Ŀ¼
ǰ��
ͨ���û���һ�η������ݿ��е�ijЩ���ݡ�������̻�Ƚ���,��Ϊ�Ǵ�Ӳ���϶�ȡ�ġ����ǽ����û����ʵ����ݴ��ڻ�����,������һ���ٷ�����Щ���ݵ�ʱ��Ϳ���ֱ�Ӵӻ����л�ȡ�ˡ������������ֱ�Ӳ����ڴ�,�����ٶ��൱�졣������ݿ��еĶ�Ӧ���ݸı��֮��,ͬ���ı仺������Ӧ�����ݼ���,�������Լ������ݿ�ѹ��,��ѯ�ڴ�Ȳ�ѯ���ݿ�Ч�ʸߡ�
��ƪ������Ҫ�ش�����:
1.�����Ĺ�ϵ�����ݿ�?
2.�����ķǹ�ϵ�����ݿ�?
3.ʲô��Redis?
4.Ϊʲô��ҪRedis?
5.Redis������ܲ���?
һ����ϵ���ݿ���ǹ�ϵ�����ݿ�
1.1 ��ϵ���ݿ�
��ϵ�����ݿ���һ���ṹ�������ݿ�,�����ڹ�ϵģ��(��ά����ģ��)������,һ�������ڼ�¼.
SQL���(�����ݲ�ѯ����)����һ�ֻ��ڹ�ϵ�����ݿ������,����ִ�жԹ�ϵ�����ݿ������ݵļ����Ͳ���.
�����Ĺ�ϵ�����ݿ���� oracle��MySQL��SQL Server��Microsoft Access��DB2��PostgreSQL��.
�������ݿ���ʹ�õ�ʱ������Ƚ��⽨����Ʊ��ṹ,Ȼ��洢���ݵ�ʱ���ṹȥ��,�����������ṹ��ƥ��ͻ�洢ʧ��.
1.2 �ǹ�ϵ�����ݿ�
NoSQL(NoSQL=Not only SQL),��˼��"��������sQL",�Ƿǹ�ϵ�����ݿ���ܳ�.
���������Ĺ�ϵ�����ݿ�������ݿ�,����Ϊ�Ƿǹ�ϵ��.
����ҪԤ�Ƚ��⽨���������ݴ洢���ṹ,ÿ����¼�����в�ͬ���������ͺ��ֶθ���(������Ⱥ��������֡�ͼƬ����Ƶ�����ֵ�).
������NoSQL���ݿ���Redis��MongBD��Hbase��Memcached��ElasticSearch(�������ݿ�)��TSDB(���������ݿ�)��.
1.3 ��ϵ�����ݿ�ͷǹ�ϵ�����ݿ�����
1.3.1 ���ݴ洢��ʽ��ͬ
��ϵ�ͺͷǹ�ϵ�����ݿ����Ҫ���������ݴ洢�ķ�ʽ����ϵ��������Ȼ���DZ���ʽ��,��˴洢�����ݱ����к����С����ݱ����Ա˴˹���Э���洢,Ҳ��������ȡ���ݡ�
�����෴,�ǹ�ϵ�����ݲ��ʺϴ洢�����ݱ����к�����,���Ǵ�������һ�����ǹ�ϵ������ͨ���洢�����ݼ���,�����ĵ�����ֵ�Ի���ͼ�ṹ��������ݼ���������ѡ�����ݴ洢����ȡ��ʽ����ҪӰ�����ء�
1.3.2 ��չ��ʽ��ͬ
- ������չ:��չCPU���ڴ桢ʹ�ü۸��С�ͻ������ͻ�
- ������չ:ʹ�ö�̨������۵���ͨ��������������Ⱥ��
SQL��NoSQL���ݿ����IJ�����������չ��ʽ��,Ҫ֧����������������ȻҪ��չ��
Ҫ֧�ָ��ಢ����,SQL���ݿ���������չ,Ҳ����˵��ߴ�������,ʹ���ٶȸ����ٵļ����,����������ͬ�����ݼ������ˡ���Ϊ���ݴ洢�ڹ�ϵ����,����������ƿ�������漰�ܶ����,�ⶼ��Ҫͨ���������������˷�����ȻSQL���ݿ��кܴ���չ�ռ�,�����տ϶���ﵽ������չ��
��NoSQL���ݿ��Ǻ�����չ�ġ���Ϊ�ǹ�ϵ�����ݴ洢��Ȼ���Ƿֲ�ʽ��,NoSQL���ݿ����չ����ͨ������Դ�����Ӹ�����ͨ�����ݿ������(�ڵ�)���ֵ����ء�
1.3.3 �������Ե�֧�ֲ�ͬ
������ݲ�����Ҫ�������Ի��߸������ݲ�ѯ��Ҫ����ִ�мƻ�,��ô��ͳ��sQL���ݿ�����ܺ��ȶ��Է��濼����������ѡ��SQL���ݿ�֧�ֶ�����ԭ����ϸ���ȿ���,�������ڻع�����
��ȻNoSQL���ݿ�Ҳ����ʹ���������,���ȶ��Է���û����ϵ�����ݿ�Ƚ�,�����������������ļ�ֵ���ڲ�������չ�Ժʹ��������������档
1.4 �ǹ�ϵ�����ݿ�����ı���
������Ӧ��Web2.0����̬��վ���͵���������.
(1)High performance�������ݿ�߲�����д����
(2)Huge Storage���Ժ������ݸ�Ч�洢���������
(3)High Scalability&&High Availabilityһ�����ݿ�߿���չ����߿���������
��ϵ�����ݿ�ͷǹ�ϵ�����ݿⶼ�и��Ե��ص���Ӧ�ó���,���ߵĽ��ܽ�Ͻ����Web2.0�����ݿⷢչ�����µ�˼·.�ù�ϵ�����ݿ��ע�ڹ�ϵ�ϺͶ����ݵ�һ���Ա���,�ǹ�ϵ�����ݿ��ע�ڴ洢��Ч����.����,�ڶ�д�����MysQ���ݿ����,���Ѿ������ʵ����ݴ洢�ڷǹ�ϵ�����ݿ���,���������ٶ�.
1.5 ��
��ϵ�����ݿ�:
ʵ���C>���ݿ�C>��(table)�C>��¼��(row)�������ֶ�(column)
�ǹ�ϵ�����ݿ�:
ʵ���C>���ݿ�C>���Ϻ�(collection)�C>��ֵ��(key-value)
�ǹ�ϵ�����ݿⲻ��Ҫ�ֶ������ݿ�ͼ���(��).
����Redis���
Redis(Զ���ֵ������)��һ����Դ�ġ�ʹ��c���Ա�д��NosQL���ݿ�
Redis �����ڴ����в�֧�ֳ־û�,����key-value(��ֵ��)�Ĵ洢��ʽ,��Ŀǰ�ֲ�ʽ�ܹ��в��ɻ��һ��.
Redis�����������ǵ�����ģ��,Ҳ������һ̨�������Ͽ���ͬʱ�������Redis����,Redis��ʵ�ʴ����ٶ�������ȫ�����������̵�ִ��Ч��.���ڷ�������ֻ����һ��Redis����,������ͻ���ͬʱ����ʱ,�������Ĵ��������ǻ���һ���̶ȵ��½�;����ͬһ̨�������Ͽ������Redis����,Redis����߲�������������ͬʱ�����������cpU��ɺܴ�ѹ��.��:��ʵ������������,��Ҫ����ʵ�ʵ������������������ٸ�Redis����.���Ը߲���Ҫ�����һЩ,���ܻῼ����ͬһ̨�������Ͽ����������.��cpU��Դ�ȽϽ���,���õ����̼���.

2.1 Redis�ŵ�
(1)���м��ߵ����ݶ�д�ٶ�:���ݶ�ȡ���ٶ���߿ɴﵽ110000��/s,����д���ٶ���߿ɴﵽ81000��/s.
(2)֧�ַḻ����������:֧��key-value(�洢�ṹ)��String��Lists��Hashes��Sets(����)��Sorted Sets (���ϻ��zset)���������Ͳ���.
(3)֧�����ݵij־û�:���Խ��ڴ��е����ݱ����ڴ�����,������ʱ������ٴμ��ؽ���ʹ��.
(4)ԭ����:Redis���в�������ԭ���Ե�.
(5)֧�����ݱ���:��master-salveģʽ�����ݱ���.
Redis��Ϊ�����ڴ����е����ݿ�,��һ�������ܵĻ���,һ��Ӧ����session���桢���С����а�����������������¡�����������ۡ��������ĵ�.
Redis ����������ʵʱ��Ҫ��ߡ����ݴ洢�й��ں���̭�����ġ�����Ҫ�־û�����ֻ��Ҫ��֤��һ���ԡ����ij���.
2.2 Redisȱ��
- ��������ݿ�˫дһ��������
- ����ѩ������
- �����������
- ����IJ�����������
2.3 RedisΪʲô��ô��
1.Redis��һ��ڴ�ṹ,�����˴���I/O�Ⱥ�ʱ����
2.Redis������ĺ���ģ��Ϊ���߳�,������������,�Լ�Ƶ�������̺߳������̵߳Ĵ���,�������߳��������л�������
3.�����˷�����I/O��·���û���,��������˲���Ч��
ע:��Redis 6.0�������ӵĶ��߳�Ҳֻ����Դ�������������̲����˶���,�����ݵĶ�д����,��Ȼ�ǵ��̴߳����ġ�
2.4 Redis��memcached�Ƚ�
| Memcached | Redis | |
|---|---|---|
| ���� | Key-value���ݿ� | Key-value���ݿ� |
| ���ڲ��� | ֧�� | ֧�� |
| �������� | ��һ�������� | ����������� |
| �־û� | ��֧�� | ֧�� |
| ���Ӹ��� | ��֧�� | ֧�� |
| �����ڴ� | ��֧�� | ֧�� |
����Redis��װ����
3.1 Redis��װ
#�رշ���ǽ
systemct1 stop firewalld
systemct1 disabled firewalld
setenforce 0
#���ر��빤��
yum install -y gcc gcc-c++ make
#�ϴ�����������ѹ
tar zxvf redis-5.0.7.tar.gz
cd /opt/redis-5.0.7/
#ָ����װ·����ʼ��װ
make && make PREFIX=/usr/local/redis install
#����RedisԴ�����ֱ���ṩ��Makefile�ļ�,�����ڽ�ѹ����������,������ִ��./configure ��������,��ֱ��ִ��make��make install������а�װ.
#ִ���������ṩ��insta11 server.sh �ű��ļ�����Redis��������Ҫ����������ļ�
cd/opt/redis-5.0.7/utils
./install_server.sh #һֱ�س�
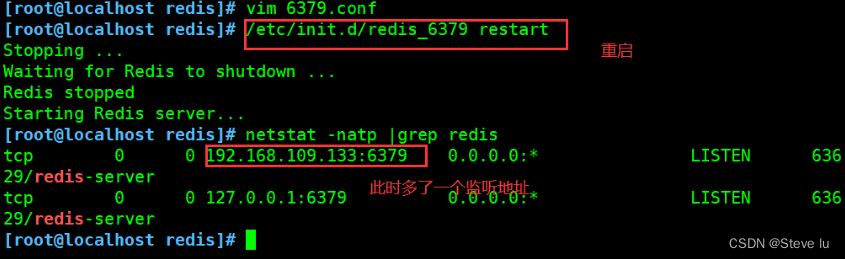
Please select the redis executable path [] /usr/local/redis/bin/redis-server#��Ҫ�ֶ���Ϊ
/usr/local/redis/bin/redis-server #ע��Ҫһ������ȷ����
#�Ż�·��
ln -s /usr/local/redis/bin/* /usr/local/bin/
#�鿴�˿�״̬
netstat -natp |grep redis



#����/�ر�/����
/etc/init.d/redis_6379 stop
/etc/init.d/redis_6379 start
/etc/init.d/redis_6379 restart
#�����ļ�����
cd /etc/redis/
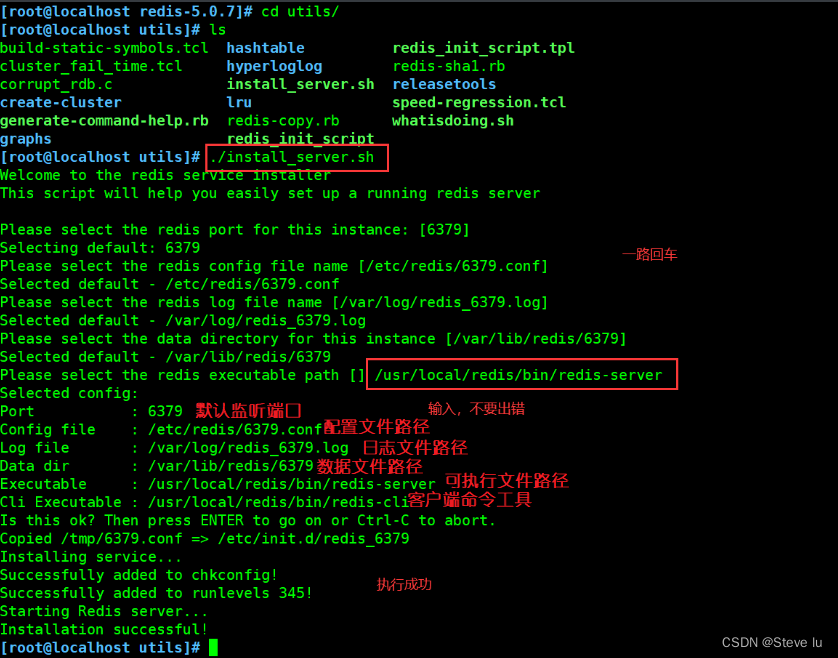
vim 6379.conf
......
70 bind 127.0.0.1 192.168.109.133 #������IP��ַ
93 port 6379 #�����˿�
137 daemonize yes #��̨����
159 pidfile /var/run/redis_6379.pid #Redis�Ľ��̺ű���λ��
172 logfile /var/log/redis_6379.log #��־�����λ��
187 databases 16 #�����������(���0-15)

3.2 Redis�����
| ���� | ���� |
|---|---|
| redis-server | ��������redis���� |
| redis-benchmark | ���ڼ��redis�ڱ���������Ч�� |
| redis-check-aof | ��AOF�־û��ļ� |
| redis-check-rdb | ��RDB�־û��ļ� |
| redis-cli | redis������� |
3.3 redis-cli:redis�������
�:redis-cli -h host -p port -a password
-h:ָ��Զ��������
-p:ָ��Redis����Ķ˿ں�
-a:ָ������,δ�������ݿ��������ʡ��
#-aѡ�����������κ�ѡ���ʾʹ��127.0.0.1:6379���ӱ����ϵ�Redis���ݿ�
#��¼����
redis-cli

3.4 redis-benchmark ���Թ���
redis-benchmark�ǹٷ��Դ���Redis���ܲ��Թ���,������Ч�IJ���Redis���������
�����IJ����:redis-benchmark [ѡ��] [ѡ��ֵ].
-h:ָ��������������.
-p:ָ���������˿�.
-s:ָ�������� socket
-c:ָ������������.
-n:ָ��������.
-d:���ֽڵ���ʽָ��SET/GETֵ�����ݴ�С.
-k:l=keep alive 0=reconnect
-r:SET/GET/INCR ʹ�����key,SADDʹ�����ֵ.
-P:ͨ���ܵ�����<numreg>����.
-q:ǿ���˳�redis.����ʾquery/secֵ.
--csv:��CSV��ʽ���.
-l:����ѭ��,����ִ�в���.
-t:�������Զ��ŷָ��IJ��������б�.
-I:Idleģʽ.����N��idle���Ӳ��ȴ�.
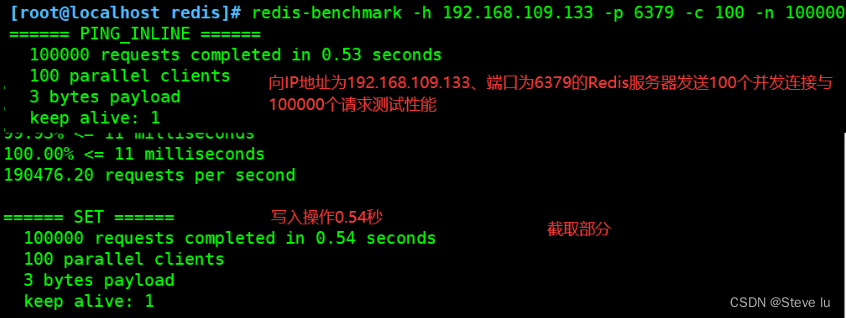
#��IP��ַΪ192.168.109.133���˿�Ϊ6379��Redis����������100������������100000�������������
redis-benchmark -h 192.168.109.133 -p 6379 -c 100 -n 100000
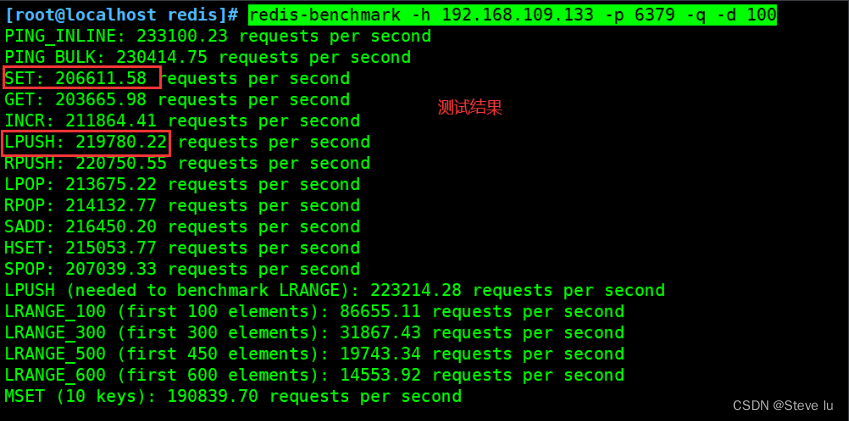
#���Դ�ȡ��СΪ100�ֽڵ����ݰ�������
redis-benchmark -h 192.168.109.133 -p 6379 -q -d 100
#���Ա�����Redis�����ڽ���set��lpush����ʱ������
redis-benchmark -t set,lpush -n 100000 -q

�ġ�Redis��������
| ���� | ���� |
|---|---|
| set | ������� |
| get | ��ȡ���� |
| keys * | �鿴���е�key |
| keys k? | �鿴k��ͷ��������һλ������ |
| exists | �жϼ��Ƿ����(����1,������0) |
| del | ɾ���� |
| type | �鿴����Ӧ��valueֵ���� |
| rename key1 key2 | ����,����key2�Ƿ���ڶ�������ɹ�,�������key1�Ḳ��key2 |
| renamenx key1 key2 | ����,��key2������,���Ը����ɹ�;��֮���� |
| dbsize | �鿴��ǰ���ݿ���key����Ŀ |
4.1 set��get
set:�������,�����ʽΪset key value
get:��ȡ����,�����ʽΪ get key
127.0.0.1:6379>set teacher zhangsan
OK
127.0.0.1:6379>get teacher
"zhangsan"

4.2 keys
#keys�������ȡ���Ϲ���ļ�ֵ�б�,ͨ��������Խ��*��?��ѡ����ʹ��.
#�ȴ���������
127.0.0.1:6379>set k1 1
127.0.0.1:6379>set k2 2
127.0.0.1:6379>set k3 3
127.0.0.1:6379>set vl 4
127.0.0.1:6379>set v5 5
127.0.0.1:6379>set v22 5
127.0.0.1:6379>KEYS * #�鿴��ǰ���ݿ������м�
127.0.0.1:6379>KEYS v* #�鿴��ǰ���ݿ�����v��ͷ������
127.0.0.1:6379>KEYS v? #�鿴��ǰ���ݿ�����v��ͷ�����������һλ������
127.0.0.1:6379>KEYS v?? #�鿴��ǰ���ݿ�����v��ͷv��ͷ�������������λ������

4.3 exists �жϼ��Ƿ����
����1,����
����0,������
127.0.0.1:6379> exists teacher
(integer) 1
127.0.0.1:6379> exists name
(integer) 0
127.0.0.1:6379>

4.4 del ɾ������
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "v1"
5) "k2"
6) "teacher"
7) "k4"
8) "myset:__rand_int__"
9) "counter:__rand_int__"
10) "key:__rand_int__"
11) "k1"
12) "k5"
127.0.0.1:6379> del teacher
(integer) 1
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "v1"
5) "k2"
6) "k4"
7) "myset:__rand_int__"
8) "counter:__rand_int__"
9) "key:__rand_int__"
10) "k1"
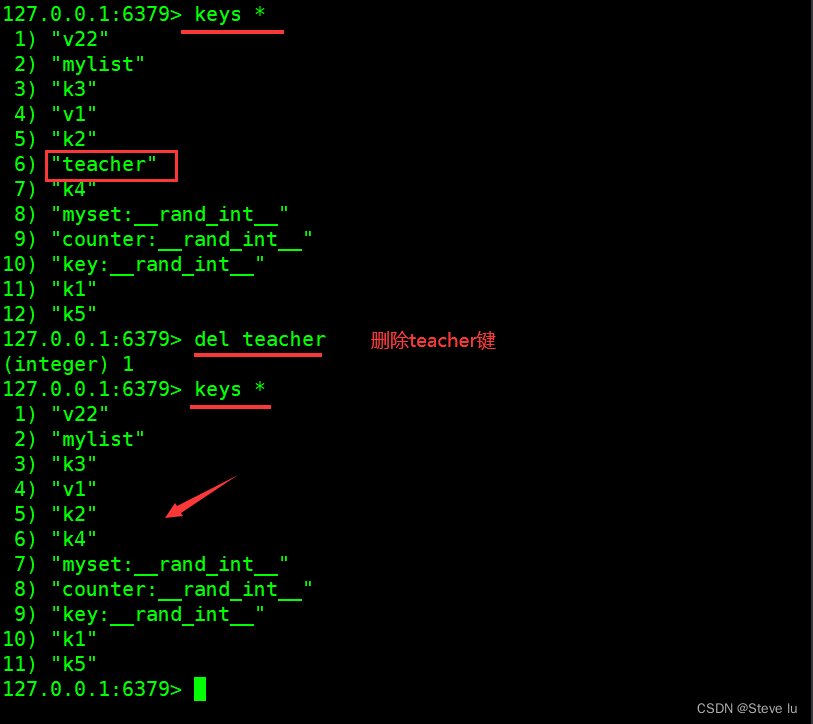
4.5 rename ������
#ʹ��rename�������������ʱ,����Ŀ��key�Ƿ���ڶ�����������,��Դkey��ֵ�Ḳ��Ŀ��key��ֵ��
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "v1"
5) "k2"
6) "k4"
7) "myset:__rand_int__"
8) "counter:__rand_int__"
9) "key:__rand_int__"
10) "k1"
11) "k5"
127.0.0.1:6379> rename k1 k111
OK
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "v1"
5) "k2"
6) "k4"
7) "k111"
8) "myset:__rand_int__"
9) "counter:__rand_int__"
10) "key:__rand_int__"
11) "k5"
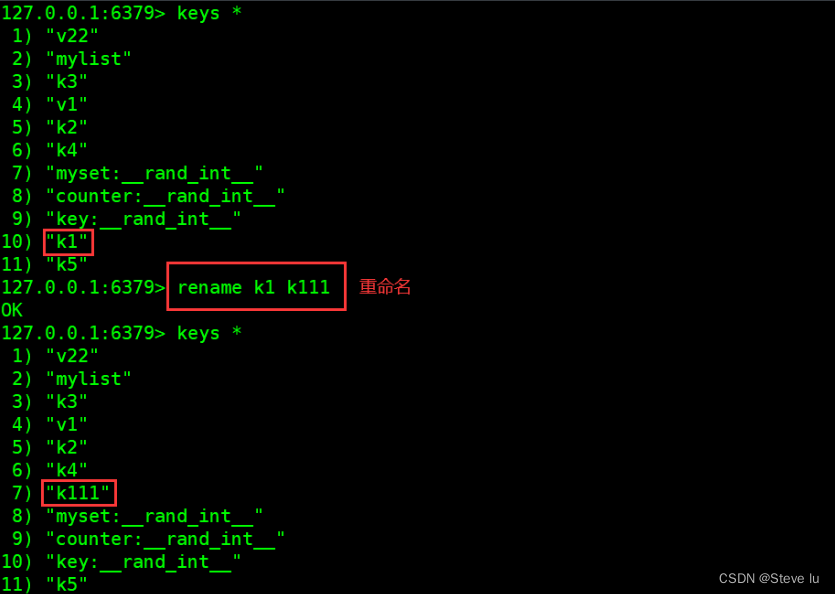
4.6 renamenx
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "v1"
5) "k2"
6) "k4"
7) "k111"
8) "myset:__rand_int__"
9) "counter:__rand_int__"
10) "key:__rand_int__"
11) "k5"
127.0.0.1:6379> renamenx k2 k222
(integer) 1
127.0.0.1:6379> renamenx k222 k3
(integer) 0
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "k222"
5) "v1"
6) "k4"
7) "k111"
8) "myset:__rand_int__"
9) "counter:__rand_int__"
10) "key:__rand_int__"
11) "k5"
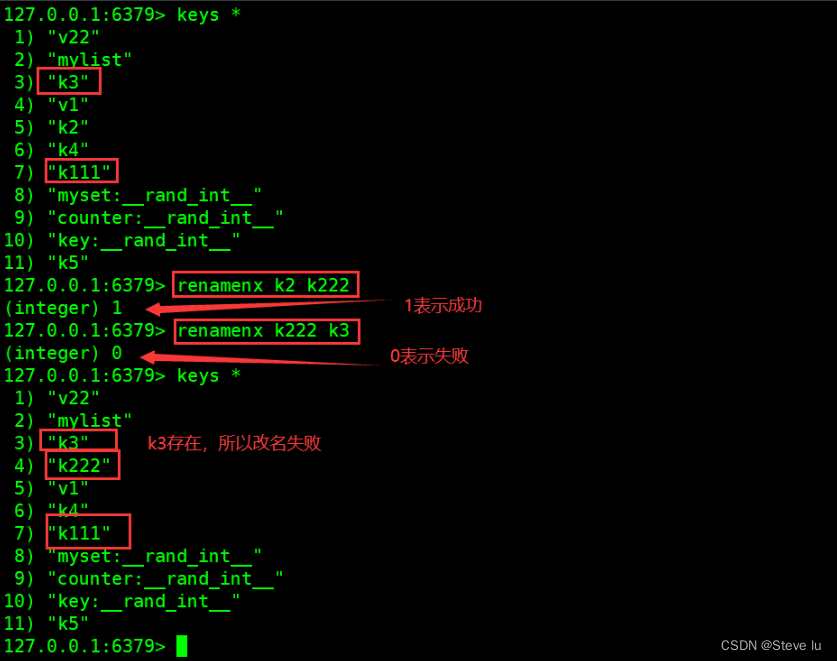
4.7 dbsize�鿴key��Ŀ
127.0.0.1:6379> dbsize
(integer) 11
127.0.0.1:6379>
#һ��11����

4.8 type�鿴��������
127.0.0.1:6379> type k111
string
127.0.0.1:6379> get k111
"1"
127.0.0.1:6379>

4.9 ��������
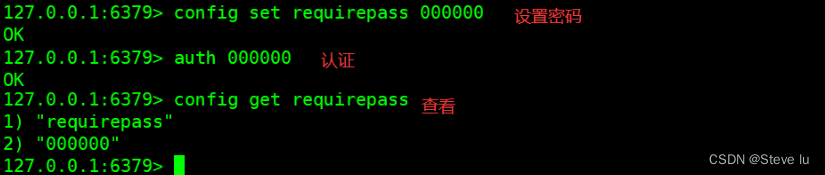
#��������
config set requirepass 000000
#auth��֤
auth 000000
#�鿴����
config get requirepass
#ɾ������
config set requirepass ''
�塢�����ݿⳣ������
Redis ֧�ֶ����ݿ�,RedisĬ������°���16�����ݿ�,���ݿ�������������0-15�����������ġ�
�����ݿ������,�������š�
#�����ݿ���л�
�����ʽ:select ���
ʹ��redis-cli����Redis���ݿ��,Ĭ��ʹ�õ������Ϊ0�����ݿ�.
127.0.0.1:6379>select 10 #�л������Ϊ10�����ݿ�
127.0.0.1:6379[10]>select 15 #�л������Ϊ15�����ݿ�
127.0.0.1:6379[15]>select 0 #�л������Ϊ0�����ݿ�

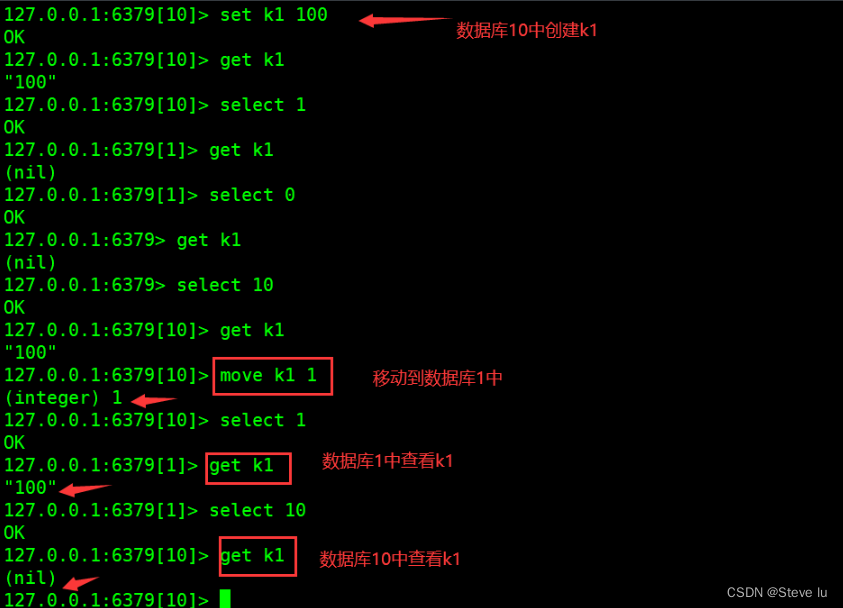
#�����ݿ���ƶ�����
��ʽ:move��ֵ���
127.0.0.1:6379[10]> set k1 100 #����k1��Ϊ100
OK
127.0.0.1:6379[10]> get k1 #�鿴k1��
"100"
127.0.0.1:6379[10]> select 1 #�л����ݿ�1
OK
127.0.0.1:6379[1]> get k1 #��ʱû��k1
(nil)
127.0.0.1:6379> select 10 #�л������ݿ�10
OK
127.0.0.1:6379[10]> move k1 1 ##�����ݿ�10��k1�ƶ������ݿ�1��
(integer) 1
127.0.0.1:6379[10]> select 1 #�л������ݿ�1
OK
127.0.0.1:6379[1]> get k1 #�鿴���ݿ�1�е�k1
"100"
127.0.0.1:6379[1]> select 10 #�л����ݿ�10
OK
127.0.0.1:6379[10]> get k1 #�鿴��1,��ʱ���ݿ�10��û����
(nil)
#������ݿ�������
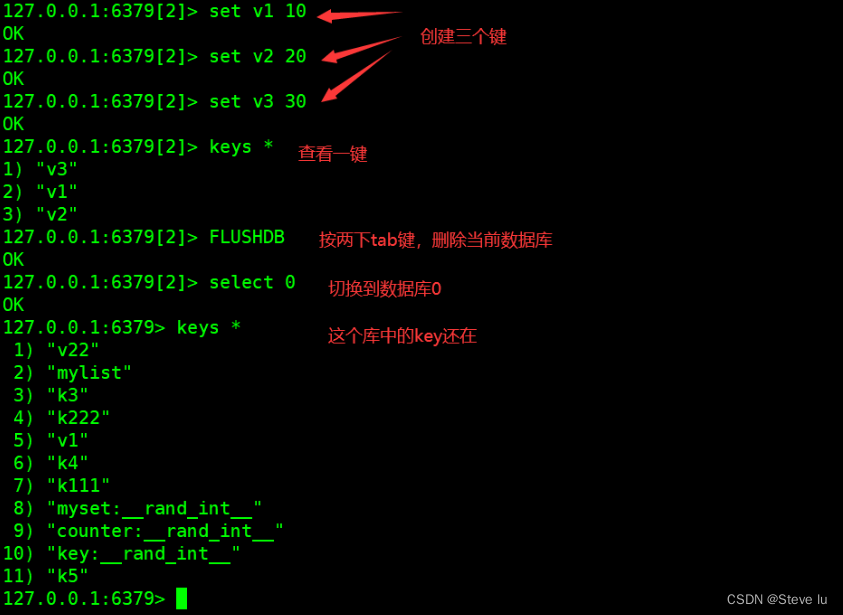
FLUSHDB:��յ�ǰ���ݿ�����
FLUSHALL:����������ݿ������,����!
127.0.0.1:6379[2]> set v1 10
OK
127.0.0.1:6379[2]> set v2 20
OK
127.0.0.1:6379[2]> set v3 30
OK
127.0.0.1:6379[2]> keys *
1) "v3"
2) "v1"
3) "v2"
127.0.0.1:6379[2]> FLUSHDB
OK
127.0.0.1:6379[2]> select 0
OK
127.0.0.1:6379> keys *
1) "v22"
2) "mylist"
3) "k3"
4) "k222"
5) "v1"
6) "k4"
7) "k111"
8) "myset:__rand_int__"
9) "counter:__rand_int__"
10) "key:__rand_int__"
11) "k5"
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> select 10
OK
127.0.0.1:6379[10]> keys *
(empty list or set)
127.0.0.1:6379[10]>

����Redis������
6.1 Redis����������
- ʹ��keys*�ѿ����,������ʹ�ñ���������������
- �����ڴ�ʹ�ú�,�������ݱ�ɾ�����������ɾ�����Ե�,ѡ���ʺ��Լ��ļ���
- û���־û�,ȴ������ʵ��,����ȫ�������ǵ÷ǻ������Ϣ��Ҫ�־û�
- RDB�ij־û���ҪVm.overcommit_memory=1,�����־û�ʧ��
- û�г־û������,����,������̫��,�ӻ�û��Ϊ���ҵ������,�ӻ�����Լ�������,��Ϊ�������ڵ�ǰ,�ȹرմӽڵ��ͬ��
6.2 Redis�����Ų�
- ���Redis ��ز鿴QPS�����������ʡ��ڴ�ʹ���ʵ���Ϣ
- ȷ�ϻ����������Դ�Ƿ����쳣
- ����ʱ��ʱ�ϻ�,ʹ��redis-cli monitor ��ӡ��������־,Ȼ�����(�º��������ʧЧ)
- ���з���ͨ,ȷ���Ƿ��д�Key�ڶ���(��KeyҲ�������ճ���Ѳ���л��)
- ������ͬ�¹�ͨ,ȷʵ�Ƿ��������
- ����άͬ�¡��з�һ���Ų������Ƿ�����,�Ƿ���ڱ�ˢ�����
�ܽ�
1.�����Ĺ�ϵ�����ݿ�?
oracle��MySQL��SQL Server��Microsoft Access��DB2��PostgreSQL
2.�����ķǹ�ϵ�����ݿ�?
Redis��MongBD��Hbase��Memcached��ElasticSearch(�������ݿ�)��TSDB(���������ݿ�)
3.ʲô��Redis?
Redis(Զ���ֵ������)��һ����Դ�ġ�ʹ��c���Ա�д��NosQL���ݿ�;Redis �����ڴ����в�֧�ֳ־û�,����key-value(��ֵ��)�Ĵ洢��ʽ,��Ŀǰ�ֲ�ʽ�ܹ��в��ɻ��һ��.
4.Ϊʲô��ҪRedis?
Redis ����������ʵʱ��Ҫ��ߡ����ݴ洢�й��ں���̭�����ġ�����Ҫ�־û�����ֻ��Ҫ��֤��һ���ԡ����ij���
5.Redis������ܲ���?
ʹ��redis-benchmark���Թ���
6.RedisĬ����������:string