���ݵ���
����
����
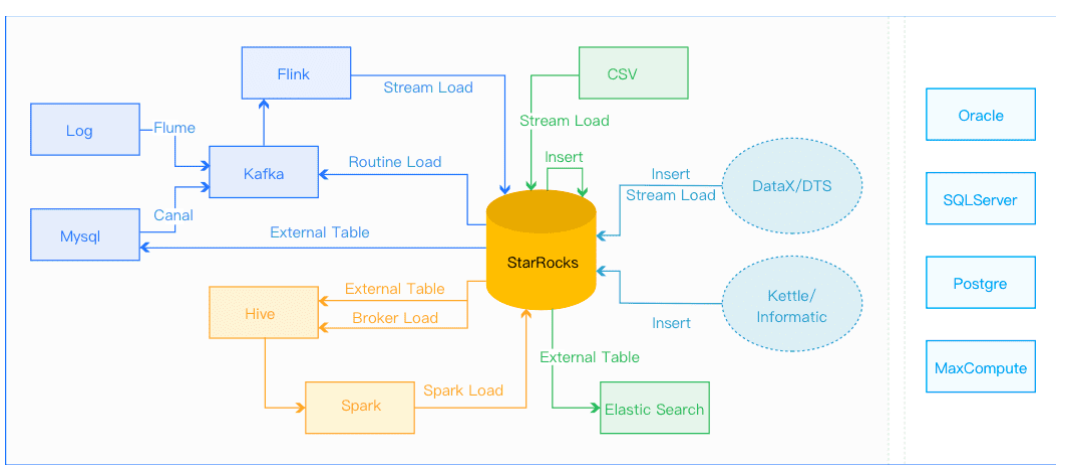
���ݵ��빦���ǽ�ԭʼ���ݰ�����Ӧ��ģ�ͽ�����ϴת�������ص�StarRocks��,�����ѯʹ�á�StarRocks�ṩ�˶��ֵ��뷽ʽ,�û����Ը�����������С������Ƶ�ʵ�Ҫ��ѡ�����ʺ��Լ�ҵ������ĵ��뷽ʽ��
- �������ݵ���,�������Դ��Hive/HDFS,�Ƽ�����Broker Load����, ������ݱ��ܶർ��Ƚ��鷳���Կ���ʹ��Hive���ֱ����ѯ,���ܻ��Broker load����Ч����,���ǿ��Ա������ݰ�Ǩ,����������������ر��,������Ҫ��ȫ�������ֵ�����ȷȥ�ؿ��Կ���Spark Load���롣
- ʵʱ���ݵ���,��־���ݺ�ҵ�����ݿ��binlogͬ����Kafka�Ժ�,�����Ƽ�ͨ��Routine load ����StarRocks,�������������и��ӵĶ��������ETLԤ��������ʹ��Flink�����Ժ���stream loadд��StarRocks,�����б���Flink-connector���Է���Flink����ʹ�á�
- ����д��StarRocks,�Ƽ�ʹ��Stream Load,���Բο���������Java/Python��demo��
- �ı��ļ������Ƽ�ʹ�� Stream load
- Mysql���ݵ���,�Ƽ�ʹ��Mysql���,insert into new_table select * from external_table �ķ�ʽ����
- ��������Դ����,�Ƽ�ʹ��DataX����,�����ṩ��DataX-starrocks-writer
- StarRocks�ڲ�����,������StarRocks�ڲ�ʹ��insert into tablename select�ķ�ʽ����,���Ը��ⲿ���������ʵ�ּ�ETL������
- �û�����ͨ�����ò��������Ƶ���������ҵ���ڴ�ʹ��,�Է�ֹ����ռ�ù�����ڴ������ϵͳOOM��
����ԭ��
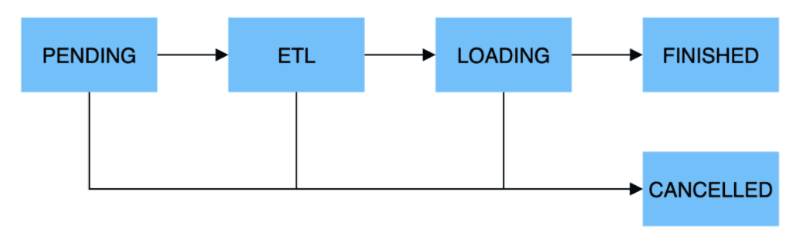
����ִ������,һ��������ҵ��Ҫ��Ϊ5����:
- PENDING:�DZ��롣�ý���ָ�û��ύ������ҵ��,�ȴ�FE����ִ�С�Broker Load��Spark Load�����ò��衣
- ETL:�DZ��롣�ý�ִ�����ݵ�Ԥ����,������ϴ�����������ۺϵȡ�Spark Load�����ò���,��ʹ���ⲿ������ԴSpark���ETL��
- LOADING:�ý��ȶ����ݽ�����ϴ��ת��,Ȼ�����ݷ���BE������������ȫ�������,����ȴ���Ч����,��ʱ������ҵ״̬������LOADING��
- FINISHED:�ڵ�����ҵ�漰���������ݾ���Ч��,��ҵ��״̬��� FINISHED,FINISHED��������ݾ��ɲ�ѯ��FINISHED�ǵ�����ҵ������״̬��
- CANCELLED:�ڵ�����ҵ״̬��ΪFINISHED֮ǰ,��ҵ��ʱ���ܱ�ȡ��������CANCELLED״̬,���û��ֶ�ȡ��������ִ���ȡ�CANCELLEDҲ�ǵ�����ҵ��һ������״̬��
ͬ�����첽
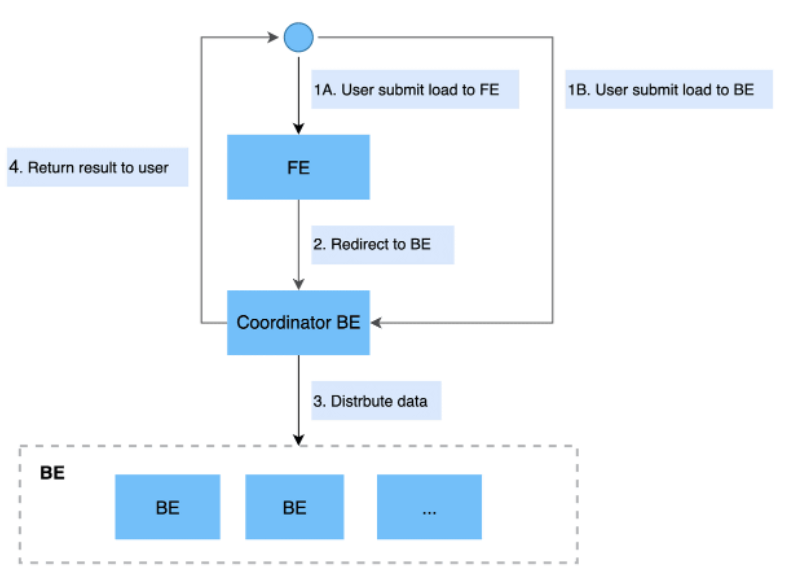
- ͬ������
- ͬ�����뷽ʽ���û�������������,StarRocks ͬ��ִ��,ִ����ɺص��������û���ͨ���ý���жϵ����Ƿ�ɹ���
- ͬ�����͵ĵ��뷽ʽ��:Stream Load,Insert��
- �첽����
- �첽���뷽ʽ���û��������������,StarRocksֱ�ӷ��ش����ɹ��������ɹ������������Ѿ�����ɹ�����������ᱻ�첽ִ��,�û��ڴ����ɹ���,��Ҫͨ����ѯ�ķ�ʽ���Ͳ鿴����鿴������ҵ��״̬���������ʧ��,����Ը���ʧ����Ϣ,�ж��Ƿ���Ҫ�ٴδ�����
- �첽���͵ĵ��뷽ʽ��:Broker Load, Spark Load��
ʹ�ó���
- HDFS����:Դ���ݴ洢��HDFS��,������Ϊ��ʮGB���ϰ�GBʱ,�ɲ���Broker Load������StarRocks�������ݡ�Դ���ݴ洢��HDSF��,�������ﵽTB����ʱ,�ɲ���Spark Load������StarRocks�������ݡ�
- �����ļ�����:���ݴ洢�ڱ����ļ���,������С��10GB,�ɲ���Stream Load���������ݿ��ٵ���StarRocksϵͳ��
- Kafka����:����������Kafka����ʽ����Դ,��Ҫ��StarRocksϵͳ����ʵʱ����ʱ,�ɲ���Routine Load������
- Insert Into����:�ֹ����Լ���ʱ���ݴ���ʱ����ʹ��
Insert Into������StarRocks����д�����ݡ�
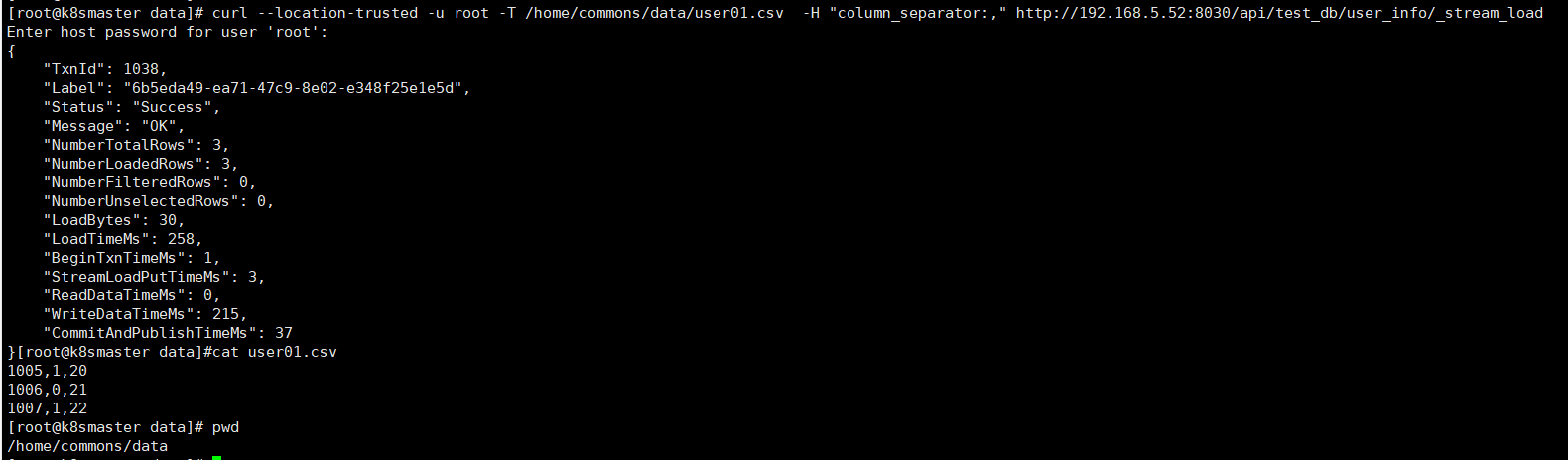
Stream load
- StarRocks֧�ִӱ���ֱ�ӵ�������,֧��CSV�ļ���ʽ����������10GB���¡�
- Stream Load ��һ��ͬ���ĵ��뷽ʽ,�û�ͨ������ HTTP �������ļ������������뵽 StarRocks �С�
- Stream Load ͬ��ִ�е��벢���ص��������û���ֱ��ͨ������ķ���ֵ�жϵ����Ƿ�ɹ���
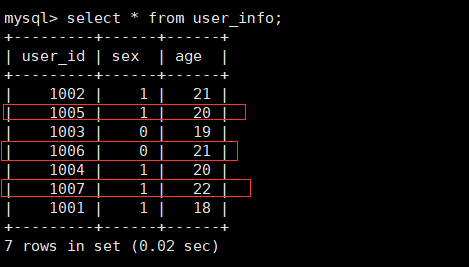
�����ݲ���ǰ���Ѵ����õ�user_info��
curl --location-trusted -u root -T /home/commons/data/user01.csv -H "column_separator:," http://192.168.5.52:8030/api/test_db/user_info/_stream_load
# Ҳ����ͨ��-H "label:labelname"���ñ�ǩ����
Broker Load
- StarRocks֧�ִ�Apache HDFS��Amazon S3���ⲿ�洢ϵͳ��������,֧��CSV��ORCFile��Parquet���ļ���ʽ���������ڼ�ʮGB���ϰ�GB ����
- ��Broker Loadģʽ��,ͨ�������Broker����,StarRocks�ɶ�ȡ��Ӧ����Դ(��HDFS, S3)�ϵ�����,���������ļ�����Դ�����ݽ���Ԥ�����͵��롣����һ���첽�ĵ��뷽ʽ,�û���Ҫͨ��MySQLЭ�鴴������,��ͨ���鿴���������鵼������
������Ҫ�Ȳ����Broker,���������� hdfs ����,�������ϵ� hdfs-site.xml �� Broker��conf Ŀ¼��,��hdfs-site.xml�ַ�����̨Broker�ڵ��conf Ŀ¼, ��������Broker,�����������ǰ�û�������
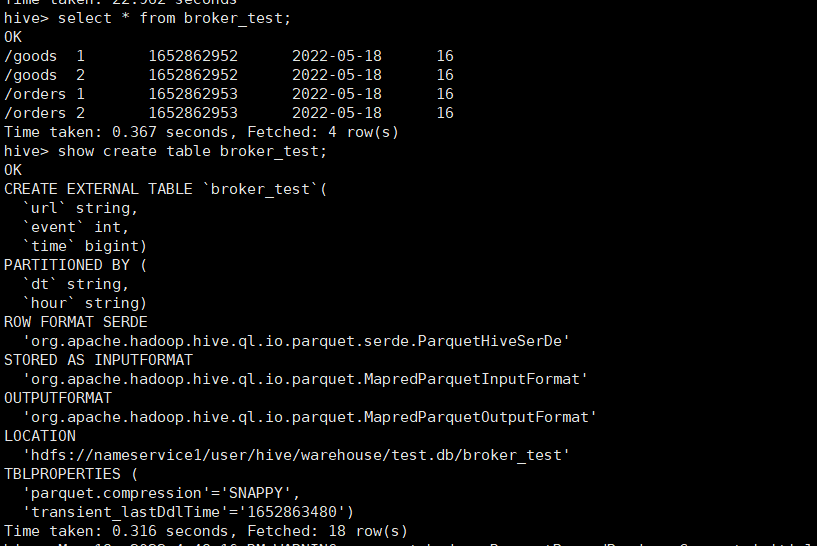
��HIve�д���broker_test,���ҵ�������
CREATE EXTERNAL TABLE broker_test(
`url` string,
`event` int,
`time` bigint)
PARTITIONED by (
`dt` string,
`hour` string)
ROW FORMAT DELIMITED
STORED AS PARQUET
TBLPROPERTIES('parquet.compression'='SNAPPY');
insert into broker_test PARTITION(dt='2022-05-18',hour='16')
values ('/goods',1,1652862952),
('/goods',2,1652862952),
('/orders',1,1652862953),
('/orders',2,1652862953);
ִ�в鿴���,hive����������
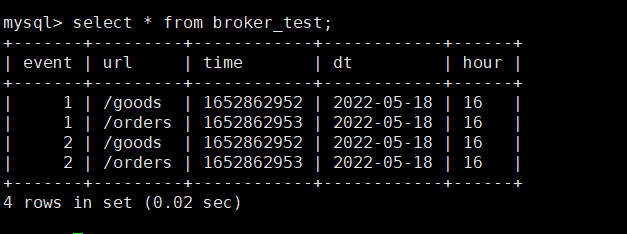
��StarRocks��test_db���ݿ���Ҳ������broker_test
CREATE TABLE IF NOT EXISTS broker_test (
url DATETIME ,
event INT ,
time BIGINT,
dt varchar(20),
hour varchar(20)
)
DUPLICATE KEY(url)
DISTRIBUTED BY HASH(url) BUCKETS 8;
StarRocks��test_db���ݿ�Ҳ����broker_test_label1
LOAD LABEL broker_test_label1
(
DATA INFILE("hdfs://nameservice1/user/hive/warehouse/test.db/broker_test/dt=2022-05-18/hour=16/*")
INTO TABLE broker_test
FORMAT AS "parquet"
(url,EVENT,TIME)
SET
(
url=url,
EVENT=EVENT,
TIME=TIME,
dt='2022-05-18',
HOUR='16'
)
)
WITH BROKER 'broker1'
PROPERTIES
(
"timeout" = "3600"
);
Broker Load�������첽��,�û�������SHOW LOAD������ָ��Label����ѯ��Ӧ������ҵ��ִ��״̬,��ѯ���Job�Ѿ����
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-1sfUd01g-1652972070699)(http://www.itxiaoshen.com:3001/assets/1652866964727KZ3cc7Bz.png)]
�鿴StarRocks��test_db���ݿ��broker_test,4�������Ѿ�����������
Routine Load
��һ������ Kafka ��Ⱥ���� CSV ����,����ROUTINE LOAD������
CREATE TABLE IF NOT EXISTS site_test (
site_id INT,
event_type INT
)
DUPLICATE KEY(site_id)
DISTRIBUTED BY HASH(site_id) BUCKETS 8;
CREATE ROUTINE LOAD routine_load_site_test ON site_test
COLUMNS TERMINATED BY ",",
COLUMNS (site_id, event_type)
PROPERTIES
(
"desired_concurrent_number" = "3",
"max_batch_interval" = "5000",
"max_error_number" = "1000"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.12.27:9092,192.168.12.28:9092,192.168.12.29:9092",
"kafka_topic" = "site_test",
"property.kafka_default_offsets" = "OFFSET_BEGINNING"
);
ʹ��kafka�������߳�����site_test��Topic��������,Ҳ֧��Json��ʽ,������������json���á�
CREATE ROUTINE LOAD routine_load_site_test ON site_test
COLUMNS TERMINATED BY ",",
COLUMNS (site_id, event_type)
PROPERTIES (
"format"="json",
"json_root"="$.data",
"desired_concurrent_number"="1",
"strip_outer_array" ="true",
"max_error_number"="1000"
)
FROM KAFKA (
"kafka_broker_list"= "192.168.12.27:9092,192.168.12.28:9092,192.168.12.29:9092",
"kafka_topic" = "site_test"
);
ʹ�� flink-connector-starrocks ������ StarRocks
StarRocks �ṩ flink-connector-starrocks,���������� StarRocks,����� Flink �ٷ��ṩ�� flink-connector-jdbc,�������ܸ��ѡ� flink-connector-starrocks ���ڲ�ʵ����ͨ�����沢������ stream load ���롣
Flink DataStream APIʾ��
����ʹ����һƪ�����õ�article�����������,����flink-demo����,Pom�ļ�����
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.itxs</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.4</flink.version>
<scala.version>2.12</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<version>1.2.1_flink-1.14_2.12</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>1.13.6</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table</artifactId>
<version>${flink.version}</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
</project>
����DataStream APIʾ��StarRocksDataStreamDemo.java
package starrocks;
import com.google.gson.Gson;
import com.starrocks.connector.flink.StarRocksSink;
import com.starrocks.connector.flink.table.sink.StarRocksSinkOptions;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
public class StarRocksDataStreamDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StarRocksDataStreamDemo starRocksDataStreamDemo = new StarRocksDataStreamDemo();
starRocksDataStreamDemo.useStream(env);
env.execute();
}
public void useStream(StreamExecutionEnvironment env){
Gson gson = new Gson();
DataStreamSource<String> ds = env.fromCollection(Arrays.asList(gson.toJson(new Article(1, 1, 1, "flink")),
gson.toJson(new Article(2, 2, 2, "java")),
gson.toJson(new Article(3, 3, 3, "starrocks"))));
ds.addSink(
StarRocksSink.sink(
// the sink options
StarRocksSinkOptions.builder()
.withProperty("jdbc-url", "jdbc:mysql://192.168.5.52:9030")
.withProperty("load-url", "192.168.5.52:8030")
.withProperty("username", "root")
.withProperty("password", "")
.withProperty("table-name", "article")
.withProperty("database-name", "test_db")
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
.build()
)
);
}
}
��������main����ǰ�����������й���Include dependencies with ��Provided�� scope
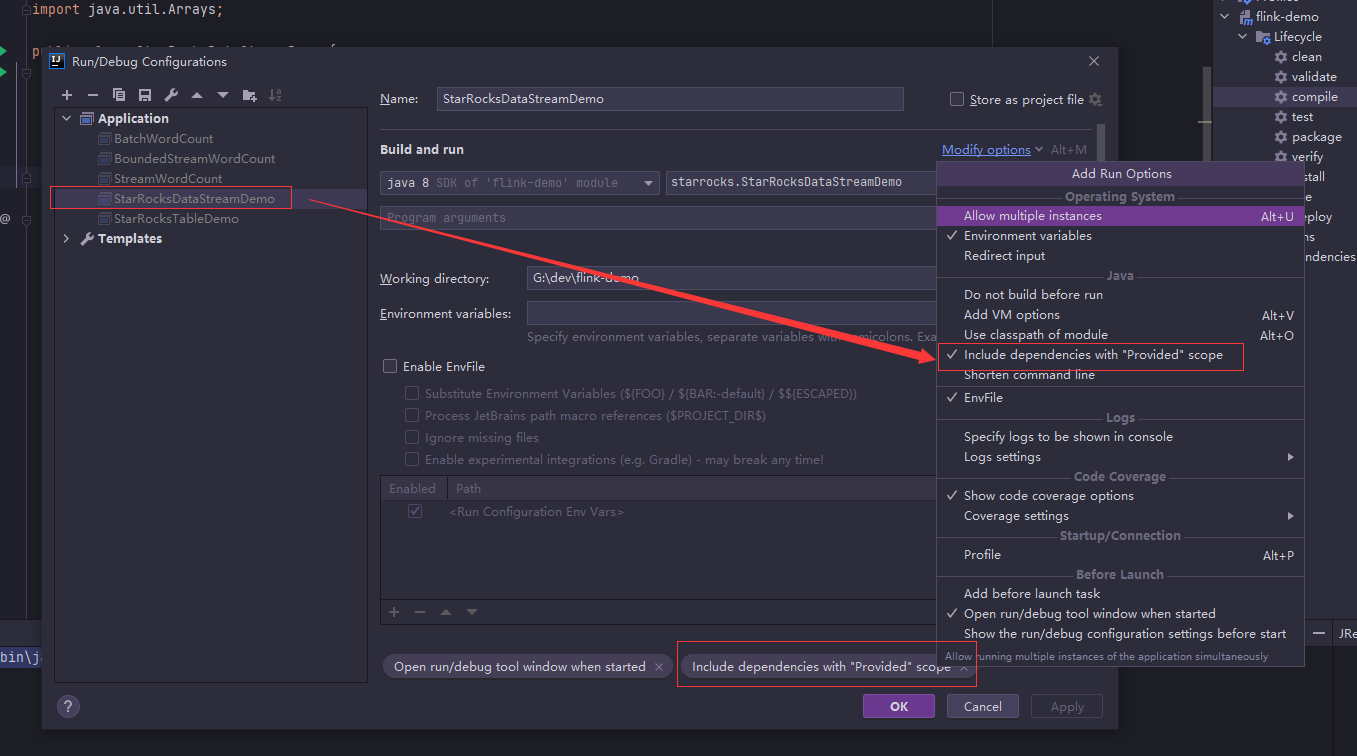
�鿴���������ѳɹ�����article����
Flink Table APIʾ��
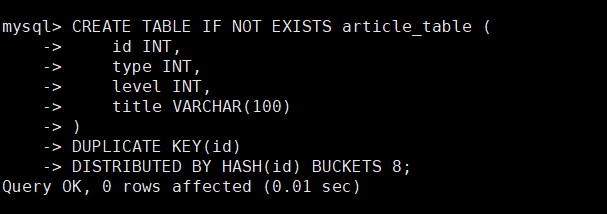
StarRocks���ȴ�����article_table
CREATE TABLE IF NOT EXISTS article_table (
id INT,
type INT,
level INT,
title VARCHAR(100)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8;
����Article pojo��
package starrocks;
public class Article {
private int id;
private int type;
private int level;
private String title;
public Article(int id, int type, int level, String title) {
this.id = id;
this.type = type;
this.level = level;
this.title = title;
}
}
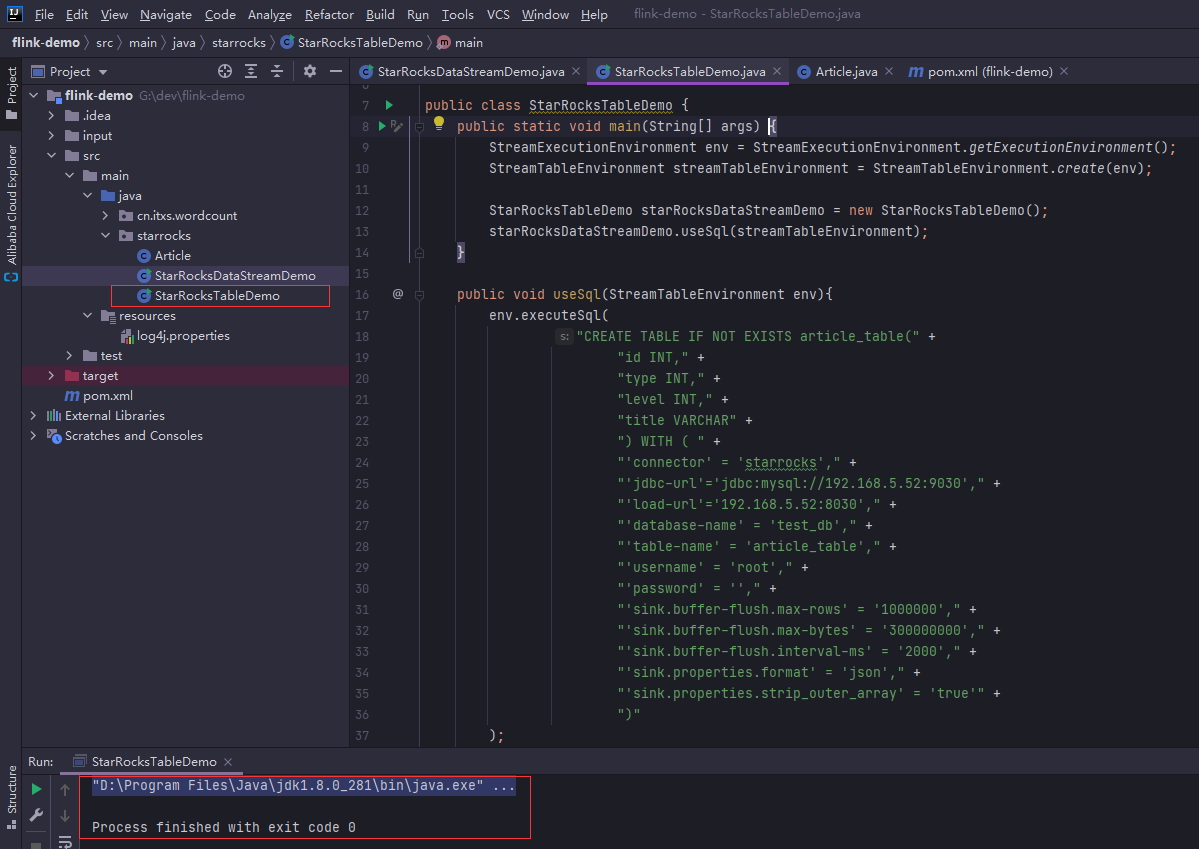
����StarRocksTableDemo.java
package starrocks;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamStatementSet;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class StarRocksTableDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment streamTableEnvironment = StreamTableEnvironment.create(env);
StarRocksTableDemo starRocksDataStreamDemo = new StarRocksTableDemo();
starRocksDataStreamDemo.useSql(streamTableEnvironment);
}
public void useSql(StreamTableEnvironment env){
env.executeSql(
"CREATE TABLE IF NOT EXISTS article_table(" +
"id INT," +
"type INT," +
"level INT," +
"title VARCHAR" +
") WITH ( " +
"'connector' = 'starrocks'," +
"'jdbc-url'='jdbc:mysql://192.168.5.52:9030'," +
"'load-url'='192.168.5.52:8030'," +
"'database-name' = 'test_db'," +
"'table-name' = 'article_table'," +
"'username' = 'root'," +
"'password' = ''," +
"'sink.buffer-flush.max-rows' = '1000000'," +
"'sink.buffer-flush.max-bytes' = '300000000'," +
"'sink.buffer-flush.interval-ms' = '2000'," +
"'sink.properties.format' = 'json'," +
"'sink.properties.strip_outer_array' = 'true'" +
")"
);
StreamStatementSet statementSet = env.createStatementSet();
statementSet.addInsertSql("insert into article_table values(4,4,4,'python'),"+
"(5,5,5,'ruby')");
statementSet.execute();
}
}
�ǵú�ǰ��һ�������������ù�ѡȻ������main,����ִ�����
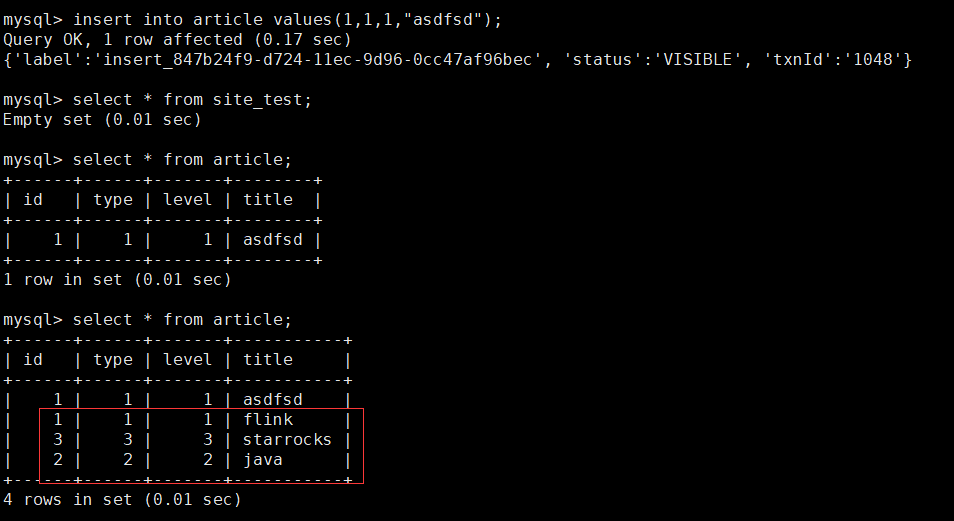
�鿴StarRocks��article_table������,�����ѳɹ��������
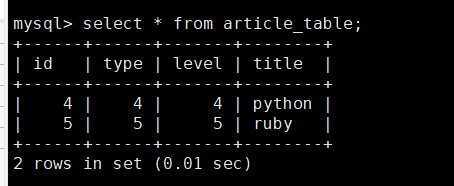
�����ʹ��
����,��Ϊ���ݿ��һ����չ����,�� PG��ClickHouse��Snowflake ��ϵͳ�ж����������֧��,���Թ㷺��Ӧ���� A/B Test �Աȡ��û���ǩ��������Ⱥ����ȳ�����StarRocks ��ǰ֧���� ��ά����Ƕ�ס�������Ƭ���Ƚϡ����˵����ԡ�
�����еĶ�����ʽΪ ARRAY,���� TYPE ������Ԫ������,Ĭ�� nullable,��ʱ��֧��ָ��Ԫ������Ϊ NOT NULL,����Ҳ���Զ������鱾��Ϊ NOT NULL��������������������:
- ֻ���� duplicate table �ж���������(2.1�汾��ʼ֧�� Primary key �� Unique key ��ʹ����������)
- �����в�����Ϊ key ��(�Ժ����֧��)
- �����в�����Ϊ distribution ��
- �����в�����Ϊ partition ��
-- һά����
create table array_test(
f0 INT,
f1 ARRAY<INT>
)
duplicate key(f0)
distributed by hash(f0) buckets 3; -- �Է�3��ͰΪ����
-- ����Ƕ������
create table nest_array_test(
f0 INT,
f1 ARRAY<ARRAY<VARCHAR(10)>>
)
duplicate key(f0)
distributed by hash(f0) buckets 3;
ʹ��SELECT��乹������
- ������ SQL ��ͨ��������( ��[�� �� ��]�� )���������鳣��,ÿ������Ԫ��ͨ������(��,��)�ָ��select [1, 2, 3] as numbers;
- ������Ԫ�ؾ��в�ͬ����ʱ,StarRocks ���Զ��Ƶ������ʵ�����(supertype) select [12, ��100��]; �C ����� [��12��, ��100��]
- ����ʹ�ü�����(
<>)��ʾ������������.select ARRAY[��12��, ��100��]; �C ����� [12, 100] - Ԫ���п�����NULL��select [1, NULL];
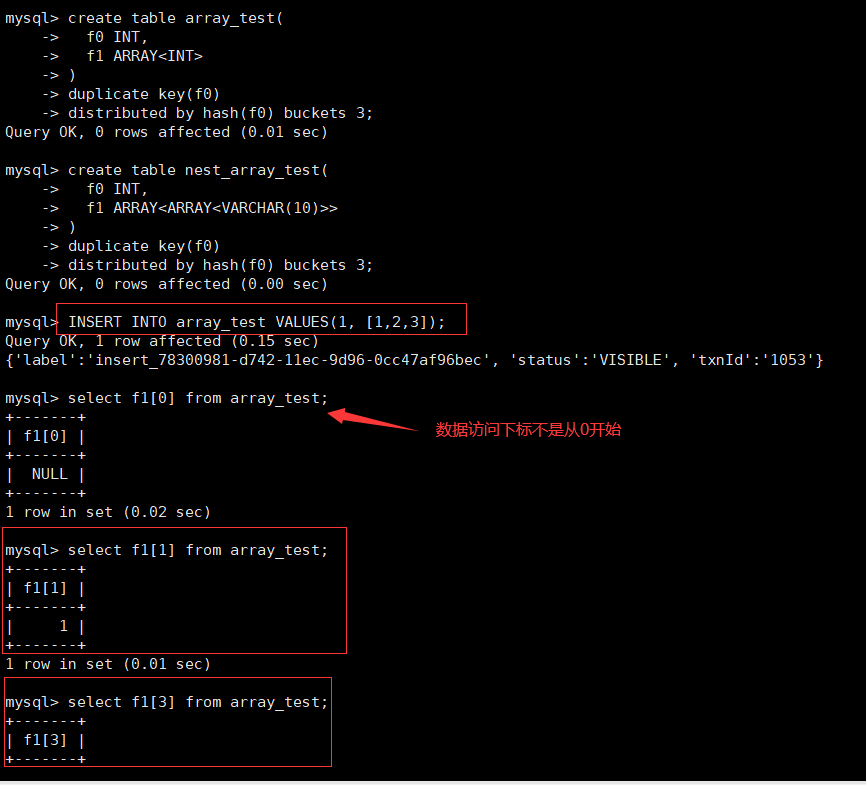
# ����һά�����������ݺͷ�����������
INSERT INTO array_test VALUES(1, [1,2,3]);
select f1[3] from array_test;
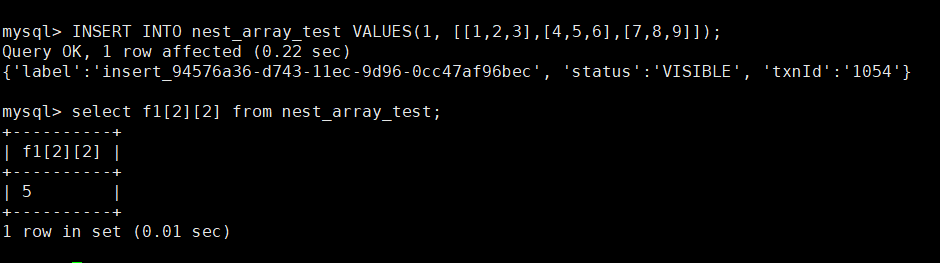
# ����Ƕ�����������������ݺͷ�����������
INSERT INTO nest_array_test VALUES(1, [[1,2,3],[4,5,6],[7,8,9]]);
select f1[2][2] from nest_array_test;
Colocate Join
����
Colocate Join ����,���ڷֲ�ʽϵͳʵ�� Join ���ݷֲ��IJ���֮һ�� �ܹ��������ݷֲ��ڶ���ڵ������ Join ʱ�������ƶ������紫��,�Ӷ���߲�ѯ���ܡ� Colocate Join ʹ�� Colocation Group(CG)����һ��� ,ͬһ CG �ڵı� Colocation Group Schema(CGS)��ͬ,������Ӧ�ķ�Ͱ��������һ�µķ�Ͱ�������������������÷�ʽ ���������Ա�֤ͬһ CG ��,�������ݷֲ�����ͬһ�� BE �ڵ��ϡ��� Join ��Ϊ��Ͱ��ʱ,����ڵ�ֻ�������� Join,������Լ��������ڽڵ��Ĵ����ʱ,��߲�ѯ���ܡ� ���,Colocation Join,��������� Join,���� Shuffle Join �� Broadcast Join,���Ա����������紫�俪��,��߲�ѯ���ܡ�
- Colocation Group(CG):һ�� CG �л����һ�ż����ϵ� Table��һ��CG�ڵ� Table ����ͬ�ķ�Ͱ��ʽ�������÷�ʽ,ʹ�� Colocation Group Schema ������
- Colocation Group Schema(CGS): ���� CG �ķ�Ͱ��,��Ͱ���Լ�����������Ϣ��
ʹ��
- ���� Colocation ��
����ʱ,������ PROPERTIES ��ָ������ "colocate_with" = "group_name",��ʾ�������һ�� Colocate Join ��,���ҹ�����һ��ָ���� Colocation Group
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
Ϊ��ʹ�� Table �ܹ�����ͬ�����ݷֲ�,ͬһ CG �ڵ� Table ���뱣֤����Լ��:
- ͬһ CG �ڵ� Table �ķ�Ͱ�������͡�������˳����ȫһ��,����Ͱ��һ��,�������ܱ�֤���ű������ݷ�Ƭ�ܹ�һһ��Ӧ�ؽ��зֲ����ơ���Ͱ��,���ڽ��������
DISTRIBUTED BY HASH(col1, col2, ...)��ָ��һ���С���Ͱ��������һ�ű�������ͨ����Щ�е�ֵ���� Hash ���ֵ���ͬ�� Bucket Seq �С�ͬ CG �� table �ķ�Ͱ�������ֿ��Բ���ͬ,��Ͱ�еĶ����ڽ�������еij��ִ�����Բ�һ��,������DISTRIBUTED BY HASH(col1, col2, ...)�Ķ�Ӧ�������͵�˳��Ҫ��ȫһ�¡� - ͬһ�� CG �����б������з���(Partition)�ĸ���������һ�¡������һ��,���ܳ���ijһ�� Tablet ��ijһ������,��ͬһ�� BE ��û�������ı���Ƭ�ĸ�����Ӧ��
- ͬһ�� CG �����б��ķ�����,�����������Բ�ͬ��
ͬһ��CG�е����б��ĸ�����������:
- CG������ Table �� Bucket Seq �� BE �ڵ��ӳ���ϵ�� Parent Table һ�¡�
- Parent Table ������ Partition �� Bucket Seq �� BE �ڵ��ӳ���ϵ�͵�һ�� Partition һ�¡�
- Parent Table ��һ�� Partition �� Bucket Seq �� BE �ڵ��ӳ���ϵ����ԭ���� Round Robin �㷨������
CG�ڱ���һ�µ����ݷֲ�������ӱ�����ӳ��,�ܹ���֤��Ͱ��ȡֵ��ͬ��������һ������ͬBE��,��˵���Ͱ����join��ʱ,ֻ�豾��join���ɡ�
- ɾ�� Colocation ��:�� Group �����һ�ű�����ɾ����(����ɾ����ָ�ӻ���վ��ɾ����ͨ��,һ�ű�ͨ��
DROP TABLE����ɾ����,���ڻ���վĬ��ͣ��һ���ʱ���,��ɾ��),�� Group Ҳ�ᱻ�Զ�ɾ����
ʾ��
��ʾ�����Ǵ�����ͬ�ṹ�����ű�ctbl1��ctbl2
CREATE TABLE `ctbl1` (
`f1` date NOT NULL COMMENT "",
`f2` int(11) NOT NULL COMMENT "",
`f3` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`f1`, `f2`)
DISTRIBUTED BY HASH(`f2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
CREATE TABLE `ctbl2` (
`f1` date NOT NULL COMMENT "",
`f2` int(11) NOT NULL COMMENT "",
`f3` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`f1`, `f2`)
DISTRIBUTED BY HASH(`f2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);

EXPLAIN SELECT * FROM ctbl1 INNER JOIN ctbl2 ON (ctbl1.f2 = ctbl2.f2);
ִ�в�ѯ�鿴�����ƻ�,Colocation Join ��Ч Hash Join �ڵ����ʾ colocate: true��
�ⲿ��
StarRocks ֧�����ⲿ������ʽ,������������Դ���ⲿ��ָ���DZ�������������Դ�е����ݱ�,�� StartRocks ֻ�������Ӧ��Ԫ����,��ֱ�����ⲿ����������Դ�����ѯ��Ŀǰ StarRocks ��֧�ֵĵ���������Դ���� MySQL��ElasticSearch��Hive��StarRocks��Apache Iceberg �� Apache Hudi������ StarRocks ����Դ,�ֽ�ֻ֧�� Insert д��,��֧�ֶ�ȡ,������������Դ,�ֽ�ֻ֧�ֶ�ȡ,����֧��д����
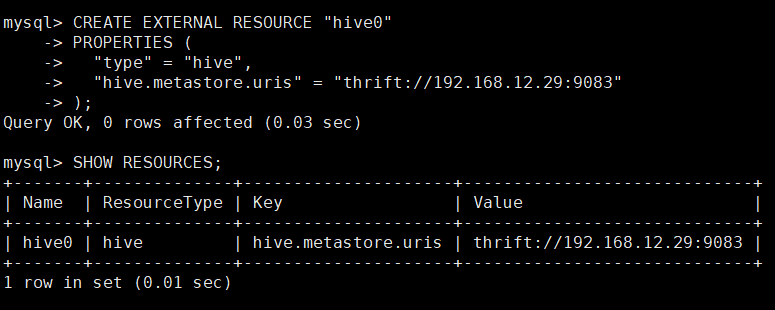
CREATE EXTERNAL RESOURCE "hive0"
PROPERTIES (
"type" = "hive",
"hive.metastore.uris" = "thrift://192.168.12.29:9083"
);
-- �鿴 StarRocks �д�������Դ
SHOW RESOURCES;
-- ɾ����Ϊ hive0 ����Դ
DROP RESOURCE "hive0";
ִ��hive���Ĵ����Ͳ���һ����������
CREATE TABLE external_test(
`url` string,
`event` int,
`time` bigint)
ROW FORMAT DELIMITED
STORED AS PARQUET
TBLPROPERTIES('parquet.compression'='SNAPPY');
insert into external_test values('/user',1,1652862952);
ִ�н������
StarRocks�д���hive���ⲿ��external_test
-- ����:���� hive0 ��Դ��Ӧ�� Hive ��Ⱥ�� test ���ݿ��µ� broker_test �������
CREATE EXTERNAL TABLE `external_test` (
`url` varchar(200),
`event` int,
`time` bigint
) ENGINE=HIVE
PROPERTIES (
"resource" = "hive0",
"database" = "test",
"table" = "external_test"
);
# ��ѯ�������
select count(*) from external_test;
�������кܶ����ⲿ��,MySQL �ⲿ����ElasticSearch �ⲿ����StarRocks �ⲿ����Apache Iceberg �����Apache Hudi ���,������ʱ���ٲ���
**���˲�����վ **ITС�� www.itxiaoshen.com

