问题
业务人员在使用我最近全职维护的数据产品时,反馈的一个问题。
这个功能模块,支持各种类型的数据源,如:Hive,MySQL,SQL Server,Oracle,ClickHouse,Impala等。支持多段SQL,多段SQL子句以英文分号分隔,且最后一个SQL子句必须是select查询子句;select查询,即形成所谓的数据集。最后生成一个定时任务,xxl-job定时调度执行SQL,更新数据集。页面上可以点击按钮【读取数据】执行多段SQL,然后可以点击按钮【预览数据】最多预览30行记录。后台实现中,读取数据会把数据集,即SQL执行结果储存到MongoDB数据库。
读取数据,执行SQL,报错信息如下:Map key t.自然日 contains dots but no replacement was configured! Make sure map keys don't contain dots in the first place or configure an appropriate replacement。
业务反馈的问题SQL比较复杂,经过简化后的SQL如下:
drop table if exists test.test_hive_field;
create table test.test_hive_field as
select
100 as userscore,
'031818' as user_id,
'2022-05-18' as dt;
select
tt.userscore,
tt.user_id as userId,
tt.dt
from (
select * from test.test_hive_field t limit 1
) tt;
由于是生产问题,并且ELK日志找不到可用可靠的错误日志,走很多弯路,包括尝试在堡垒机里调试定位问题。事实上最简单的路径应该是,找到可用的测试环境的数据源,在本地开发测试环境下复现,然后断点调试问题。并且,没有第一时间去百度,Google,浪费不少时间,兜了不少圈子。
题外话,在使用测试环境hive数据源,遇到另一个报错:
org.apache.hadoop.util.Shell [<clinit>:694] Did not find winutils.exe: {}
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
后来终于可以在本地调试代码:
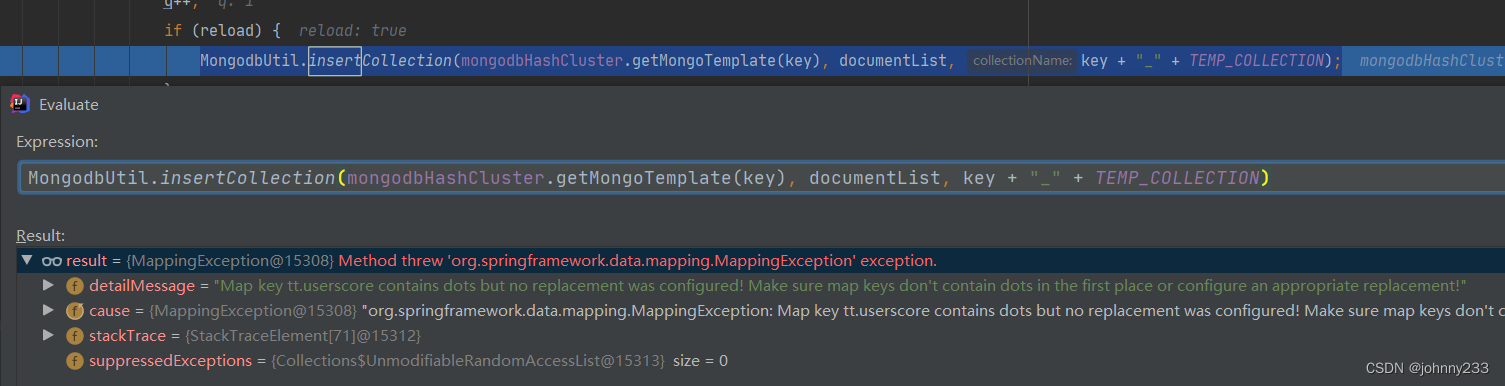
可以看到,问题根源在于:数据insert到MongoDB集合时报错。
数据长啥样呢?
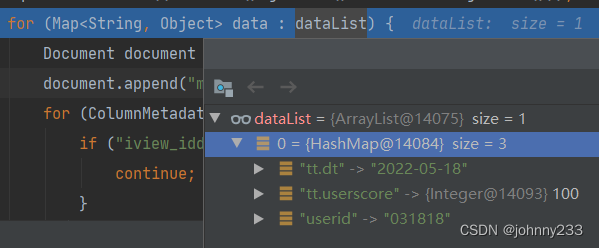
查询结果字段为全小写,有 dot 符号。
解决
既然已经能够通过调试来定位问题,并且能知道有问题的代码出现在那一行,那解决问题就不远。
Google搜索得到比较靠谱的mongodb-escape-dots-in-map-key。意思很明显,就是:.以及$符号是MongoDB保留关键词,字段命名时不能含有这些符号。
MongoDB的模版方法模式MongoTemplate配置如下:
MongoDatabaseFactory mongoDbFactory = new SimpleMongoClientDatabaseFactory(mongoUri.getUri());
DbRefResolver dbRefResolver = new DefaultDbRefResolver(mongoDbFactory);
MongoMappingContext mongoMappingContext = new MongoMappingContext();
MappingMongoConverter mongoConverter = new MappingMongoConverter(dbRefResolver, mongoMappingContext);
mongoConverter.setMapKeyDotReplacement(".");
mongoConverter.with(mongoDbFactory);
mongodbMap.put(mongodbNameTemp, new MongoTemplate(mongoDbFactory, mongoConverter));
注,Spring-data-mongodb版本号为:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<version>2.3.4.RELEASE</version>
</dependency>
结果还是不行,报错信息如下:Invalid BSON field name tt.dt
mongo-database-invalid-bson-field-name-exception
意思是配置MappingMongoConverter行不通,只能把点去掉,下面这行代码简直nonsense,doing-nothing,用.来替换(设置,set)字段里面的.:
mongoConverter.setMapKeyDotReplacement(".");
替换成:
mongoConverter.setMapKeyDotReplacement("-");
解决问题,但是这意味着存储到MongoDB数据库的字段名,已经不是最初SQL里面指定的查询字段名,而变成如下样式:
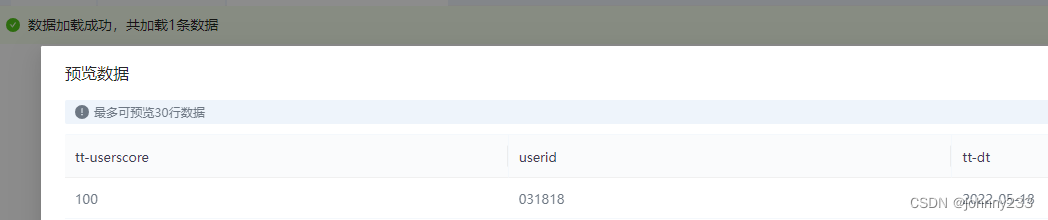
解决方法就是在从MongoDB取数时,再转换一下,将-转换成.。后面就没有继续往下钻研。
大致思路如上。
解决思路二
之所以有思路二,是因为我们支持各种不用的SQL方言,上面出现问题的数据源是Hive,具体来说,其URL为:jdbc:hive2://100.200.300.400:10000/edw。
作为背景,需要知道的是,仅仅只是hive数据源有上面这个问题,其他数据源,则没有这个问题。
有一个impala数据源,其URL为:jdbc:hive2://impala.pddcorp.com:25005,有类似的SQL:
select
tt.guaranteeremainingamount,
tt.user_id as userId,
tt.dt
from (
select * from cdr.hnsx_baihang_change t limit 10
) tt
一直以来没有发现问题,调试截图如下:
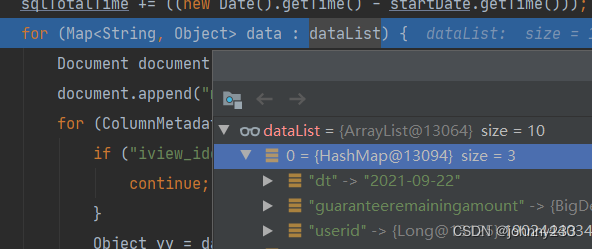
查询结果字段全小写,没有 dot 符号。故而数据insert到MongoDB,不会报错。
所以解决思路在hive数据源的查询结果的特殊处理上:
String columnLabel = metaData.getColumnLabel(j);
if (columnLabel.contains(".") && this.datasourceJson.getString(Constant.JDBC_URL).contains("10000")) {
columnLabel = columnLabel.substring(columnLabel.indexOf(".") + 1);
}
如果是10000端口,就表示是hive数据源;如果含有.,则截图后面的字段。
问题,为什么impala和hive数据源使用同一个hive-jdbc,查询字段不一样?
注:
使用的hive-jdbc版本为:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1-cdh6.2.1</version>
</dependency>
备注
代码片段,一直想不明白,为什么不用@Component注解配置类,要写成Util工具类:
@Slf4j
public class MongodbHashCluster {
private final SortedMap<Long, String> vNodes = new TreeMap<>();
private final Map<String, MongoTemplate> mongodbMap = new HashMap<>();
public MongodbHashCluster(MongoUriList mongoUriList) {
log.info("获取配置:" + mongoUriList);
if (!CollectionUtils.isEmpty(mongoUriList.getList())) {
int k = 0;
int DEFAULT_VNODE_NUM = 150;
for (MongoUriList.MongoUri mongoUri : mongoUriList.getList()) {
String mongodbNameTemp = mongoUri.getName();
if (mongodbNameTemp == null) {
mongodbNameTemp = "mongodb_" + ++k;
}
log.info("获取mongodb配置:" + mongodbNameTemp);
// 核心配置
MongoDatabaseFactory mongoDbFactory = new SimpleMongoClientDatabaseFactory(mongoUri.getUri());
DbRefResolver dbRefResolver = new DefaultDbRefResolver(mongoDbFactory);
MongoMappingContext mongoMappingContext = new MongoMappingContext();
MappingMongoConverter mongoConverter = new MappingMongoConverter(dbRefResolver, mongoMappingContext);
mongoConverter.setMapKeyDotReplacement(".");
mongoConverter.with(mongoDbFactory);
mongodbMap.put(mongodbNameTemp, new MongoTemplate(mongoDbFactory, mongoConverter));
for (int i = 0; i < DEFAULT_VNODE_NUM; i++) {
long hashCode = hash2(mongodbNameTemp + "_vnode_" + i);
vNodes.put(hashCode, mongodbNameTemp);
}
}
}
}
private String get(String key) {
long hashCode = hash2(key);
SortedMap<Long, String> subMap = vNodes.tailMap(hashCode);
if (!subMap.isEmpty()) {
return subMap.get(subMap.firstKey());
}
return vNodes.get(vNodes.firstKey());
}
public MongoTemplate getMongoTemplate(String key) {
try {
String mongoTemplateName = get(key);
return mongodbMap.get(mongoTemplateName);
} catch (Exception e) {
log.error("get mongoTemplate error", e);
}
return null;
}
/**
* MurMurHash算法,是非加密HASH算法,性能很高,
* 比传统的CRC32, MD5, SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
* 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
* http://murmurhash.googlepages.com/
*/
public static Long hash2(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(
ByteOrder.LITTLE_ENDIAN);
// for big-endian version, do this first:
// finish.position(8-buf.remaining());
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}
参考
mongodb-escape-dots-in-map-key
mongo-database-invalid-bson-field-name-exception

