Kafka ������ �� Kafka �������� kafka����
Kafka ������
1 ��������
1.1��������ԭ��
1.�����ڼ�Ⱥ����չ,��߸�������,ÿ�� Partition ����ͨ����������Ӧ�����ڵĻ���,��һ�� topic�ֿ����ж�� Partition ���,���������Ⱥ�Ϳ�����Ӧ�����С��������;
2.������߲�����д,��Ϊ������ Partition Ϊ��λ��д�ˡ�(���뵽ConcurrentHashMap�ڸ߲��������¶�дЧ�ʱ�HashTable�ĸ�Ч)
1.2��������ԭ��*��
������Ҫ�� producer ���͵����ݷ�װ��һ�� ProducerRecord ����

1.ָ�� partition �������,ֱ�ӽ�ָ����ֱֵ����Ϊ partiton ֵ;
2.û��ָ�� partition ֵ���� key �������,�� key �� hash ֵ�� topic �� partition ������ȡ��õ� partition ֵ;
3.��û�� partition ֵ��û�� key ֵ�������,��һ�ε���ʱ�������һ������(����ÿ�ε������������������),�����ֵ�� topic ���õ� partition ����ȡ��õ� partitionֵ,Ҳ���dz�˵�� round-robin �㷨��
2 ���ݿɿ��Ա�֤(���������͵�����)��*��
Ϊ��֤ producer ���͵�����,�ܿɿ��ķ��͵�ָ���� topic, topic ��ÿ�� partition �յ�producer ���͵����ݺ�,����Ҫ�� producer ���� ack(acknowledgement: ȷ���յ�),���producer �յ� ack, �ͻ������һ�ֵķ���,�������·������ݡ�
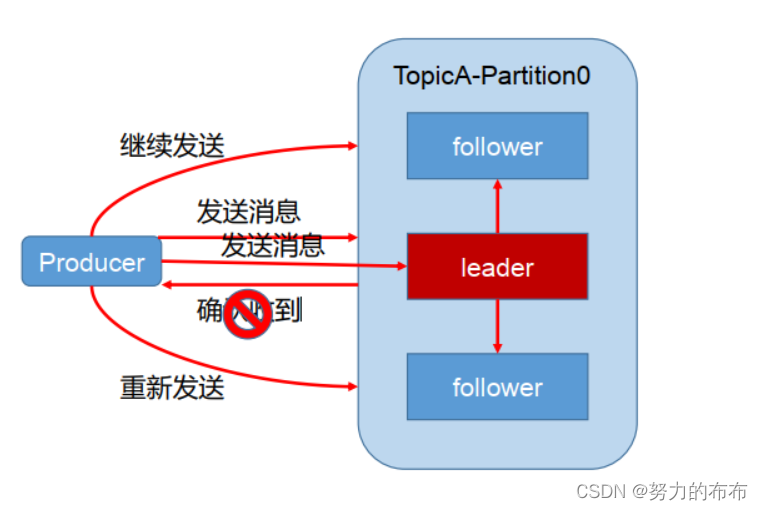
��ʱ����ack?
ȷ����follower��leaderͬ�����,leader�ٷ���ack,�������ܱ�֤leader�ҵ�֮��,����follower��ѡ�ٳ��µ�leader��
���ٸ�followerͬ�����֮����ack? �������ַ���:
1.�������ϵ�followerͬ�����,���ɷ���ack�����������·���
2.ȫ����followerͬ�����,�ſ��Է���ack
2.1����������ͬ������
�ⲽ������Ҫ����������follower��leader������������Ե�Լ��,����õڶ���,��������ȫ��һ��,ֻҪ��һ̨���С���һ�־�Ҫ��ѭ����+1��ԭ��
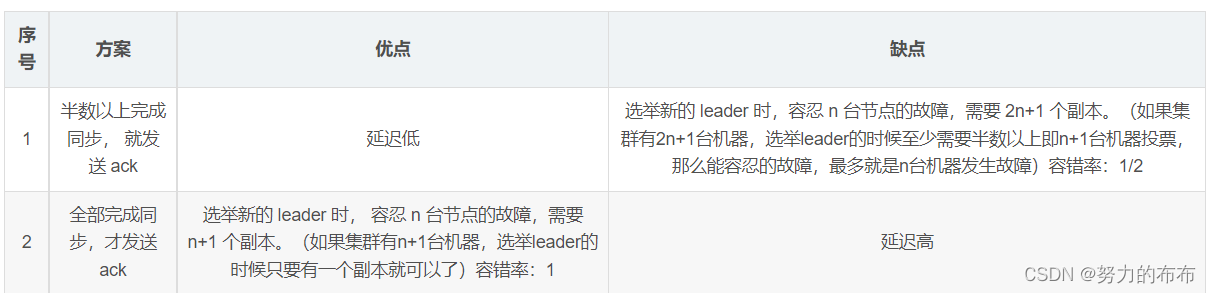
Kafka ѡ���˵ڶ��ַ���,ԭ������:
1.ͬ��Ϊ������ n ̨�ڵ�Ĺ���,��һ�ַ�����Ҫ 2n+1 ������,���ڶ��ַ���ֻ��Ҫ n+1 ������,�� Kafka ��ÿ���������д���������, ��һ�ַ�������ɴ������ݵ����ࡣ
2.��Ȼ�ڶ��ַ����������ӳٻ�Ƚϸ�,�������ӳٶ� Kafka ��Ӱ���С��
2.2��ISR
���õڶ��ַ���֮��,���������龰: leader �յ�����,���� follower ����ʼͬ������,����һ�� follower,��Ϊij�ֹ���,�ٳٲ����� leader ����ͬ��,�� leader ��Ҫһֱ����ȥ,ֱ�������ͬ��,���ܷ��� ack�����������ô�����?
Leader ά����һ����̬�� in-sync replica set (ISR:ͬ������),��Ϊ�� leader ����ͬ���� follower ���ϡ��� ISR �е� follower ������ݵ�ͬ��֮��,leader �ͻ�� producer ���� ack����� follower��ʱ��δ��leaderͬ������,��� follower �����߳� ISR,��ʱ����ֵ��replica.lag.time.max.ms�����趨�� Leader ��������֮��,�ͻ�� ISR ��ѡ���µ� leader��
��0.9�汾�н�����һ������ISR������ȥ���ˡ���������� replica.lag.max.messages
leader�е�������follower�е����� �IJ�ࡣ(�������ߵIJ����10��֮��,�ͼ���ISR)
ȥ����ԭ����:��������������ٽ�ֵ��10��,kafka�Ƿ����ε���������,�������ʱ,һ�������ڵ������кܶ�,����ISR�����е�follower�����߳���ISR,���Ǻܿ�,����������follower�ֻᱻ���뵽ISR��, ���ISR�IJ���̫��Ƶ��(ISR��ά�����ڴ���),���һ���Ƶ���IJ���zookeeper(kafka ����Ϣ�Ǵ����zookeeper���,����zookeeper��Ҳ�������ISR��)
replica.lag.time.max.ms
DESCRIPTION: If a follower hasn��t sent any fetch requests or hasn��t consumed up to the leaders log end offset for at least this time, the leader will remove the follower from isr
TYPE: long
DEFAULT: 10000
Source
2.3��ack Ӧ�����(���ݶ�ʧ�������ظ�)
����ijЩ��̫��Ҫ������,�����ݵĿɿ���Ҫ���Ǻܸ�,�ܹ��������ݵ�������ʧ,����û��Ҫ�� ISR �е� follower ȫ�����ճɹ���
���� Kafka Ϊ�û��ṩ�����ֿɿ��Լ���,�û����ݶԿɿ��Ժ��ӳٵ�Ҫ�����Ȩ��,ѡ�����µ����á�
acks ��������:
- 0: producer ���ȴ� broker(����˵��leader)�� ack,��һ�����ṩ��һ����͵��ӳ�, broker һ���յ���û��д����̵����ݾ��Ѿ�����,�� broker ����ʱ�п��ܶ�ʧ����;
leader�ս��յ�����Ϣ����,�ͷ���ACK,���ʱ�����leader崻�,��Ϣ��û����,����producer�յ���ack��Ϊ���������ͻᷢ����һ����Ϣ,�Ӷ��������ݶ�ʧ
- 1: producer �ȴ� broker �� ack, partition �� leader ���̳ɹ��� ack,����� followerͬ���ɹ�֮ǰ leader ����,��ô���ᶪʧ����;
leader�����̳ɹ��ͷ���ACK,�����ʱ��follower��û���ü�ͬ��,leader崻���,�ӻ��ͻᶪʧ����,��Ȼ�������������´�ѡ�ٴӴӻ�ѡ�ͻᶪ
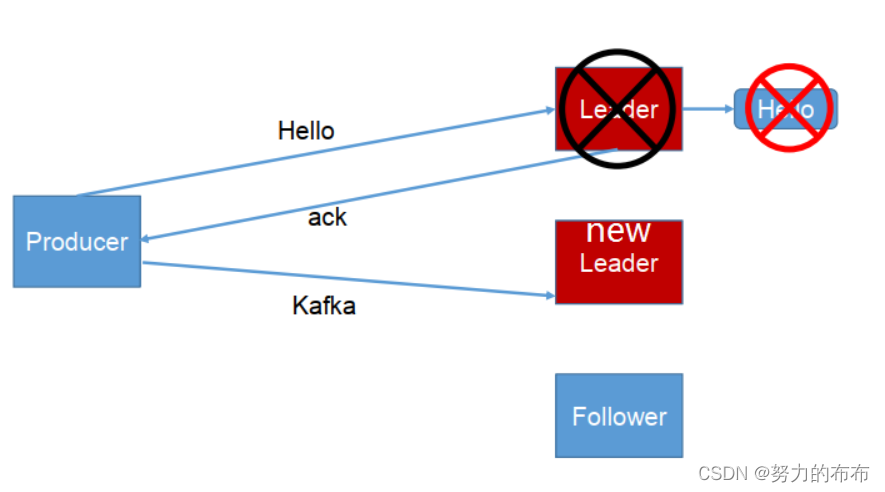
- -1(all) : producer �ȴ� broker �� ack, partition �� leader �� ISR ���follower ȫ�����̳ɹ���ŷ��� ack����������� follower ͬ����ɺ�, broker ���� ack ֮ǰ, leader ��������,��ô����������ظ���(����ISR��û��follower,�ͱ���� ack=1 �����)
����ȫ��������ACK,��������ȫ������,ack����֮ǰleader����,�ͻ��ٷ�һ����Ϣ��leader,�ͻ������ظ��ˡ����û�дӻ�,ֻ������,-1��ʱ������������̳ɹ��ͷ���ACK,�ͺ�1һ����,leader�����̳ɹ��ͷ���ACK,�����Ǵӻ�
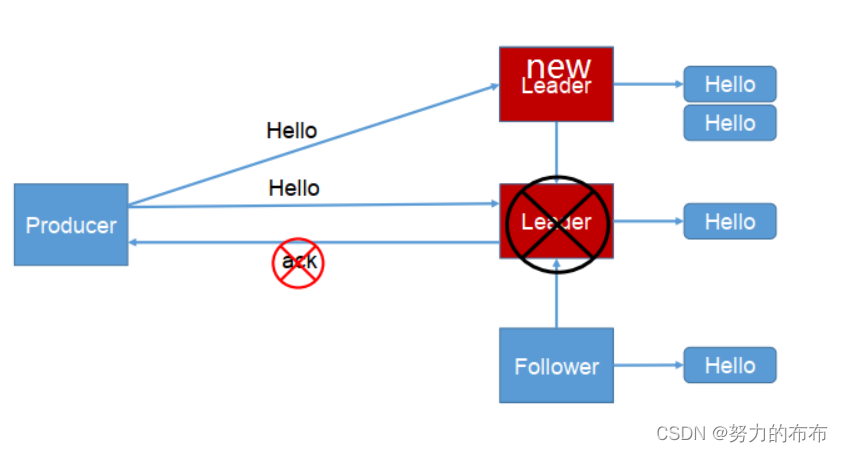
����:��ACKǰ,0������,1һ����,-1ȫ����,(����:��Ϣ�浽����)
2.4 Exactly Once ���� ��������ظ���������
���������� ACK ��������Ϊ-1(all),���Ա�֤ Producer �� Server ֮�䲻�ᶪʧ����,�� At Least Once ���塣��Ե�,�������� ACK ��������Ϊ 0,���Ա�֤������ÿ����Ϣֻ�ᱻ����һ��,�� At Most Once ���塣
At Least Once ���Ա�֤���ݲ���ʧ,���Dz��ܱ�֤���ݲ��ظ�;
��Ե�, At Most Once���Ա�֤���ݲ��ظ�,���Dz��ܱ�֤���ݲ���ʧ��
����,����һЩ�dz���Ҫ����Ϣ,����˵��������,��������������Ҫ�����ݼȲ��ظ�Ҳ����ʧ,�� Exactly Once ���塣
At Least Once ���ٷ���һ��,�϶�����ʧ,���ǿ����ظ�;At Most Once ����һ��,���ظ�,���ܻᶪʧ;
At least once��Messages are never lost but may be redelivered.
At most once��Messages may be lost but are never redelivered.
Exactly once��this is what people actually want, each message is delivered once and only once.
Source
�� 0.11 �汾��ǰ�� Kafka,�Դ�������Ϊ����,ֻ�ܱ�֤���ݲ���ʧ,�������������߶�������ȫ��ȥ�ء����ڶ������Ӧ�õ����,ÿ������Ҫ������ȫ��ȥ��,��Ͷ���������˺ܴ�Ӱ�졣
0.11 �汾�� Kafka,������һ���ش�����:�ݵ��ԡ���ν���ݵ��Ծ���ָ Producer ������ Server ���Ͷ��ٴ��ظ�����, Server �˶�ֻ��־û�һ�����ݵ��Խ�� At Least Once ����,������ Kafka �� Exactly Once ��������:
At Least Once + �ݵ��� = Exactly Once
Ҫ�����ݵ���,ֻ��Ҫ�� Producer �IJ����� enable.idempotence ����Ϊ true ����(��ʱ ack= -1)�� Kafka���ݵ���ʵ����ʵ���ǽ�ԭ��������Ҫ����ȥ�ط������������Ρ�ԭ��:�����ݵ��Ե� Producer �ڳ�ʼ����ʱ��ᱻ����һ�� PID,����ͬһ Partition ����Ϣ�ḽ�� Sequence Number����Broker �˻��<PID, Partition, SeqNumber>������,��������ͬ��������Ϣ�ύʱ, Broker ֻ��־û�һ����
���� PID �����ͻ�仯,ͬʱ��ͬ�� Partition Ҳ���в�ͬ����,�����ݵ�������֤���������Ự�� Exactly Once��(Ҳ����˵��ֻ������λỰ���������������Ϣ�ظ�����)
3�����ϴ���ϸ��(����һ����)
follower �� leader ����������,��������
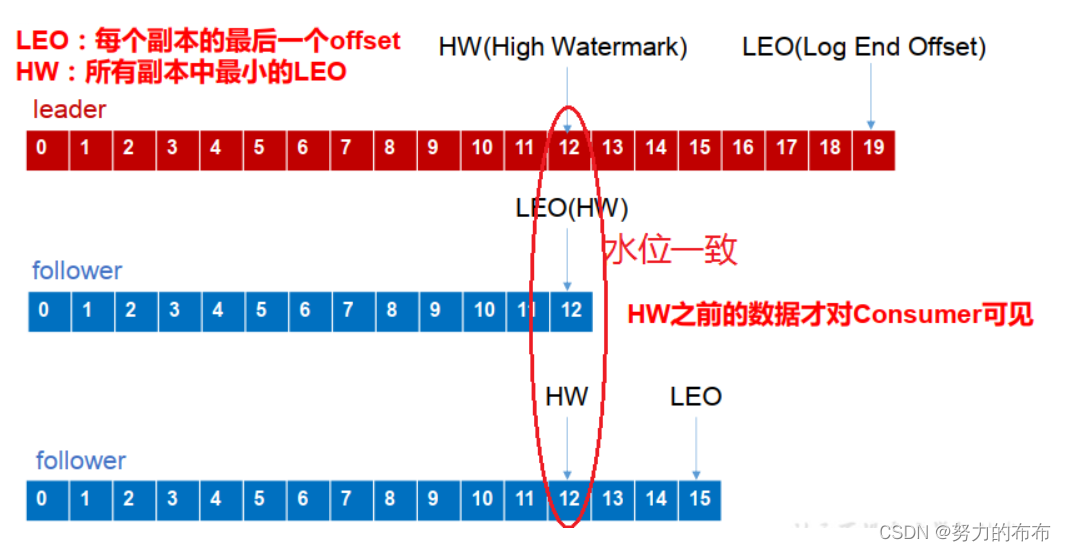
LEO:(Log End Offset)ÿ�����������һ��offset;
HW:(High Watermark)��ˮλ,ָ�����������ܼ��������� offset, ISR ��������С�� LEO;
follower ���Ϻ� leader ����:
- follower ����:follower �������Ϻ�ᱻ��ʱ�߳� ISR,���� follower �ָ���, follower ���ȡ���ش��̼�¼���ϴε� HW,���� log �ļ����� HW �IJ��ֽ�ȡ��,�� HW ��ʼ�� leader ����ͬ�����ȸ� follower �� LEO ���ڵ��ڸ� Partition �� HW,�� follower �� leader ֮��,�Ϳ������¼��� ISR �ˡ�
- leader ����:leader ��������֮��,��� ISR ��ѡ��һ���µ� leader,֮��,Ϊ��֤�������֮�������һ����, ����� follower ���Ƚ����Ե� log �ļ����� HW �IJ��ֽص�,Ȼ����µ� leaderͬ�����ݡ�
ע��: ��ֻ�ܱ�֤����֮�������һ����,�����ܱ�֤���ݲ���ʧ���߲��ظ���ack�Ǹ������ݶ�ʧ��
Kafka ������
1.1Kafka���ѷ�ʽ
consumer ���� pull(��) ģʽ�� broker �ж�ȡ���ݡ�
push(��)ģʽ������Ӧ�������ʲ�ͬ��������,��Ϊ��Ϣ������������ broker ������������Ŀ���Ǿ�����������ٶȴ�����Ϣ,����������������� consumer ������������Ϣ,���͵ı��־��Ǿܾ������Լ�����ӵ������ pull ģʽ����Ը��� consumer �������������ʵ�������������Ϣ��
pull ģʽ����֮����,��� kafka û������,�����߿��ܻ�����ѭ����, һֱ���ؿ����ݡ� �����һ��, Kafka ������������������ʱ�ᴫ��һ��ʱ������ timeout,�����ǰû�����ݿɹ�����, consumer ��ȴ�һ��ʱ��֮���ٷ���,���ʱ����Ϊ timeout��
1.2����������ķ����������
һ�� consumer group ���ж�� consumer,һ�� topic �ж�� partition,���Ա�Ȼ���漰�� partition �ķ�������,��ȷ���Ǹ� partition ���ĸ� consumer �����ѡ�
Kafka �����ַ������:(ĿǰӦ��������,����ɲο�:�ܽ�:kafka�����ߺ������ߵķ����������)
-
round-robinѭ�� (��ѯ)
-
range (��Χ)
1.2.1�� Round Robin (��ѯ)
Round Robin (��ѯ)���������һ����������,���������ֵġ�
����Roudn Robin�ط������,����Ҫ���õ���һ����ѯ�ķ�ʽ�������еķ���,�ò�����Ҫʵ�ֵIJ�������:�����������ȼ���������topic:t0��t1��t2,������topicӵ�еķ������ֱ�Ϊ1��2��3,��ô�ܹ�����������,�����������ֱ�Ϊ:t0-0��t1-0��t1-1��t2-0��t2-1��t2-2�������������������consumer:C0��C1��C2,���Ƕ������Ϊ:C0����t0,C1����t0��t1,C2����t0��t1��t2����ô��Щ�����ķ��䲽������: -
���Ƚ����е�partition��consumer�����ֵ����������,��ν���ֵ���,���ǰ��������Ƶ��ַ���˳��,��ô�������������������consumer����֮��ֱ�Ϊ:
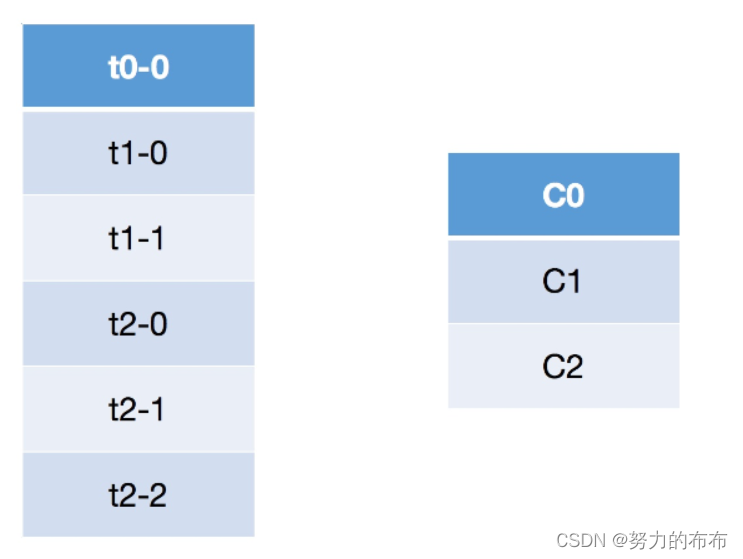
-
Ȼ��������˳����ѯ�ķ�ʽ���������������������consumer,�����ǰconsumerû�ж��ĵ�ǰ�������ڵ�topic,����ѯ���ж���һ��consumer:
-
���Խ�t0-0�����C0,����C0������t0,������Է���ɹ�;
-
���Խ�t1-0�����C1,����C1������t1,������Է���ɹ�;
-
���Խ�t1-1�����C2,����C2������t1,������Է���ɹ�;
-
���Խ�t2-0�����C0,����C0û�ж���t2,�������ѯ��һ��consumer;
-
���Խ�t2-0�����C1,����C1û�ж���t2,�������ѯ��һ��consumer;
-
���Խ�t2-0�����C2,����C2������t2,������Է���ɹ�;
-
ͬ������t2-1��t2-2���ڵ�topic��û�б�C0��C1������,������������ɹ�,���ն��� �����C2��
-
���������IJ��轫���еķ������������֮��,���շ����Ķ����������:
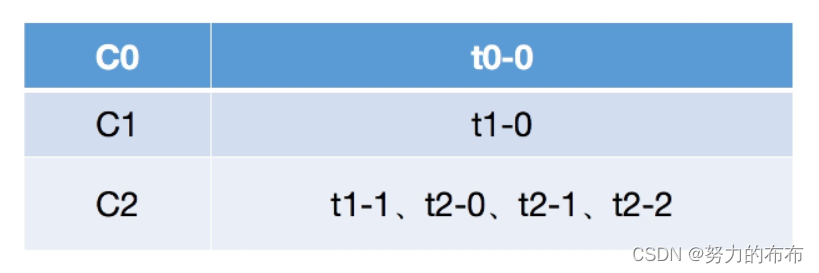
������IJ���������Կ���,��ѯ�IJ��Ծ��ǼĽ����е�partition��consumer�����ֵ����������֮��,Ȼ�����ν�partition���������consumer,�����ǰ��consumerû�ж��ĵ�ǰ��partition,��ô�ͻ���ѯ��һ��consumer,ֱ�����ս����еķ�����������ϡ����Ǵ�����ķ��������Կ���,(ȱ��:)��ѯ�ķ�ʽ����������»ᵼ��ÿ��consumer�����صķ���������һ��,�Ӷ����¸���consumerѹ������һ��
1.2.2�� Range(kafkaĬ�ϵIJ���)
Range�����ǰ���topic���ν��з����(��Ե�������topic)��
��ν��Range�ط������,�������Ȼ�������consumer������صķ�������,Ȼ��ָ�������ķ����������consumer���������Ǽ���������consumer:C0��C1,����topic:t0��t1,������topic�ֱ�����������,��ô�ܹ��ķ���������:t0-0��t0-1��t0-2��t1-0��t1-1��t1-2����ôRange������Խ��ᰴ�����²�����з����ķ���:
- ��Ҫע�����,Range�����ǰ���topic���ν��з����(��Ե�������topic) ,����������t0���н���,�����Ȼ��ȡ t0 �����з���:t0-0��t0-1��t0-2,�Լ����ж����˸�topic��consumer:C0��C1,���һὫ��Щ������consumer�����ֵ����������;
- Ȼ����ƽ������ķ�ʽ����ÿ��consumer��õ����ٸ�����,���û�г���,��Ὣ������ķ������μ��㵽ǰ�漸��consumer��������������������������consumer,��ôÿ��consumer���ٻ�õ�1������,��3����2����1,��ô�ͻὫ����IJ��������㵽ǰ�漸��consumer,Ҳ���������1��������һ��consumer,�ܽ���˵,��ôC0����ӵ�0��������ʼ,����2������,��C1����ӵ�2��������ʼ,����1������;
- ͬ��,��������IJ������ν��к����topic�ķ��䡣
- �����������������ķ����������:
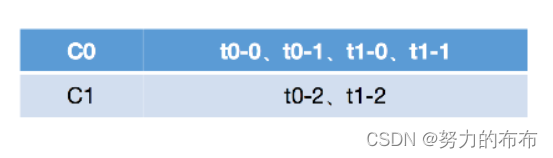
(ȱ��:)���Կ���,�������Range������ʽ���з���,�䱾���������α���ÿ��topic,Ȼ����Щtopic�ķ��������������ĵ�consumer��������ƽ���ķ�Χ���䡣���ַ�ʽ�Ӽ���ԭ���Ͼͻᵼ��������ǰ���consumer���䵽����ķ���,�Ӷ����¸���consumer��ѹ�������⡣
1.2.3����
����ʱ��:������������������߸��������仯ʱ,�ͻᴥ�����������ߵķ���������ԡ�
���һ���������������е������߶���������ͬ������(topic),��������ѯ��
���һ�����������ڵ������߶��ĵ�����(topic)��ͬ,������range��
����kafkaĬ�ϵķ�ʽ��:range��
ʵ����,����Ҫ�����������ѡ��
1.3 offset ����
���� consumer �����ѹ����п��ܻ���ֶϵ�崻��ȹ���, consumer �ָ���,��Ҫ�ӹ���ǰ��λ�õļ�������,���� consumer ��Ҫʵʱ��¼�Լ����ѵ����ĸ� offset,�Ա���ϻָ���������ѡ�(offset���� consumer group + topic + partition ȷ����)
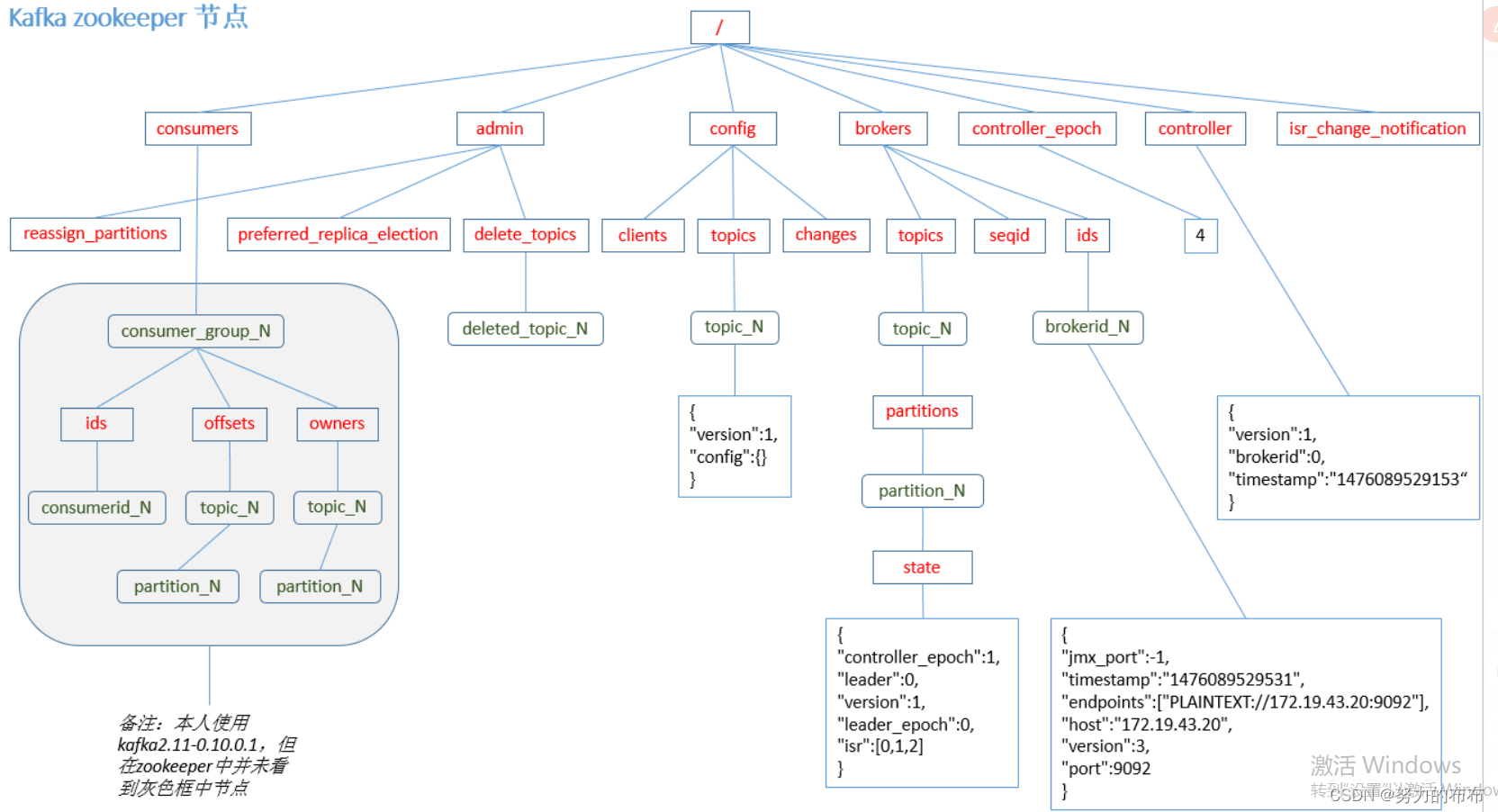
Kafka 0.9 �汾֮ǰ, consumer Ĭ�Ͻ� offset ������ Zookeeper ��;�� 0.9 �汾��ʼ,consumer Ĭ�Ͻ� offset ������ Kafka һ�����õ� topic ��,�� topic Ϊ__consumer_offsets��
1.�������ߵ������ļ� consumer.properties
#���������������� ϵͳ��topic,������
exclude.internal.topics=false
2.��ȡ offset
1.0.11.0.0 ֮ǰ�汾 :
bin/kafka-console-consumer.sh
�Ctopic __consumer_offsets
�Czookeeper hadoop102:2181
�Cformatter ��kafka.coordinator.GroupMetadataManager$OffsetsMessageFormatter��
�Cconsumer.config config/consumer.properties --from -beginning
2.0.11.0.0 ��֮��汾 :
#����
bin/kafka-console-consumer.sh
�Ctopic __consumer_offsets
�Czookeeper hadoop102:2181
�Cformatter ��kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter��
�Cconsumer.config config/consumer.properties --from-beginning
.
Kafka ����
Kafka �� 0.11 �汾��ʼ����������֧�֡�������Ա�֤ Kafka �� Exactly Once ����Ļ�����(Exactly Once ����ֻ�ܱ�֤���λỰ�����������е��ݵ���),���������ѿ��Կ�����ͻỰ,Ҫôȫ���ɹ�,Ҫôȫ��ʧ�ܡ�
1 Producer ����
Ϊ��ʵ�ֿ������Ự������,��Ҫ����һ��ȫ��Ψһ�� Transaction ID(���ID���ɿͻ��˸���),���� Producer ��õ�PID ��Transaction ID ��������Producer ������Ϳ���ͨ�����ڽ��е� TransactionID ���ԭ���� PID��
Ϊ�˹��� Transaction, Kafka ������һ���µ���� Transaction Coordinator�� Producer ����ͨ���� Transaction Coordinator ������� Transaction ID ��Ӧ������״̬�� Transaction Coordinator ��������������д�� Kafka ��һ���ڲ� Topic,������ʹ������������,��������״̬�õ�����,�����е�����״̬���Եõ��ָ�,�Ӷ��������С�
�����Ϳ��Ա�֤���������Ự���ݵ��ԡ������˽���Ϣ��һ����д��kafka��Ⱥ��
2 Consumer ����
�������������Ҫ�Ǵ� Producer ���濼��,���� Consumer ����,����ı�֤�ͻ���Խ���,����ʱ����֤ Commit ����Ϣ����ȷ���ѡ��������� Consumer ����ͨ�� offset ����������Ϣ,���Ҳ�ͬ�� Segment File �������ڲ�ͬ,ͬһ�������Ϣ���ܻ����������ɾ���������