有三种方法,针对不同的情况。
方法一
数据库是新的,里面没有任何数据。这时的去重,是指在插入数据时,判断本次要插入的数据,是否在数据库中已存在。若存在,可以忽略本次的插入操作,或覆盖数据;若不存在,则插入。
原理
MongoDB的_id字段的值是唯一的(类似MySQL的主键),若不手动赋值,则会在插入数据库过程中自动生成。
MongoDB插入数据时会自动根据_id的值判断是否是重复数据,即数据库中是否有某条数据的_id和本次要插入的数据的_id相同,若发现重复数据,则本次插入操作会报错DuplicateKeyError。
以爬取电影信息为例,这里假设根据name和categories和score生成的md5是唯一的,即不会有其他电影与当前这个电影的name和categories和score同时一样(实际用时根据情况选择合适的字段),所以可以将这种方式生成的md5作为_id的值,从而实现插入数据时去重。
若接口返回的数据中自带id(或URL中有id,如csdn的文章链接中有当前文章的id,即/article/details/后面的一串数字),由于这个id是唯一的,也可以直接用这个id作为_id,但用这个id时若有重复数据,最好是覆盖,因同一篇文章id相同,但若文章内容更新了,再次爬取时就不能忽略本条数据,应该覆盖。
另外,MongoDB自己生成的_id,后面在用_id查询时,需from bson.objectid import ObjectId,查询条件写{'_id': ObjectId('6280b3f24f15c0da689726a7')};而若_id是自己用md5手动赋值的,则查询条件写{'_id': '7c97b08cde07182297fc5fc51435a498'}。根据MongoDB自动生成的_id查询时,只能用ObjectId();根据自己手动赋值的_id查询时,只能直接写_id的值。示例代码(Python3.8+)
import pymongo
import os
from bson.objectid import ObjectId
def start():
connection = pymongo.MongoClient(host=os.getenv('SPIDER_TEST_MongoDB_HOST'), port=27017, username=os.getenv("SPIDER_TEST_MongoDB_USER"), password=os.environ.get("SPIDER_TEST_MongoDB_PASSWORD"))
database = connection.movie
collection = database.movie_collection
return connection, collection
def test(collection):
if result1 := collection.find_one_and_delete({'_id': ObjectId('6280b3f24f15c0da689726a7')}):
print(result1)
if result2 := collection.find_one_and_delete({'_id': '7c97b08cde07182297fc5fc51435a498'}):
print(result2)
def end(connection):
connection.close()
if __name__=='__main__':
connection, collection = start()
test(collection)
end(connection)代码
以Scrapy为例,pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import os
import pymongo
import hashlib
from pymongo.errors import DuplicateKeyError
colorful_str_start = '\033[1;37;41m' # 彩色打印,也可以直接用RainbowPrint库 from https://www.cnblogs.com/easypython/p/9084426.html和https://www.cnblogs.com/huchong/p/7516712.html和https://zhuanlan.zhihu.com/p/136173259
colorful_str_end = '\033[0m'
class MongoDBPipeline:
def open_spider(self, spider):
self.connection = pymongo.MongoClient(host=os.getenv('SPIDER_TEST_MongoDB_HOST'), port=27017, username=os.getenv("SPIDER_TEST_MongoDB_USER"), password=os.environ.get("SPIDER_TEST_MongoDB_PASSWORD"))
database = self.connection.movie
self.collection = database.movie_collection
def process_item(self, item, spider):
item = dict(item)
temp_string = item['name'] + str(item['categories']) + str(item['score']) # 我拿到的item中部分数据是列表,为了拼接字符串,这里直接强制转为字符串,仅作示意
item['_id'] = hashlib.md5(temp_string.encode('utf-8')).hexdigest() # MongoDB的_id字段的值是唯一的(类似MySQL的主键),若不手动赋值,则会在插入数据库过程中自动生成。MongoDB插入数据时会自动根据_id的值判断是否是重复数据,即数据库中是否有某条数据的_id和本次要插入的数据的_id相同。这里假设根据name和categories和score生成的md5是唯一的,即不会有其他电影与当前这个电影的name和categories和score同时一样(实际用时根据情况选择合适的字段),所以可以将这种方式生成的md5作为_id的值,从而实现插入数据时去重。若接口返回的数据中自带id(或URL中有id,如csdn的文章链接中有当前文章的id,即/article/details/后面的一串数字),由于这个id是唯一的,也可以直接用这个id作为_id,但用这个id时若有重复数据,最好是覆盖,因同一篇文章id相同,但若文章内容更新了,再次爬取时就不能忽略本条数据,应该覆盖。
# MongoDB自己生成的_id,后面在用_id查询时,需from bson.objectid import ObjectId,查询条件写{'_id': ObjectId('6280b3f24f15c0da689726a7')};而若_id是自己用md5手动赋值的,则查询条件写{'_id': '7c97b08cde07182297fc5fc51435a498'}。根据MongoDB自动生成的_id查询时,只能用ObjectId();根据自己手动赋值的_id查询时,只能直接写_id的值。
try:
self.collection.insert_one(item)
except DuplicateKeyError: # 数据重复时可以忽略或覆盖
# 忽略重复数据
print(f'_id为{item["_id"]},name为 {item["name"]},数据库中已存在这条数据,所以{colorful_str_start}已忽略{colorful_str_end}本次的插入操作') # 打印当前数据的_id和name字段的值
'''
# 覆盖重复数据
print(f'_id为{item["_id"]},name为 {item["name"]},数据库中已存在这条数据,开始删除数据库中的这条数据')
self.collection.delete_one({'_id': item['_id']}) # 删除旧数据
self.collection.insert_one(item) # 插入新数据
print(f'_id为{item["_id"]},name为 {item["name"]},数据库中的这条旧数据已删除,且本次的新数据{colorful_str_start}已插入(覆盖){colorful_str_end}数据库')
'''
else:
return item
def close_spider(self, spider):
self.connection.close()除了上面的写法,还有一种写法,不同的是这种写法在插入重复数据时可能不能忽略,只能覆盖,参考链接1,参考链接2。
def process_item(self, item, spider):
item = dict(item)
temp_string = item['name'] + str(item['categories']) + str(item['score'])
item['_id'] = hashlib.md5(temp_string.encode('utf-8')).hexdigest()
self.collection.update_one({'_id': item['_id']}, {'$set': item}, upsert=True)def save_data(data):
? ? ? ? ? ? collection.update_one({
? ? ? ? ? ? ? ? 'name': data.get('name')
? ? ? ? ? ? }, {
? ? ? ? ? ? ? ? '$set': data
? ? ? ? ? ? }, upsert=True)在这里我们声明了一个save_data方法,它接收一个data参数,也就是我们刚才提取的电影详情信息。在方法里面,我们调用了update_one方法,第一个参数是查询条件,即根据name进行查询;第二个参数就是data对象本身,就是所有的数据,这里我们用$set操作符表示更新操作;第三个参数很关键,这里实际上是upsert参数,如果把这个设置为True,则可以做到存在即更新,不存在即插入的功能,更新会根据第一个参数设置的name字段,所以这样可以防止数据库中出现同名的电影数据。
注:实际上电影可能有同名,但该场景下的爬取数据没有同名情况,当然这里更重要的是实现MongoDB的去重操作。
方法二
?数据库中已有一部分数据,且不确定里面是否有重复数据,若有重复数据,需先删除重复数据,再插入新数据。
你可能想到MySQL和MongoDB的distinct,但pymongo的distinct返回的是针对某个字段的所有不同的值,如有3条数据,每条的name字段的值分别为张三、李四、张三,则集合.distinct(‘name’)的返回值是['张三', '李四']。它直接返回去重后的数据(且只能返回某个字段的所有值,不知道能不能返回所有字段的值,即返回所有数据),但数据库中原来的重复的数据还在。参考链接3。
另外,数据量大时,distinct会报错distinct too big, 16mb cap。参考链接4。
所以,aggregate更合适,pymongo文档1,pymongo文档2,MongoDB文档。
原理
aggregate先根据特定字段分组,可以是单个字段或多个字段,把这些字段当作整体(意思是,若有多个字段,需多个字段同时满足,也就是"且",字段1 且 字段2 且 字段3),只要这个整体是唯一的就行(意思上类似主键,如有三个字段'name'='小明','age'=10,'student_id'=123,同时满足这三个条件的学生,理论上应该只有一人。具体选取哪些字段,类似方法一中生成md5所需的字段,只要这些字段组合起来,能确定到一条唯一的数据就行)。
然后在分组结果中统计每个字段(还是看作整体)在数据库中出现的次数,即每个字段(还是看作整体)的数量,也就是每条数据的数量;若数量大于1,则表示当前字段所属的文档(即MongoDB中的document,对应MySQL中的一条数据),在数据库中有多条。
最后返回这些重复数据,它们在一个可迭代对象中。无论是否查到了重复数据,都返回这个可迭代对象,只是查不到数据时,后面通过遍历这个可迭代对象来删除重复数据没有意义(就像遍历空列表)。
这部分的原理,5,参考链接6,建议看这两个链接,里面有示例数据和语句执行流程图,同时还有与pymongo的写法对应的SQL语句,方便理解;若用它的示例数据,需手动转成json再导入MongoDB,形式是[{"":""},{"":""},{"":""}]。
拿到所有的重复数据后,只要遍历它们,再按你指定的条件删除就行,注意遍历时从第2个数据开始遍历(下标为1),因为要保留第一条数据,删除第一条数据之后的重复数据。
代码
注释相比原理更细致,但大体意思一样
import pymongo
import os
from tqdm import tqdm
def start():
connection = pymongo.MongoClient(host=os.getenv('SPIDER_TEST_MongoDB_HOST'), port=27017, username=os.getenv("SPIDER_TEST_MongoDB_USER"), password=os.environ.get("SPIDER_TEST_MongoDB_PASSWORD"))
database = connection.movie
collection = database.movie_collection
return connection, collection
def test(collection):
data = collection.aggregate([ # 返回分组($group)并筛选($match)后的数据,它们在一个可迭代对象中。无论是否查到了数据,都返回这个可迭代对象,只是查不到数据时,后面for循环中遍历这个可迭代对象没有意义(就像遍历空列表)。
{
'$group': # 用于根据给定的字段(即_id的值)进行分组,有多个字段时,意思是同时满足这些字段,即字段1 且 字段2 且 字段3
{
'_id': # '_id'可能是固定写法 from https://www.mongodb.com/docs/manual/reference/operator/aggregation/group/
{
'name': '$name', # 冒号前是自己起的名字,冒号后是对应的数据库中的字段的值
'categories': '$categories',
'score': '$score'
},
'count': # 统计满足前面设置的分组条件的数据出现的次数,自己起的名字
{'$sum': 1} # 满足分组条件的数据每出现一次,count的值就加1。若是{'$sum': 2},则每次count的值加2。from https://blog.csdn.net/jinyangbest/article/details/123225648和https://www.cnblogs.com/deepalley/p/12022381.html和https://www.it1352.com/1636882.html和https://www.jb51.net/article/168337.htm和https://stackoverflow.com/questions/17044587/how-to-aggregate-sum-in-mongodb-to-get-a-total-count和https://stackoverflow.com/questions/40791907/what-does-sum1-mean-in-mongo和https://www.mongodb.com/docs/manual/reference/operator/aggregation/sum/和https://www.mongodb.com/docs/v4.0/reference/operator/aggregation/sum/
}
},
{ # 筛选出count(前面定义的出现次数)的值大于1的数据,出现次数大于1说明当前数据在数据库中有重复
'$match':
{
'count': {'$gt': 1}
}
}
], allowDiskUse=True) # 避免出现超出内存阈值的异常
# print(type(data)) # pymongo.command_cursor.CommandCursor
for item in tqdm(iterable=list(data), ncols=100, desc='去重进度', colour='green'): # data本身是可迭代对象,但不转list的话,若数据库中有重复数据,则运行时tqdm的显示效果和list(data)的不同,list(data)能显示百分比和进度条和颜色,不转list不显示百分比和进度条和颜色,显示的是已去重的数据的数量;若数据库中没有重复数据,则转不转list都不显示百分比和进度条和颜色,只显示数量,且数量为0。
count = item['count'] # 本身就是int类型,后面在range()中用,这里不用强制转int()
name = item['_id']['name']
categories = item['_id']['categories']
score = item['_id']['score']
for _ in range(1, count): # 仅保留第一条数据,删除后面的重复数据,第二条数据的下标为1
collection.delete_one({ # 若数据库中某条数据的name、categories、score字段同时满足下面的条件,则删除该条数据
'name': name, # 冒号前是数据库中的字段名,冒号后是对应的数据库中的字段的值,这些值是从前面aggregate返回的可迭代对象中获取的
'categories': categories,
'score': score
})
def end(connection):
connection.close()
if __name__=='__main__':
connection, collection = start()
test(collection)
end(connection)
?方法三
适用情况和方法一相同。
Crawlab自带去重,文档-爬虫-结果去重。
注意:由于 Crawlab 是需要储存在对应的 MongoDB 中的,因此在去重之前,需要在爬虫中注明 "结果集",也就是对应的表名。
覆盖去重
覆盖去重顾名思义,就是将老的数据覆盖掉,保证数据的唯一性,从而达到去重的目的。
其具体原理和步骤如下:
- 根据 "去重" 字段找到新数据对应的老数据,并将老数据删除;
- 将新数据插入到 "结果集" 中。
忽略去重
忽略去重比覆盖去重简单,其具体原理如下:
- 根据 "去重" 字段找到新数据对应的老数据;
- 如果存在老数据,则忽略,不插入;
- 如果不存在老数据,则插入。
去重字段
"去重字段" 其实相当于结果集的主键(虽然 MongoDB 中的主键永远是?
_id),多条同一个主键的数据是不允许的。如果 Crawlab 的去重逻辑打开,则会在该结果集中的 "去重字段" 上创建一个唯一索引,保证数据的唯一性,同时保证查找数据的效率。
如果你在Crawlab运行scrapy爬虫,可以先看这篇文章,再结合本文的方法三,也能实现去重。不过运行前要做如下设置

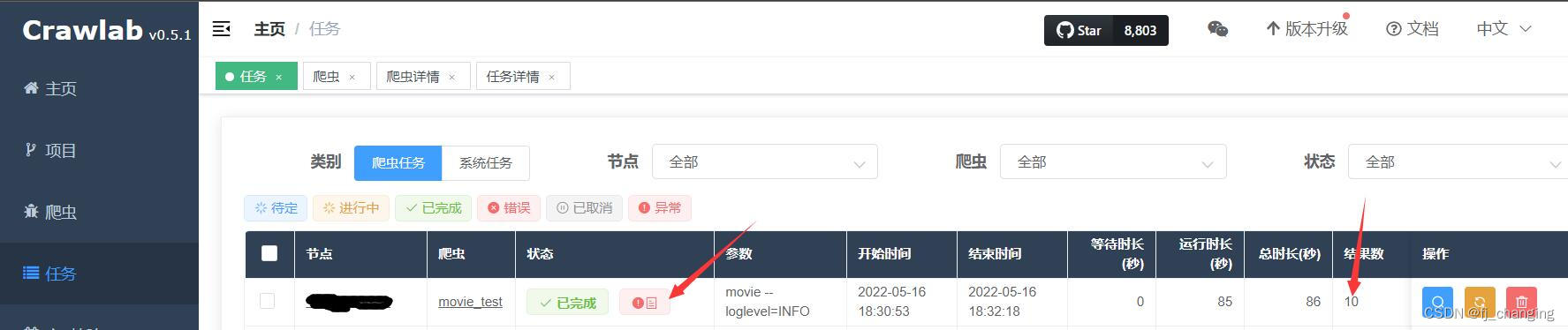
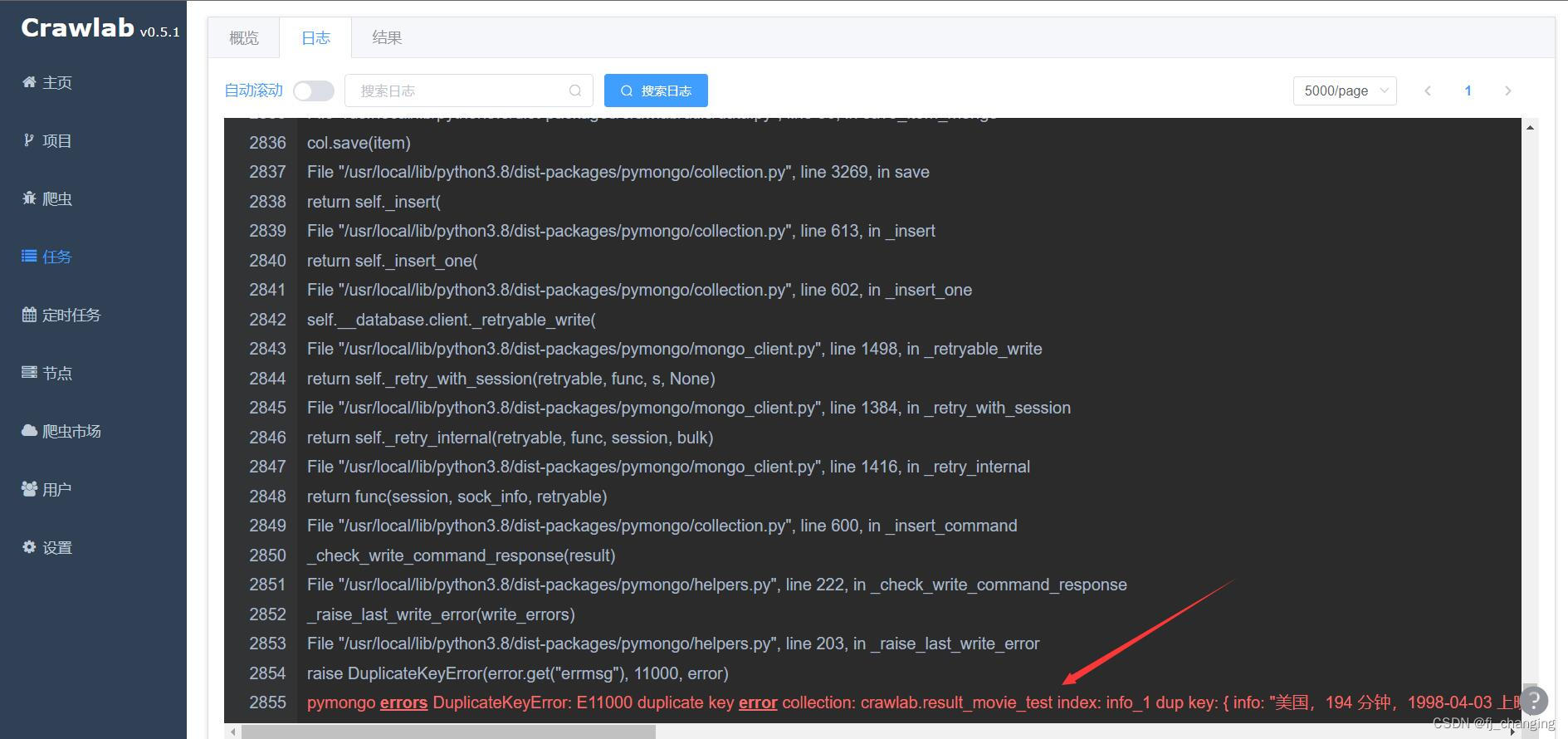
?注意,去重规则选忽略时,运行爬虫时有报错pymongo errors DuplicateKeyError: E11000 duplicate key error collection:,不用管这个报错,原因可能是忽略时Crawlab内部没捕获处理这个错误,或者处理方式就是抛出。可以在任务页查看爬虫的结果数对不对,如共爬取100条,数据库中已有90条,则结果数应该是10,然后去数据库里看,数据库里应该是100条。去重规则选覆盖时,没这个问题。
参考链接
MongoDB:PyMongo百万级数据去重_苏寅的博客-CSDN博客_pymongo 删除重复
爬虫中的去重处理方法详解_拒绝者zzzz的博客-CSDN博客_爬虫去重
「2022 年」崔庆才 Python3 爬虫教程 - 高效实用的 MongoDB 文档存储 (baidu.com),MongoDB基本使用
Query and Projection Operators ― MongoDB Manual,MongoDB中一些运算符

