接口响应速度优化和sql优化实操
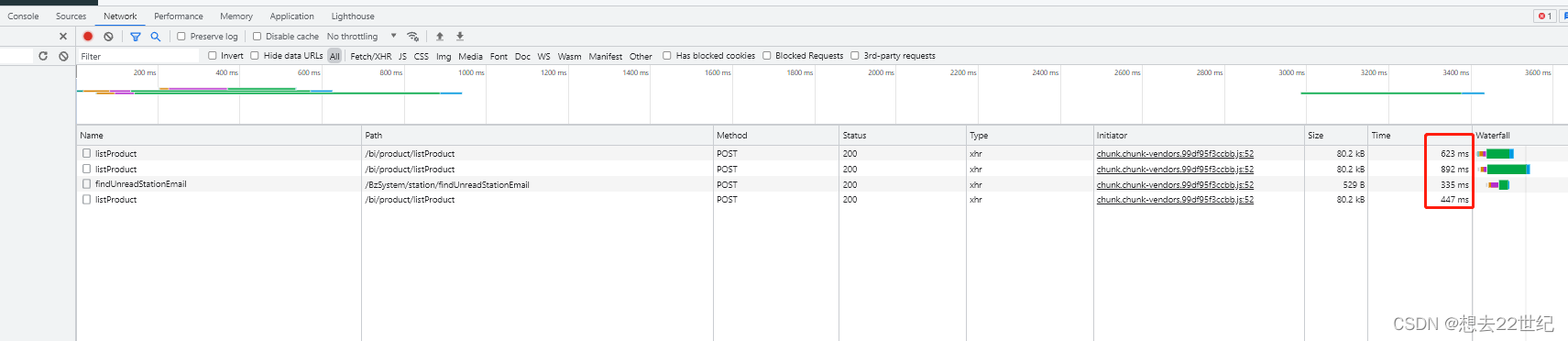
接口响应速度达到20s
前端展示接口平均速度为8s,最坏情况到达20s

默认搜索条件十分复杂,基本每个字段都传条件,不好建立联合索引
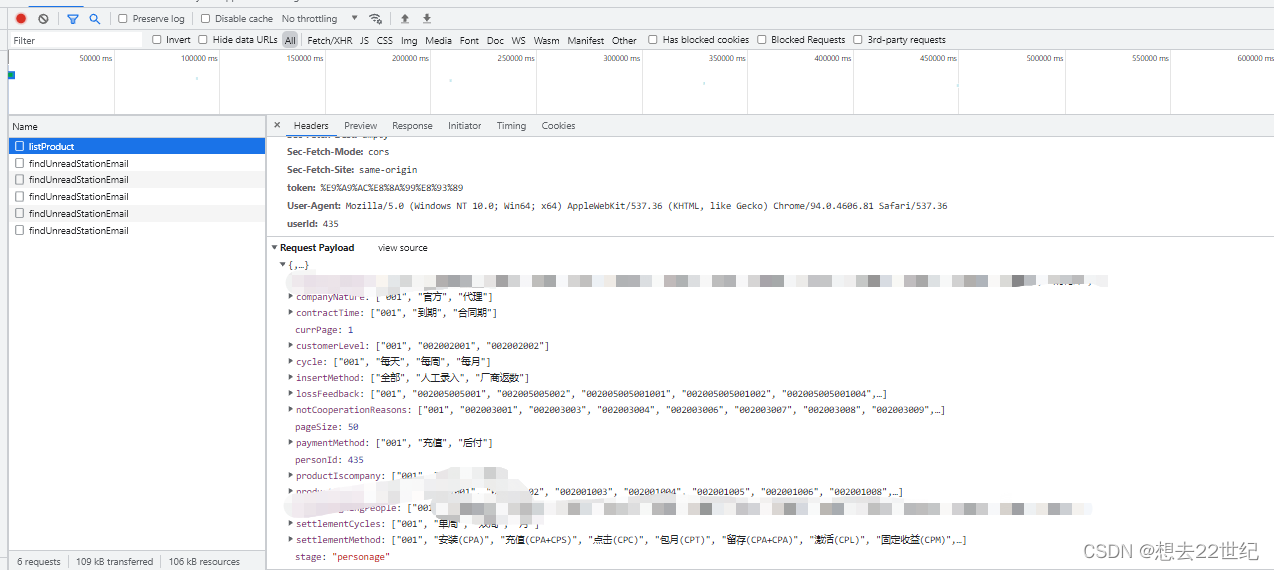
多线程异步查询
接口内容分为两部分,并且查询相互独立
1、查询页面集合(方法内存在很多业务逻辑,不是简单查询)
2、查询总数 (方法内存在很多业务逻辑,不是简单查询)
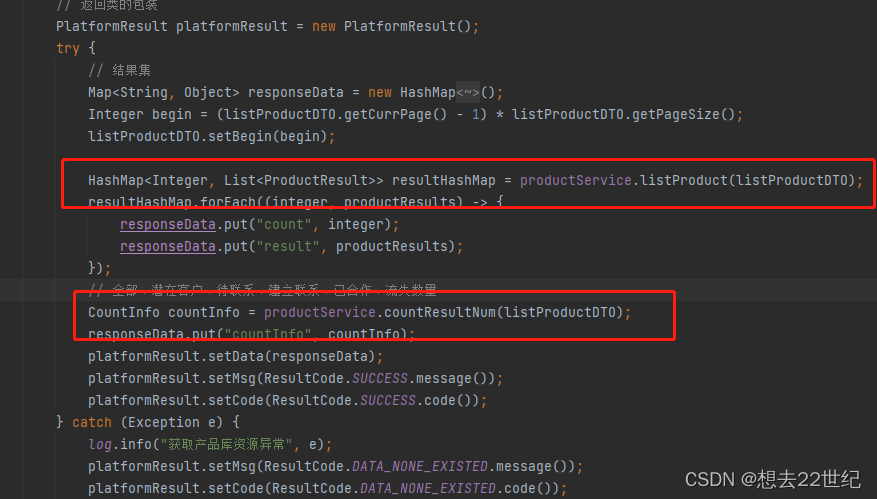 所以使用线程池来执行查询操作,这里使用Callable接口,Callable对象执行后可以有返回值,运行Callable任务可以得到一个Future对象,通过Future对象可以了解任务执行情况,可以使用future.get()方法等待线程的执行结果。(这里也可以使用CountDownLanch)
所以使用线程池来执行查询操作,这里使用Callable接口,Callable对象执行后可以有返回值,运行Callable任务可以得到一个Future对象,通过Future对象可以了解任务执行情况,可以使用future.get()方法等待线程的执行结果。(这里也可以使用CountDownLanch)
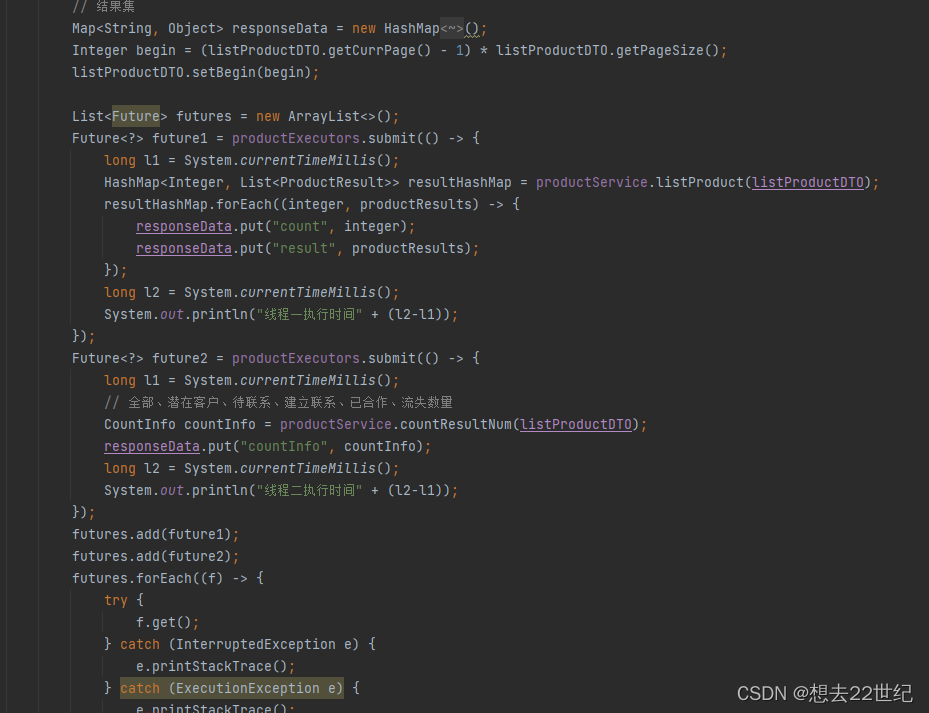
成功解决?
本以为到这里简单处理一下,就可以达到需求方可以接受的层度,自测接口一看
线程1耗时:6000ms
线程2耗时:7000ms
没办法只有梳理上百行的业务和sql(苦逼)!!!
一条一条的找到慢sql(这里还是精简后的sql,实际查询条件那叫一个眼花缭乱)
这里命名为:慢sqlA,执行耗时7s
SELECT COUNT(1) FROM (
SELECT COUNT(1) FROM `tb_product_information_pass` AS pass LEFT JOIN tb_product_contacts
AS con ON con.product_information_id = pass.id LEFT JOIN tb_product_query_data pqd ON
pqd.product_id = pass.id WHERE `product_status` = 1 AND pass.`show_id` != 1
GROUP BY product_group_name ) AS t
这里命名为:慢sqlB,执行耗时5s
SELECT COUNT(DISTINCT pass.id) AS `all`,
SUM(IF(pass.`customer_rank` = '003003001', 1, 0)) AS `hide`,
SUM(IF(pass.`customer_rank` = '003003002', 1, 0)) AS `toContact`,
SUM(IF(pass.`customer_rank` = '003003003', 1, 0)) AS `setContact`,
SUM(IF(pass.`customer_rank` = '003003004', 1, 0)) AS `cooperationed`,
SUM(IF(pass.`customer_rank` = '003003005', 1, 0)) AS `lose`
FROM (
SELECT pc_index_data,pass.*
FROM `tb_product_information_pass` AS pass
LEFT JOIN tb_product_query_data pqd ON pqd.product_id = pass.id
GROUP BY pass.id
) AS pass
LEFT JOIN tb_product_contacts AS con ON con.product_information_id = pass.id
WHERE pass.`show_id` != 1 and `business_affairs` IN ( '方' ) and pass.`product_status` = 1
这里命名为:慢sqlC,耗时6s
SELECT pc_index_data, COUNT(temp.productId) AS child_amount,`productId`, `product_name`, `product_source`, `product_iscompany`, `company_name`, `company_nature`, `user_name`,
`id_card`, `contact_address`, `customer_level`, `control_volume`, `number`, `settlement_cycles`, `settlement_method`, `share_proportion`, `cycle`, `kpi`, `advance_payment`,
`payment_method`, `business_affairs`, `not_cooperation_reasons`, `loss_feedback`, `input_time`, `customer_rank`, `related_Id`, `edit_type`, `delete_type`, `second_id`, `person_id`,
`productPass`, `product_status`, `contract_time`, `second_signing_people`, `second_company_term`, `contract_code`, `stage_time` , `hits` , `contact_number`,`product_group_name`
FROM (
SELECT MAX( IFNULL(pqd.pc_index_data,0)) AS pc_index_data, pass.`id` AS `productId`, `product_name`, `product_source`, `product_iscompany`, `company_name`, `company_nature`, `user_name`, `id_card`,
`contact_address`, `customer_level`, `control_volume`, `number`, `settlement_cycles`, `settlement_method`, `share_proportion`, `cycle`, `kpi`, `advance_payment`, `payment_method`, `business_affairs`,
`not_cooperation_reasons`, `loss_feedback`, `input_time`, `customer_rank`, `related_Id`, `edit_type`, `delete_type`, `second_id`, `person_id`, pass.`pass_type` AS `productPass`, `product_status`,
`contract_time`, `second_signing_people`, `second_company_term`, `contract_code`, `stage_time` , `hits` , '' AS `contact_number`,`product_group_name`
FROM `tb_product_information_pass` AS pass LEFT JOIN tb_product_contacts AS con ON con.product_information_id = pass.id LEFT JOIN tb_product_query_data pqd ON pqd.product_id = pass.id
WHERE `product_status` = 1 AND pass.`show_id` != 1 GROUP BY pass.id ) AS temp GROUP BY product_group_name ORDER BY `productPass` ASC, input_time DESC
数据量情况
tb_product_information_pass:7w
tb_product_query_data :300w
tb_product_contacts :8w
慢sqlA优化
我心伤悲
对product_status和product_group_name字段建立联合索引,查询速度并没有明显变化。
多表联查优化策略:
1、left join时候采用小表驱动大表的方式,即把数据量较小的表放在左边(无明显)
==2、将left join 改成inner join(实际上是减少数据量,但是这里右表的null值对业务来说任然具有意义) ==
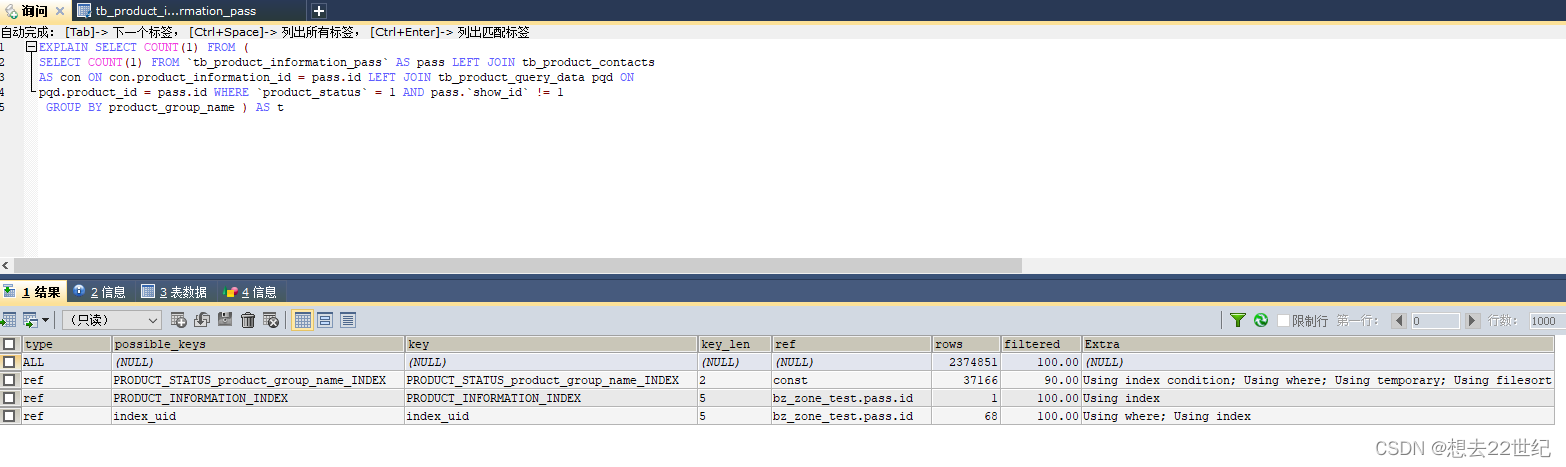 这里用了出现了using filesort与using temporate,using index,using where。
这里用了出现了using filesort与using temporate,using index,using where。
1、using index:当我们的查询列表以及搜索条件中只包含属于某个索引的列, 也就是在可以使用索引覆盖的情况下会出现
2、using where:当我们使用全表扫描来执行对某个表的查询, 并且该语句的 WHERE 子句中有针对该表的搜索条件时, 在 Extra 列中会提示上述额外信息。当使用索引访问来执行对某个表的查询, 并且该语句的 WHERE 子句中有除了该索引包含的列之外的其他搜索条件时, 在 Extra 列中也会提示上述信息。
3、using filesort:多出现在分组或者排序时,很多情况下排序操作无法使用到索引, 只能在内存中(记录较少的时候) 或者磁盘中(记录较多的时候) 进行排序, MySQL把这种在内存中或者磁盘上进行排序的方式统称为文件排序。 如果某个查询需要使用文件排序的方式执行查询, 就会在执行计划的 Extra 列中显示 Using filesort提示
4、using temporate:在许多查询的执行过程中, MySQL 可能会借助临时表来完成一些功能, 比如去重、 排序之类的, 比如我们在执行许多包含 DISTINCT、 GROUP BY、 UNION 等子句的查询过程中, 如果不能有效利用索引来完成查询, MySQL 很有可能寻求通过建立内部的临时表来执行查询。 如果查询中使用到了内部的临时表, 在执行计划的 Extra 列将会显示 Using temporary 提示
经过测试发现,这里的sql主要是由于group by而变慢的
group by 实际上等于group by column order by column,所以将
GROUP BY product_group_name 改为直接排序
GROUP BY product_group_name order by null,但是sql并没有明显提速。
柳暗花明又一村
优化using temporate
mysql在使用临时表时会首先使用内存临时表,当数据量溢出内存临时表时切换磁盘临时表
SQL_BIG_RESULT:这个提示告诉mysql直接走磁盘临时表,跳过内存临时表。
惊了(没干什么都提速到毫秒)
优化后的sql:
SELECT COUNT(1) FROM ( SELECT SQL_BIG_RESULT COUNT(1) FROM `tb_product_information_pass` AS pass LEFT JOIN tb_product_contacts AS con ON con.product_information_id = pass.id LEFT JOIN tb_product_query_data pqd ON pqd.product_id = pass.id WHERE `product_status` = 1 AND pass.`show_id` != 1 GROUP BY product_group_name ) AS t
慢sqlB优化
这里比较简单,前置搜索条件减少子查询的数据量,sql响应速度从5s变为1s。(nice)
SELECT COUNT(DISTINCT pass.id) AS `all`,
SUM(IF(pass.`customer_rank` = '003003001', 1, 0)) AS `hide`,
SUM(IF(pass.`customer_rank` = '003003002', 1, 0)) AS `toContact`,
SUM(IF(pass.`customer_rank` = '003003003', 1, 0)) AS `setContact`,
SUM(IF(pass.`customer_rank` = '003003004', 1, 0)) AS `cooperationed`,
SUM(IF(pass.`customer_rank` = '003003005', 1, 0)) AS `lose`
FROM (
SELECT pc_index_data,pass.*
FROM `tb_product_information_pass` AS pass
LEFT JOIN tb_product_query_data pqd ON pqd.product_id = pass.id
WHERE `business_affairs` IN ( '方' ) and pass.`product_status` = 1 GROUP BY pass.id
) AS pass
LEFT JOIN tb_product_contacts AS con ON con.product_information_id = pass.id
WHERE pass.`show_id` != 1
继续努力慢sqlC优化
分解sql
这条sql两层分组,每层分组都具有聚合函数,拆解sql,其主要耗时再MAX( IFNULL(pqd.pc_index_data,0))这条函数上,其数据量100w条,在这个基本上载进行函数操作可想而知的慢。
这里我首先想到的是有没有办法从sql层面削去两层分组和函数。(并没有找到合适的方法,跪求sql语句层面的优化)
由于数据量的问题,内存中处理函数也不可取
分析业务和数据表。
tb_product_query_data 表的数据量达到惊人的300w,但是联表查询只用了一个字段
pc_index_data,是不是可以减少一个连表查询内,在tb_product_information_pass表建立冗余字段pc_index_data,降低查询数据量呢
说干就干,建冗余字段
1、建冗余字段

2、并将tb_product_query_data 的数据同步置tb_product_information_pass
UPDATE tb_product_information_pass a , (SELECT product_id,MAX(IFNULL(pc_index_data,0)) AS pc_index_data FROM tb_product_query_data GROUP BY product_id) b SET a.pc_index_data = b.pc_index_data WHERE a.id = b.`product_id`
3、建立触发器,监控tb_product_query_data 表的数据变化同步到tb_product_information_pass
DELIMITER $$
USE `bz_zone_test`$$
DROP TRIGGER /*!50032 IF EXISTS */ `insert_product_query`$$
CREATE
/*!50017 DEFINER = 'bz_zone_test'@'%' */
TRIGGER `insert_product_query` AFTER INSERT ON `tb_product_query_data`
FOR EACH ROW BEGIN
UPDATE tb_product_information_pass SET pc_index_data = IF(new.pc_index_data <= pc_index_data,pc_index_data,new.pc_index_data)
WHERE id = new.product_id;
END;
$$
DELIMITER ;
DELIMITER $$
USE `bz_zone_test`$$
DROP TRIGGER /*!50032 IF EXISTS */ `update_product_query`$$
CREATE
/*!50017 DEFINER = 'bz_zone_test'@'%' */
TRIGGER `update_product_query` AFTER UPDATE ON `tb_product_query_data`
FOR EACH ROW BEGIN
UPDATE tb_product_information_pass SET pc_index_data = IF(new.pc_index_data <= pc_index_data,pc_index_data,new.pc_index_data)
WHERE id = new.product_id;
END;
$$
DELIMITER ;
修改原sql,去掉烦人的函数
速度优化置1s内(开心)
大功告成
成就感十足