аЁЬт:
ЮФеТФПТМ
бЁдё:
- HDFSЕФОжЯоад
- ВЛЪЪКЯЕЭбгГйЕФЪ§ОнЗУЮЪ
- HBase ИќМгЪЪКЯ
- ЮоЗЈИпаЇДцДЂДѓСПаЁЮФМў
- ВЛжЇГжЖргУЛЇаДШыМАШЮвтаоИФЮФМў
- ВЛЪЪКЯЕЭбгГйЕФЪ§ОнЗУЮЪ
- HDFSЬхЯЕНсЙЙЕФОжЯоад
- УќУћПеМфЕФЯожЦ
- адФмЕФЦПОБ
- ИєРыЮЪЬт
- МЏШКЕФПЩгУад
- Hadoop1.0ЕФОжЯогыВЛзу
-
ГщЯѓВуДЮЕЭ
-
БэДяФмСІгаЯо
- ИДдгЕФЗжВМЪНБрГЬЙЄзїИпЖШГщЯѓЮЊMapReduceСНИіКЏЪ§,дкНЕЕЭПЊЗЂИДдгЖШЕФЭЌЪБ,вВДјРДБэДяФмСІгаЯоЕФЮЪЬт,ЪЕМЪЩњГЩЛЗОГжаЕФвЛаЉгІгУЪЧЮоЗЈгУМђЕЅЕФMapКЭReduce РДЭъГЩЕФ
-
ПЊЗЂепашвЊздМКЙмРэзївЕжЎМфЕФвРРЕЙиЯЕ
- ЪЕМЪЩњВњжаашвЊЖрИізївЕазїВХФмЫГРћНтОівЛаЉЮЪЬт,етаЉзївЕжЎМфЭљЭљДцдкИДдгЕФвРРЕЙиЯЕ,ЕЋЪЧMapReduce БОЩэУЛгаЖдвРРЕЙиЯЕНјаагааЇЙмРэ
-
ФбвдПДЕНГЬађЕФећЬхТпМ
- гУЛЇЕФЪЕМЪДІРэТпМЖМдкСНИіКЏЪ§жа,УЛгаИќИпВуДЮЕФГщЯѓ
-
жДааЕќДњВйзїаЇТЪЕЭ
- УПДЮДІРэЖМБиаыОЙ§MapКЭReduce ЕФЪ§ОнЖСШЁКЭаДШыЕФЙ§ГЬ,аЇТЪЕЭЯТ
-
зЪдДРЫЗб
- Reduce ШЮЮёБиаыЕШЕНЫљгаЕФMapШЮЮёЖМЭъГЩВХФмМЬај
-
ЪЕЪБадВю
- жЛЪЪКЯДІРэРыЯпХњДІРэГЬађ,ЮоЗЈжЇГжНЛЛЅЪНЕФЪ§ОнДІРэ
-
ХаЖЯ:
-
УћГЦНкЕуВЛЛсЖЈЦкМьВщИББОЪ§СП(Дэ)
- УћГЦНкЕуЛсЖЈЦкМьВщШпгрИББОЕФЪ§СП,ШчЙћИББОЪ§СПаЁгкШпгрвђзг,ОЭЛсЦєЖЏЪ§ОнШпгрИДжЦ,ЩњГЩаТЕФИББО,HDFSгыЦфЫћЮФМўЯЕЭГзюДѓЕФЧјБ№ОЭдкгкПЩвдЕїећШпгрЪ§ОнЕФЮЛжУ
-
MapКЏЪ§РДздгкHDFSЕФЮФМўПщИёЪНЪЧЙЬЖЈЕФ
- ВЛЙЬЖЈ,ЮФМўИёЪНШЮвт,ПЩвдЪЧЮФМў,вВПЩвдЪЧЖўНјжЦИёЪНЕФ
-
MapReduce ЕФМќжЕЖдЕФМќОпгаЮЈвЛад
- МќВЛОпБИЮЈвЛад,ВЛФмзїЮЊЪфГіЕФЩэЗнБъЪЖ
ЬюПе:
- УћГЦНкЕуЕФСНИіКЫаФЪ§ОнНсЙЙ
- FsImage
- EditLog
- ШчЙћEditLog КмДѓОЭЛсЕМжТNameNode ЦєЖЏНјГЬТњ,ЪЙЕУУћГЦНкЕуГЄЦкДІгкАВШЋФЃЪН,ЮоЗЈЖдЭтЬсЙЉаДВйзї
- УћГЦНкЕуЦєЖЏЪБЛсНЋFsImage МгдиЕНФкДцжа,ШЛКѓжДааEditLogЮФМўжаЕФИїЯюВйзї,ЪЙЕУФкДцжаЕФдЊЪ§ОнБЃГжзюаТ
- УћГЦНкЕуЦєЖЏГЩЙІКѓНјШые§ГЃдЫааФЃЪН,HDFSЕФИќаТВйзїЛсБЛаДШыЕНEditLog жа,ЖјВЛЪЧаДШыFsImage
- DataNodeЪЧЗжВМЪНЮФМўЯЕЭГHDFSЕФЙЄзїНкЕу,ИКд№Ъ§ОнЕФДцДЂКЭЖСШЁ
- HDFSФЌШЯЕФШпгрИДжЦвђзгЪ§ЪЧ3,УПвЛИіЮФМўЛсБЃДцдк3ИіЕиЗН,ЦфжаСНИіИББОдкЭЌвЛИіЛњМмЕФВЛЭЌЛњЦїЩЯ,ЕкШ§ИіИББОдкЗХдкВЛЭЌЕФЛњМмЕФЛњЦїЩЯ,ШЁЪ§ОнЕФЪБКђОЭНќШЁ(ОЭНќЛњМмНјааЪ§ОнЖСШЁ)
- HDFSЕФЪ§ОнИДжЦВЩгУСїЫЎЯпВпТд
- HDFSаДЪ§ОнЕФЙ§ГЬжаЛсЭЈЙ§RPCдЖГЬЕїгУУћГЦНкЕу,ПЭЛЇЖЫЭЈЙ§ЕїгУЪфГіСїЕФwrite()ЗНЗЈЯђHDFSжаЖдгІЕФЮФМўаДШыЪ§Он
- HDFSаДЪ§ОнЕФЙ§ГЬжа,ЮЊСЫБЃжЄЪ§ОнНкЕуЕФЪ§ОнЪБзМШЗЕФ,НгЪеЕНЪ§ОнЕФУћГЦНкЕуЛсЯђЗЂЫЭепЗЂЫЭACKШЗШЯАќ
- HDFSаДЪ§ОнЕФЙ§ГЬЪЧСїЫЎЯпИДжЦВпТд,ЭЈЙ§ЙЙНЈЪ§ОнСїЙмЕРНјааЪ§ОнДЋЪф
- HBaseЪЧgoogleЕФBigTableЕФПЊдДЪЕЯж
- MapReduceФЃаЭжазіЕФЕквЛМўЪТЪЧ(НЋДѓЙцФЃЪ§ОнМЏНјааЗжЦЌ,ЗжГЩШєИЩЖРСЂЕФаЁЪ§ОнПщ)
- Reduce КЏЪ§ЕФШЮЮёЪЧНЋЪфШыЕФвЛЯЕСаОпгаЯрЭЌМќЕФМќжЕЖдвдФГжжЗНЪНзщКЯЦ№РД,ЪфГіДІРэКѓЕФМќжЕЖд,ЪфГіЕФНсЙћЛсКЯВЂГЩвЛИіДѓЮФМў
- shuffle ЕФИїИіжДааНзЖЮЗжЧј,ХХађ,КЯВЂ,ЙщВЂ
- MapЕФЪфГіНсЙћЛсЯШаДШыЛКДцжа,ЛКДцТњЪБ,ОЭЦєЖЏвчаДВйзї
- Shuffle Й§ГЬЕФНсЙћЪБзюжеЩњГЩвЛИіДѓЮФМўаДЕНБОЕиДХХЬЩЯ
- MapЖЫЖСШЁMapНсЙћ,ШЛКѓжДааЙщВЂВйзї,зюКѓЪфЫЭИјReduce ШЮЮёНјааДІРэ
- ZooKeeper ЪЕЯжHAжаЕФздЖЏЛЏЧаЛЛ
- HDFSдкHadoop1.0жаЕФЕЅЕуЪЇаЇЮЪЬтЪЧЭЈЙ§HDFS HAНјааНтОіЕФ
- HDFSЕФЕЅвЛУќУћПеМф,ЮоЗЈЪЕЯжзЪдДИєРыЕФЮЪЬтЪЧЭЈЙ§HDFS СЊАюНјааНтОіЕФ
- зЪдДЙмРэаЇТЪЕЭЕФЮЪЬтЪЧЭЈЙ§HDFSзЪдДЙмРэПђМмYarnНтОіЕФ
ДѓЬт
МђД№ 6*5
ЪЕбщЯрЙи 10*1
злКЯГЬађ(ХфжУНтЪЭ)10*1
вЛЁЂМђД№Ьт
1ЁЂHadoop ЩњЬЌМАИїВПЗжЕФзїгУ
ЕкЖўеТ(ПЩФмад5)
вВгаПЩФмПМЬюПе
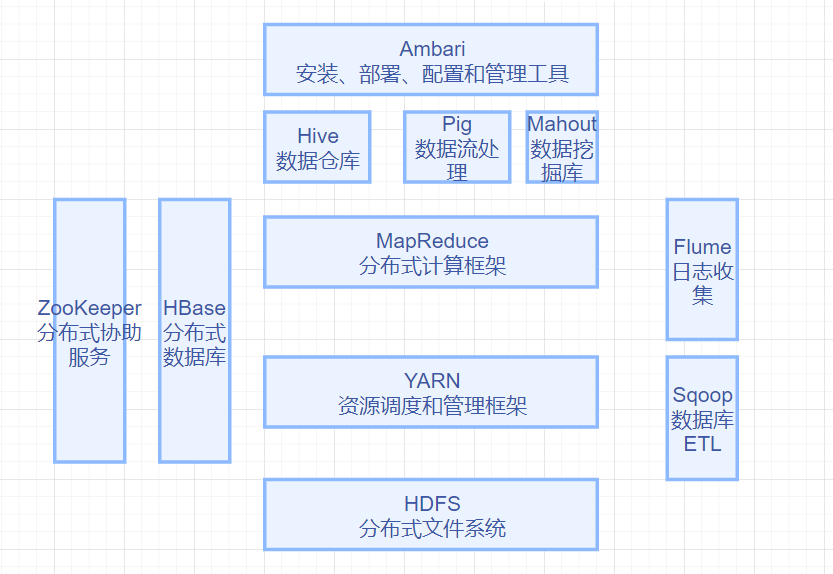
2ЁЂHDFSЕФЪЕЯжФПБъ
ЕкШ§еТ(ПЩФмад3)
- МцШнСЎМлЕФгВМўЩшБИ
- СїЪ§ОнЕФЖСаД,вдСїЪ§ОнЕФаЮЪНЗУЮЪЮФМўЯЕЭГ
- ДѓЪ§ОнМЏ
- МђЕЅЕФЮФМўФЃаЭ,ЁАвЛДЮаДШыЖрДЮЖСШЁЁБ,ЮФМўвЛЕЉаДШы,ЙиБеКѓОЭЮоЗЈдйДЮаДШы,жЛФмБЛЖСШЁ
- ЧПДѓЕФПчЦНЬЈад
3ЁЂFsImageКЭEditLogЕФЙ§ГЬ
ЕкШ§еТ(ПЩФмад3)
FsImage гУгкЮЌЛЄЮФМўЯЕЭГМАЮФМўЪїжаЫљгаЮФМўКЭЮФМўМаЕФдЊЪ§Он
ВйзїШежОEditLog жаМЧТМСЫЫљгаеыЖдЮФМўЕФДДНЈЁЂЩОГ§ЁЂжиУќУћЕШВйзї
УћГЦНкЕуЦєЖЏЪБЛсНЋFsImage МгдиЕНФкДцжа,ШЛКѓжДааEditLogЮФМўжаЕФИїЯюВйзї,ЪЙЕУФкДцжаЕФдЊЪ§ОнБЃГжзюаТ
4ЁЂHDFSЖСЪ§ОнЕФЙ§ГЬ
ЕкШ§еТ(ПЩФмад5)
ПЭЛЇЖЫЭЈЙ§FileSystem.open()ДђПЊЮФМў,DistributeFileSystem ЛсДДНЈЪфШыСїFSDataInputStream(HDFSЪЕЯжРр DFSInputStream)
- ЪфШыСї(ЭЈЙ§ClientProtocal.getBlockLocations)дЖГЬЕїгУУћГЦНкЕу,ЛёЕУЮФМўПЊЪМВПЗжЪ§ОнПщЕФБЃДцЮЛжУЁЃЖдгкИУЪ§ОнПщ,УћГЦНкЕуЗЕЛиБЃДцИУЪ§ОнПщЫљгаЪ§ОнНкЕуЕФЕижЗ,ЭЌЪБИљОнОрРыПЭЛЇЖЫЕФдЖНќЖдЪ§ОнНкЕуНјааХХађ,ШЛКѓНЋFSDataInputStream КЭ Ъ§ОнПщЕФЪ§ОнНкЕуЕижЗЗЕЛиИјПЭЛЇЖЫ
- ПЭЛЇЖЫЭЈЙ§FSDataInputStream ЕїгУreadЗНЗЈЖСШЁЪ§Он,ЪфШыСїИљОнХХађНсЙћ,бЁдёзюНќЕФЪ§ОнНкЕу,НЈСЂСЌНгВЂЖСШЁЪ§Он
- Ъ§ОнПщЖСШЁЭъБЯКѓ,FSDataInputStreamЙиБеКЭЪ§ОнНкЕуЕФСЌНг
- ЪфШыСїЭЈЙ§getBlockLocation() ЗНЗЈВщевЯТвЛИіЪ§ОнПщ(ШчЙћПЭЛЇЖЫЛКДцжавбОАќКЌИУЪ§ОнПщЕФЮЛжУаХЯЂ,ОЭВЛдйЕїгУИУЗНЗЈ)
- евЕНЪ§ОнПщЕФзюМбЪ§ОнНкЕу,ЖСШЁЪ§Он
- ШЋВПЪ§ОнПщЖСШЁЭъБЯКѓЕїгУFSDataInputStream ЕФclose() ЗНЗЈ,ЙиБеЪфШыСї
ШчЙћПЭЛЇЖЫКЭЪ§ОнНкЕуЭЈаХЪБГіЯжДэЮѓ,ОЭЛсГЂЪдСЌНгКЌДЫЪ§ОнПщЕФЯТвЛИіЪ§ОнНкЕу
5ЁЂHBase RegionЕФЖЈЮЛЗНЪН
6ЁЂМђЪіMapКЏЪ§КЭReduceКЏЪ§ЕФЙІФм
ЕкЦпеТ(ПЩФмад5)
- MapКЏЪ§
- ЪфШы<k1,v1>
- ЪфГіList<k2,v2>
- ЙІФм:
- НЋаЁЪ§ОнМЏНјвЛВНЗжНтГЩвЛХњ<key,value>,ЪфШыMapКЏЪ§жаНјааДІРэ
- УПИіЪфШыЕФ<k1,v1> ЛсЪфГівЛХњ<k2,v2>(жаМфНсЙћ)
- ReduceКЏЪ§
- ЪфШы<k2,list(v2)>
- ЪфГі<k3,v3>
- ЙІФм:
- ЪфШыЕФжаМфНсЙћ<k2,list(v2)>жаЕФList(v2)БэЪОЪЧвЛХњЪєгкЭЌвЛИіЕФk2ЕФvalue
MapКЏЪ§ЕФЪфШыЪЧРДздЗжВМЪНЮФМўЯЕЭГЕФШЮвтИёЪНЮФМўПщ,ЪзЯШMapКЏЪ§ЛсНЋЪфШыЕФдЊЫизЊЛЛЮЊ<key,value>ИёЪНЕФМќжЕЖд,МќКЭжЕЕФРраЭШЮвт
ReduceКЏЪ§НЋЪфШыЕФвЛЯЕСаОпгаЯрЭЌМќЕФМќжЕЖдвдФГжжЗНЪНзщКЯЦ№РД,ЪфГіДІРэКѓЕФМќжЕЖд,ЪфГіЕФНсЙћЛсКЯВЂГЩвЛИіДѓЮФМў
MapКЏЪ§КЭReduceКЏЪ§ЖМЪЧГЬађдБИљОнвЕЮёздааЪЕЯж,ЫљвдЙІФмжЛЬИТлЪфШыЪфГіКЭзюжеЕФНсЙћ,гЁжЄКЏЪ§ЪНБрГЬЕФЫМЯы
7ЁЂМђЪіMapЖЫКЭReduceЖЫЕФshuffleЙ§ГЬ
MapЖЫ
MapЕФЪфГіНсЙћЪзЯШаДШыЛКДц,ЛКДцТњЪБвчаДВйзїаДШыДХХЬЮФМў,ВЂЧхПеЛКДцЁЃЦєЖЏвчаДЪБ,ЪзЯШЛсНЋЛКДцжаЕФЪ§ОнНјааЗжЧј,ШЛКѓЖдУПИіЪ§ОнНјааХХађКЭКЯВЂ,жЎКѓдйаДШыДХХЬЮФМўЁЃЕБДцдкЖрИівчаДЮФМўЪБ,ОЭЛсБЛЙщВЂГЩвЛИіДѓЕФДХХЬЮФМўЁЃ
ЦфжавЛЖЈЗЂЩњЕФЪБКђЗжЧј,ХХађ,ЙщВЂ,ШєГЬађдБЪЕЯжСЫКЯВЂНгПк,дђжДааКЯВЂВйзї
ReduceЖЫ
MapЛњЦїСьЛсЪєгкздМКДІРэЕФФЧВПЗжЪ§Он,ШЛКѓЖдЪ§ОнНјааЙщВЂ,ШЛКѓНЛИјReduceКЏЪ§НјааДІРэ
ЖўЁЂЪЕбщЬт
hadoop ЕФАВзАПМЕу:
вЛЁЂДДНЈHadoop гУЛЇ
adduser hadoop #1 passwd hadoop #2ЖўЁЂSSHУтУмЕЧТМ
ssh-keygen -t rsa -P '~/.ssh' #ЩњГЩid_dsa.pub #3 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys ssh localhost #бщжЄ #4Ш§ЁЂВщПДHadoop АцБО
./hadoop1.2.1/bin/hadoop version #5ЫФЁЂдЫааВтЪд
mkdir ./input #ДДНЈinput ФПТМ #grep ЪЧРрЕФШыПк ./bin/hadoop jar /........../hadoop-mapreduce-example-*.jar ./input ./output 'dfs[a-z.]+' #./bin/hadoop 6 jar 7 ./input 8 ./output 9 аДЖдТЗОЖ10
Ш§ЁЂзлКЯГЬађЬт
hadoopЮБЗжВМЪНАВзАПМЕу:
core-site.xml hadoopЭЈгУХфжУЮФМў
<configuration> <property> <name>hadoop.tmp.dir</name> #дЫааВњЩњЕФСйЪБЮФМўЕФДцДЂЕижЗ <value>file:/usr/local/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> #1 #жЦЖЈhdfs ЗУЮЪЕФавщ,ipКЭЖЫПкКХ <value>hdfs://localhost:9000</value> #2 </property> </configuration>hdfs-sit.xml hdfЬигаХфжУЮФМў
<configuration> <property> #ЭЌвЛЗнЪ§ОнЕФИББОЪ§ <name>dfs.replication</name> #3 <value>1</value> #4 </property> <property> <name>dfs.namenode.name.dir</name> #5 <value>file:/user/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> #6 <value>file:/user/local/hadoop/tmp/dfs/data</value> </property> </configuration>ГѕЪМЛЏЮФМўЯЕЭГ
./bin/hadoop namenode -formatЦєЖЏМЏШК
./sbin/start-all.sh #8МьВщЦєЖЏГЩЙІ
jps #8ЗУЮЪwebвГУц
http://localhost:9870
HDFSГЃгУУќСю:
hadoop fs -ls <path> ЯдЪОpath ТЗОЖЯТЕФЮФМўаХЯЂ #9 hadoop fs -cat <path> НЋpath ТЗОЖЯТЕФЮФМўФкШнЪфГіЕНБъзМЪфГі #10 hadoop fs -mkdir [-p] <path> ДДНЈжЦЖЈЕФpathТЗОЖЕФЯТЕФЮФМўМа,-pМЖСЊДДНЈ #11 hadoop fs -put <localSrc> <dst> ДгБОЕиТЗОЖ<locslSrc> ЕФЮФМўИДжЦЕНdstжИЖЈhadoopЮФМўФПТМЯТ #12

