目录
3、将user_table.txt中的数据最终导入到数据仓库Hive中。
??(4)查询2014年12月10日到2014年12月13日有多少人浏览了商品
??(5)以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数
??(6)给定时间(2014-12-12)和给定地点(江西),求当天发出到该地点的货物的数量。因 为省份随机,答案不确定。
??(7)查询某一天(2014-12-12)在该网站购买商品超过5次的用户id 。
1、数据
raw_user.csv:完整用户数据,记录2000万左右(见网盘-实验步骤-综合案例1数据)
small_user.csv:子集,方便测试,记录30万条
我们用small_user.csv这个小数据集进行实验,这样可以节省时间。等所有流程都跑通以后,可以使用大数据集raw_user.csv去测试。
使用file_zilla上传数据,并修改文件权限:
chmod 755 /home/hadoop/data/small_user.csv
2、数据预处理
(1)删除首行数据
sed -i '1d' small_user.csv(2)对字段进行预处理
建一个脚本文件pre_deal.sh,把这个脚本文件和数据集small_user.csv放在同一个目录下。
vim pre_deal.sh文件内容:
#下面设置输入文件,把用户执行pre_deal.sh命令时提供的第一个参数作为输入文件名称
infile=$1
#下面设置输出文件,把用户执行pre_deal.sh命令时提供的第二个参数作为输出文件名称
outfile=$2
#注意!!最后的$infile > $outfile必须跟在}’这两个字符的后面
awk -F "," 'BEGIN{
srand();
id=0;
Province[0]="山东";Province[1]="山西";Province[2]="河南";Province[3]="河北";Province[4]="陕西";Province[5]="内蒙古";Province[6]="上海市";
Province[7]="北京市";Province[8]="重庆市";Province[9]="天津市";Province[10]="福建";Province[11]="广东";Province[12]="广西";Province[13]="云南";
Province[14]="浙江";Province[15]="贵州";Province[16]="新疆";Province[17]="西藏";Province[18]="江西";Province[19]="湖南";Province[20]="湖北";
Province[21]="黑龙江";Province[22]="吉林";Province[23]="辽宁"; Province[24]="江苏";Province[25]="甘肃";Province[26]="青海";Province[27]="四川";
Province[28]="安徽"; Province[29]="宁夏";Province[30]="海南";Province[31]="香港";Province[32]="澳门";Province[33]="台湾";
}
{
id=id+1;
value=int(rand()*34);
print id"\t"$1"\t"$2"\t"$3"\t"$5"\t"substr($6,1,10)"\t"Province[value]
}' $infile > $outfile执行pre_deal.sh脚本文件,对small_user.csv进行数据预处理
./pre_deal.sh small_user.csv user_table.txt3、将user_table.txt中的数据最终导入到数据仓库Hive中。
(1)将user_table.txt上传到hdfs的 /bigdatacase/dataset下
hdfs??dfs ?-put ?/home/hadoop/bigdatacase/dataset/user_table.txt??/bigdatacase/dataset(2)在hive下建立一个新的数据库
create database zxzx;(3)创建外部表,并将user_table.txt已经上传至hdfs的数据存进hive下
CREATE EXTERNAL TABLE zxzx_user(
id INT,
uid STRING,
item_id STRING,
behavior_type INT,
item_category STRING,
visit_date DATE,
province STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE LOCATION '/bigdatacase/dataset';4、基于hive分析数据
(1)查找前20位顾客购买日期和种类。
select visit_date, item_category
from zxzx_user
limit 20;
(2)查询用户id不重复的有多少条记录?
select count(distinct uid)
from zxzx_user;
(3)查询不重复的数据有多少条?
select count(*) from (
select uid,item_id,behavior_type,item_category,visit_date,province
from zxzx_user
group by uid,item_id,behavior_type,item_category,visit_date,province
having count(*)=1
)a;
(4)查询2014年12月10日到2014年12月13日有多少人浏览了商品
select count(*)
from zxzx_user
where behavior_type='1' and
visit_date<'2014-12-14' and
visit_date>'2014-12-09';
(5)以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数
select count(uid), day(visit_date)
from zxzx_user
where behavior_type='4'
group by day(visit_date); 
(6)给定时间(2014-12-12)和给定地点(江西),求当天发出到该地点的货物的数量。因为省份随机,答案不确定。
select count(*)
from zxzx_user
where visit_date ='2014-12-11' and
province='江西' and
behavior_type='4'; (7)查询某一天(2014-12-12)在该网站购买商品超过5次的用户id 。
select uid,count(behavior_type)
from zxzx_user
where behavior_type='4' and
visit_date='2014-12-12'
group by uid
having count(behavior_type)>5;
(8)每个地区浏览次数(答案不确定)
select province,count(behavior_type)
from zxzx_user
group by province;5、可视化
(1)求每天的成交量,递减展示。
1.(hive下)首先将每天的成交量计算出来,并建立一个有关成交量的新表(zx_shiyan1)(数据库名:zxzx)
create table zx_shiyan1 as
select visit_date,count(visit_date)
from zxzx_user
group by visit_date,behavior_type
having behavior_type='4' ;
?2.(hive下)将数据导出到hdfs
INSERT OVERWRITE ?DIRECTORY '/hive'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from zx_shiyan1;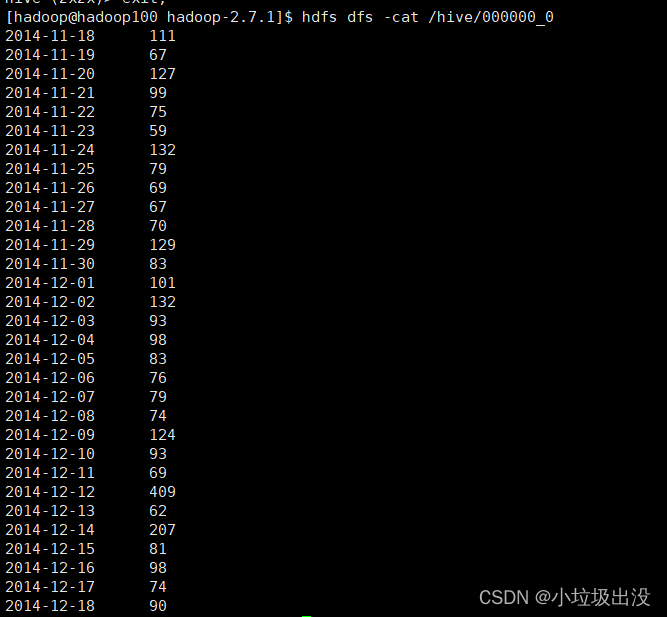
3.导出数据到mysql
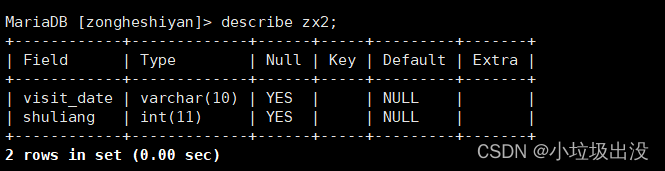
(1)建表(mysql下)(数据库名:zongheshiyan)
create table zx2(
visit_date?varchar(10),
shuliang int
); ??
?(2)执行导出

sqoop export --connect "jdbc:mysql://localhost:3306/zongheshiyan?useUnicode=true&characterEncoding=utf-8" \
--username root --password root \
--export-dir '/hive/000000_0' --table zx2\
--input-fields-terminated-by '\t' --driver com.mysql.jdbc.Driver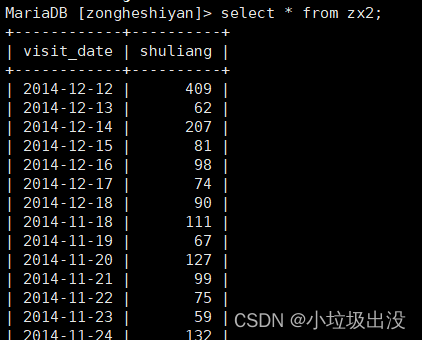
4.添加一个guest用户,可以远程访问mysql下,zongheshiyan数据库里的所有表
grant select,insert,update,delete on zongheshiyan.* to guest@"%" identified by "guest"; 5.在navicat下创建连接
?连接名随意,IP填写你要连接的地址,主机或者虚拟机

6.javaEE下jsp文件内容
<%@page pageEncoding="UTF-8" import="java.sql.*"%>
<!DOCTYPE html>
<html style="height: 100%">
<head>
<meta charset="utf-8">
<title></title>
</head>
<body style="height:600px; margin: 0">
<div id="main" style="width: 4000px;height:80%;"></div>
<script type="text/javascript" src="js/echarts.min.js"></script>
<script>
function show(title,value){
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
// 标题
title: {
text: '每天的成交量,递减展示'
},
// 工具箱
toolbox: {
show: true,
feature: {
saveAsImage: {
show: true
}
}
},
// 图例
legend: {
data: ['成交量']
},
// x轴
xAxis: {
data: title
},
yAxis: {
type: 'value'
},
// 数据
series: [{
name: '成交量',
type: 'bar',
data: value,
itemStyle: {
normal: {
label: {
show: true, //开启显示
position: 'top', //在上方显示
textStyle: { //数值样式
color: 'black',
fontSize: 16
}
}
}
},
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
}
</script>
<%
Class.forName("com.mysql.jdbc.Driver");
String url="jdbc:mysql://你自己的IP:3306/zongheshiyan";
Connection con=DriverManager.getConnection(url,"guest","guest");
String sql="select * from zx2 order by shuliang desc";
PreparedStatement pst=con.prepareCall(sql);
ResultSet rs=pst.executeQuery();
%>
<script type="text/javascript">
title=new Array();
value=new Array();
<%
while(rs.next()){
%>
title.push("<%=rs.getString(1)%>");value.push(<%=rs.getInt(2)%>);
<%
}
rs.close();
pst.close();
con.close();
%>
show(title,value);
</script>
</body>
</html>7.成果展示
?
(2)访问量前10名的商品种类。
1.首先将各类商品的访问量计算出来,并建立一个有关访问量的新表(zx_shiyan)
create table zx_shiyan as
select item_category,count(uid)
from zxzx_user
group by item_category;2.将数据导出到hdfs
INSERT OVERWRITE DIRECTORY '/hive'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from zx_shiyan;3.导出数据到mysql
1.建表
create table zx(
item_category int,
shuliang int
);2.执行导出
sqoop export --connect "jdbc:mysql://localhost:3306/zongheshiyan?useUnicode=true&characterEncoding=utf-8" \
--username root --password root \
--export-dir '/hive/000000_0' --table zx?\
--input-fields-terminated-by '\t' --driver com.mysql.jdbc.Driver4成果展示:

(3)购买量前10名的用户。
1.首先将所有用户的购买量计算出来,并建立一个有关购买量的新表(zx_shiyan33)
create table zx_shiyan33 as
select uid,count(uid)
from zxzx_user ?
group by uid,behavior_type
having behavior_type='4' ;2.将数据导出到hdfs
INSERT OVERWRITE ?DIRECTORY '/hive'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from zx_shiyan33;3.导出数据到mysql
1.建表
create table zx3(
uid int,
shuliang int
);2.执行导出
sqoop export --connect "jdbc:mysql://localhost:3306/zongheshiyan?useUnicode=true&characterEncoding=utf-8" \
--username root --password root \
--export-dir '/hive/000000_0' --table zx3?\
--input-fields-terminated-by '\t' --driver com.mysql.jdbc.Driver4.成果展示:

关于可视化jsp代码,参考实验一
只需修改一下title、图例、数据name以及sql语句
要注意ip地址写对、sql的数据库名称正确

