��ʦ����
��ѩ��,Cloudera�������ּܹ�ʦ,����Cloudera֮ǰ����Teradata��˾����7������ּܹ�ʦ,�ڴ����ݺ����ݲֿ�����ʮ���깤������,Ŀǰ������л������к�����鼰��ҵ�ͻ��ļ���֧�ֺͷ����ܹ���ơ�
��������Ϊѩ����ʦ����������������
���ȸ�л�����ṩ��λ���,Ҳлл��������μ�����һ��������,���ȼ���һ�����Լ�,�ҽ���ѩ��,��cloudera��ߵ��������û�����ʦ,��Ҫ�Ǹ��������й��ĺ���������ҵ�û�,Ϊ�����ṩһЩ���������һЩ����֧�֡�
 ����������������̲��ֳ���������֡�
����������������̲��ֳ���������֡�
��һ������,�һ����һ��ʵʱ���ַ�չ�Ľ�,����ôһ�����ݻ�������;�������ǿ�һ��ͨ�õ�ʵʱ���ֵķ����ܹ���ʲô���ӵ�;������,��Ϊ������Cloudera���,���Ի����ҿ���Cloudera����ν���ʵʱ���ֵ�,����ȥ��ʵʱ���ֵij�������һ�����ࡣҲ�����Cloudera��ʵʱ���ֵ���ϵ�ܹ�,�Լ�����һЩʵʱ���ּܹ������,ͨ����Щ������ҶԼ��������˽⡣
01 ʵʱ���ַ�չ�ṹ

���ݲֿ�ĸ������� 90 ����� Bill Inmon ���, ��ʱ�ı����Ǵ�ͳ�� OLTP ���ݿ����ܺõ�֧�ֳ����ڷ������߳���,�������ݲֿ����� 4 �����ĵ�,����Ҫ����� OLTP ���ݿʱ��״̬���Ա����⡣
1)��������:���ݲֿ��������֯��ʽ�� OLTP ������������ͬ����Ϊ���ݲֿ�������������ߵ�,�������ݾ������������������Ƿ��������������ʽ����֯��
2)����:�������ݲֿ���˵,������Ҫȥ���϶����ɢ�ġ��칹������Դ,��һЩ������ϴ�� ETL ����,���ϳ�һ�����ݲֿ�,OLTP ����Ҫ�����Ƶļ��ɲ�����
3)����ȶ�:OLTP ���ݿ�һ�㶼������ҵ���,����Ҫ�������ǰѵ�ǰ��ҵ��״̬���ķ�ӳ����,���� OLTP ���ݿ���Ҫ֧�ִ���������ɾ���ĵIJ��������Ƕ������ݲֿ���˵,ֻҪ����ִ�����������,һ��ʹ�ó������Dz�ѯ,�������������ȶ��ġ�
4)��ӳ��ʷ�仯:���ݲֿ��Ƿ�ӳ��ʷ�仯�����ݼ���,������������Ὣ��ʷ��һЩ���ݵĿ��մ������������� OLTP ���ݿ���˵,ֻҪ��ӳ��ʱ�����µ�״̬�Ϳ����ˡ�
������ 4 ���������ݲֿ��һ�����ĵĶ��塣
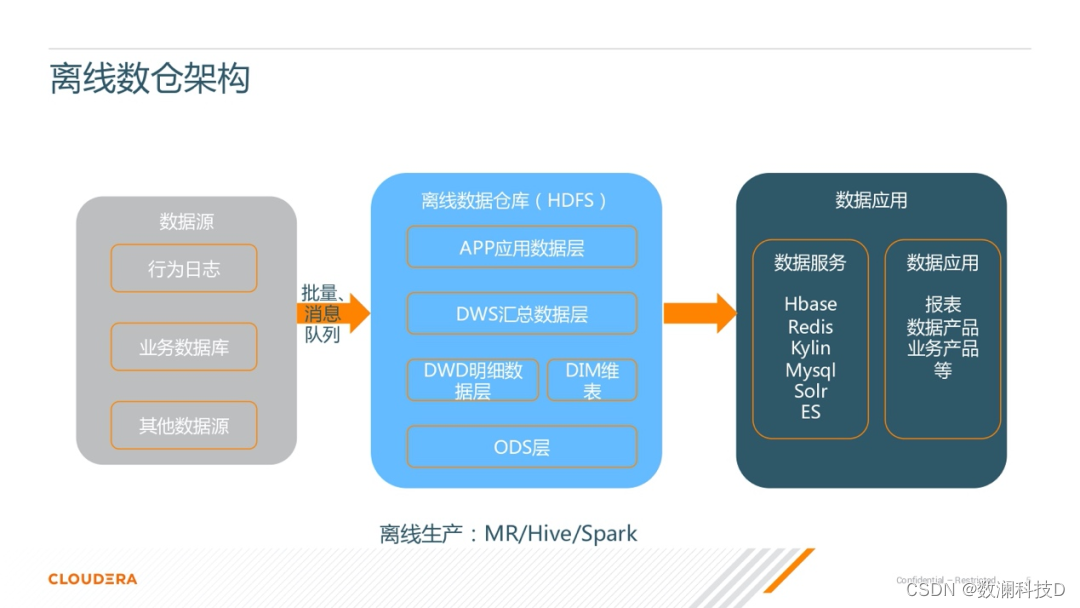
����ͼ���Կ��������������������Ļ��ڡ�
��һ������������Դ����,һ�㹫˾������Դ��Ҫ������:
1)��1����ͨ���ڿͻ�������ϱ�,�ռ��û�����Ϊ��־,�Լ�һЩ�����־����־��������Դ�����������Ϊ��־��˵,һ��ᾭ��һ������������,�������ݻ��ϱ��� Nginx Ȼ�� Flume �ռ�,Ȼ��洢�� Kafka ��������Ϣ����,Ȼ������ʵʱ�������ߵ�һЩ��ȡ������,��ȡ�����ǵ��������ݲֿ� HDFS��
2)��2������Դ��ҵ�����ݿ�,������ҵ�����ݿ�Ļ�,һ��ᾭ�� Canal �ռ����� binlog,Ȼ��Ҳ���ռ�����Ϣ������,�������� Camus ��ȡ�� HDFS��
3) ��������������Դ�����������Դ������ȡ�
������������Դ���ն�����ص� HDFS �е� ODS ��,Ҳ����Դ���ݲ�,������ݺ�ԭʼ����Դ�DZ���һ�µġ�
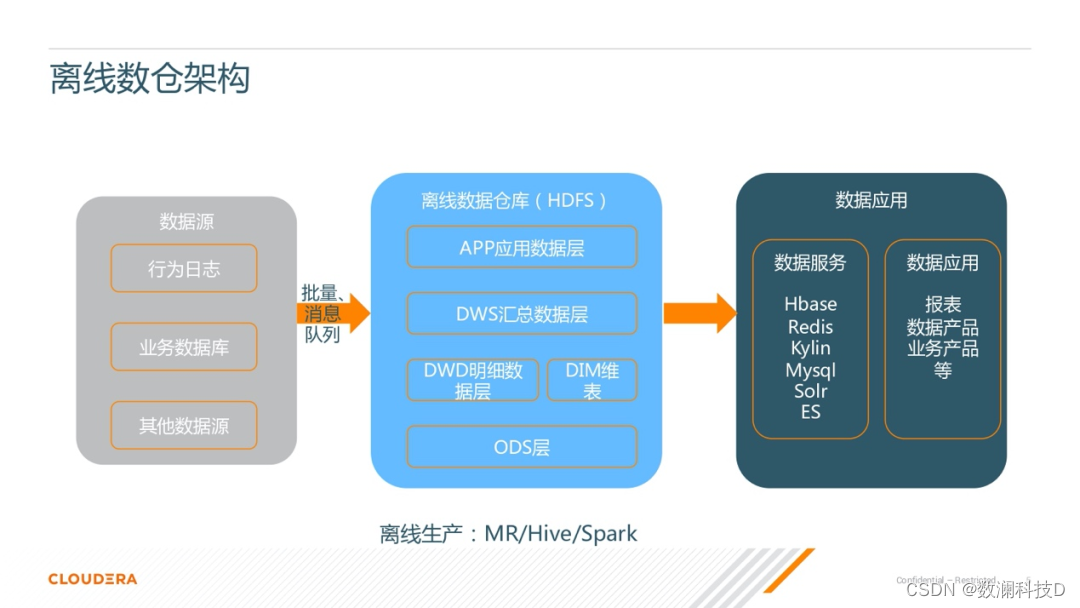
�ڶ����������������ݲֿ�,��ͼ����ɫ�Ŀ�չʾ�IJ��֡����Կ�������һ���ֲ�Ľṹ,���е�ģ�����������ά�Ƚ�ģ˼·��
1)��ײ��� ODS ��,��һ�㽫���ݱ�������Ϣ��ʧ�Ĵ���� HDFS,��������ԭʼ����־���ݲ��䡣
2) �� ODS ��֮��,һ������ͳһ��������ϴ����һ,�͵õ��� DWD ��ϸ���ݲ㡣��һ��Ҳ����ͳһ��ά�����ݡ�
3)Ȼ����� DWD ��ϸ���ݲ�,���ǻᰴ��һЩ��������������ʵ���ȥ��֯���ǵ�����,��֯��һЩ������Ļ������ݲ� DWS��
4)�� DWS ֮��,���ǻ�����Ӧ�ó���ȥ��һЩ������Ӧ�õ� APP Ӧ�����ݲ�,��Щ����Ӧ���Ǹ߶Ȼ��ܵ�,�����ܹ�ֱ�ӵ��뵽���ǵ�Ӧ�÷���ȥʹ�á�
���м���������ݲֿ����������,һ�㶼�Dz���һЩ���������ļܹ�����,����˵ MapReduce��Hive��Spark �ȵ�,����һ���Ǵ��� HDFS �ϡ�
����ǰ�������ں�,���ǵ�һЩӦ�ò�����ݻ�洢�����ݷ�����,����˵ HBase ��Redis��Kylin ������һЩ KV �Ĵ洢�����һ���Դ�����Щ���ݴ洢�ϵ�һЩ����,��װ��Ӧ�ķ���ӿ�,�����ṩ��������������ǻ�ȥ����һЩ����ҵ��ı�����������������ݲ�Ʒ,�Լ���֧�����ϵ�һЩҵ���Ʒ�ȵȡ���һ��Ļ�,��֮Ϊ������ҵ��˵�����Ӧ�ò��֡�

Խ��Խ��Ŀͻ�Ҫ��Ĺ�����:
1)����ʵʱ���ݡ���ʵʱ���ݺ���ʷ����
2)��������������,��ʹ��Щ�������Ǵ�ͳ�ϴ洢��һ���(����:ʵʱ�ͻ��¼�������CRM����һ��;���紫�����������г�Ӫ�����������һ��)
3)�������ݡ��ļ��˹�ģ,�����С�С���ݡ������������
4) �������������ݼ��ɵ�һ����ȫ�ļ���ƽ̨��
�ƶ���һ���Ƶ����ذ���������ҵ����Ļ���
l �ڼ�������,�������κ�ʱ������,�����ɵؼ���������ݲ�ͨ����Ϣ����ϵͳʵʱ�������ݡ�
l ��ҵ����,��˾���������ڽ��価���ܶ��ҵ�����ֻ����Զ���,��ʹ���ߺ��ʲ�����������Ч��
l ���Ļ�����,����ϣ���ܹ������������Ĵ�,������ȥ�ʱ���(��лGoogle��Wikipedia)��

����RTDW���������,������ڸо��Ͼ�������ͨ�����ݲֿ�,�������е�һ�ж����ĸ���,��ʹ���ָ����ģ�������ϡ��������ݲֿ��ִ�����һ������,���������С�С���ݡ�����͡������ݡ���ģ�����ܡ�
1)�����Ը�����ٶȵ���ֿ�C��Ϊÿ����������¼�����ý�����ݲ��ϵ���
2)���ݿ���Ѳ�ѯ�����ʱ�����-������������в�ѯ,������д������ۺϻ�ѹ��
3)��ѯ���е��ٶȸ���CС��ѡ���Բ�ѯ��10��100����Ϊ��λ���к���;���͡�ɨ�����㷱�صIJ�ѯ�ԺܸߵĴ�������
4) ��Ҫʱ,���ݱ仯�ĺܿ�-�������ij��ԭ����ҪУ�����������,�����������д���ɾ͵���ɡ�
�������������ƺ�������,������Щ����,����ʮ���������ݲֿ�ȴ��ʾ����������������ڴ������ٵ��������,Ҫ���ֽ������ܷdz�����,����һЩ���ݿ�����Ҫ����,������Ҫʹ�ô�����ͬģʽ�IJ�ѯ��
Cloudera�ṩ��RTDW����,������������Щ���д����,����ͻ����ڹ���RTDWӦ�ó���,��������ʹ��Cloudera�ִ������ݲֿ�ʵ����������Ե�һ���֡�
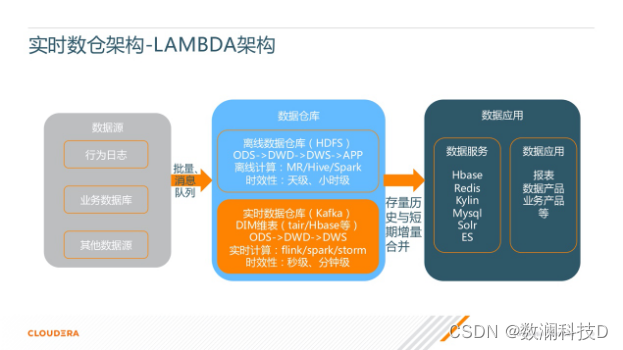
����ܹ��� Storm �������������,��ʵ Lambda �ܹ�����Ҫ˼·����ԭ���������ּܹ��Ļ����ϵ�����ʵʱ���ֵIJ���,Ȼ�����ߵĴ������������� t+0 ��ʵʱ��������һ�� merge,�Ϳ��Բ�������״̬ʵʱ���µĽ����
l �������������ݲֿ�ܹ�ͼ�ȽϿ������ԵĿ���,ʵʱ�������ӵIJ�������ͼ��ɫ�������������һ����ʵʱ�������ݷ��� Kafka ��������Ϣ������,Ҳ����ά�Ƚ�ģ��һЩ�ֲ�,�����ڻ������ݵIJ���,���Dz��Ὣ APP ���һЩ���ݷ���ʵʱ����,���Ǹ���Ļ��Ƶ����ݷ����ȥ��һЩ���㡣
l Ȼ����ʵʱ����IJ���,���Ǿ�����ʹ�� Flink��Spark-streaming �� Storm �����ļ�������,ʱЧ����,��ԭ�����켶��Сʱ�������������뼶�����Ӽ���
���Ҳ���Կ�������ܹ�ͼ��,�м����ݲֿ������������,һ�������ߵ����ݲֿ�,һ����ʵʱ�����ݲֿ⡣
���DZ���Ҫ��ά����(ʵʱ�����������)����,�����ڴ������,����Ҳ��Ҫȥʵ��ʵʱ�����ߵ�ҵ����롣
Ȼ���ںϲ���ʱ��,������Ҫ��֤ʵʩ�����ߵ�����һ����,���Ե������ǵĴ��������,����Ҳ��Ҫȥ������������ʵʱ�������ݵĶԱȺ�У�顣
��ʵ����ڲ�������Դ������ά�ɱ���˵���DZȽϸߵġ����� Lamda �ܹ��ϱȽ����Ժ�ͻ����һ�����⡣��˾Ͳ����� Kappa �ṹ��
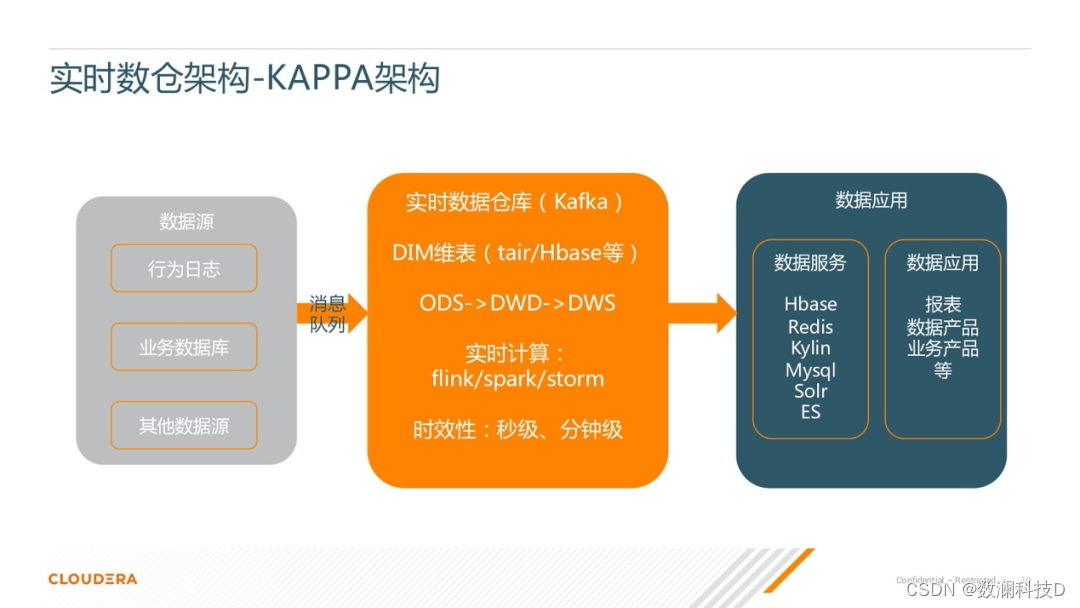
Kappa �ܹ���һ����Ҫ��˼·���������ֲ����Ƴ�����������,���ֵ�����ȫ������ʵʱ���֡�����ͼ���Կ����ղ��м�IJ���,��������ģ���Ѿ�û���ˡ�
����Kappa�ܹ�,ҵ�����ᵼ�¿ھ����,��������Ҫ����,������ˢ��ʷ���ݡ�Kappa �ܹ��Ľ��˼·��:����Ҫ����һ���ܹ��洢��ʷ���ݵ���Ϣ����,���� Kafka,���������Ϣ�����ǿ���֧�����ij����ʷ�Ľڵ����¿�ʼ���ѵġ�
������Ҫ����һ������,��ԭ���Ƚ����һ��ʱ��ڵ�ȥ���� Kafka �ϵ�����,Ȼ������µ��������еĽ����Ѿ��ܹ������ڵ������ܵ�������ƽ��ʱ��,��Ϳ�����������������л����µ���������,�ɵ�����Ϳ���ͣ��,����ԭ�������Ľ����Ҳ���Ա�ɾ����
������������ʵʱ OLAP ������һЩ����,��һ���µ�ʵʱ�ܹ������˳���,�������ҳ�Ϊʵʱ OLAP ���塣
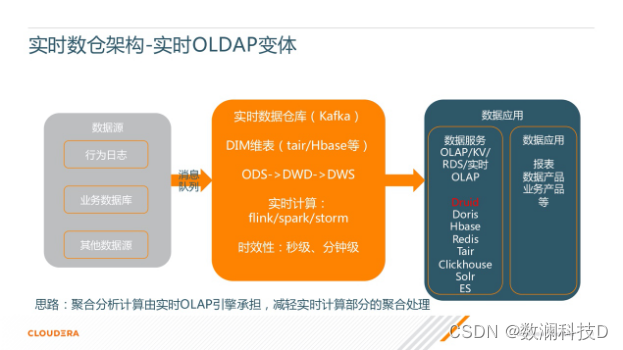
���˼·�ǰѴ����ľۺϡ�������������ʵʱ OLAP �������е�����ʵʱ���ּ���IJ���,���Dz���Ҫ�����ر���,�����Ǿۺ���ص�һЩ��,Ȼ�������Ϳ��Ա�������������Ӧ�ò���������Ը���ҵ�������������,�����ܹ�������

����������������ʵʱ���ּܹ���һ���Ա�:
1)�Ӽ�������Ƕ�:Lamda �ܹ�����Ҫȥά����������������,Kappa �ܹ���ʵʱ OLAP ����ֻ��Ҫά������������ͺ��ˡ�
2)�����ɱ�:�� Lamda �ܹ���˵,��Ϊ����Ҫά��ʵʱ�������״���,�������Ŀ����ɱ����һЩ��Kappa �ܹ���ʵʱ OLAP ����ֻ��ά��һ�״���Ϳ����ˡ�
3) ���������:ʵʱ OLAP ��������������ġ�
4)��ʵʱ OLAP ����������:ʵʱ OLAP ������ǿ����ʵʱ OLAP ���������������,ǰ������ǿ������
5)������Դ:Lamda �ܹ���Ҫ������������Դ,Kappa �ܹ�ֻ��Ҫ��������Դ,ʵʱ OLAP ������Ҫ����� OLAP ��Դ��
6)���������:Lamda �ܹ���ͨ���������������,Kappa �ܹ���Ҫ����ǰ����ܵķ�ʽȥ����������Ϣ��������,ʵʱ OLAP ����Ҳ��Ҫ����������Ϣ����,����������ݻ�Ҫ���µ��뵽 OLAP ������,ȥ�����㡣
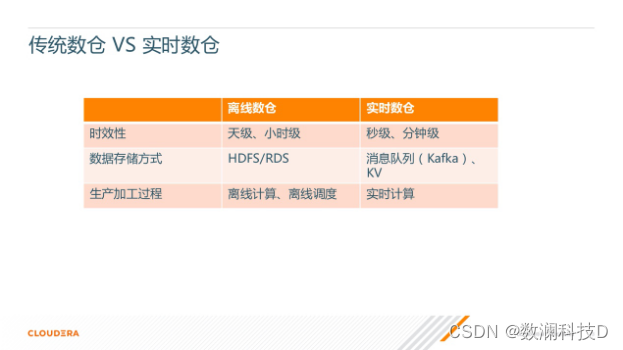
Ȼ����������һ�´�ͳ���ֺ�ʵʱ��������IJ��졣
l ���ȴ�ʱЧ������:����������֧��Сʱ�����켶��,ʵʱ���ֵ��뼶���Ӽ�,����ʵʱ����ʱЧ���Ƿdz��ߵġ�
l �����ݴ洢��ʽ����:������������Ҫ����HDFS��RDS����,ʵʱ����һ���Ǵ�����Ϣ����,����һЩkv�洢,��ά�����ݵĻ������Ĵ���kv�洢�ϡ�
l �������ӹ����̷���,����������Ҫ���������������Լ����ߵĵ��ȡ�������ʵʱ������˵,��Ҫ������ʵʱ�������档
02 ͨ�õ�ʵʱ���ַ����ܹ�

ʵʱ���ݴ����ı���������������δ֪״̬�µ�һ�־����ܿ��ٴ����ͻ��ܼ���,�������ݴ�������Ҫ�����������ʹ��ڻ������ַ�ʽ��
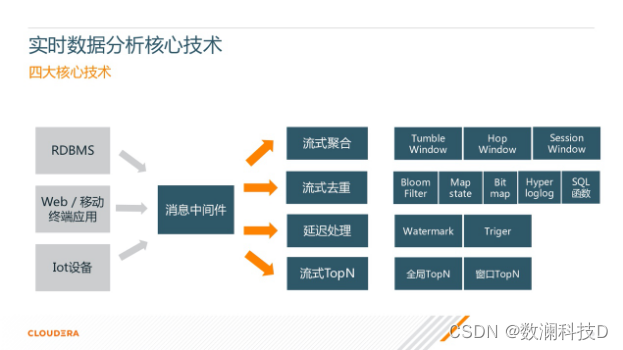
����join����������ǿ細������,�ᵼ��������������������,��ȫ��join�ֻᵼ��state�洢����,��˸����ǽ�����joinת��Ϊ����ά��֮���join,һ��ʹ��left join,��ά�������ڴ�/redis/mysql�С�ά����������,����hbase�С�����ǹ㲥��ʽ,ʹ��kafkaά����