�ճ�ʹ�õ�Hive��Pig��Cascading�ײ���㶼����MapReduce���
�û�Ҳ���Բ�ʹ����Щ����,ֱ��ʹ��MapReduceִ������,MapReduce���ṩJAVA API,Ҳ�ṩHadoop Streaming��Hadoop Pipes��֧���������ԵĿ���
��ϵ��������Ҫ����MapReduce�����ԭ��:
��һƪҪ����MapReduce���²�����(����HDFS�洢�ܹ���Hadoop�ṩ��RPC����)�Լ�MapReduce�����ܺ����̵ļ�Ҫ����
�ڶ�ƪ��Ҫ����MapReduce��ʵ��ԭ��,����MapReduce�ĸ����������ҵ�����й���
������Ҫ�ǡ�Hadoop������Ļ:�������MapReduce�ܹ������ʵ��ԭ�����鼮�ıʼ�,�����Ȿ�鲻̫�Ƽ�,�о��������Ƽ�Ҳ�ܶ�ļ�����鼮����һ�������(������leader�Ƽ�����,����������Ҳ�Ƚ����,�Ͷ���,֮������ٿ�����û�и��õĿ����������)
- �����ֱȽ϶�,��ʱ���Ѿ���Ӱ���Ķ���
- ���ǰ�����ﲻһ��,���о�������������
- ���Բ�̫�Ͻ�,һЩ�״γ��ֵĸ���û�н���
- һЩ�½ڻ���ˡ�֪����Ȼ,��֪��������Ȼ���ĸо�,�½���ƺ�������û��̫˳
- ��֮,���Ƕ���ʱ����Ҫ��������鼮���߲���һ�����������
һ��HDFS�洢
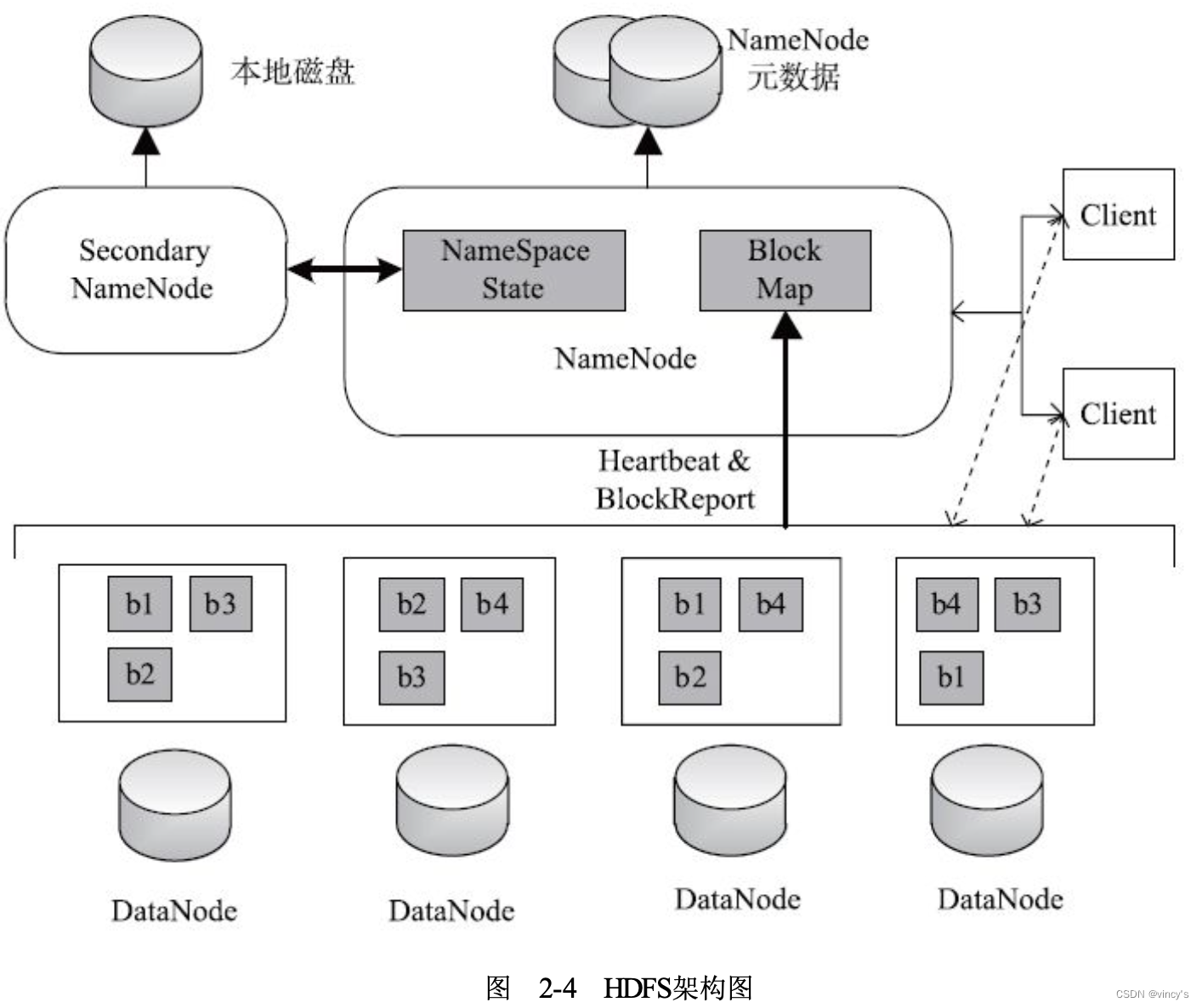
HDFS��master-slave(NameNode-DataNode)�ܹ�:
-
Client:�û�ʹ��HDFS�Ľӿ�
-
NameNode:һ��HDFS��Ⱥֻ��һ��NameNode
- �洢ȫ���ļ�Ԫ����,����fsimage(Ԫ���ݾ����ļ�)��editlog(�ļ��Ķ���־)
- ���DataNode�Ľ���״̬,DataNode崻���ʱ����
-
Secondary NameNode:���ںϲ�fsimage��editlog,��checkpoint
-
DataNode:һ��Slave�ڵ���һ��DataNode
- ����ʵ�ʵ����ݴ洢:�������з�Ϊ���block,һ��block 64M,һ��blcok����ˮ�ߵķ�ʽд�����ɸ�DataNode��,�и�������û�����,split���Ļ����,��map task���

- ������NameNode�㱨������Ϣ
����MapReduce����
1. MapReduce����ܹ�

MapReduce��Master-Slave(JobTracker-TaskTracker)�ܹ�
- Client:�û��ύ��ҵ,�����ҵ,һ����ҵ��һ��Job
- JobTracker
- ���TaskTracker�Ľ���״̬,���������,��ʱ����ҵת���������ڵ�
- ����TaskTracker����Դʹ�ú���ҵ����,����TaskScheduler
- TaskScheduler�����������,��һ���ɲ��ģ��
- TaskTracker
- ����ִ������Ľڵ�,����JobTracker����,ɱ��/�����ڵ�
- һ��TaskTracker���ж��slot(CPU���ڴ���Դ)
- MapTask
- ��HDFS��ȡinput block,ÿ��Map Task��ȡһ��split(DataNode�洢ͼ�г��ֹ�)������
- ��ÿһ��splitִ���û������map����,ִ�н���ֳ����ɸ�partition,�洢�����ش���,һ��partition��һ��reduce task����
- ReduceTask
- ��ȡMapTask�ļ�����(Shuffle��)
- ����ȡ��key-value����(Sort��)
- ִ���û������reduce����,������洢��HDFS��(Reduce��)
2. MapReduce����ģ��

ʹ��MapReduce,��Ҫ����5�����,�¸�С�ڻ���ϸ����
- InputFormat:�����ʽ,���ݷ�Ƭ��
- Mapper:��Ӧͼ��map task
- Partitioner:��Ӧͼ��group by sorting ��Ӧ�ĸ�key-value�����ĸ�reduce task
- Reducer:��Ӧͼ��reduce task
- OutputFormat:�����ʽ
- Canbiner:�Ż�MapReduce���� ���DZر����
˼��
-
���ʹ��MapReduce���top-k����:��ѯ����Ƶ����ߵ�k������
�����ݼ���Ϊ������ݿ�,ÿ�����ݿ�����һ��map task
map task1:ͳ�Ƹ������ʳ��ֵ�Ƶ��
reduce task1:���ܸ������ʳ��ֵ�Ƶ��
�C
ÿ��map task2��Ӧһ��reduce task1
map task2:�������Ƶ����ߵ�k������
reduce task2:����Ѷ��map task����ĵ��ʻ������������ǰk������ -
���ʹ��MapReduce���K-means����:��N������ΪK������
���ѡ��K������Ϊ��������ĵ�
map task:����ÿ���ڵ㵽K�����ĵ�ľ���,��ѡ����������ĵ���Ϊ�����һԱ
reduce task:����ÿ�������ƽ������,��ΪK�����ĵ�
�ظ�map-reduce����ֱ�������ظ��������ݵ㵽���ĵ�ľ������С -
���ʹ��MapReduce���Fibonacci��ֵ����
�����
����
���������⻮�ֳ����ɸ�����ص�������,����ʹ��MapReduce���
map task��reduce task��������ʲô?
���潫��ϸ������5�����
3. MapReduce���ģ��
���潫��ϸMapReduce�����Ҫ5�����:InputFormat��Mapper��Partitioner��Reducer��OutputFormat
-
InputFormat
��Ҫ����:�����������ݰ���ʲô���з�Ϊsplit,��ȷ��split�ĸ�����map task�ĸ���(ˢһ��split��Ӧһ��map task),ͬʱʵ��Ϊmap�����ṩ����,����ij��split,Ҫ���Է������split��Ӧ������-
�û��ӽ�:��Ҫ�ṩ����
goalSize:������ÿ��split��С=totalSize/numSplits,�ļ��ܴ�С/������split��Ŀ
minSize:split��С����Сֵ,Ĭ��1
blockSize:�洢ʱ�з��õ�block,���Ľ��ܹ� -
�ڲ��ӽ�:�����û��ṩ�IJ�������split��С,ѡ��host
- splitSize(split��С)=max{minSize, min{goalSize, blockSize}}
�ܺ�����,ÿ��split��С����ȡgoalSize,���Dz��ܳ���blockSize,����blockSize��ζ���ڶ��block��,�ͻ��ڶ��node��,ͬʱ��Ҫ���㳬����С��minSize,����û���ҪsplitSize����blockSize,��������minSize����blockSize - һ��inputSplit�����ڶ��block��,���Կ�����������ȫ����,�ѱ����Է�Ϊ:node locality,rack locality,data center locality(δʵ��)
- Ϊ���map task�ı�����,inputSplit��С�����blockSize���
- һ��inputSplit�ĺ�ѡhost�б�={������inputSplit����������ǰ�����ڵ�} ,��ʱ��ֻҪ��map task���ȵ��б���Ľڵ�,����Ϊ�����㱾����
- splitSize(split��С)=max{minSize, min{goalSize, blockSize}}
-
-
Mapper
������ʼ����Map���������������֡���ʼ������ʹ��jobConf�ij�ʼ��������Mapper��ʼ��;map()����key-value,���key-value��reporter;ͨ��Closeable�ӿڶ�Mapper�������� -
Partitioner
��Ҫ����:��Mapper�������м�����Ƭ,��ͬһ�����������ͬһ��Reducer(��һ��һ��Reducerֻ����һ����Ƭ),��Ƭ�����Ӱ�쵽Reducer�ĸ��ؾ���,MapReduce�ṩ�����ַ�Ƭ��ʽ:- HashPartitioner:��key��hashֵ�������ݻ��ֵ���һ��partition
- TotalOrderPartitioner:��keyֵ��С�������ֵ���һ��partition,��keyֵ��С�����֡������partition,��������ȫ���ֱ���Ҫ֪������keyֵ�ֲ�,���Բ��ó����ķ����鿴keyֵ�ֲ�,����������IntercalSampler��RandomSampler��SplitSampler��,����������n�ȷ�,�ҳ�n�ȷֵ�,ÿ��Mapper����������n�ȷֵ��Ƭ,ÿ��Reducer�Է�Ƭ�ٽ����ڲ�����,���Ϳ�������ȫ����
-
Reducer
��Mapperһ��,����Ŀ���û�ͨ������mapred.reduce.tasks(Ĭ����ĿΪ1)ָ��
������һ��������job(MapReduce��ҵ)����,���������չ,���ӵ�DAG(������ͼ)���
- ����Ƕ����������ϵ��job����ʹ��JobControlһ�����ύ���job,JobControl�ᰴ��job֮��������ϵ������ҵ����
- ����һ��Map��Reduce�δ��ڶ��Mapper(���ܴ��ڶ��Reducer),����ʹ��ChainMapper��ChainReducer
����Hadoop RPC
Hadoop RPC���û����¼�������Reactor���ģʽ,ʵ��ʹ�õ�NIO������+��̬�������ơ�Java�����̵�
1. Hadoop RPCʹ�÷���
�ⲿ��û̫��,������
// ����RPCЭ��ӿ�
interface ClientProtocol extends org.apache.hadoop.ipc.VersionedProtocol {
//�汾��,Ĭ�������,��ͬ�汾�ŵ�RPC Client��Server֮�䲻���ͨ��
public static final long versionID=1L;
String echo(String value)throws IOException;
int add(int v1,int v2)throws IOException;
}
// ʵ��RPCЭ��ӿ�
public static class ClientProtocolImpl implements ClientProtocol {
public long getProtocolVersion(String protocol, long clientVersion) {
return ClientProtocol.versionID;
}
public String echo(String value)throws IOException {
return value;
}
public int add(int v1,int v2)throws IOException {
return v1+v2;
}
}
// ���첢����RPC Server
server = RPC.getServer(new ClientProtocolImpl(), serverHost, serverPort, numHandlers, false, conf);
server.start();
// ����RPC Client
proxy = (ClientProtocol)RPC.getProxy(ClientProtocol.class, ClientProtocol.versionID, addr, conf);
int result = proxy.add(5,6);
String echoResult = proxy.echo("result");
��Hadoop��,JobTracker��NameNode�ֱ���MapReduce��HDFS������ϵͳ�е�RPC Server
2. MapReduce�е�����ͨ��Э��

- JobSubmissionProtocol:Client(�û�)��JobTracker��ͨ��Э��,�û��ύ��ҵ�������ҵ�������
// ��ҵ�ύ
public JobStatus submitJob(JobID jobName, String jobSubmitDir, Credentials ts)throws IOException;
/*��ҵ����*/
// ����ҵ���ȼ�
setJobPriority()
// ɱ��һ����ҵ
killJob()
// ɱ��һ������
killTask()
/*��ҵ���*/
// ��ȡ��Ⱥ��ǰ״̬,��slot����,�����������е�Task��Ŀ��
public ClusterStatus getClusterStatus(boolean detailed)throws IOException;
// ��ȡij����ҵ������״̬
public JobStatus getJobStatus(JobID jobid)throws IOException;
// ��ȡ������ҵ������״̬
public JobStatus[] getAllJobs()throws IOException;
- InterTrackerProtocol:TaskTracker��JobTracker��ͨ��Э��,�㱨�ڵ�ʹ������������������
/* method:TaskTracker��JobTracker�㱨�ڵ�ʹ������������������
** param:TaskTrackerStatus:��װ�����ڽڵ����Դʹ�����(�����ڴ�������ڴ����� ��ʹ����,CPU�����Լ������ʵ�)�������������(ÿ���������н���,״̬�Լ������Ľε�)
** return:HeartbeatResponse:������һ��TaskTrackerAction���͵�����,������JobTracker��TaskTracker����ĸ�������,��Ҫ��Ϊ���¼�������:
** ?CommitTaskAction:Task�������,�ύ������Ľ����
** ?ReinitTrackerAction:���¶��Լ�(TaskTracker)��ʼ����
** ?KillJobAction:ɱ��ij����ҵ,��������ʹ�õ���Դ��
** ?KillTaskAction:ɱ��ij������
** ?LaunchTaskAction:����һ��������
*/
// ����Ҫ��һ��ͨ��,����TaskTrackerֻ��ͨ��������ȡ����
HeartbeatResponse heartbeat(TaskTrackerStatus status, boolean restarted,boolean initialContact,boolean acceptNewTasks,short responseId) throws IOException;
// ��JobTracker�л�ȡij����ҵ�Ѿ���ɵ�Task�б�,����Ҫ��ΪReduce Task��ȡ����ɵ� Map Task�б�,�Ա㿪ʼԶ�̿���(shuffle)����
TaskCompletionEvent[]getTaskCompletionEvents(JobID jobid, int fromEventId ,int maxEvents)throws IOException;
// ��ȡJobTrackerָ����ϵͳĿ¼,�Ա�TaskTracker����ҵ��ص��ļ���ŵ���Ŀ¼��
public String getSystemDir();
// ��ȡJobTracker����汾��,TaskTracker��JobTracker����汾��һ�²ſ�����
public String getBuildVersion()throws IOException;
- TaskUmbilicalProtocol:Task��TaskTracker���ͨ��Э��,Task��ͬ�ڵ�TaskTracker���ӽ���
/*�����Ա����õķ���*/
// Task��TaskTracker�㱨�Լ��ĵ�ǰ״̬,״̬��Ϣ����װ��TaskStatus��,һ�������3s����һ��
boolean statusUpdate(TaskAttemptID taskId, TaskStatus taskStatus,JvmContext jvmContext)throws IOException, InterruptedException;
// Task������̽��TaskTracker�Ƿ���� ,���3s��Taskû���������,����Ҫ�ر�,�������
boolean ping(TaskAttemptID taskid, JvmContext jvmContext)throws IOException;
/*�������*/
// Task�յ�������ʱ,���ȴ����ӽ���,Ȼ���ӽ�����Ҫ����getTask��ȡTask
// Task�㱨�����쳣,reportDiagnosticInfo/fsError/fatalError�㱨Exception/FSError/Throwable,shuffleErroe�㱨Shuffle�γ��ֵĴ���
// Taskͨ��reportNextRecordRange������TaskTrack�㱨Ҫ�����ļ�¼��Χ
// ΪReduce Task�ṩ��getMapCompletionEvent������ȡMap Task������б�
// Task�������,�����commitPending, canCommit��done����
- RefreshUserMappingProtocol:Client(����Ա)�����û�-�û���ӳ���ϵ
- RefreshAuthorizationPolicyProtocol:Client(����Ա)����MapReduce����ķ��ʿ����б�,����Щ�û�����ʹ��JobSubmissionProtocolЭ��
- AdminOperationsProtocol:Client(����Ա)���¶��з��ʿ����б�(��Щ�û���������Щ�����ύ����)�ͽڵ��б�(���ýڵ�������ͺ�����)

