1. АВзА3ЬЈcentos7ЗўЮёЦї
1.1.ХфжУУћзжhadoop01\hadoop02\hadoop03
hostnamectl set-hostname hadoop01hostnamectl set-hostname hadoop02hostnamectl set-hostname hadoop031.2.аоИФhostsЮФМў
vi /etc/hostsЮФМўФЉЮВЬэМгвдЯТФкШн:
hadoop01ЕФipЕижЗ hadoop01
hadoop02ЕФipЕижЗ hadoop02
hadoop03ЕФipЕижЗ hadoop031.3.ЙиБеЗРЛ№ЧН
systemctl stop firewalldsystemctl disable firewalld2.xshellЕуЛїЙЄОп,бЁдёЗЂЫЭМќЪфШыЕНЫљгаЛсЛА
2.1.ЫљгаДАПкзДЬЌИФГЩNO
3.hadoop01ЪфШывдЯТУќСю
3.1.зіssh ЙЋЫНдП ЮоУи;жаЭОжБНгЛиГЕ
ssh-keygen -t rsa -P ''3.2.copyЙЋдПЕНhadoop02,hadoop03;ЪфШыyes,дйЪфШыУмТы
ssh-copy-id hadoop01ssh-copy-id hadoop02ssh-copy-id hadoop034.ВтЪдвдЩЯВйзїЪЧЗёГЩЙІ
4.1.hadoop02,hadoop03ЗжБ№ЪфШывдЯТУќСю

cd .ssh/ls4.2.hadoop02ЪфШывдЯТУќСю
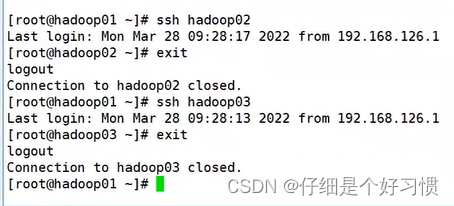
ssh hadoop02ssh hadoop03exit5.Ек2ВНЕФЛљДЁ,hadoop02КЭhadoop03ДАПкзДЬЌИФГЩOFF

5.1.ЪфШывдЯТУќСю,КЭЕк3ВНвЛбљ
ssh-keygen -t rsa -P ''ssh-copy-id hadoop01ssh-copy-id hadoop02ssh-copy-id hadoop035.2.вдЩЯВйзїЖМЭъГЩКѓhadoop01,hadoop02КЭhadoop03ЕФДАПкзДЬЌЖМИФГЩOFF,ШЮвтвЛИіДАПкАДЯТctrl+l

6.АВзАchrony
yum -y install chrony7.АВзАwget
yum install -y gcc vim wget8.ХфжУchrony
vim /etc/chrony.conf8.1.ЮФМўЬэМгШчЯТФкШн,зЂЪЭЕєserver 0.centos.pool.ntp.org iburst
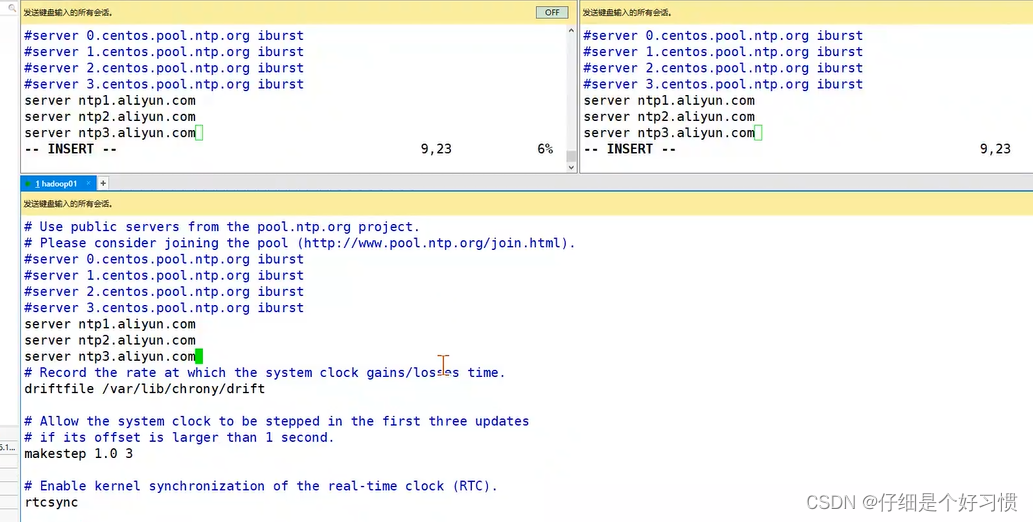
server ntp1.aliyun.com
server ntp2.aliyun.com
server ntp3.aliyun.com9.ЦєЖЏchrony
systemctl start chronyd10.АВзАpsmisc
yum install -y psmisc11.БИЗндЪМдД
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup12.ЯТдидД
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo13.ЧхГ§ЛКДц
yum clean allyum makecache14.ДђПЊxftp,НЋjdkАВзААќЗжБ№ЭЯЕНШ§ЬЈЛњЦїЕФoptЮФМўМаЯТ,ШЛКѓжДаавдЯТУќСю,АВзАjdk
cd /opttar -zxf jdk-8u111-linux-x64.tar.gzmkdir softmv jdk1.8.0_111/ soft/jdk18014.1.ХфжУЛЗОГБфСП
vim /etc/profile#java env
export JAVA_HOME=/opt/soft/jdk180
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarsource /etc/profilejava -version15.ДђПЊxftp,НЋzookeeperАВзААќЗжБ№ЭЯЕНШ§ЬЈЛњЦїЕФoptЮФМўМаЯТ,ШЛКѓжДаавдЯТУќСю,АВзАzookeeper
tar -zxf zookeeper-3.4.5-cdh5.14.2.tar.gzmv zookeeper-3.4.5-cdh5.14.2 soft/zk34515.1.аоИФzoo.cfgЮФМў
cd soft/zk345/conf/cp zoo_sample.cfg zoo.cfgvim zoo.cfgаоИФdataDir=/opt/soft/zk345/datas:
dataDir=/opt/soft/zk345/datasЮФМўФЉЮВМгЩЯвдЯТФкШн:

server.1=192.168.239.137:2888:3888
server.2=192.168.239.141:2888:3888
server.3=192.168.239.142:2888:388816.ДДНЈdatasЮФМўМа
cd /opt/soft/zk345/mkdir datas17.hadoop01,hadoop02КЭhadoop03ЕФДАПкзДЬЌЖМИФГЩON
17.1.hadoop01вГУцЪфШывдЯТУќСю
cd datasecho "1"> myidcat myid17.2.hadoop02вГУцЪфШывдЯТУќСю
cd datasecho "2"> myidcat myid17.3.hadoop03вГУцЪфШывдЯТУќСю
cd datasecho "3"> myidcat myid18.hadoop01,hadoop02КЭhadoop03ЕФДАПкзДЬЌЖМИФГЩOFF
18.1.ХфжУzookeeperдЫааЛЗОГ
vim /etc/profile#Zookeeper env
export ZOOKEEPER_HOME=/opt/soft/zk345
export PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile19.ЦєЖЏzookeeperМЏШК
zkServer.sh start20.jpsУќСюВщПД,БиаывЊгаНјГЬQuorumPeerMain
jps21.ДђПЊxftp,НЋHadoopАВзААќЗжБ№ЭЯЕНШ§ЬЈЛњЦїЕФoptЮФМўМаЯТ,ШЛКѓжДаавдЯТУќСю,АВзАHadoopМЏШК
cd /opttar -zxf hadoop-2.6.0-cdh5.14.2.tar.gzmv hadoop-2.6.0-cdh5.14.2 soft/hadoop260cd soft/hadoop260/etc/hadoop21.1.ЬэМгЖдгІИїИіЮФМўМа
mkdir -p /opt/soft/hadoop260/tmp mkdir -p /opt/soft/hadoop260/dfs/journalnode_data mkdir -p /opt/soft/hadoop260/dfs/edits mkdir -p /opt/soft/hadoop260/dfs/datanode_datamkdir -p /opt/soft/hadoop260/dfs/namenode_data21.2.ХфжУhadoop-env.sh
vim hadoop-env.shаоИФJAVA_HOMEКЭHADOOP_CONF_DIRЕФжЕШчЯТ:
export JAVA_HOME=/opt/soft/jdk180
export HADOOP_CONF_DIR=/opt/soft/hadoop260/etc/hadoop21.3.ХфжУcore-site.xml,ПьНнМќshift+GЕНЮФМўФЉЮВЬэМгШчЯТФкШн(зЂвтИФЛњЦїУћ!!!)
vim core-site.xml<configuration>
<!--жИЖЈhadoopМЏШКдкzookeeperЩЯзЂВсЕФНкЕуУћ-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hacluster</value>
</property>
<!--жИЖЈhadoopдЫааЪБВњЩњЕФСйЪБЮФМў-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/soft/hadoop260/tmp</value>
</property>
<!--ЩшжУЛКДцДѓаЁ ФЌШЯ4KB--> <property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--жИЖЈzookeeperЕФДцЗХЕижЗ-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--ХфжУдЪаэrootДњРэЗУЮЪжїЛњНкЕу-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--ХфжУИУНкЕудЪаэrootгУЛЇЫљЪєЕФзщ-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>21.4.ХфжУhdfs-site.xml,ЮФМўФЉЮВЬэМгШчЯТФкШн(зЂвтИФЛњЦїУћ!!!)
vim hdfs-site.xml<configuration>
<property>
<!--Ъ§ОнПщФЌШЯДѓаЁ128M-->
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<property>
<!--ИББОЪ§СП ВЛХфжУФЌШЯЮЊ3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!--namenodeНкЕуЪ§Он(дЊЪ§Он)ЕФДцЗХЮЛжУ-->
<name>dfs.name.dir</name>
<value>file:///opt/soft/hadoop260/dfs/namenode_data</value>
</property>
<property>
<!--datanodeНкЕуЪ§Он(дЊЪ§Он)ЕФДцЗХЮЛжУ-->
<name>dfs.data.dir</name>
<value>file:///opt/soft/hadoop260/dfs/datanode_data</value>
</property>
<property>
<!--ПЊЦєhdfsЕФwebuiНчУц-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<!--datanodeЩЯИКд№НјааЮФМўВйзїЕФЯпГЬЪ§-->
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value> </property>
<property>
<!--жИЖЈhadoopМЏШКдкzookeeperЩЯЕФзЂВсУћ-->
<name>dfs.nameservices</name>
<value>hacluster</value>
</property>
<property>
<!--haclusterМЏШКЯТгаСНИіnamenodeЗжБ№ЪЧnn1,nn2-->
<name>dfs.ha.namenodes.hacluster</name>
<value>nn1,nn2</value>
</property>
<!--nn1ЕФrpcЁЂservicepcКЭhttpЭЈбЖЕижЗ -->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn1</name>
<value>hadoop01:9000</value>
</property>
<property>
<name>dfs.namenode.servicepc-address.hacluster.nn1</name>
<value>hadoop01:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.hacluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<!--nn2ЕФrpcЁЂservicepcКЭhttpЭЈбЖЕижЗ -->
<property>
<name>dfs.namenode.rpc-address.hacluster.nn2</name>
<value>hadoop02:9000</value>
</property>
<property>
<name>dfs.namenode.servicepc-address.hacluster.nn2</name>
<value>hadoop02:53310</value>
</property>
<property>
<name>dfs.namenode.http-address.hacluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<!--жИЖЈNamenodeЕФдЊЪ§ОндкJournalNodeЩЯДцЗХЕФЮЛжУ-->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/hacluster</value>
</property>
<property>
<!--жИЖЈJournalNodeдкБОЕиДХХЬЕФДцДЂЮЛжУ-->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/soft/hadoop260/dfs/journalnode_data</value>
</property>
<property>
<!--жИЖЈnamenodeВйзїШежОДцДЂЮЛжУ-->
<name>dfs.namenode.edits.dir</name>
<value>/opt/soft/hadoop260/dfs/edits</value>
</property>
<property>
<!--ПЊЦєnamenodeЙЪеЯзЊвЦздЖЏЧаЛЛ-->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!--ХфжУЪЇАмздЖЏЧаЛЛЪЕЯжЗНЪН-->
<name>dfs.client.failover.proxy.provider.hacluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!--ХфжУИєРыЛњжЦ-->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<!--ХфжУИєРыЛњжЦашвЊSSHУтУмЕЧТМ-->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!--hdfsЮФМўВйзїШЈЯо falseЮЊВЛбщжЄ-->
<name>dfs.premissions</name>
<value>false</value>
</property>
</configuration>21.5.ХфжУmapred-site.xml,ЮФМўФЉЮВЬэМгШчЯТФкШн(зЂвтИФЛњЦїУћ!!!)
cp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml<configuration>
<property>
<!--жИЖЈmapreduceдкyarnЩЯдЫаа-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--ХфжУРњЪЗЗўЮёЦїЕижЗ-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<!--ХфжУРњЪЗЗўЮёЦїwebUIЕижЗ-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<!--ПЊЦєuberФЃЪН-->
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
</configuration>21.6.ХфжУyarn-site.xml,ЮФМўФЉЮВЬэМгШчЯТФкШн(зЂвтИФЛњЦїУћ!!!)
vim yarn-site.xml<configuration>
<property>
<!--ПЊЦєyarnИпПЩгУ-->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- жИЖЈYarnМЏШКдкzookeeperЩЯзЂВсЕФНкЕуУћ-->
<name>yarn.resourcemanager.cluster-id</name>
<value>hayarn</value>
</property>
<property>
<!--жИЖЈСНИіresourcemanagerЕФУћГЦ-->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!--жИЖЈrm1ЕФжїЛњ-->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop02</value>
</property>
<property>
<!--жИЖЈrm2ЕФжїЛњ-->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<property>
<!--ХфжУzookeeperЕФЕижЗ-->
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property> <property>
<!--ПЊЦєyarnЛжИДЛњжЦ-->
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<!--ХфжУжДааresourcemanagerЛжИДЛњжЦЪЕЯжРр-->
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<!--жИЖЈжїresourcemanagerЕФЕижЗ-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
<property>
<!--nodemanagerЛёШЁЪ§ОнЕФЗНЪН-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--ПЊЦєШежООлМЏЙІФм-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--ХфжУШежОБЃСє7Ьь-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>22.ХфжУslaves
vim slaves22.1.ПьНнМќddЩОГ§localhost,ЬэМгШчЯТФкШн
hadoop01
hadoop02
hadoop0323.ХфжУhadoopЛЗОГБфСП
vim /etc/profile#hadoop env
export HADOOP_HOME=/opt/soft/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEsource /etc/profile24.ЦєЖЏHadoopМЏШК
24.1.ЪфШывдЯТУќСю
hadoop-daemon.sh start journalnode24.2.ЪфШыjpsУќСю,ЛсЗЂЯжЖрСЫвЛИіНјГЬJournalNode
jps24.3.ИёЪНЛЏnamenode(жЛдкhadoop01жїЛњЩЯ)(hadoop02КЭhadoop03ЕФДАПкзДЬЌИФГЩON)
hdfs namenode -format24.4.НЋhadoop01ЩЯЕФNamenodeЕФдЊЪ§ОнИДжЦЕНhadoop02ЯрЭЌЮЛжУ
scp -r /opt/soft/hadoop260/dfs/namenode_data/current/ root@hadoop02:/opt/soft/hadoop260/dfs/namenode_data24.5.дкhadoop01ЩЯИёЪНЛЏЙЪеЯзЊвЦПижЦЦїzkfc
hdfs zkfc -formatZK24.6.дкhadoop01ЩЯЦєЖЏdfsЗўЮё,дйЪфШыjpsВщПДНјГЬ
start-dfs.shjps
24.7.дкhadoop03ЩЯЦєЖЏyarnЗўЮё,дйЪфШыjpsВщПДНјГЬ
start-yarn.shjps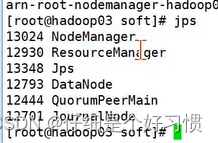
24.8.дкhadoop02ЩЯЪфШыjpsВщПДНјГЬ,ШчЯТЭМ
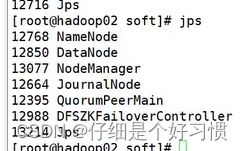
24.9.дкhadoop01ЩЯЦєЖЏhistoryЗўЮёЦї,jpsдђЛсЖрСЫвЛИіJobHistoryServerЕФНјГЬ
mr-jobhistory-daemon.sh start historyserverjps24.10.дкhadoop02ЩЯЦєЖЏresourcemanagerЗўЮё,jpsдђЛсЖрСЫвЛИіResourcemanagerЕФНјГЬ
yarn-daemon.sh start resourcemanagerjps25.МьВщМЏШКЧщПі
25.1.дкhadoop01ЩЯВщПДЗўЮёзДЬЌ,hdfs haadmin -getServiceState nn1дђЛсЖдгІЯдЪОactive,nn2дђЯдЪОstandby
hdfs haadmin -getServiceState nn1hdfs haadmin -getServiceState nn225.2.дкhadoop03ЩЯВщПДresourcemanagerзДЬЌ,yarn rmadmin -getServiceState rm1дђЛсЖдгІЯдЪОstandby,rm2дђЯдЪОactive
yarn rmadmin -getServiceState rm1yarn rmadmin -getServiceState rm226.фЏРРЦїЪфШыIPЕижЗ:50070,ЖдБШвдЯТЭМЦЌ
26.1.hadoop01ЕФIPЕижЗ,зЂвтВщПДЪЧЗёЮЊЁАactiveЁБ

26.2.hadoop02ЕФIPЕижЗ,зЂвтВщПДЪЧЗёЮЊЁАstandbyЁБ

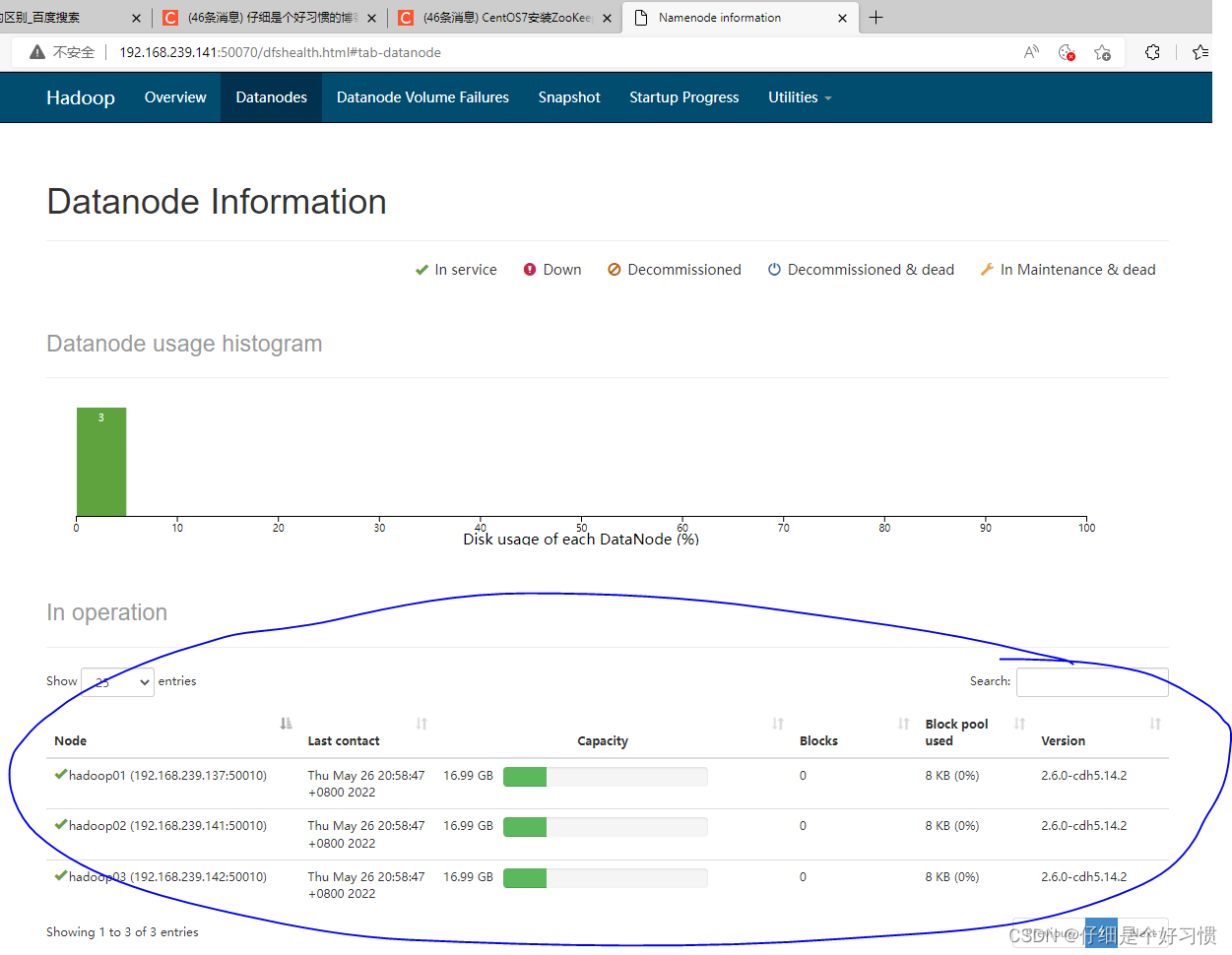
26.3.зюКѓбЁдёЩЯЗНЕФDatanodes,ВщПДЪЧЗёЪЧШ§ИіНкЕу,ШчКЮЪЧ,дђИпПЩгУhadoopМЏШКДюНЈГЩЙІ!!!