ЮФеТФПТМ
MapReduceЖЈвх
MapReduceЪЧвЛИіЗжВМЪНдЫЫуГЬађЕФБрГЬПђМм,ЪЧгУЛЇПЊЗЂЁАЛљгкHadoopЕФЪ§ОнЗжЮігІгУЁБЕФКЫаФПђМмЁЃ
MapReduceКЫаФЙІФмЪЧНЋгУЛЇБраДЕФвЕЮёТпМДњТыКЭздДјФЌШЯзщМўећКЯГЩвЛИіЭъећЕФЗжВМЪНдЫЫуГЬађ,ВЂЗЂдЫаадквЛИіHadoopМЏШКЩЯЁЃ
MapReduceКЫаФЫМЯы
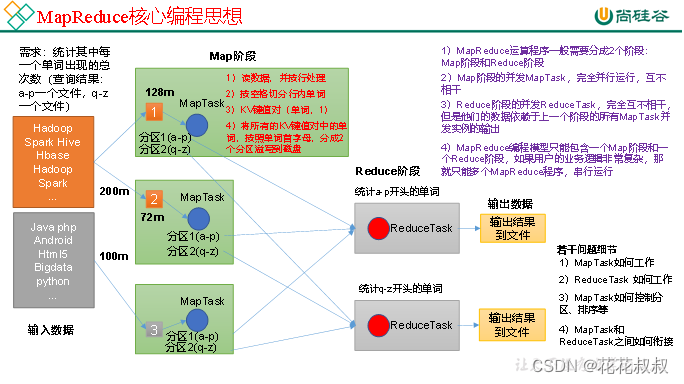
(1)ЗжВМЪНЕФдЫЫуГЬађЭљЭљашвЊЗжГЩжСЩй2ИіНзЖЮЁЃ
(2)ЕквЛИіНзЖЮЕФMapTaskВЂЗЂЪЕР§,ЭъШЋВЂаадЫаа,ЛЅВЛЯрИЩЁЃ
(3)ЕкЖўИіНзЖЮЕФReduceTaskВЂЗЂЪЕР§ЛЅВЛЯрИЩ,ЕЋЪЧЫћУЧЕФЪ§ОнвРРЕгкЩЯвЛИіНзЖЮЕФЫљгаMapTaskВЂЗЂЪЕР§ЕФЪфГіЁЃ
(4)MapReduceБрГЬФЃаЭжЛФмАќКЌвЛИіMapНзЖЮКЭвЛИіReduceНзЖЮ,ШчЙћгУЛЇЕФвЕЮёТпМЗЧГЃИДдг,ФЧОЭжЛФмЖрИіMapReduceГЬађ,ДЎаадЫааЁЃ
WordCountАИР§

HadoopађСаЛЏ
ађСаЛЏОЭЪЧАбФкДцжаЕФЖдЯѓ,зЊЛЛГЩзжНкађСа(ЛђЦфЫћЪ§ОнДЋЪфавщ)==вдБугкДцДЂЕНДХХЬ(==ГжОУЛЏ)КЭЭјТчДЋЪфЁЃ
вЛАуРДЫЕ,ЁАЛюЕФЁБЖдЯѓжЛЩњДцдкФкДцРя,ЙиЛњЖЯЕчОЭУЛгаСЫЁЃЖјЧвЁАЛюЕФЁБЖдЯѓжЛФмЫЭЕНЭјТчЩЯЕФСэЭтвЛЬЈМЦЫуЛњЁЃ ШЛЖјађСаЛЏПЩвдДцДЂЁАЛюЕФгЩБОЕиЕФНјГЬЪЙгУ,ВЛФмБЛЗЂЁБЖдЯѓ,ПЩвдНЋЁАЛюЕФЁБЖдЯѓЗЂЫЭЕНдЖГЬМЦЫуЛњЁЃ
MapReduceПђМмдРэ

InputFormatЪ§ОнЪфШы
MapTaskВЂааЖШОіЖЈЛњжЦ
Ъ§ОнПщ:BlockЪЧHDFSЮяРэЩЯАбЪ§ОнЗжГЩвЛПщвЛПщЁЃЪ§ОнПщЪЧHDFSДцДЂЪ§ОнЕЅЮЛЁЃ
Ъ§ОнЧаЦЌ:Ъ§ОнЧаЦЌжЛЪЧдкТпМЩЯЖдЪфШыНјааЗжЦЌ,ВЂВЛЛсдкДХХЬЩЯНЋЦфЧаЗжГЩЦЌНјааДцДЂЁЃЪ§ОнЧаЦЌЪЧMapReduceГЬађМЦЫуЪфШыЪ§ОнЕФЕЅЮЛ,вЛИіЧаЦЌЛсЖдгІЦєЖЏвЛИіMapTaskЁЃ

FileInputFormatЧаЦЌЛњжЦ

CombineTextInputFormatЧаЦЌЛњжЦ
1)гІгУГЁОА:
CombineTextInputFormatгУгкаЁЮФМўЙ§ЖрЕФГЁОА,ЫќПЩвдНЋЖрИіаЁЮФМўДгТпМЩЯЙцЛЎЕНвЛИіЧаЦЌжа,етбљ,ЖрИіаЁЮФМўОЭПЩвдНЛИјвЛИіMapTaskДІРэЁЃ
2)ащФтДцДЂЧаЦЌзюДѓжЕЩшжУ
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
зЂвт:ащФтДцДЂЧаЦЌзюДѓжЕЩшжУзюКУИљОнЪЕМЪЕФаЁЮФМўДѓаЁЧщПіРДЩшжУОпЬхЕФжЕЁЃ
3)ЧаЦЌЛњжЦ
ЩњГЩЧаЦЌЙ§ГЬАќРЈ:ащФтДцДЂЙ§ГЬКЭЧаЦЌЙ§ГЬЖўВПЗжЁЃ


