我们将通过一个示例使用情绪分析 NLP 模型来评估评论(文本)字段是否包含正面或负面情绪。使用公开可用的模型,我们将向你展示如何将该模型部署到 Elasticsearch,并在摄取管道中使用该模型将客户评论分类为正面或负面。
情感分析是一种二元分类,其中字段被预测为一个值或另一个值。该预测的概率分数通常介于 0 和 1 之间,分数接近 1 表示预测更自信。这种类型的 NLP 分析可以有效地应用于许多数据集,例如产品评论或客户反馈。
我们希望分类的客户评论位于 2015 年 Yelp 数据集挑战的公共数据集中。从 Yelp Review 网站整理的数据集是测试情绪分析的完美资源。在此示例中,我们将使用常见的情绪分析 NLP 模型评估 Yelp 评论数据集的样本,并使用该模型将评论标记为正面或负面。我们希望发现正面评论和负面评论的百分比。
更多关于 NLP 的阅读:
安装
如果你还没有安装好自己的 Elasticsearch,Kibana 及 Eland,那么请阅读之前的文章 “Elasticsearch:如何部署 NLP:文本嵌入和向量搜索”。
将情绪分析模型部署到 Elasticsearch
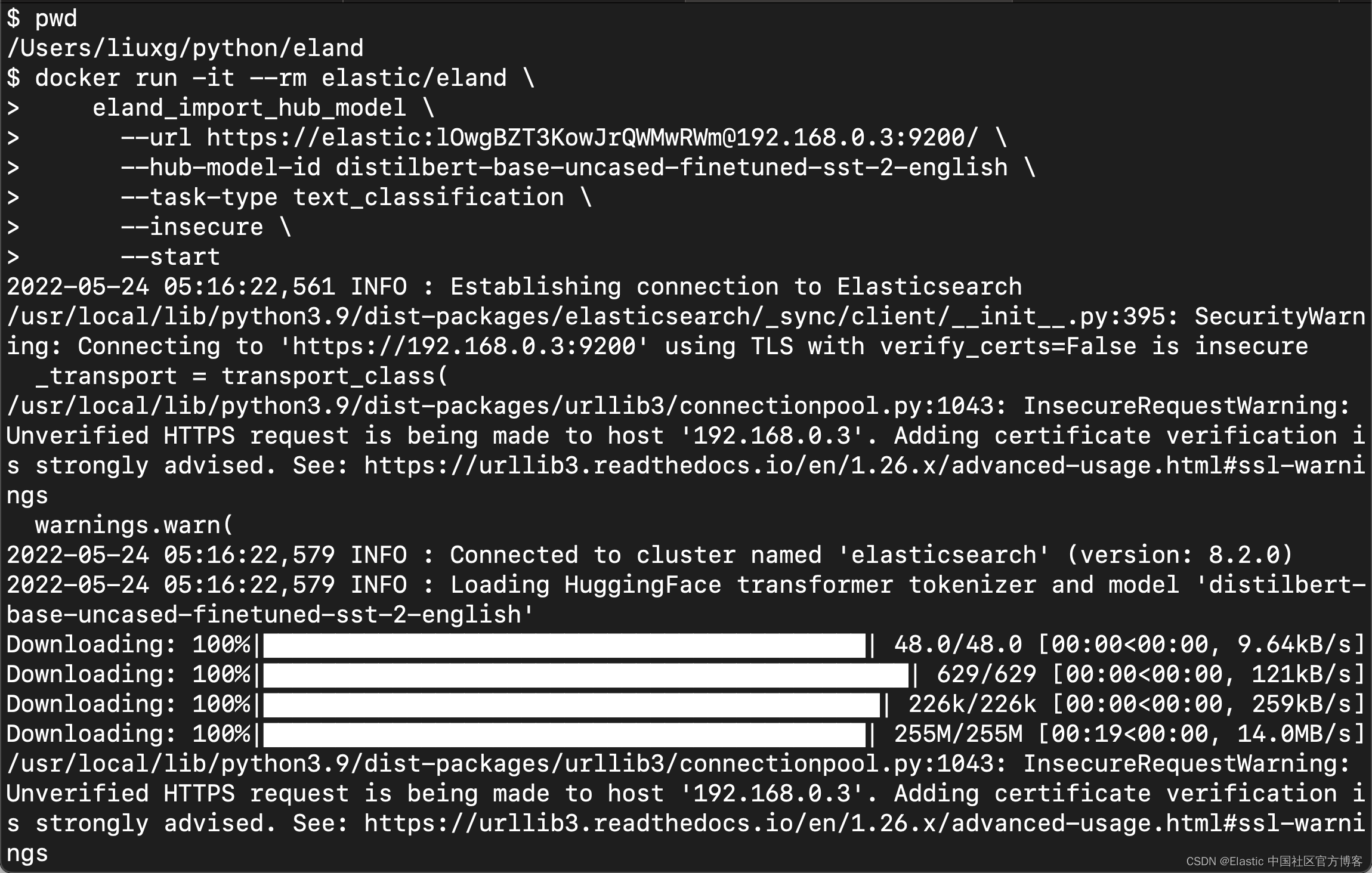
接下来是使用在上面安装步骤中构建的 Eland docker 代理从 Hugging Face 安装模型:
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url https://elastic:lOwgBZT3KowJrQWMwRWm@192.168.0.3:9200/ \
--hub-model-id distilbert-base-uncased-finetuned-sst-2-english \
--task-type text_classification \
--insecure \
--start注意:请根据自己的用户账号信息更新 --url 选项中的 Elasticsearch 信息。由于我们使用的是自签名的证书部署的,在这里,我们使用 --insecure 来规避 SSL 签名证书的检查。在这里,?--task-type 设置为 text_classification 并且 --start 选项被传递给 Eland 脚本,因此模型将自动部署,而无需在模型管理 UI 中启动它。
 ?
?
? ?
?
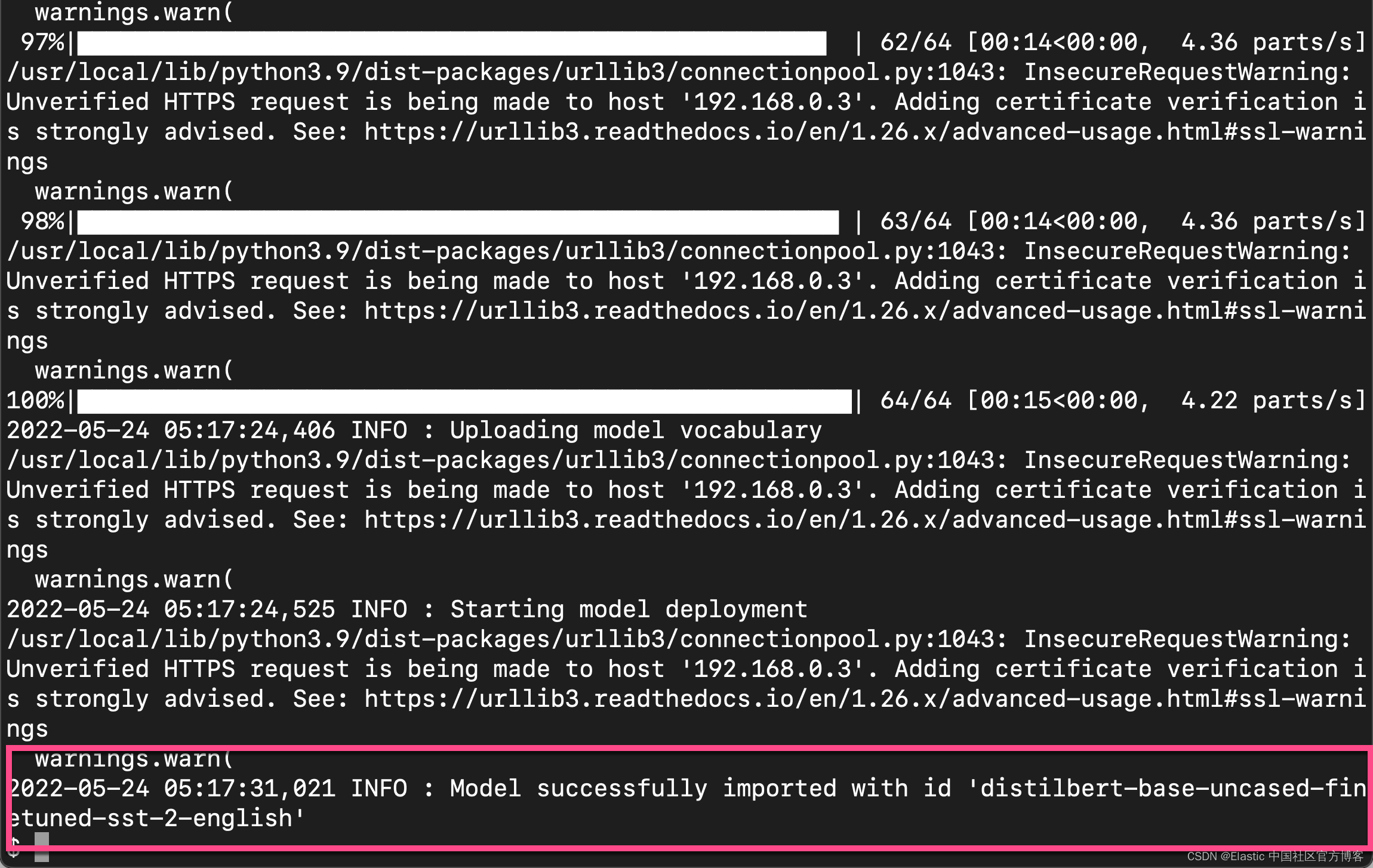
上面显示我们的模型已经成功地被上传到 Elasticsearch 中去了。
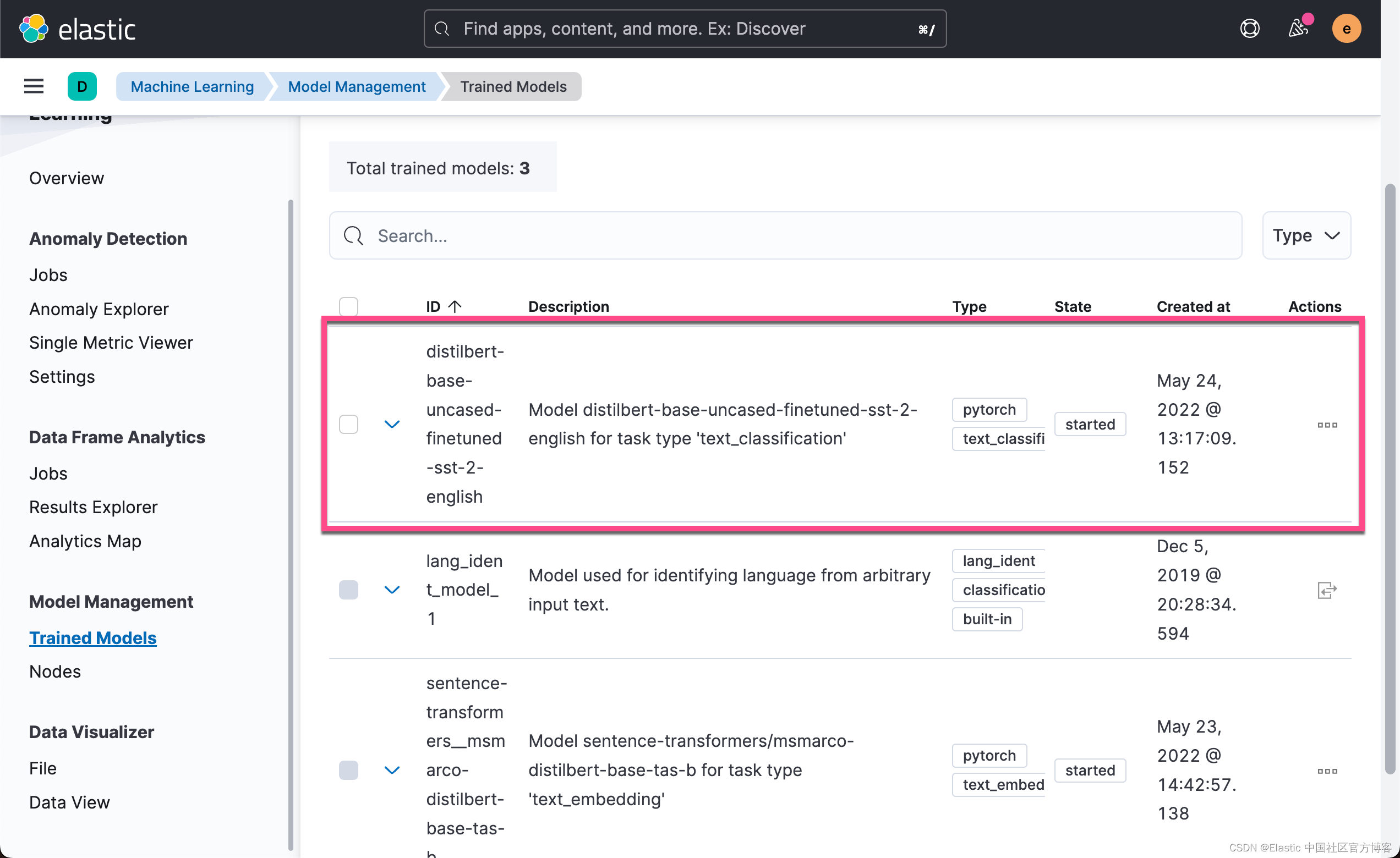
我们回到 Kibana 的机器学习界面:
 ??
??
 ??
??
 ??
??
 ??
??
 ??
??
我们可以看到最新上传的模型。上面显示,模型已经被启动了。
部署后,在 Kibana 控制台中尝试以下示例:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The movie was awesome!"
}
]
}上面返回的结果是:
{
"predicted_value" : "POSITIVE",
"prediction_probability" : 0.9998643926058477
}也就是说 “This movie was awesome” 是一个比较正面的评价。
你也可以试试这个例子:
POST _ml/trained_models/distilbert-base-uncased-finetuned-sst-2-english/deployment/_infer
{
"docs": [
{
"text_field": "The cat was sick on the bed"
}
]
}对猫和清洁床单的人产生强烈的负面反应:
{
"predicted_value" : "NEGATIVE",
"prediction_probability" : 0.9992468470666165
}分析 Yelp 评论
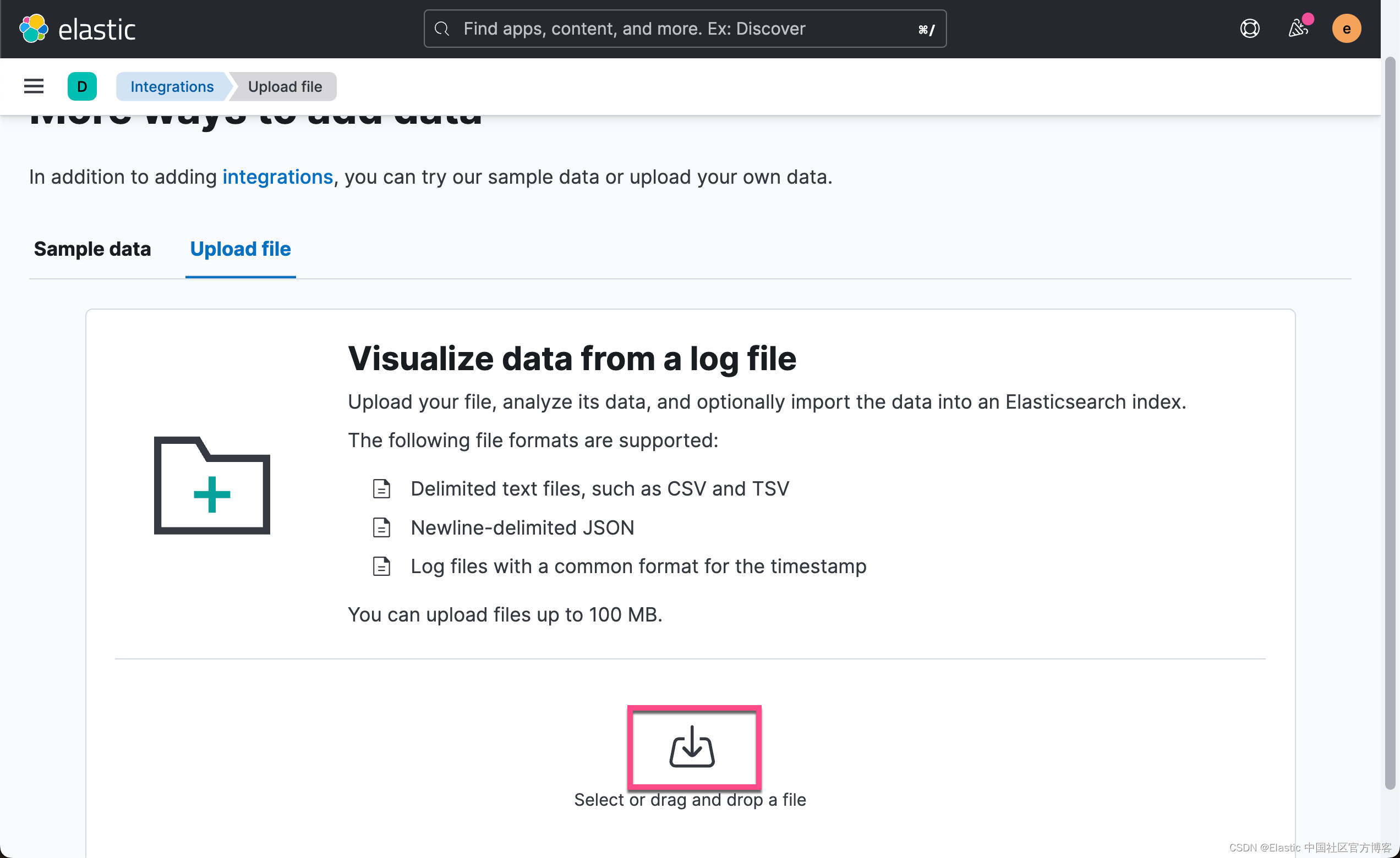
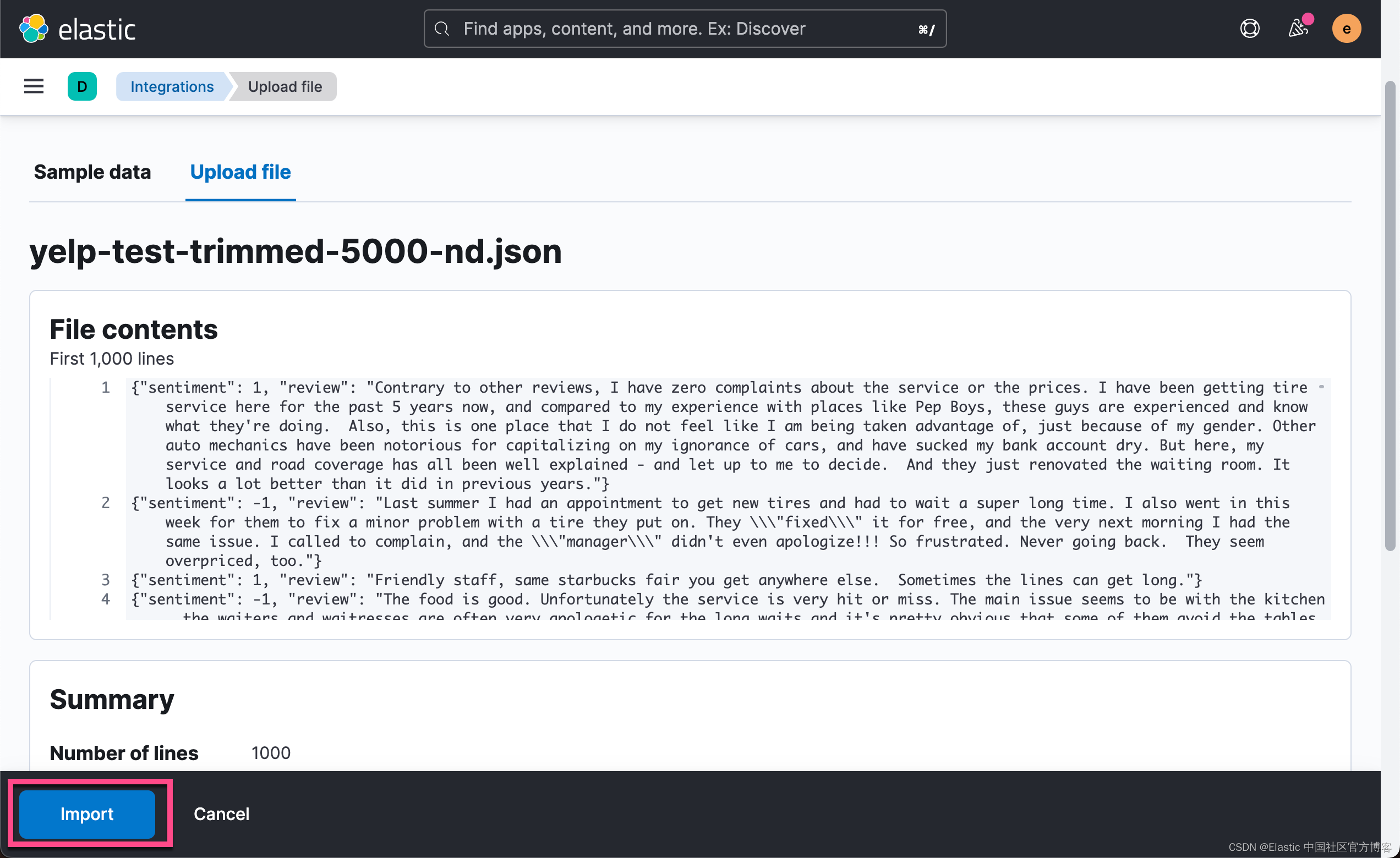
在美国,Yelp 有点像我们的美团。你可以在上面订餐,看医生,沙龙等等。是一个非常流行的 app。分析用户对于客户的评价是非常有用的。如文章开始的部分所述,我们将使用 Hugging Face 上可用的 Yelp 评论的子集,这些评论已手动标记了情绪。 这将使我们能够将结果与标记指数进行比较。 我们将使用 Kibana 的文件上传功能上传此数据集的样本,以供推理处理器进行处理。
 ?
?
 ??
??
 ??
??
 ?
?
 ?
?
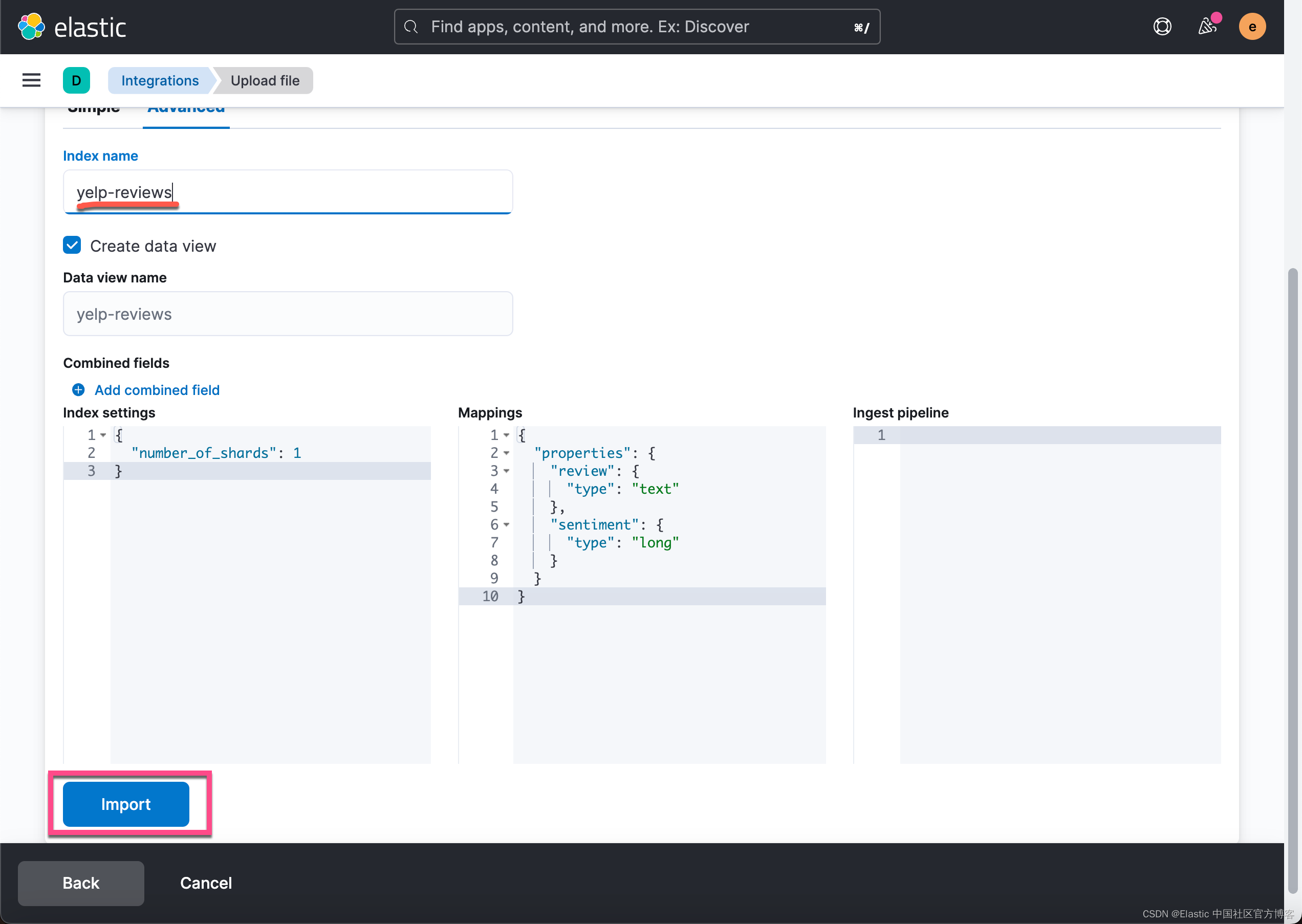
在 Kibana 控制台中,我们可以创建一个摄取管道,这次用于情绪分析,并将其称为 sentiment。 评论位于名为 review 的字段中。 正如我们之前所做的,我们将定义一个 field_map 以将评论映射到模型期望的字段。 设置了相应的?on_failure 处理程序:
PUT _ingest/pipeline/sentiment
{
"processors": [
{
"inference": {
"model_id": "distilbert-base-uncased-finetuned-sst-2-english",
"field_map": {
"review": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
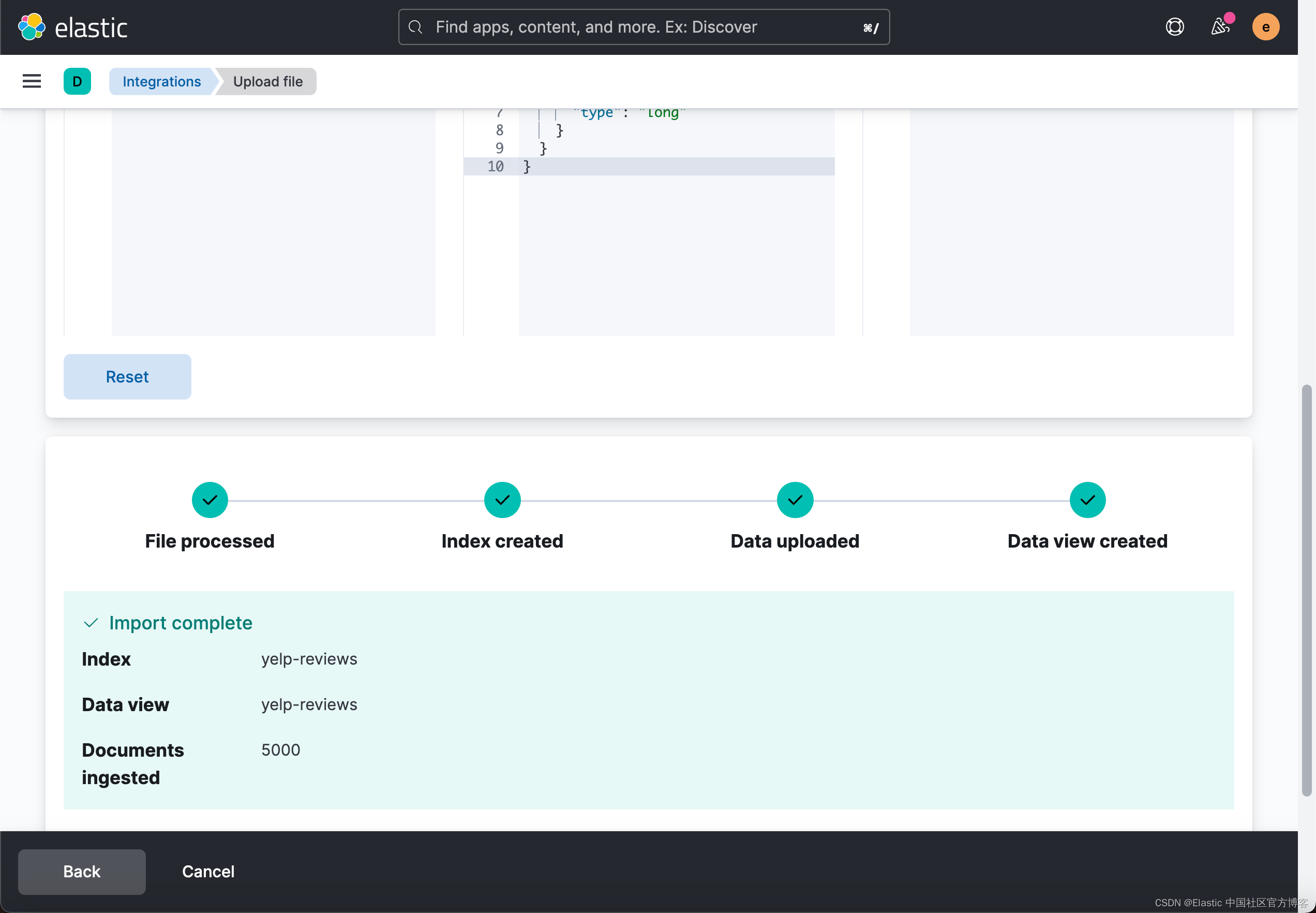
}评论文档存储在 Elasticsearch 索引 yelp-reviews 中。 使用重新索引 API 通过情绪分析管道推送评论数据。 鉴于重新索引需要一些时间来处理所有文档并对其进行推断,请通过调用带有 wait_for_completion=false 标志的 API 在后台重新索引。 使用在 Elasticsearch 中使用 PyTorch 进行现代自然语言处理的介绍 检查进度。
POST _reindex?wait_for_completion=false
{
"source": {
"index": "yelp-reviews"
},
"dest": {
"index": "yelp-reviews-with-sentiment",
"pipeline": "sentiment"
}
}上面的命令返回一个 task id。我们可以使用如下的命令来查看进度:
GET _tasks/ViiAKJJMSEmig9qtGfb34g:2984987或者,通过观察模型统计 UI 中的推理计数增加来跟踪进度。
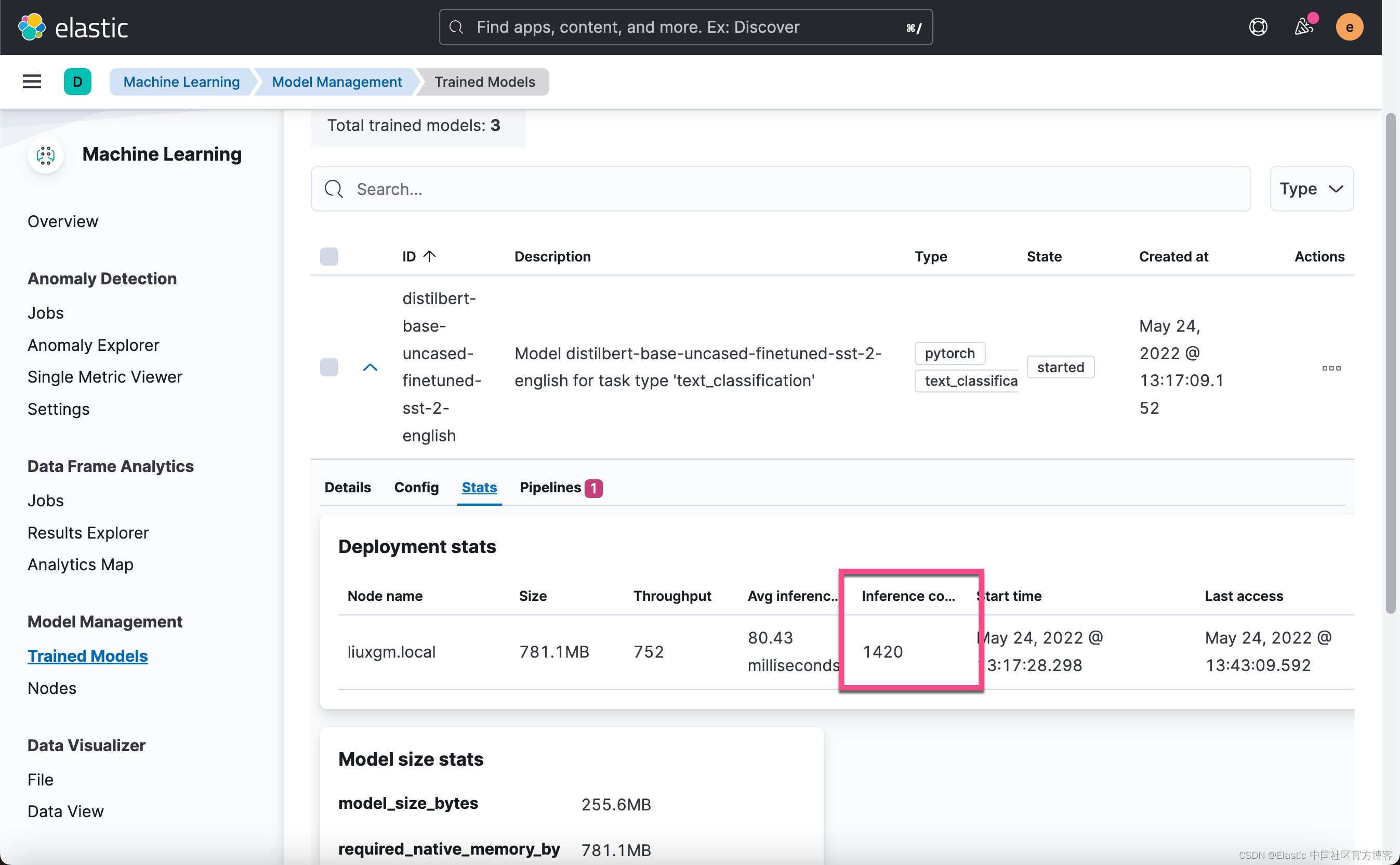 ?
?
我们共有 5000 个数据。在上面的界面中,如果我们看到 5000,则表明我们的任务已经完成。
重新索引的文档现在包含推理结果。 例如,分析的文档之一如下所示:
{
"review": "The food is good. Unfortunately the service is very hit or miss. The main issue seems to be with the kitchen, the waiters and waitresses are often very apologetic for the long waits and it's pretty obvious that some of them avoid the tables after taking the initial order to avoid hearing complaints.",
"ml": {
"inference": {
"predicted_value": "NEGATIVE",
"prediction_probability": 0.9985209630712552,
"model_id": "distilbert-base-uncased-finetuned-sst-2-english"
}
},
"timestamp": "2022-02-02T15:10:38.195345345Z"
}?如上所示,预测的值是 NEGATIVE。从上面的评论中,我们可以看出来,这个显然是有道理的。
可视化有多少评论是负面的
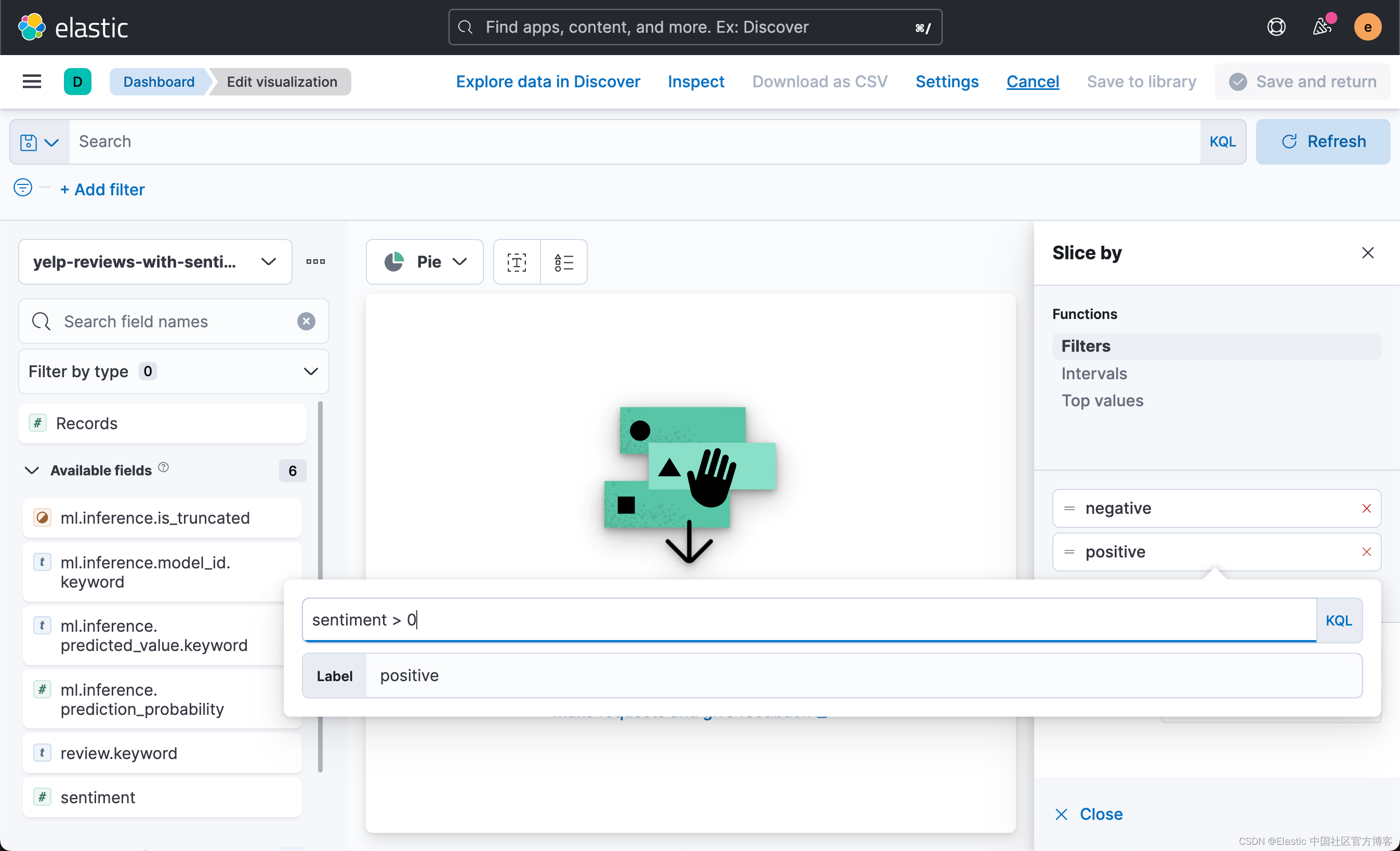
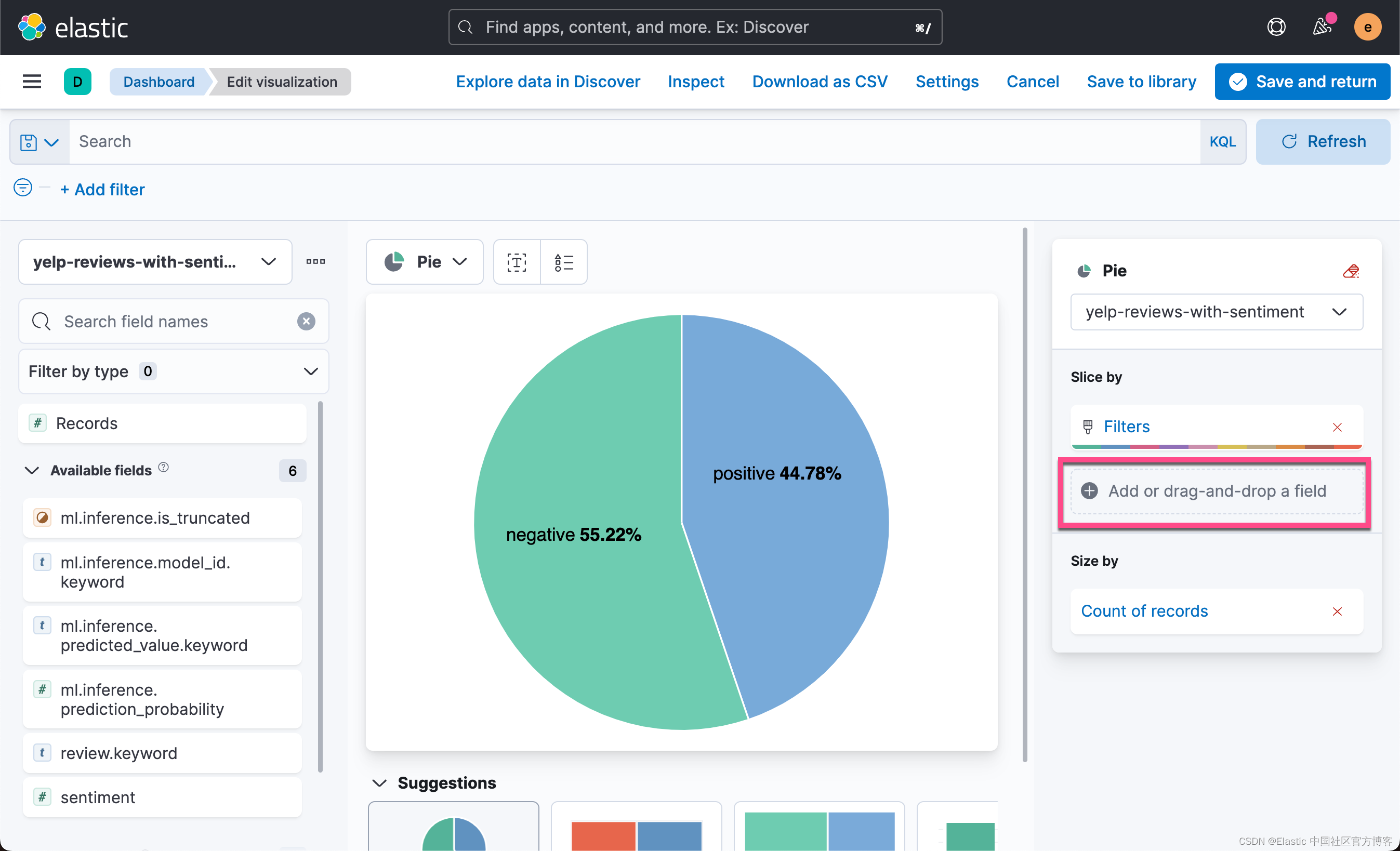
有多少百分比的评论是负面的? 我们的模型与手动标记的情绪相比如何? 让我们通过构建一个简单的可视化来从模型中手动跟踪正面和负面评论来找出答案。 通过基于 ml.inference.predicted_value 字段创建可视化,我们可以报告比较结果,并看到大约 44% 的评论被认为是正面的,而这 4.59% 的评论被情绪分析模型错误地标记。
我们首先为?yelp-reviews-with-sentiment 创建一个 data view:
 ?
?
 ??
??
 ??
??
 ??
??
我们接下来做可视化:
 ??
??
 ??
??
 ??
??
 ??
??
 ??
??
 ??
??
 ??
??
 ??
??
从上面我们可以看出来 positive 的评论为 44.78,这个是根据手动打分的结果。我们下面来根据情绪分析得出来的字段?ml.inference.predicted_value 来进行统计:
?
?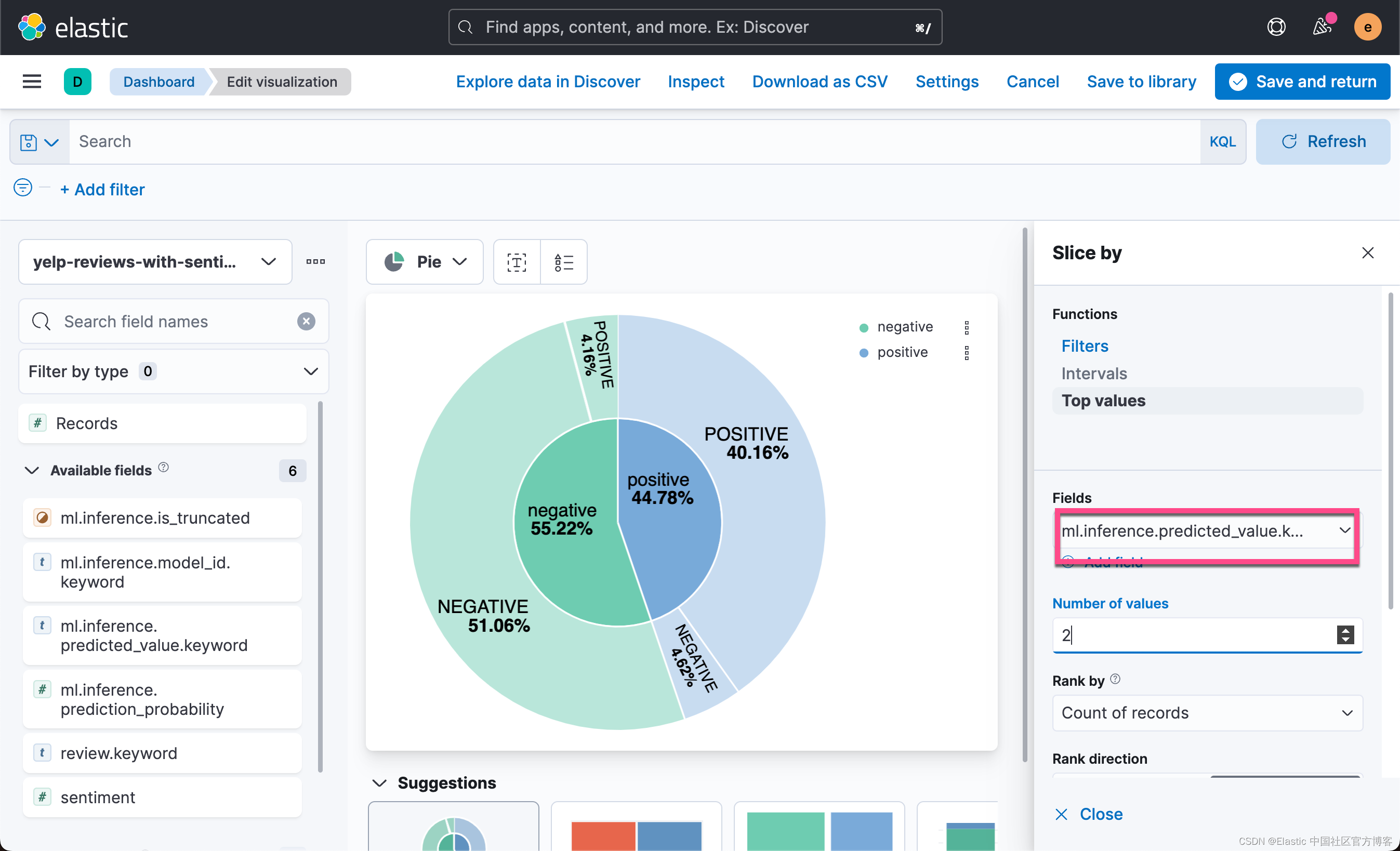
从上面的可视化图中,我们可以看出来,在 negative 中的 55.22% 中有一个 4.16% 的错误判定为 POSITRIVE,而在占 positive 44.78% 比例中的 4.62% 被错误地判定为 NEGATIVE。这个可以是在容忍的范围里。
试一试
NLP 是 Elastic Stack for 8.0 中的一项重要新功能,具有令人兴奋的路线图。 通过在 Elastic Cloud 中构建集群,发现新功能并跟上最新发展。 立即注册免费试用 14 天,并尝试此博客中的示例。

