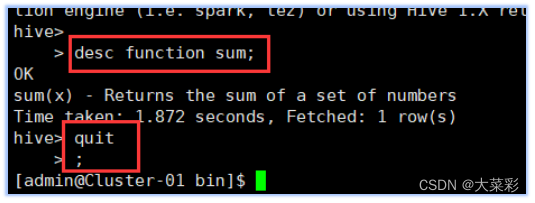
3.查看Hive的功能函数的详细信息。
4.退出hive
四、心得体会
1.正式试验前进行理解与预习,了解实验原理和实验目的。在老师讲解时认真听讲抓住重点并相应的做笔记简介记住主要过程,否则在真正实验时会出现思路不清晰而导致增加难度,浪费时间。
2.做实验时,一定要亲力亲为,务必要将每个步骤,每个细节弄清楚。当出现问题时要沉稳理智,先检查是不是由于粗心大意导致的简单问题;若不是则上网进行搜索,尽可能的自己解决;若还未解决则和周围同学商量、互帮互助的完成实验;实在没有向老师求助。试验结束后整理自己碰到的问题及解决办法,避免同样的问题再次出错。
3. 遇到问题或失败时,要一遍遍地反复去尝试,摸索,排错的过程也是学习的过程。而且这样获得的知识比从书本上直接获取来的知识印象更加深刻。
4.对于别人的建议,要有质疑精神。自己需要认真分析过后,判断它是正确的再采纳。不能盲目地随波逐流,以免给自己带来更多的麻烦。
5.写实验报告时要尽可能的详细精确,这个过程是理清思路再次深度学习的过程,要充分回想当时碰到的问题及解决方案,将每个步骤原理及过程弄清楚,充分的反映到报告上。
通过这次实验,使我不但对所学的理论知识有了更深刻的理解和加深,而且对于动手动脑能力也有了提高,也充分认识到了在遇到问题时要反复尝试,摸索,尽全力的自己解决,这次实验使我收获颇深!

