📣📣📣📣📣📣📣
🎍大家好,我是慕枫
🎍前阿里巴巴高级工程师,InfoQ签约作者、阿里云专家博主,一直致力于用大白话讲解技术知识
🎍在这里和大家分享一线互联网大厂面试经验、技术人成长路线以及Java技术、分布式、高并发、架构设计方面的经验总结
🎍感恩遇见,希望我们都能成为更好的自己
🎍创建了慕枫技术面试现场社区,主要分享大厂面试问题,欢迎大家加入慕枫技术面试现场
📣📣📣📣📣📣📣
?
目录
原则一:根据SQL语句中的where条件、order by条件以及group by条件对应的字段进行索引设计。
原则二:在基数比较大的字段上建立索引,同时需要将基数更高的字段放在最左边。
原则三:如果SQL中出现JOIN操作,那么JOIN的字段必须建立索引,同时字段的类型、字符集都需要保持一致。
原则四:如果SQL中出现JOIN操作,那么JOIN的字段必须建立索引,同时字段的类型、字符集都需要保持一致。
引言
相信大家都知道索引可以加快数据的查询速度,但是有时候如果索引设计不当,也可能造成索引失效而进行全表数据扫描,从而最终导致系统性能下降。因此我们在索引设计阶段就需要充分考虑各种可能情况,尽量避免由于索引设计缺陷导致的后期出现数据查询性能问题。本文总结了7个实用Mysql索引设计原则,相信在大家进行索引设计的时候可以进行参考。
索引设计原则
我们在数据库表设计好之后,先不要着急马上就进行表的索引设计,因为这个时候其实你也并不清楚未来在这个表上可能存在的查询条件到底是什么。所以我们需要先根据实际的产品需求来进行业务代码开发,在这个过程中我们必然会涉及到数据库持久化操作,也就是我们常说的CRUD。等我们把对应的Mapper接口以及SQL写好后,也就基本确定了哪些字段是条件字段、哪些字段是排序字段以及哪些字段是分组字段。这些字段确认好之后,我们就可以着手进行数据库表的索引设计了。关于如何设计索引,这里给大家梳理了7条非常实用的索引设计原则,相信大家在实际的项目中都可以用得上。
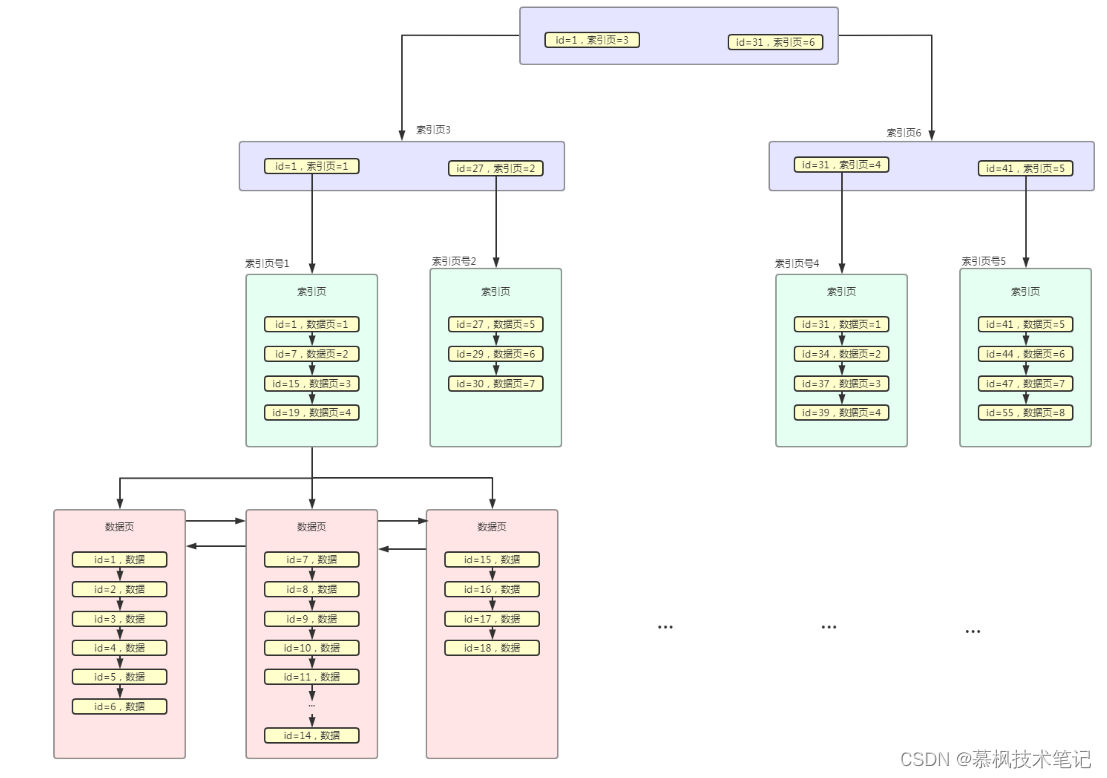
原则一:根据SQL语句中的where条件、order by条件以及group by条件对应的字段进行索引设计。
当我们的SQL语句中出现where条件、order by条件以及group by条件的时候,也就是表示我们需要通过SQL语句来进行数据过滤(where条件)、根据哪些字段进行排序(order by条件)以及根据哪些字段进行分组聚合(group by条件)。因此我们的设计的索引需要尽可能的覆盖这些字段,为的就是在数据查询的时候通过这些字段用上索引。假设我们有这样一张表clothes可以用来查询衣服,那么在设计索引的时候就需要根据实际的查询需求在对应的字段建立索引。那么对于衣服这张表来说一般会在c_brand(品牌)、c_type(类型)以及c_size(尺码)等这些字段建立索引,因为他们是最常用的筛选条件,另外可以考虑在价格字段上进行排序,这也是非常常见的过滤条件。
原则二:在基数比较大的字段上建立索引,同时需要将基数更高的字段放在最左边。
什么叫基数比较大的字段呢?实际就是值比较多的字段,或者说就是字段值的区分度比较高,我们可以用一个简单的公式来评判某个字段的区分度,区分度等于count(distinct 具体的列) / count(*),表示字段不重复的比例。也就是说字段中包含的变化数据比较多的话是比较适合建索引的,因为这样才能发挥索引B+树的潜力。为什么这么说呢?
假设有这样一张员工表中包含了性别字段i_gender,它的值只有0:男性,1:女性这两个值。我们都知道Mysql的索引结构是通过B+树实现的,而B+树背后的核心本质思想实际就是二分查找。而二分查找就需要待排序的数据基数大,也及时区分度高。而字段中只有0、1这样的就属于基数比较小,无法发挥索引树检索的效率,Mysql认为这种索引树还不如全表查询来的痛快。
另外还需要特别注意点是,对于区分度高的字段我们应该把它放在联合索引的左侧,因为这样可以更快的过滤掉更多的无效数据,从而提升索引的使用效率。还是拿员工信息来举例子,员工表中的毕业院校的字段的区分度就比民族字段区分度要高的多,索引我们在设计联合索引的时候就需要将毕业院校的字段仿造民族的左侧,这样可以更快的过滤掉无效数据。
原则三:如果SQL中出现JOIN操作,那么JOIN的字段必须建立索引,同时字段的类型、字符集都需要保持一致。
数据库JOIN是常见的数据记录遍历的SQL操作,假设平台有一张用户表以及订单表,这个时候如果想要获取用户的订单信息,那么就可以使用JOIN操作来完成操作。不过在使用JOIN的过程中如果参与JOIN的表过多的话,对应的结果可能是一个笛卡尔积,对于Mysql的优化器来说实在是很难选择出来哪个才是最好的执行计划,就好比找对象一样,如果只有一个可以选择也没什么好纠结的,如果有10个可以选择,那就很头大了,不知道选择哪个好,因此我们要避免出现过多数量表的JOIN。另外很重要的一点就是在进行JOIN的字段上一定要建立索引,否则全表扫描。同时JOIN字段的类型、字符集等都要保持一致,避免在JOIN过程中可能导致的隐式的类型转换造成不走索引的后果。
原则四:如果SQL中出现JOIN操作,那么JOIN的字段必须建立索引,同时字段的类型、字符集都需要保持一致。
数据库JOIN是常见的数据记录遍历的SQL操作,假设平台有一张用户表以及订单表,这个时候如果想要获取用户的订单信息,那么就可以使用JOIN操作来完成操作。不过在使用JOIN的过程中如果参与JOIN的表过多的话,对应的结果可能是一个笛卡尔积,对于Mysql的优化器来说实在是很难选择出来哪个才是最好的执行计划,就好比找对象一样,如果只有一个可以选择也没什么好纠结的,如果有10个可以选择,那就很头大了,不知道选择哪个好,因此我们要避免出现过多数量表的JOIN。另外很重要的一点就是在进行JOIN的字段上一定要建立索引,否则全表扫描。还有很重要的一点,用于JOIN的字段的类型、字符集等都需要保持一致,否则可能存在隐式的类型转换导致揍走不了索引。
原则五:尽量在字段类型值比较小的字段上建立索引。
索引本身也是占用磁盘空间的,因此如果可以在字段类型比较小的字段上面建立索引,相应的索引占用空间就会更少,对应其数据检索的效率就会更高。但是这并非绝对的,如果存在区分度更高的字段但是字段类型比较大,那么我们还是会在区分度高的字段上面建立索引,但是我们可以采取一些折中的办法,比如我们可以取字段的前10个字符作为索引,这样我们们既可以在区分度高的字段建立索引,但是又至于太占用磁盘空间。
原则六:索引不是建的越多越好。
有的同学在设计索引的时候恨不得把所有的字段都加上索引,总是觉得索引越多肯定性能越好,实际上真实场景下并非如此。我们都知道索引就像是一本书的目录,就像树的目录会占用书中的纸张一样,索引也是需要占用磁盘空间进行存储的,因此过多的索引会浪费资源。另外索引过多反而会降低性能,因为在进行数据插入的过程中,如果索引建立的过多就会导致更新多颗索引树,在这个过程中,如果数据的插入并不是按照顺序插入那么还会导致数据页分裂的问题。因此我们尽量通过两道三个联合索引来覆盖全部的查询场景。
原则七:使用字符串前缀创建索引
有些字段类型的长度比较长,因此字段的区分区相对来说也是比较大的,因此这些字段比较适合建索引。但是也是因为字段长度的原因,所建立的索引占用磁盘空间就会相对较大。实际上只要字段区分度足够高,没有必要对全字段建立索引,我们可以截取字段指定数量的字符作为检索条件的索引,具体需要截取多少字符那需要根据截取的字符串是否可以保持比较大区分度来进行决定。
SELECT COUNT(DISTINCT LEFT(order_code, 10)) / COUNT(*) FROM order总结
本文主要总结了在进行索引设计的时候需要考虑的几点设计原则,其实索引设计的根本无非就是两点,一个是希望通过两三个联合索引来覆盖数据检索的各个场景,避免因为检索的时候没有索引导致的数据检索效率低的问题,再者就是希望在实际的SQL运行过程中尽量避免索引失效情况的发生,避免建了索引但是实际上并不起作用。把握了这两个准则之后,相信大家在设计索引的时候可以游刃有余。
创作不易,如果各位同学觉得文章还不错的话,麻烦点赞+收藏+评论交流哦。老样子,文末和大家分享一首诗词。
卜算子・黄州定慧院寓居作
缺月挂疏桐,漏断人初静。谁见幽人独往来,缥缈孤鸿影。
惊起却回头,有恨无人省。拣尽寒枝不肯栖,寂寞沙洲冷。

