Ŀ¼
4��RDD �ݴ����� Checkpoint
�־û��ľ���:
�־û�/����������ݷ����ڴ���,��Ȼ�ǿ��ٵ�,����Ҳ����ɿ���;Ҳ�������ݷ��ڴ�����,Ҳ������ȫ�ɿ���!������̻��ȡ�
������:
Checkpoint �IJ�������Ϊ�˸��ӿɿ������ݳ־û�,�� Checkpoint ��ʱ��һ������ݷ����� HDFS ��,�����Ȼ�Ľ����� HDFS �����ĸ��ݴ����߿ɿ���ʵ���������̶��ϵİ�ȫ,ʵ���� RDD ���ݴ��߿��á�
�÷�:
SparkContext.setCheckpointDir("Ŀ¼") //HDFS��Ŀ¼
RDD.checkpoint
�ܽ�:
��������α�֤���ݵİ�ȫ���Լ���ȡЧ��:���Զ�Ƶ��ʹ������Ҫ������,��������/�־û�,���� checkpint ������
�־û��� Checkpoint ������:
1��λ��:Persist �� Cache ֻ�ܱ����ڱ��صĴ��̺��ڴ���(���߶����ڴ�Cʵ����) Checkpoint ���Ա������ݵ� HDFS ����ɿ��Ĵ洢�ϡ�
2����������:Cache �� Persist �� RDD ���ڳ��������ᱻ��������ֶ����� unpersist ���� ,Checkpoint �� RDD �ڳ����������Ȼ����,���ᱻɾ����
5. RDD ������ϵ
1) ��խ����
����������ϵ����:RDD ���������ĸ� RDD �Ĺ�ϵ�����ֲ�ͬ������,��������(wide dependency/shuffle dependency)խ����(narrow dependency)

ͼ��:
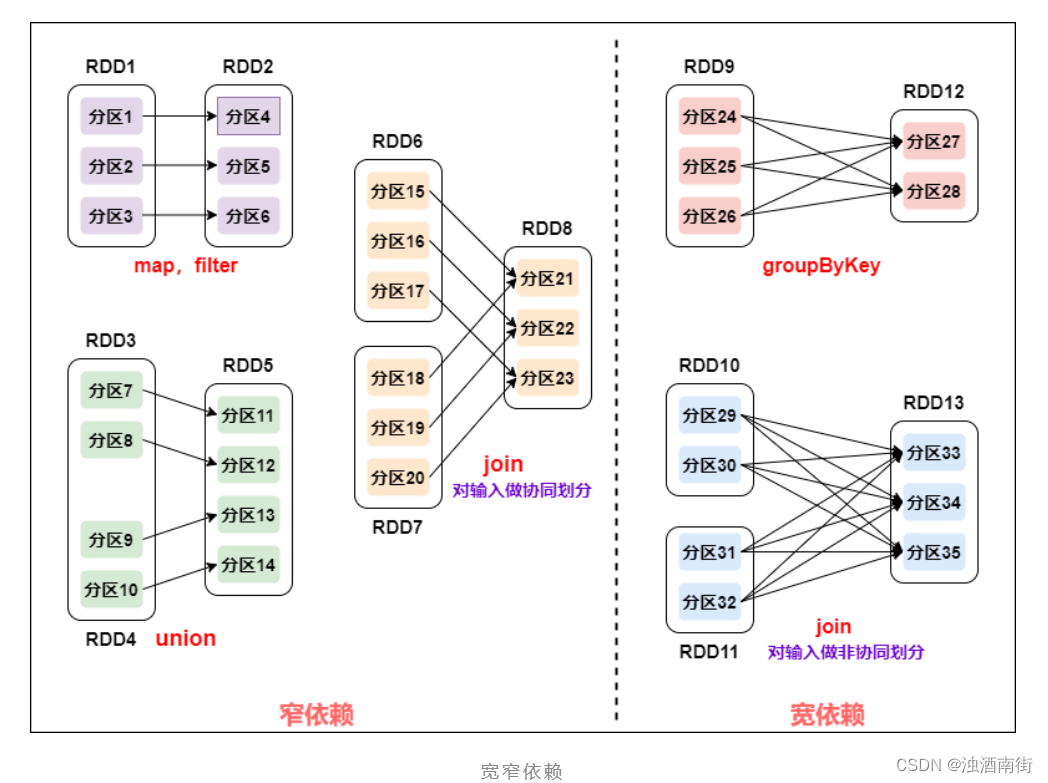
������ֿ�խ����:
խ����:�� RDD ��һ������ֻ�ᱻ�� RDD ��һ����������;
������:�� RDD ��һ�������ᱻ�� RDD �Ķ����������(�漰�� shuffle)��
2) ΪʲôҪ��ƿ�խ����
1������խ����:
խ�����Ķ���������Բ��м���;
խ������һ�����������������ʧֻ��Ҫ���¼����Ӧ�ķ��������ݾͿ����ˡ�
2�����ڿ�����:
���� Stage(��)������:���ڿ�����,����ȵ���һ�μ�����ɲ��ܼ�����һ�Ρ�
6. DAG �����ɺͻ��� Stage
1) DAG ����
1��DAG ��ʲô:
DAG(Directed Acyclic Graph ������ͼ)ָ��������ת��ִ�еĹ���,�з���,�ޱջ�(��ʵ���� RDD ִ�е�����);
ԭʼ�� RDD ͨ��һϵ�е�ת���������γ��� DAG ������ͼ,����ִ��ʱ,������ DAG ������,ִ�������ļ���(���ݱ�������һ������)��
2��DAG �ı߽�
��ʼ:ͨ�� SparkContext ������ RDD;
����:���� Action,һ������ Action ���γ���һ�������� DAG��
2) DAG ���� Stage
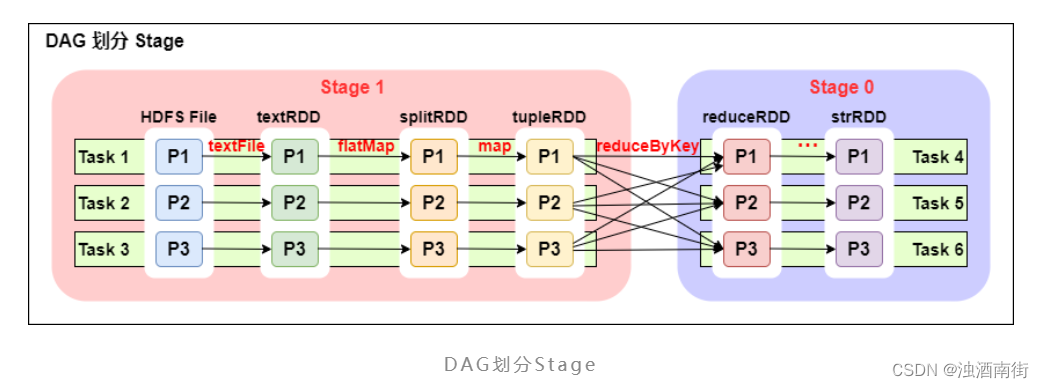
1������:
һ�� Spark ��������ж�� DAG(�м��� Action,���м��� DAG,��ͼ���ֻ��һ�� Action(ͼ��δ����),��ô����һ�� DAG)��
һ�� DAG �����ж�� Stage(���ݿ�����/shuffle ���л���)��
ͬһ�� Stage �����ж�� Task ����ִ��(task ��=������,����ͼ,Stage1 ������������ P1��P2��P3,��Ӧ��Ҳ������ Task)��
���Կ������ DAG ��ֻ reduceByKey ������һ��������,Spark �ں˻��Դ�Ϊ�߽罫��ǰ�ֳɲ�ͬ�� Stage��
ͬʱ���ǿ���ע�,��ͼ�� Stage1 ��,�� textFile �� flatMap �� map ����խ����,�⼸�����������γ�һ����ˮ�߲���,ͨ�� flatMap �������ɵ� partition ���Բ��õȴ����� RDD �������,���Ǽ������� map ����,�����������˼����Ч�ʡ�
2��ΪʲôҪ���� Stage? --���м���
һ�����ӵ�ҵ��������� shuffle,��ô����ζ��ǰ��β��������,����ִ����һ����,����һ���εļ���Ҫ������һ���ε����ݡ���ô���ǰ��� shuffle ���л���(Ҳ���ǰ��տ��������л���),�Ϳ��Խ�һ�� DAG ���ֳɶ�� Stage/��,��ͬһ�� Stage ��,���ж�����Ӳ���,�����γ�һ�� pipeline ��ˮ��,��ˮ���ڵĶ��ƽ�еķ������Բ���ִ�С�
3������ DAG �� stage?
����խ����,partition ��ת�������� stage ����ɼ���,������(��խ��������������ͬһ�� stage ��,����ʵ����ˮ����)��
���ڿ�����,������ shuffle �Ĵ���,ֻ���ڸ� RDD ������ɺ�,���ܿ�ʼ�������ļ���,Ҳ����˵��ҪҪ���� stage��
�ܽ�:
Spark ����� shuffle/������ʹ�û����㷨���� DAG ���� Stage ����,�Ӻ���ǰ,�����������ͶϿ�,����խ�����Ͱѵ�ǰ�� RDD ���뵽��ǰ�� stage/����;
����Ļ����㷨��μ�����:http://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se

