���ķ����Ի�Ϊ��������FusionInsight MRS HDFS ϸ�������Ż�ʵ����,����:pippo��
����
? ? ?HDFS����NameNode��Ϊ��Ԫ���ݷ���NameNode�����������ռ���Ϣ�������ڴ����ṩ����ȡ����(getBlockLocations��listStatus��getFileInfo)�ȴ��ڴ��л�ȡ��Ϣ��д����(mkdir��create��addBlock)�����ڴ�״̬,������־����д�뵽��־����(QJM)��
? ? ?HDFS NameNode�����ܾ���������Hadoop��Ⱥ�Ŀ���չ�ԡ������ռ����ܵĸĽ����ڽ�һ����չHadoop��Ⱥ������Ҫ��
- ? ? ?Apache HDFS ����ܹ�����:
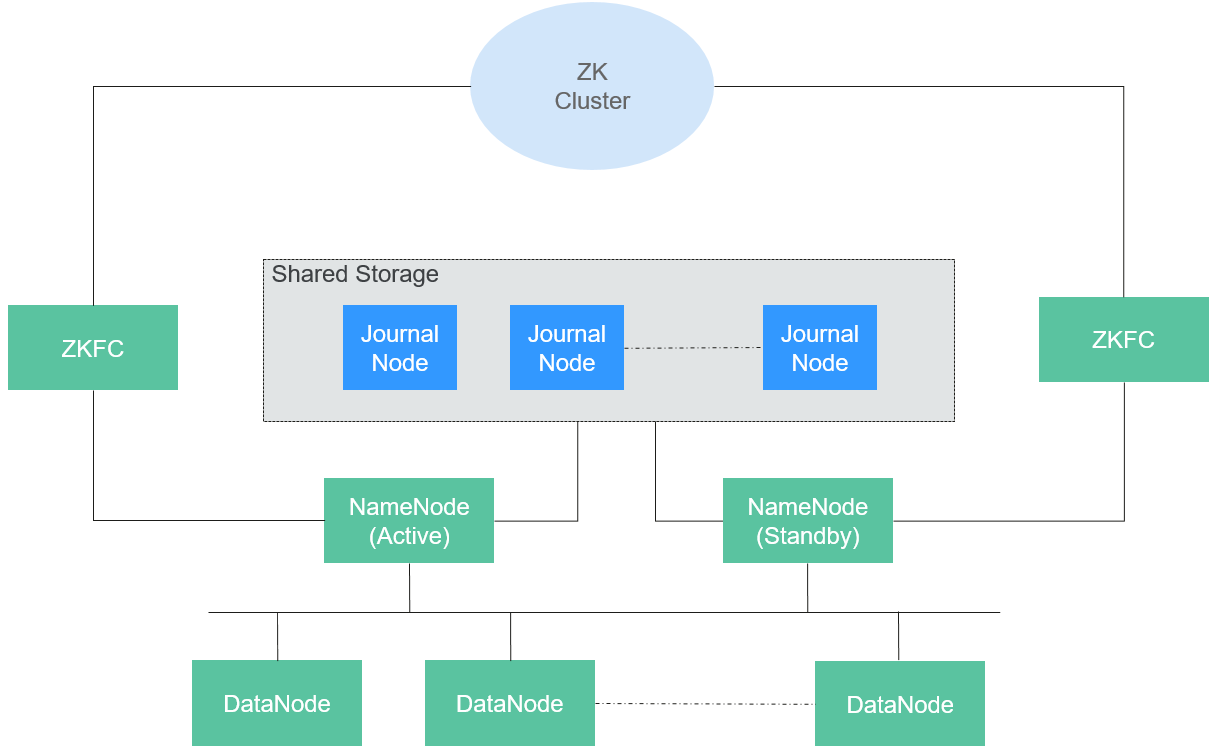
- ? ? ?Apache HDFS ������Ϣ����:
? ? ?
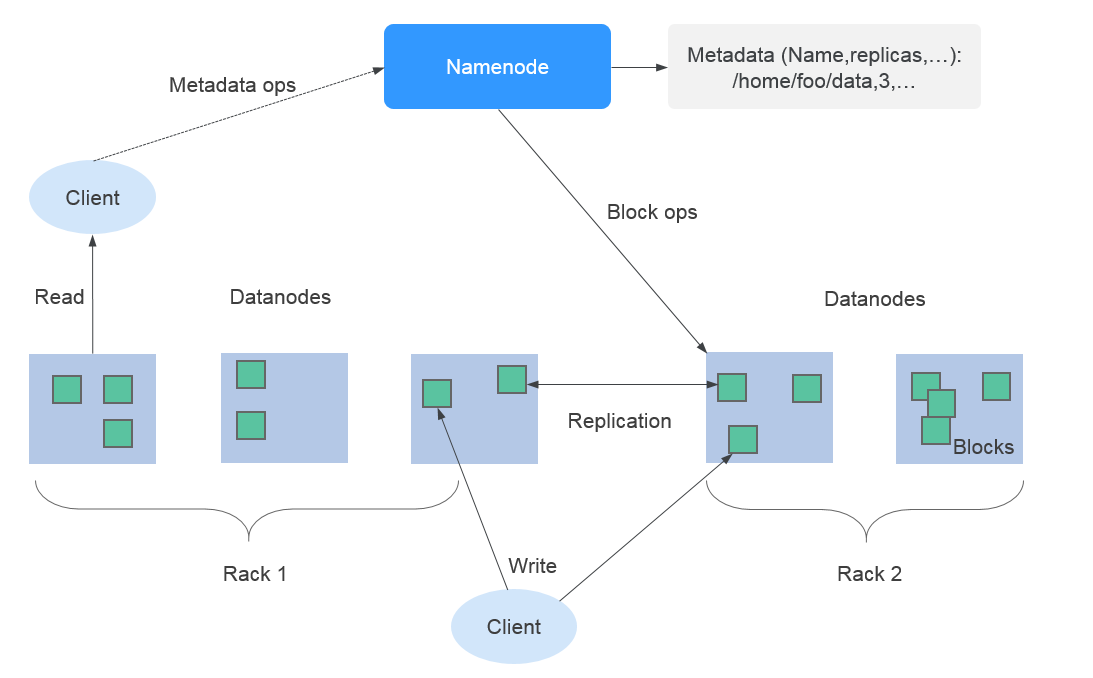
ʹ��
? ? ? HDFS NameNode��д������������ȫ�������ռ�ϵͳ�������ơ�ÿ��д���������ȡ����������,ֱ���ò���ִ����ɡ��������Է�ֹд������IJ���ִ��,��ʹ��������ȫ������,���������ռ��еĶ����ཻ���֡�
ʲô��Fine Grained Locking(FGL)
? ? ? FGL��ϸ������������ҪĿ����ͨ���ڶ��������ռ�������ö���������滻ȫ����,����д������IJ�����?
��ǰ״̬
? ? ??HDFS���˼·Ϊһ��д,��ζ���������ʹ�ù�����,д����ʹ�ö�ռ��������HDFS NameNodeԪ���ݱ����Ϊ�����ڴ�ռ��е������ռ���,��������κμ����д����������������д����,ֱ����ǰд������ɡ���Ȼд��һ��,���ǵ��漰����������/д����ʱ,��ͻ�Ӱ���������ܡ�
? ? ?��HDFS NameNode��,�ڴ��е�Ԫ���������ֲ�ͬ�����ݽṹ:
- INodeMap: inodeid -> INode
- BlocksMap: blockid -> Blocks
- DataNodeMap: datanodeId -> DataNodeInfo
? ? ?INodeMap�ṹ�а���inodeid��INode��ӳ��,������NamespaceĿ¼���ִ������ֲ�ͬ���͵�INode���ݽṹ:INodeDirectory��INodeFile������INodeDirectory��ʶ����Ŀ¼���е�Ŀ¼,INodeFile��ʶ����Ŀ¼���е��ļ���
? ? ?BlocksMap�ṹ�а���blockid��BlockInfo��ӳ�䡣ÿһ��INodeFile�������������ͬ��Block,�����������ļ���С�Լ�ÿ��Block��С������,��ЩBlock���������ļ����Ⱥ�˳�����BlockInfo����,BlockInfoά������Block��Ԫ����;ͨ��blockid���Կ��ٶ�λBlock��
? ? DataNodeMap�������datanodeid��DataNodeInfo��ӳ�䡣����Ⱥ����������,ͨ�����ܸ�֪������������Ⱥ�Ļ������˽ṹ,һ����NameNode�����������ڲ��ᷢ����仯��
? ? ?ͨ��INodeMap��BlocksMap��ͬ��ʶ�洢��HDFS�е�ÿ���ļ���������Ϣ�������ļ�����������,�����ݽṹ��СҲ����֮����,���Ե���ȫ���������ܲ����ܴ�Ӱ�졣�������Dz��ü��ļ�Ŀ¼���ṹ����ʾ���еĵ�һȫ�������ļ�ϵͳ��ȱ�㡣
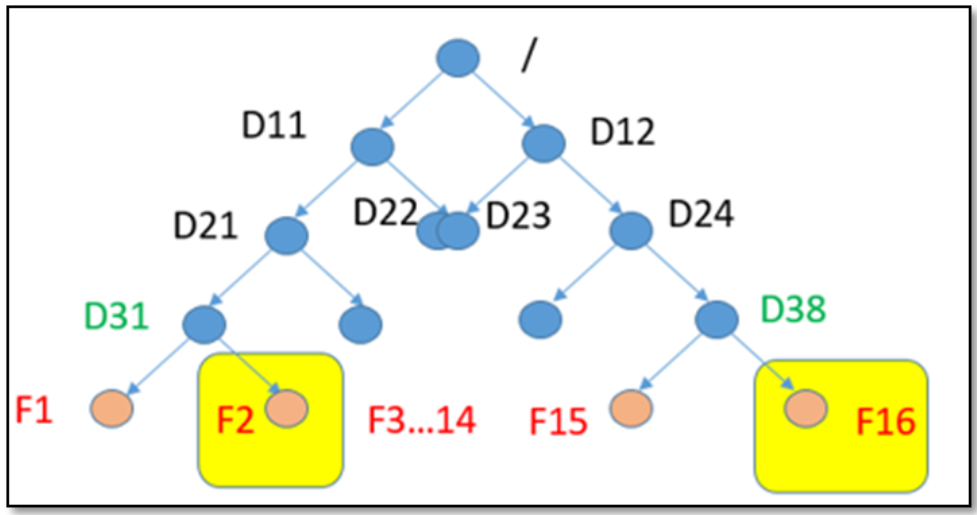
?HDFS NameNode �ڴ�Ŀ¼���ṹ
? ? ? ?����ͼ��ʾ,/D11/D21/D31/F2 �� /D12/D24/D38/F16�Dz��ཻ���ļ�,���в�ͬ�ĸ��ڵ���游�ڵ㡣���Կ���F2��F16�������������ļ�,������һ���ļ����κβ�������Ӧ��Ӱ����һ���ļ���
���
? ? ? ��ǰ����,HDFS NameNode���ļ���Ϣ��Ԫ���ݽṹ���ڴ��б���Ϊһ��Ŀ¼���ṹ���������������������ļ�ʱ,�ڶ��β�����Ҫ�ȵ���һ�β�����ɲ��ͷ������ͷ����Ժ�,ֻ�еڶ���������ȡ������ܼ������ļ�ϵͳ�����Ƶ�,��������Ҳ������,ֱ���ڶ��β����ͷ�����
? ? ? �������������,���ǿ���2���ļ�����д��(������ɾ�����ӡ�����)������F2��F16���ļ�ϵͳ�µ�2�������ļ�(���в�ͬ�ĸ��ڵ���游�ڵ�)���ڽ������ӵ�F2ʱ,F16Ҳ����ͬʱ�����ġ�������������Ŀ¼��ȫ�ֶ�����,��F16�IJ�������ȶ�F2�IJ�����ɺ����ִ�С�
? ? ? ����ȫ����,���Խ����ֲ���һ����Ϊ�����������ļ���,ÿ���������������Լ�����������F2���ڷ���-1,F16���ڷ���-2��F2�ļ���������ͨ����ȡ����-1������������,F16�ļ���������ͨ����ȡ����-2�����������ġ�
? ? ? ����ǰһ��,��Ҫ�Ȼ�ȡȫ����,Ȼ������ÿ���ļ������ĸ��������ҵ�������,��ȡ���������ͷ�ȫ���������ȫ������������ȫ��ɾ�����෴,ͨ������ȫ����ʱ����,һ���ͷ�ȫ����,������д�������Ի�ȡȫ������������ȡ�������������ļ�������
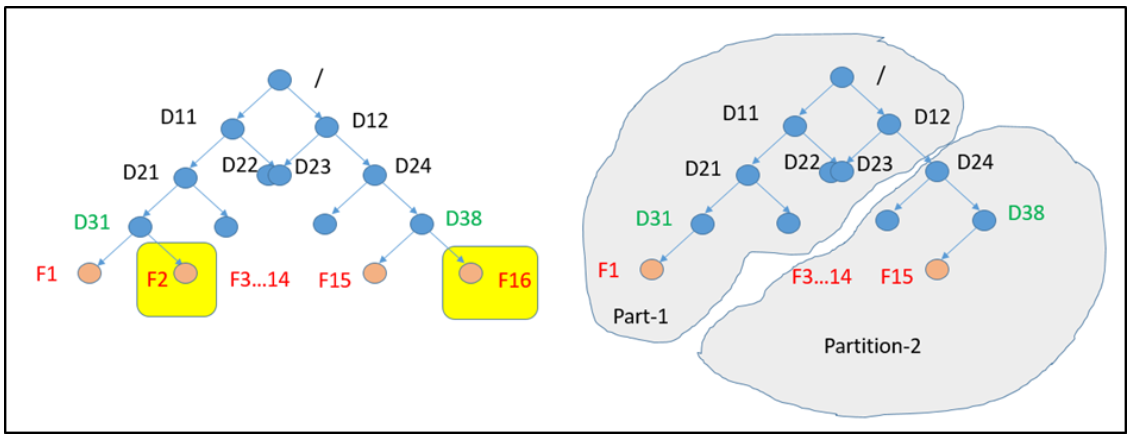
? ? ? ?������������ξ���?�����Ч�Ķ�������Ӷ���ø��ߵ�������?
? ? ? ?Ĭ�������,������СΪ65K,���ϵ��Ϊ1.8��һ�������ﵽ�������,���ᴴ���·��������뵽�����б��С����������,����ӵ�е���NameNode����CPU�����ķ�����,����ķ�����������ʹ��CPU����,�����ٵķ����������������CPU��
ʵ��
? ? ? ?�����µ����ݽṹ-PartitionedGSet,�����������ռ䴴�������з�����Ϣ��PartitionEntry��һ�������Ķ���ṹ��LatchLock�����������,���ڿ���������--��������������
PartitionedGSet
? ? ? ?PartitionedGSet��һ��������νṹ����һ��RangeMap������INode�ķ�Χ,��������ӳ�䵽��Ӧ�ķ����С����������˲�νṹ�ĵڶ���,ÿ�������洢����ָ����Χ��INode��Ϣ��Ϊ�˸��ݼ�ֵ����INode,��Ҫ������RangeMap���ҵ���Ӧ��ֵ�ķ�Χ,Ȼ���ڶ�Ӧ��RangeSet,ʹ�ù�ϣֵ��ȡ����Ӧ��INode��
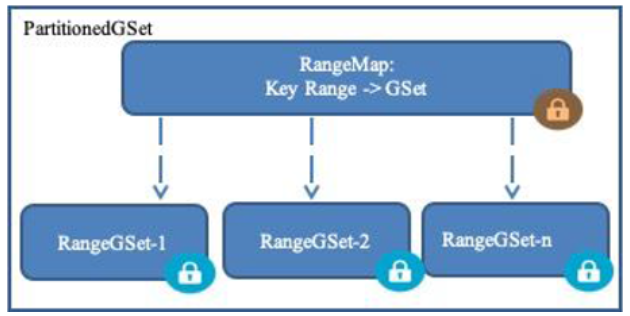
HDFS NameNode ������νṹ
? ? ? RangeGSet��������һ������ֵ�����ﵽ��ֵ��,�������µ�RangeGSet���յĻ���δ������õ�RangeGSet�ɺ�̨RangeMonitor�ػ������������������ա�
? ? ? HDFS NameNode����ʱ,���ݾ����е�INode������������ij�ʼ��������ͬʱ����Ҫ����CPU����,��Ϊ������������ߵ�Զ��CPU��������������ϵͳ�IJ����ԡ�
- ��̬����:�����Ĵ�С����,������ƽ����һ�����Խ��з��Ѻͺϲ���
- ��������:ֻ��һ������,��ֻ��һ����֮���Ӧ����,����Ӧ��ȫ�������ơ���������С�ͼ�Ⱥ��д�븺�رȽ���ļ�Ⱥ��
- ��̬����:��һ���̶���RangeMap,�����ӻ��ߺϲ����з������������ڷ��������������ļ�ϵͳ�������⽫��������RangeMap��Ҫ��,��������ʹ������
Latch Lock
? ? ?RangeMap��RangeGSet�ֱ��е���������Latch Lock��һ����ģʽ,�������Ȼ�ȡRangeMap����,�Բ��������INode����Ӧ�ķ�Χ,Ȼ���ȡ�������Ӧ��RangeGSet����,ͬʱ�ͷ�RangeMap������������κ�������Χ����һ�����������Կ�ʼ����ִ�С�
? ? ?��RangeMap�ϳ�����������ȫ������Ŀ¼ɾ�������������ݹ鴴��Ŀ¼�ȼ�������������Ҫ�������RangeGSet����Ҫȷ����ǰHDFS������Ҫ��IJ�����ԭ���ԡ�����,������������ļ���һ��Ŀ¼�ƶ�����һ��Ŀ¼,��������������ļ���Դ��Ŀ��Ŀ¼��RangeMap,�Ա�ʹ��������Ϊԭ�ӡ�������ģʽ��һ�������Ż�������ijЩ������Latch Lock������������ȫ�������ʹ�á�
INode Keys
? ? ?HDFS�е�ÿ��Ŀ¼���ļ�����һ��Ψһ��INode,��ʹ�ļ��������������ƶ�������λ��,��INode�ᱣ�ֲ��䡣INode�������ļ�INode������β,ǰ�������INode�Ĺ̶��������С�
? ? ? Key Definition:??key(f) = <ppId, pId, selfId>
? ? ? selfId���ļ���INodeId,pId�Ǹ�Ŀ¼��INodeId,ppId�Ǹ�Ŀ¼�ĸ�Ŀ¼��INodeId��INode�������ֱ��ﲻ����֤��ͬ��,ͬʱҲ��֤�˱���(��ͬ�游�ڵ�)�ڴ��������±���������ͬ�ķ�Χ�С���Щ������INodeId�����ļ���,�������ļ���Ŀ¼����������,��Ϊ�͵�������,���������½��з�����
��
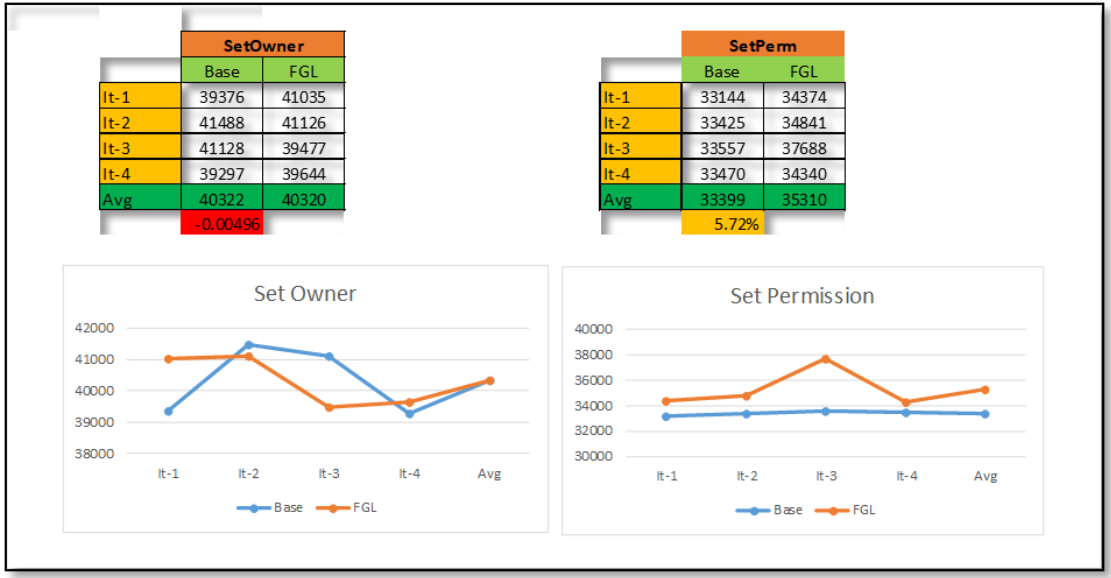
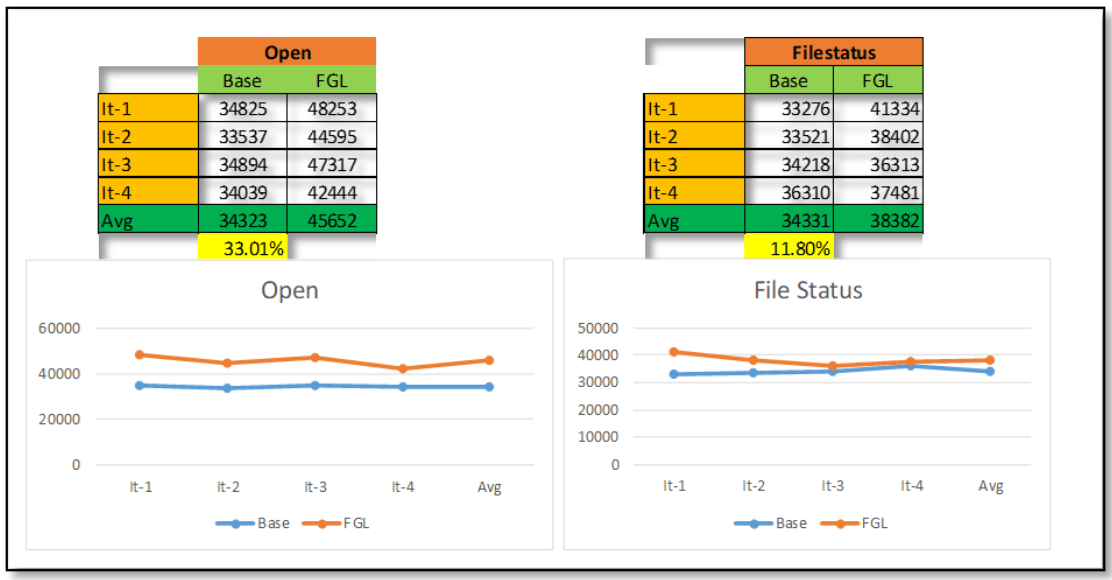
? ? ? ����������֤ʹ�úͲ�ʹ��FGL��������,����Ҫд����������,������ƽ�������25%���ҡ�
��ϸ���ܶԱ�
? ? ? ʹ��Hadoop NN Benchmarking����(NNThroughputBenchmark)����֤NameNode�����ܡ�ÿ��д��API��֤���۲쵽ƽ��25%�������������к���һ����������û��������API,������������ЩAPI����������API,���û��̫���������
? ? ? ?NNThroughputBenchmark������NameNode���ܻ����Թ��ߡ��ù����ṩ�˷dz�������API����,���紴���ļ�,����Ŀ¼��ɾ��������������Ͻ�������ǿ,�Ӷ��ܹ�֧������д��API,���ܹ�����ʹ�úͲ�ʹ��FGL�İ汾���������ݡ�
? ? ? ���ڲ��Ե����ݼ�:�߳��� 1000���ļ��� 1000000��ÿ��Ŀ¼�ļ��� 40��
д�����Ƶ�ʸߵ�API

�����ڲ�дAPI
���ö�ȡAPI:
? ? ?ͨ��������FGLʵ��,��ȡAPIҲ�кܺõ�����������
���л����Թ��ߵ�����:
? ? ? ?./hadoop org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark -fs file:/// -op create -threads 200 -files 1000000 -filesPerDir 40 �Cclose
? ? ? ?./hadoop org.apache.hadoop.hdfs.server.namenode.NNThroughputBenchmark -fs hdfs:x.x.x.x:dddd/hacluster -op create -threads 200 -files 1000000 -filesPerDir 40 -close
�ο�
? ? ? ? ��FGL��ص���������
? ? ? ??Hadoop Meetup Jan 2019 ��?HDFS Scalability and Consistent Reads from Standby Node, which covers Three-Stage Scalability Plan. Slides 21�C25
? ? ? ? �����и�����NameNode����չ����ص�����Jira
? ? ? ??HDFS-5453. Support fine grain locking in FSNamesystem
? ? ? ? HDFS-5477. Block manager as a service
? ? ? ? HDFS-8286. Scaling out the namespace using KV store
? ? ? ? HDFS-14703. Namenode Fine Grained Locking (design inspired us to implement it fully)
�ܽ�
? ? ??��Ϊ��FusionInsight MRS��ԭ�����ݺ�Ϊ����ͻ��ṩ����һ�塢��ԭ�������ݺ��������,����һ���ܹ��ɳ����ݽ������ߡ�ʵʱ�����������ݺ�,֧������ͻ�ȫ�����ݵ�ʵʱ���������߷�����������ѯ��ʵʱ��������ģ���������ݲֿ⡢���ݽ���������ȴ�����Ӧ�ó�����
? ? ? ��Ϊ��FusionInsight MRSͨ��FGL��HDFS NameNode�����ƽ����Ż�,��Ч������NameNode�Ķ�д������,�Ӷ��ܹ�֧�ָ�������,����ҵ���������,�Ӷ����õ�֧������ͻ���Ч����,ҵ����,��ֵ���ָ��졣

