前言
本文隶属于专栏《大数据安装部署》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
关联
1. 下载
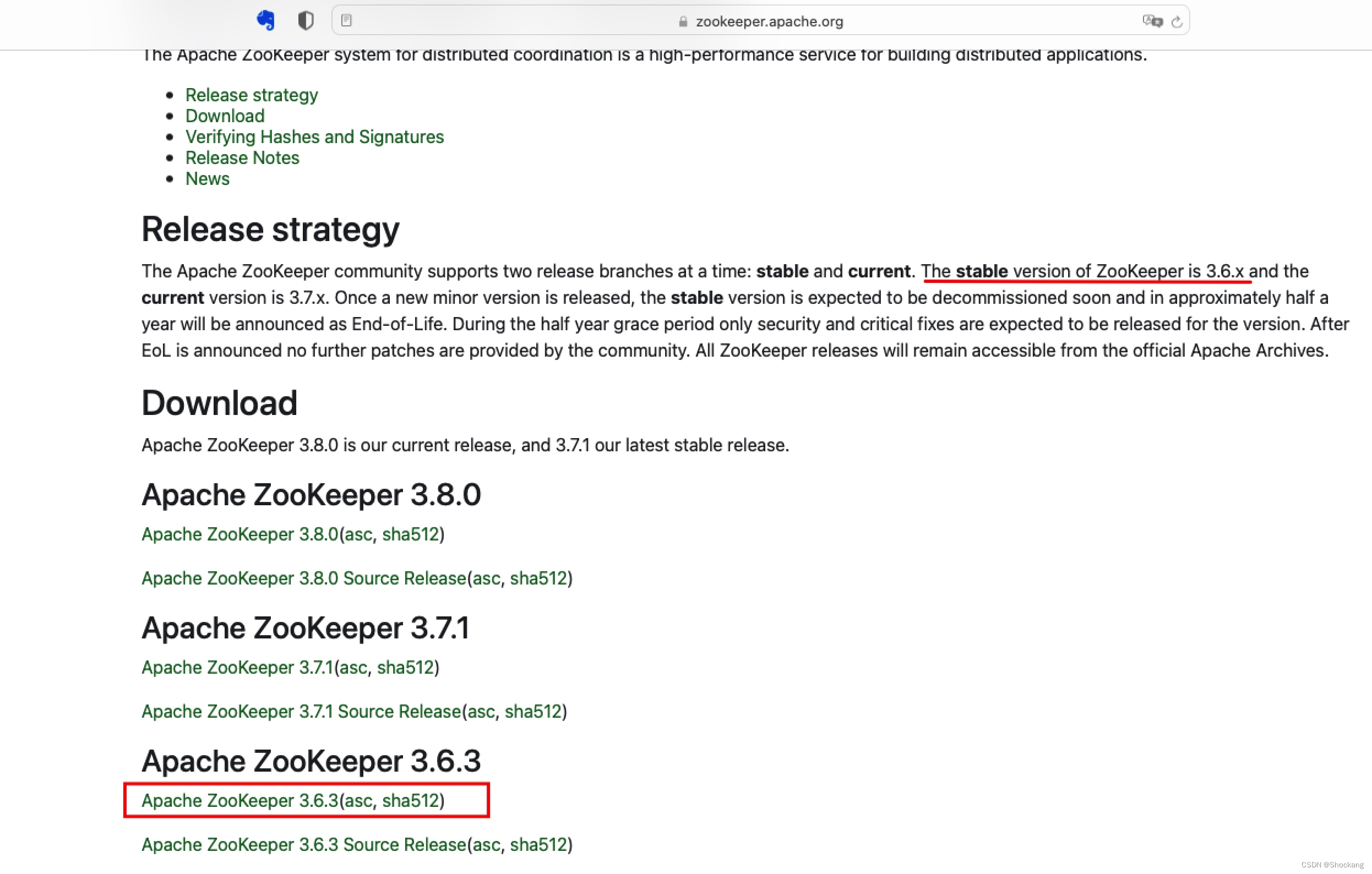
打开下载地址后,如下图点击 Apache ZooKeeper 3.6.3(asc, sha512) 下载
这里我们选择最新的稳定版本 3.6.3
2. 上传
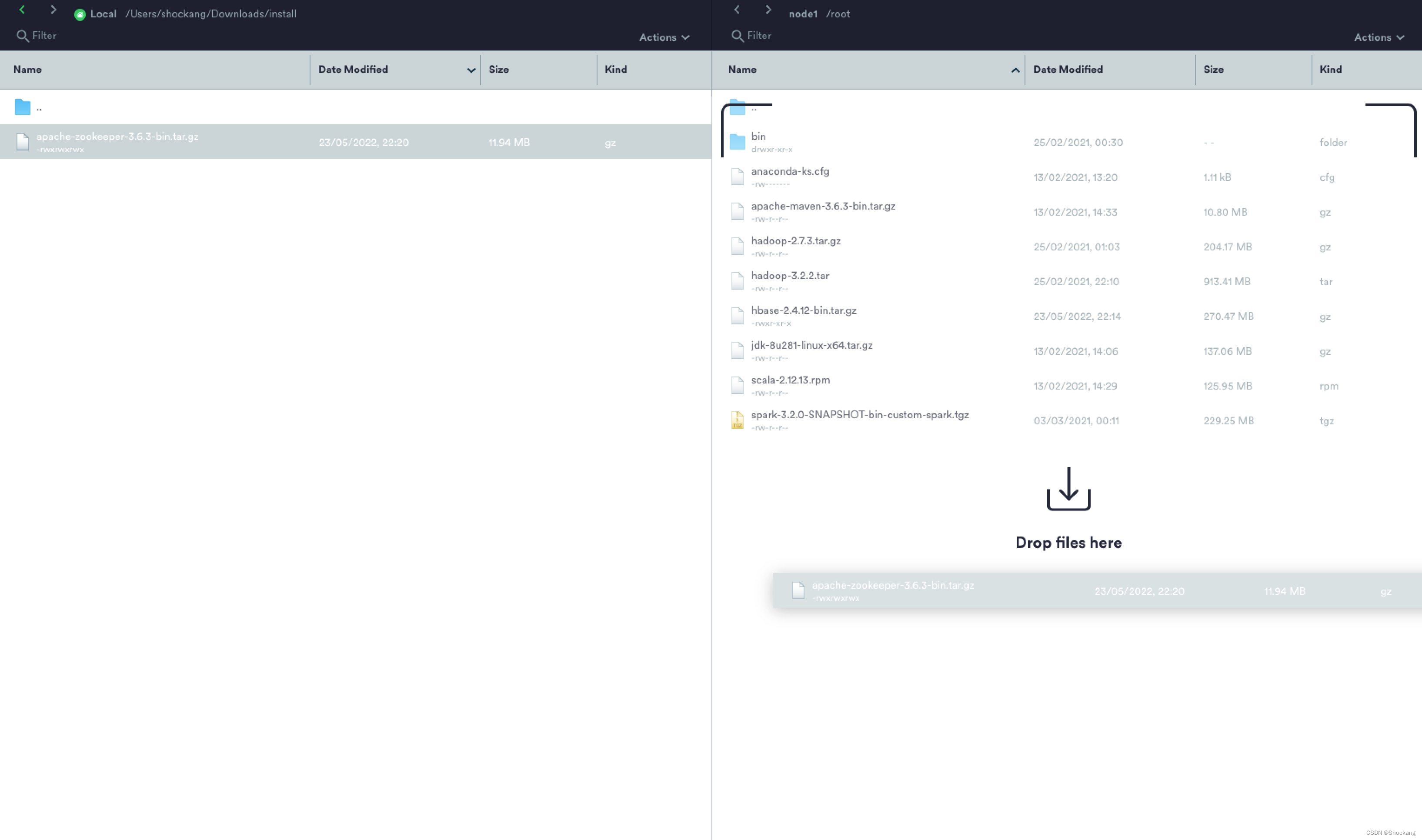
由于我使用的 MAC 电脑,这里使用的 Termius 软件完成安装包的上传。
3. 解压
root 用户下解压到 /opt/bigdata 目录
[root@node1 ~]# tar -xzvf apache-zookeeper-3.6.3-bin.tar.gz -C /opt/bigdata/
切换目录
[root@node1 ~]# cd /opt/bigdata/
修改用户组
[root@node1 bigdata]# chown -R hadoop:hadoop apache-zookeeper-3.6.3-bin/
修改权限
[root@node1 bigdata]# chmod -R 755 apache-zookeeper-3.6.3-bin/
4. 配置 ZK 环境变量
可以参考我下面的配置来修改 /etc/profile 或者~/.bash_profile文件
JAVA_HOME=/opt/java
MAVEN_HOME=/opt/maven
HADOOP_HOME=/opt/bigdata/hadoop-3.2.2
SPARK_HOME=/opt/bigdata/spark-3.2.0
ZK_HOME=/opt/bigdata/apache-zookeeper-3.6.3-bin
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZK_HOME/bin
export JAVA_HOME MAVEN_HOME HADOOP_HOME SPARK_HOME ZK_HOME PATH

node1 配置好的环境变量需要同步到 node2 和 node3 上面,因为等下还要将安装目录复制过去,此处顺便一起搞定。
[root@node1 ~]# scp /etc/profile node2:/etc
profile 100% 2476 942.8KB/s 00:00
[root@node1 ~]# scp /etc/profile node3:/etc
profile 100% 2476 1.0MB/s 00:00
[root@node1 ~]#
记得配置完成后都要使用
source命令使得环境变量生效。[root@node1 ~]# source /etc/profile
5. 修改 ZK 集群配置文件
将目录切换到 zookeeper 的安装目录下的 conf 目录下复制 zoo_sample.cfg 文件为 zoo.cfg
[hadoop@node1 ~]$ cd /opt/bigdata/apache-zookeeper-3.6.3-bin/conf
[hadoop@node1 conf]$ ll
总用量 12
-rwxr-xr-x. 1 hadoop hadoop 535 4月 9 2021 configuration.xsl
-rwxr-xr-x. 1 hadoop hadoop 3435 4月 9 2021 log4j.properties
-rwxr-xr-x. 1 hadoop hadoop 1148 4月 9 2021 zoo_sample.cfg
[hadoop@node1 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@node1 conf]$ vim zoo.cfg
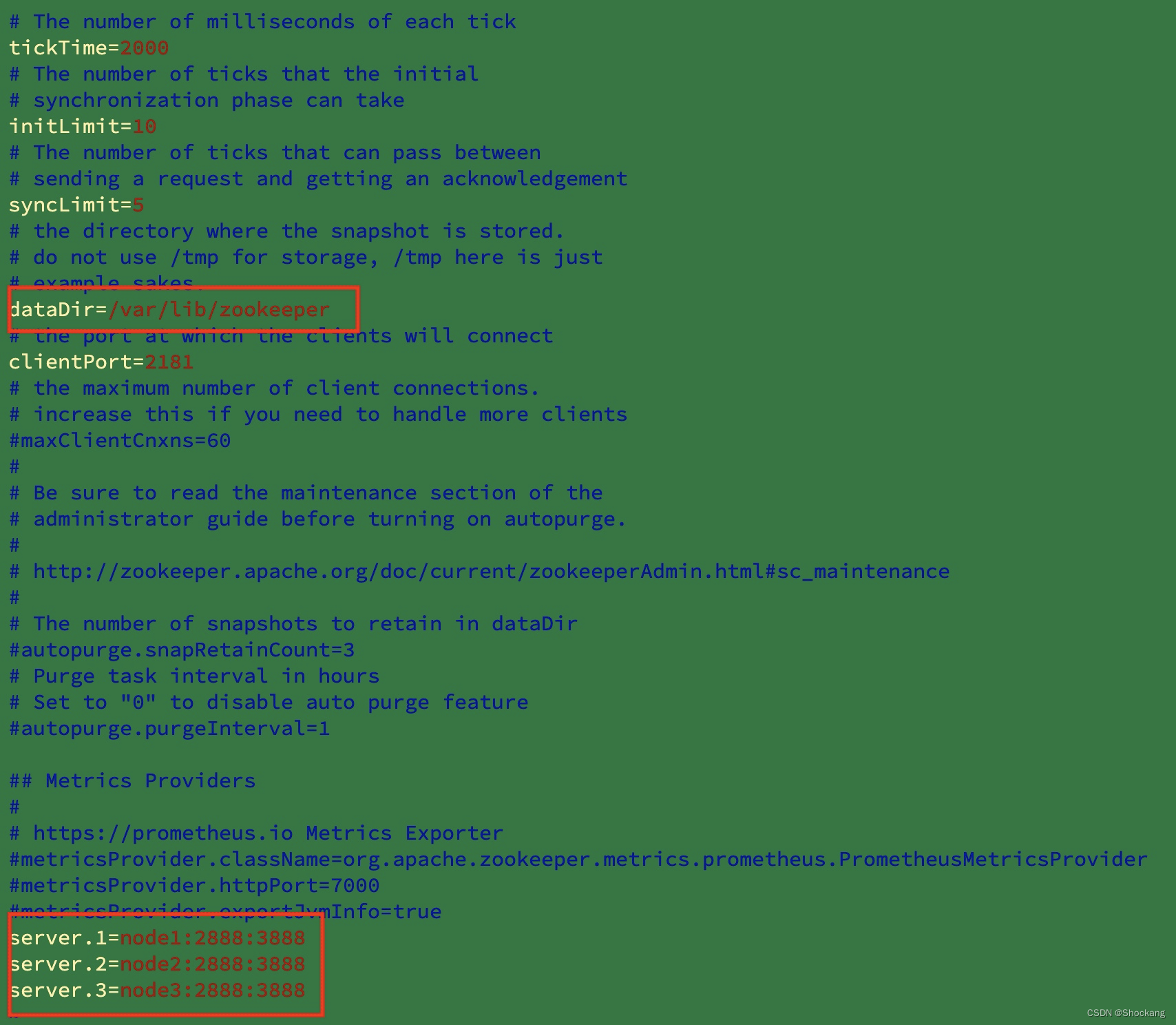
修改dataDir的值为dataDir=var/lib./zookeeper,在文件的末尾添加如下配置: server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888
6. 创建 myid 文件
在节点 node1,node2,node3 对应的 /var/lib/zookeeper目录下(上面 dataDir 配置的目录/var/lib/zookeeper)创建 myid 文件,几个文件内容依次为1,2,3
如下我们切换到root用户,在/var/lib目录下创建zookeeper目录,因为 hadoop 用户对 /var/lib 目录没有写权限, 所以我们在创建 zookeeper 目录时需要切换到root 用户(拥有最大权限)
[hadoop@node1 conf]$ logout
[root@node1 bigdata]# cd /var/lib
[root@node1 lib]# mkdir /var/lib/zookeeper
[root@node1 lib]# cd zookeeper/
[root@node1 zookeeper]# vim myid
注意 3 个节点都得操作。
7. 修改 zookeeper 目录权限
如下修改 node1,node2,node3 上面 zookeeper 目录的用户组和权限。
[root@node1 zookeeper]# chown -R hadoop:hadoop /var/lib/zookeeper
[root@node1 zookeeper]# chmod -R 755 /var/lib/zookeeper
8. 复制 zookeeper
在 hadoop 用户下将 zookeeper 安装目录复制到 node2 和 node3 节点。
[root@node1 zookeeper]# su - hadoop
上一次登录:二 5月 24 08:41:10 CST 2022pts/0 上
[hadoop@node1 ~]$ scp -r /opt/bigdata/apache-zookeeper-3.6.3-bin/ hadoop@node2:/opt/bigdata
[hadoop@node1 ~]$ scp -r /opt/bigdata/apache-zookeeper-3.6.3-bin/ hadoop@node3:/opt/bigdata
9. 启动 zookeeper 集群
启动 zookeeper 集群需要手动分别依次在三台机器上启动,启动前需要在三台机器上都将用户切换为 hadoop 用户。
node1 上启动 zookeeper
[hadoop@node1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node1 ~]$
node2 上启动 zookeeper
[root@node2 lib]# su - hadoop
上一次登录:一 3月 14 23:37:00 CST 2022pts/0 上
[hadoop@node2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node2 ~]$
node3 上启动 zookeeper
[root@node3 zookeeper]# su - hadoop
上一次登录:六 7月 31 22:56:36 CST 2021pts/1 上
[hadoop@node3 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node3 ~]$
10. 查看 zookeeper 集群状态
使用 zkServer.sh status 命令在三个节点分别执行查看状态
在 node1 上查看
[root@node1 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
在 node2 上查看
[root@node2 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
在 node3 上查看
[root@node3 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/bigdata/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader

