1. ����ģʽ(����ĸ���)
1.1 �Ựģʽ(Session Mode)
??�Ựģʽ,��Ҫ������һ����Ⱥ,����һ���Ự,������Ự��ͨ���ͻ����ύ��ҵ����Ⱥ����ʱ������Դ���Ѿ�ȷ��,���������ύ����ҵ�Ὰ����Ⱥ�е���Դ��
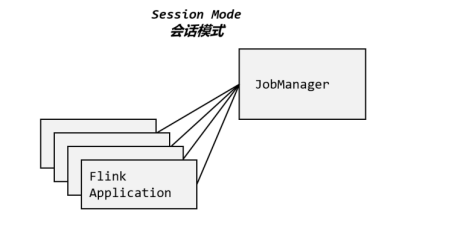
??��Ⱥ�����������dz�Խ����ҵ֮�ϵ�,��ҵ�����˾��ͷ���Դ,��Ⱥ��Ȼ�������С���Ȼ:��Ϊ��Դ�ǹ�����,������Դ������,�ύ�µ���ҵ�ͻ�ʧ�ܡ�����,ͬһ�� TaskManager �Ͽ��������˺ܶ���ҵ,�������һ���������ϵ��� TaskManager 崻�,��ô������ҵ�����ܵ�Ӱ��
??�Ựģʽ�ʺ��ڵ�����ģС��ִ��ʱ��̵Ĵ�����ҵ
1.2 ����ҵģʽ(Per-Job Mode)
??����ҵģʽ���ϸ��һ��һ,��ȺֻΪ�����ҵ�������ɿͻ�������Ӧ�ó���,Ȼ��������Ⱥ,��ҵ���ύ�� JobManager,�����ַ��� TaskManager ִ�С���ҵ��ҵ��ɺ�,��Ⱥ�ͻ�ر�,������Դ�ᱻ�ͷš�ÿ����ҵ�������Լ��� JobManager����,ռ�ö�������Դ,��ʹ��������,����TaskManager 崻�Ҳ����Ӱ��������ҵ��
??����ҵģʽ�������������и����ȶ�,��ʵ��Ӧ�õ���ѡģʽ
ע:
??Flink ������ֱ�����е���ҵģʽ,��Ҫ����һЩ��Դ���������������Ⱥ,�� YARN
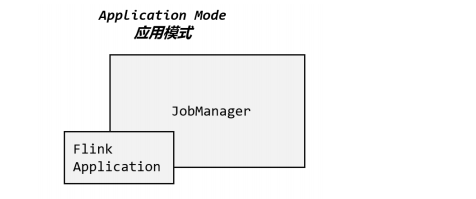
1.3 Ӧ��ģʽ(Application Mode)
??Ӧ�ô����ڿͻ�����ִ��,Ȼ���ɿͻ����ύ�� JobManager,�ͻ�����Ҫռ�ô�����������������������ͰѶ��������ݷ���JobManager;�����ύ��ҵ�õ���ͬһ���ͻ���,�ͻ���ؿͻ������ڽڵ����Դ���ġ�
??����취����,ֱ�Ӱ�Ӧ���ύ�� JobManger �����С�Ϊÿһ���ύ��Ӧ�õ�������һ��JobManager,Ҳ���Ǵ���һ����Ⱥ����� JobManager ֻΪִ����һ��Ӧ�ö�����,ִ�н���֮�� JobManager Ҳ�ر���
1.4 �ܽ�
??�ڻỰģʽ��,��Ⱥ���������ڶ����ڼ�Ⱥ�����е��κ���ҵ����������,�����ύ��������ҵ������Դ��������ҵģʽΪÿ���ύ����ҵ����һ����Ⱥ,�����˸��õ���Դ����,��ʱ��Ⱥ��������������ҵ���������ڰ����,Ӧ��ģʽΪÿ��Ӧ�ó���һ���Ự��Ⱥ,�� JobManager ��ֱ�ӵ���Ӧ�ó���� main()����
2. ϵͳ�ܹ�
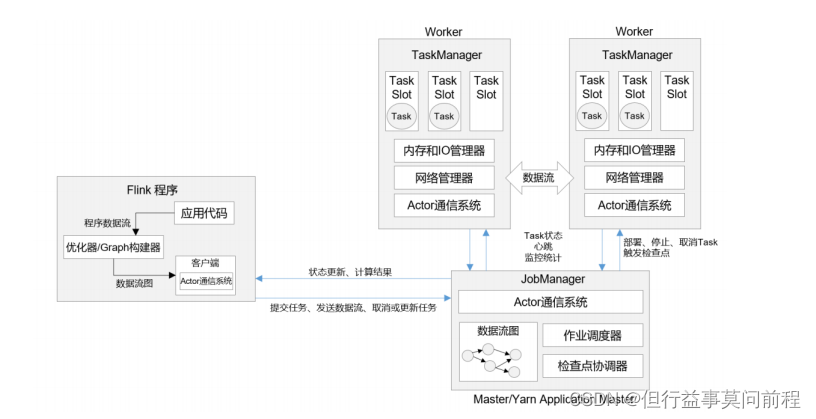
2.1 ���幹��
??Flink ������ʱ�ܹ���,����Ҫ�ľ����������:��ҵ������(JobManger)�����������(TaskManager)������һ���ύִ�е���ҵ,JobManager �����������ϵġ������ߡ�(Master),�����������,�����ڲ����Ǹ߿��õ������ֻ����һ��;�� TaskManager �ǡ������ߡ�(Worker��Slave),����ִ������������,���Կ�����һ��������
ע:
attached mode (default): The yarn-session.sh client submits the Flink cluster to YARN, but the client keeps running, tracking the state of the cluster. If the cluster fails, the client will show the error. If the client gets terminated, it will signal the cluster to shut down as well.
detached mode (-d or --detached): The yarn-session.sh client submits the Flink cluster to YARN, then the client returns. Another invocation of the client, or YARN tools is needed to stop the Flink cluster.
??�ͻ��˲����Ǵ���ϵͳ��һ����,��ֻ������ҵ���ύ��������˵,���ǵ��ó���� main ����,������ת���ɡ�������ͼ��(Dataflow Graph),������������ҵͼ(JobGraph),һ������ JobManager���ύ֮��,�����ִ����ʵ���ͻ���û�й�ϵ��;����ѡ��Ͽ��� JobManager ������, Ҳ���Լ����������ӡ��������ύ��ҵʱ,���ϵ�-d ����,���DZ�ʾ����ģʽ(detached mode),Ҳ���ǶϿ�����
2.1.1 ��ҵ������(JobManager)
??JobManger ���� 3 ����ͬ�����:

1. JobMaster
??JobMaster �� JobManager ������ĵ����,��������������ҵ(Job)������JobMaster�;���� Job ��һһ��Ӧ��,��� Job ����ͬʱ������һ�� Flink ��Ⱥ��, ÿ�� Job ����һ���Լ��� JobMaster������ҵ�ύʱ,JobMaster ���Ƚ��յ�Ҫִ�е�Ӧ��,����:Jar ��,������ͼ(dataflow graph),����ҵͼ(JobGraph)��JobMaster ��� JobGraph ת����һ�����������������ͼ,���ͼ��������ִ��ͼ��(ExecutionGraph),�����������п��Բ���ִ�е����� JobMaster ������Դ������(ResourceManager)��������,����ִ�������Ҫ����Դ��һ������ȡ�����㹻����Դ,�ͻὫִ��ͼ�ַ��������������ǵ� TaskManager �ϡ��������й�����,JobMaster �Ḻ��������Ҫ����Э���IJ���,����˵����(checkpoints)��Э��
2. ��Դ������(ResourceManager)
??ResourceManager ��Ҫ������Դ�ķ������,�� Flink ��Ⱥ��ֻ��һ������ν����Դ��,��Ҫ��ָ TaskManager �������(task slots)������۾��� Flink ��Ⱥ�е���Դ���䵥Ԫ,�����˻�������ִ�м����һ�� CPU ���ڴ���Դ��ÿһ������(Task)����Ҫ���䵽һ�� slot ��ִ�С�ע��Ҫ�� Flink ���õ� ResourceManager ��������Դ����ƽ̨(���� YARN)��ResourceManager ���ֿ���Flink �� ResourceManager,��Բ�ͬ�Ļ�������Դ����ƽ̨�в�ͬ�ľ���ʵ�֡��� Standalone ����ʱ,��Ϊ TaskManager �ǵ���������(û��Per-Job ģʽ),���� ResourceManager ֻ�ַܷ�����TaskManager �������,���ܵ���������TaskManager����������Դ����ƽ̨ʱ,�Ͳ��ܴ����ơ����µ���ҵ������Դʱ,ResourceManager �Ὣ�п��в�λ�� TaskManager ����� JobMaster�����ResourceManager û���㹻�������,������������Դ�ṩƽ̨����Ự,�����ṩ����TaskManager ���̵�����������,ResourceManager ������ͣ�����е� TaskManager,�ͷż�����Դ
3. �ַ���(Dispatcher)
??Dispatcher ��Ҫ�����ṩһ�� REST �ӿ�,�����ύӦ��,���Ҹ���Ϊÿһ�����ύ����ҵ����һ���µ� JobMaster �����Dispatcher Ҳ������һ�� Web UI,���������չʾ�ͼ����ҵִ�е���Ϣ��Dispatcher �ڼܹ��в����DZ����,�ڲ�ͬ�IJ���ģʽ�¿��ܻᱻ���Ե���
2.1.2 ���������(TaskManager)
??TaskManager �� Flink �еĹ�������,�������ľ�����������������,����Ҳ����Ϊ��Worker����Flink ��Ⱥ�б���������һ�� TaskManager;��Ȼ���ڷֲ�ʽ����Ŀ���,ͨ�����ж�� TaskManager ����,ÿһ�� TaskManager ��������һ�������������(task slots)��Slot����Դ���ȵ���С��λ,slot ������������ TaskManager �ܹ����д�������������������֮��,TaskManager ������Դ������ע������ slots;�յ���Դ��������ָ���,TaskManager �ͻὫһ�����߶����λ�ṩ�� JobMaster ����,JobMaster �Ϳ��Է���������ִ���ˡ���ִ�й�����,TaskManager ���Ի�������,�����Ը���������ͬһӦ�õ� TaskManager��������
2.2 �߲㼶�����ӽ�
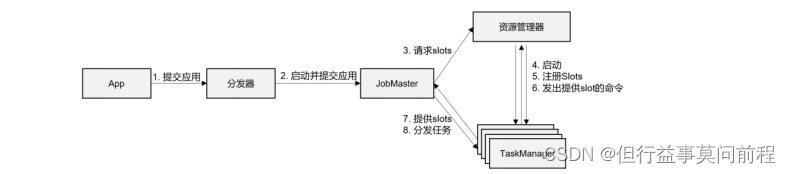
(1) һ�������,�ɿͻ���(App)ͨ���ַ����ṩ�� REST �ӿ�,����ҵ�ύ��JobManager
(2)�ɷַ������� JobMaster,������ҵ(���� JobGraph)�ύ�� JobMaster
(3)JobMaster �� JobGraph ����Ϊ��ִ�е� ExecutionGraph,�õ��������Դ����,Ȼ������Դ������������Դ(slots)��
(4)��Դ�������жϵ�ǰ�Ƿ����㹻�Ŀ�����Դ;���û��,�����µ� TaskManager
(5)TaskManager ����֮��,�� ResourceManager ע���Լ��Ŀ��������(slots)
(6)��Դ������֪ͨ TaskManager Ϊ�µ���ҵ�ṩ slots
(7)TaskManager ���ӵ���Ӧ�� JobMaster,�ṩ slots
(8)JobMaster ����Ҫִ�е�����ַ��� TaskManager
(9)TaskManager ִ������,����֮����Խ�������
3. ����ģʽ(Standalone)
3.1 ����
??����ģʽ(Standalone)�Dz��� Flink �������ķ�ʽ:����Ҫ������ Flink ���,��ֻ�Dz���ϵͳ�����е�һ�� JVM ���̡�
??����ģʽ�������κ��ⲿ����Դ����ƽ̨;�����Դ����,���߳��ֹ���,û���Զ���չ���ط�����Դ�ı�֤,�����ֶ����������Զ���ģʽһ��ֻ���ڿ������Ի���ҵ�dz��ٵij����¡�
3.2 �Ựģʽ���𡢵���ҵģʽ����(��֧��)��Ӧ��ģʽ����
4. YARN ģʽ��������мܹ�
4.1 ����
??YARN �ϲ���Ĺ�����:�ͻ��˰� Flink Ӧ���ύ�� Yarn �� ResourceManager, Yarn �� ResourceManager ���� Yarn �� NodeManager ��������������Щ������,Flink �Ჿ��JobManager �� TaskManager ��ʵ��,�Ӷ�������Ⱥ��Flink ����������� JobManger �ϵ���ҵ����Ҫ�� Slot ������̬���� TaskManager ��Դ
yarnģʽ����
??���hadoop����
echo $HADOOP_CLASSPATH
4.2 �Ựģʽ
4.2.1 ����
������Ⱥ:
(1)���� hadoop ��Ⱥ(HDFS, YARN)��
(2)ִ�нű������� YARN ��Ⱥ������Դ,����һ�� YARN �Ự,���� Flink ��Ⱥ
bin/yarn-session.sh -d -nm cz -qu hello
�������:
-d:����ģʽ,Flink YARN �ͻ��˺�̨����
-jm(�CjobManagerMemory):���� JobManager �����ڴ�,Ĭ�ϵ�λ MB
-nm(�Cname):������ YARN UI ��������ʾ��������
-qu(�Cqueue):ָ�� YARN ������
-tm(�CtaskManager):����ÿ�� TaskManager ��ʹ���ڴ�
ע:
??Flink1.11.0 �汾����ʹ��-n ������-s �����ֱ�ָ�� TaskManager ������ slot ����,YARN �ᰴ������̬���� TaskManager �� slot
YARN Session ����֮������һ�� web UI ��ַ�Լ�һ�� YARN application ID

����������yarnģʽflink��Ⱥ:
web UIΪhttp://hadoop104:42947
ֹͣ��Ⱥecho "stop" | ./bin/yarn-session.sh -id application_1654053140138_0001
ǿ��ֹͣyarn application -kill application_1654053140138_0001
�ύ��ҵ:
(1)ͨ�� Web UI �ύ��ҵ
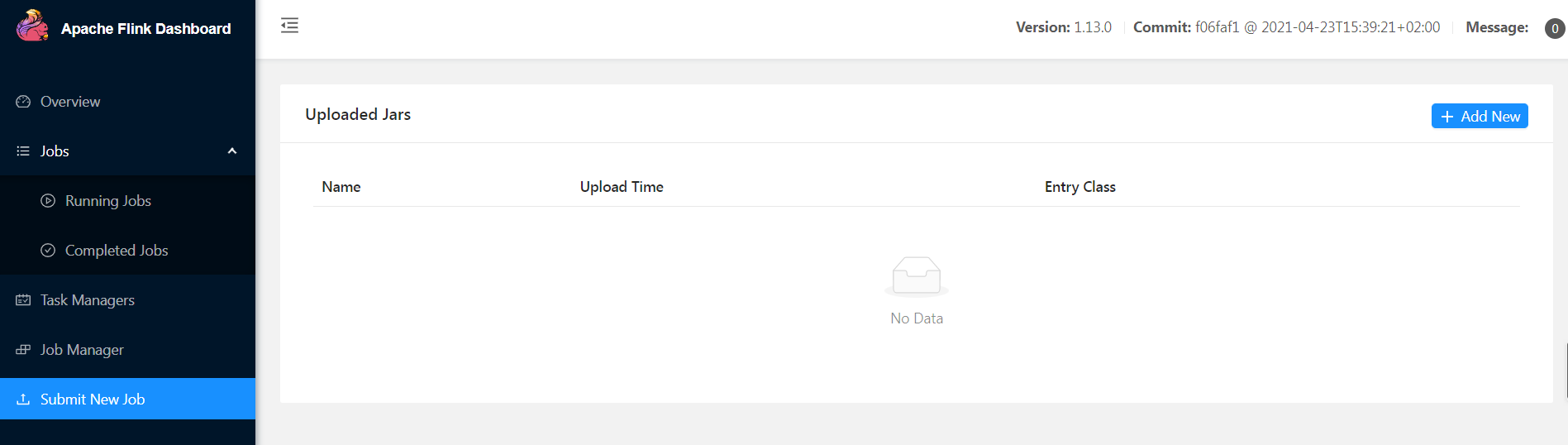
(2)ͨ���������ύ��ҵ
bin/flink run [OPTIONS] <jar-file> <arguments>
4.2.2 ����ʱ�ܹ�
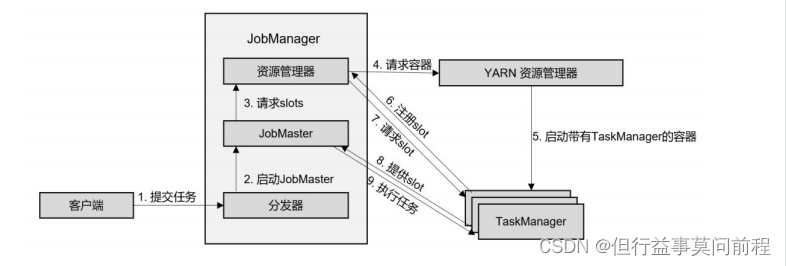
(1)�ͻ���ͨ�� REST �ӿ�,����ҵ�ύ���ַ���
(2)�ַ������� JobMaster,������ҵ(���� JobGraph)�ύ�� JobMaster
(3)JobMaster ����Դ������������Դ(slots)
(4)��Դ�������� YARN ����Դ���������� container ��Դ
(5)YARN �����µ� TaskManager ����
(6)TaskManager ����֮��,�� Flink ����Դ������ע���Լ��Ŀ��������
(7)��Դ������֪ͨ TaskManager Ϊ�µ���ҵ�ṩ slots
(8)TaskManager ���ӵ���Ӧ�� JobMaster,�ṩ slots
(9)JobMaster ����Ҫִ�е�����ַ��� TaskManager,ִ������
4.3 ����ҵģʽ
4.3.1 ����
??�� YARN ������,���������ⲿƽ̨����Դ����,���Կ���ֱ���� YARN �ύһ����������ҵ,�Ӷ�����һ�� Flink ��Ⱥ
(1)ִ�������ύ��ҵ
bin/flink run -d -t yarn-per-job -creview.part2.StreamWordCount libexec/FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar
(2)�� YARN �� ResourceManager ����鿴ִ�����


��� Tracking URL

(3)ʹ�������в鿴��ȡ����ҵ
bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY

bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>

4.3.2 ����ʱ�ܹ�
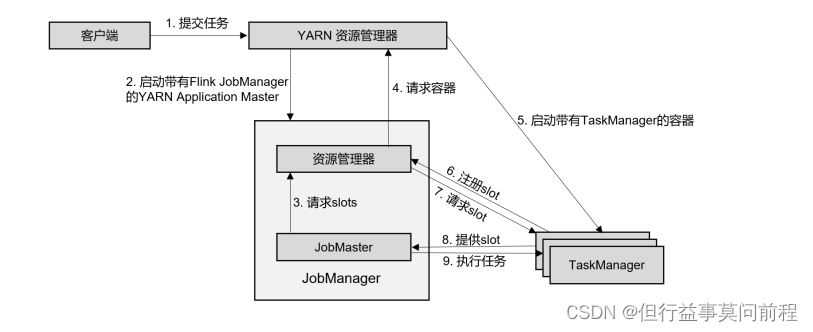
(1)�ͻ��˽���ҵ�ύ�� YARN ����Դ������,��һ���л�ͬʱ�� Flink �� Jar ���������ϴ��� HDFS,�Ա�������� Flink ������������
(2)YARN ����Դ���������� Container ��Դ,���� Flink JobManager,������ҵ�ύ��JobMaster������ʡ���� Dispatcher ���
(3)JobMaster ����Դ������������Դ(slots)
(4)��Դ�������� YARN ����Դ���������� container ��Դ
(5)YARN �����µ� TaskManager ����
(6)TaskManager ����֮��,�� Flink ����Դ������ע���Լ��Ŀ��������
(7)��Դ������֪ͨ TaskManager Ϊ�µ���ҵ�ṩ slots
(8)TaskManager ���ӵ���Ӧ�� JobMaster,�ṩ slots
(9)JobMaster ����Ҫִ�е�����ַ��� TaskManager,ִ������
4.4 Ӧ��ģʽ
4.4.1 ����
(1)ִ�������ύ��ҵ
bin/flink run-application -t yarn-application -c review.part2.StreamWordCount libexec/FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar

(2)���������в鿴��ȡ����ҵ
bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY

$ bin/flink cancel -t yarn-application
-Dyarn.application.id=application_XXXX_YY <jobId>

(3)��ͨ�� yarn.provided.lib.dirs ����ѡ��ָ��λ��,�� jar �ϴ���Զ��
4.4.2 ����ʱ�ܹ�
??Ӧ��ģʽ�뵥��ҵģʽ���ύ���̷dz�����,ֻ�dz�ʼ�ύ�� YARN ��Դ�������IJ����Ǿ������ҵ,��������Ӧ�á�һ��Ӧ���п��ܰ����˶����ҵ,��Щ��ҵ������ Flink ��Ⱥ���������Զ�Ӧ�� JobMaster
4.5 �߿���
??Standalone ģʽ��, ͬʱ������� JobManager, һ��Ϊleader,����Ϊstandby, �� leader ����, �����IJŻ���һ����Ϊ leader�� �� YARN �ĸ߿�����ֻ����һ�� Jobmanager, ����� Jobmanager ����֮��, YARN ���ٴ�����һ��, ������ʵ�����õ� YARN �����Դ�����ʵ�ֵĸ߿���
(1)�� yarn-site.xml ������
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
(2)�� flink-conf.yaml �����á�
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfsĿ¼
high-availability.zookeeper.quorum: hadoop102:2181,hadoop103:2181,hadoop104:2181
high-availability.zookeeper.path.root: /flink-yarn
(3)���� yarn-session
(4)ɱ�� JobManager, �鿴�������
ע��:
yarn-site.xml �����õ��� JobManager ��������������, flink-conf.xml �еĴ���Ӧ��С�����ֵ
ps:�ο��鼮pdf:
����:�ٶ�����
��ȡ��:1256

