1.Explain���߽���
ʹ��EXPLAIN�ؼ��ֿ���ģ���Ż���ִ��SQL���,������IJ�ѯ�����ǽṹ������ƿ����
�� select ���֮ǰ���� explain �ؼ���,MySQL ���ڲ�ѯ������һ�����,ִ�в�ѯ�᷵��ִ�мƻ�����Ϣ,������ִ������SQL��
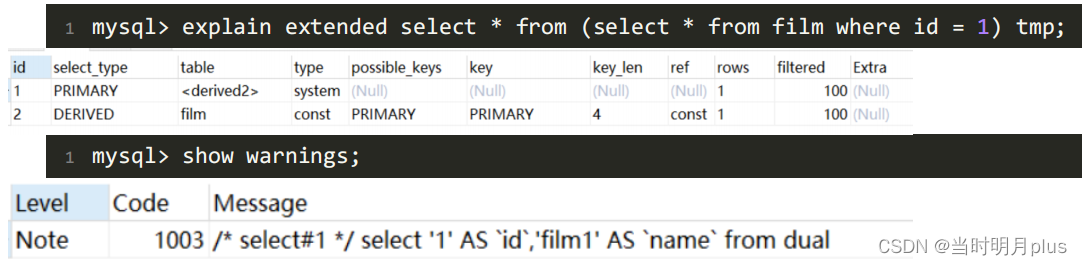
ע��:��� from �а����Ӳ�ѯ,�Ի�ִ�и��Ӳ�ѯ,�����������ʱ����
Explain�ٷ��ĵ�
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
2.ʾ���ű�
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `actor` (`id`, `name`, `update_time`) VALUES (1,'a','2017�\12�\22 15:27:18'), (2,'b','2017�\12�\22 15:27:18'), (3,'c','2017�\12�\22 15:27:18');
DROP TABLE IF EXISTS `film`;
CREATE TABLE `film` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `film` (`id`, `name`) VALUES (3,'film0'),(1,'film1'),(2,'film2');
DROP TABLE IF EXISTS `film_actor`;
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL,
`film_id` int(11) NOT NULL,
`actor_id` int(11) NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `film_actor` (`id`, `film_id`, `actor_id`) VALUES (1,1,1),(2,1,2),(3,2,1);mysql> explain select * from actor;

?�ڲ�ѯ�е�ÿ���������һ��,�����������ͨ�� join ���Ӳ�ѯ,��ô���������
3.explain ��������

4.explain���
4.1. id��
4.2. select_type��

2)primary:���Ӳ�ѯ�������� select

?

?
4.3. table��
4.4. type��(��Ҫ)
��һ�б�ʾ�������ͻ��������,��MySQL������β��ұ��е���,���������м�¼�Ĵ�ŷ�Χ��

?
2)const, system:mysql�ܶԲ�ѯ��ij���ֽ����Ż�������ת����һ������(���Կ�show warnings �Ľ��)��
����primary key �� unique key ���������볣���Ƚ�ʱ,���Ա������һ��ƥ����,��ȡ1��,�ٶȱȽϿ졣system��const������,����ֻ��һ��Ԫ��ƥ��ʱΪsystem
?

?

?2.��������ѯ,idx_film_actor_id��film_id��actor_id����������,����ʹ�õ���film_actor�����ǰfilm_id���֡�

5)range:��Χɨ��ͨ�������� in(), between ,> ,<, >= �Ȳ����С�ʹ��һ������������������Χ���С�



?

?
4.5. possible_keys��
4.6. key��
4.7. key_len��


4.8. ref��
4.9. rows��
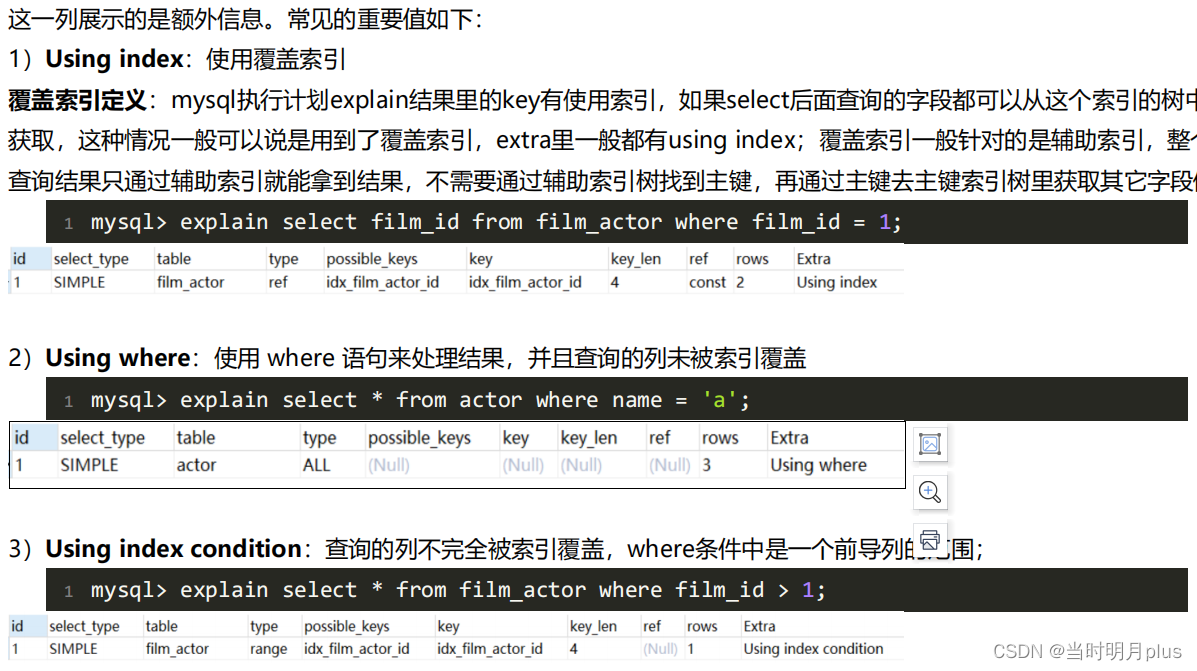
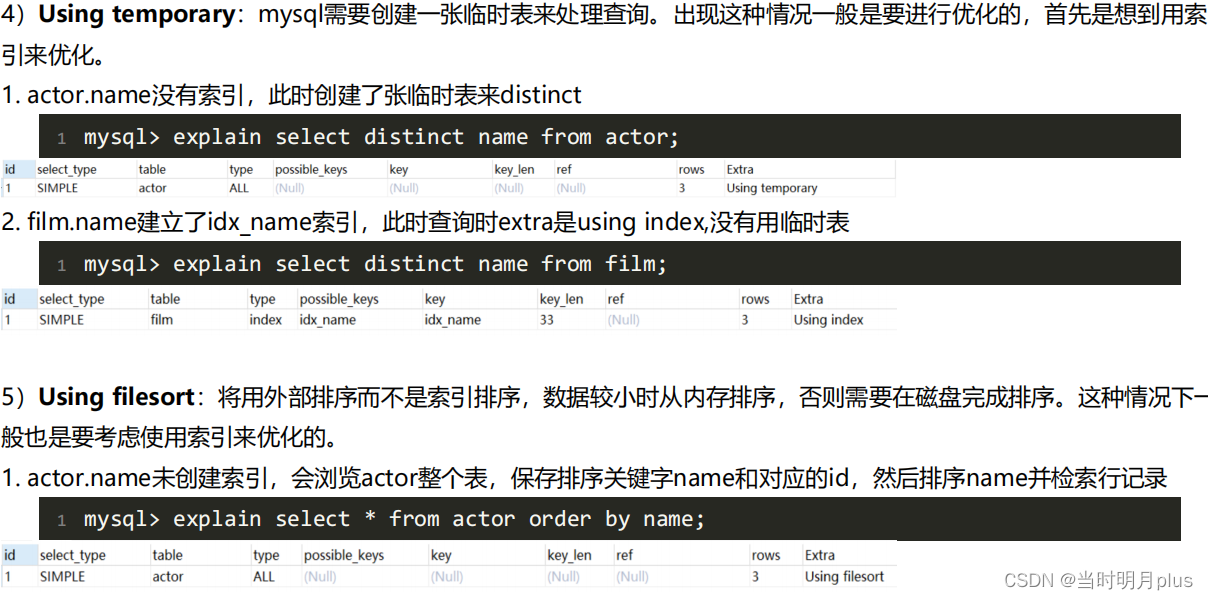
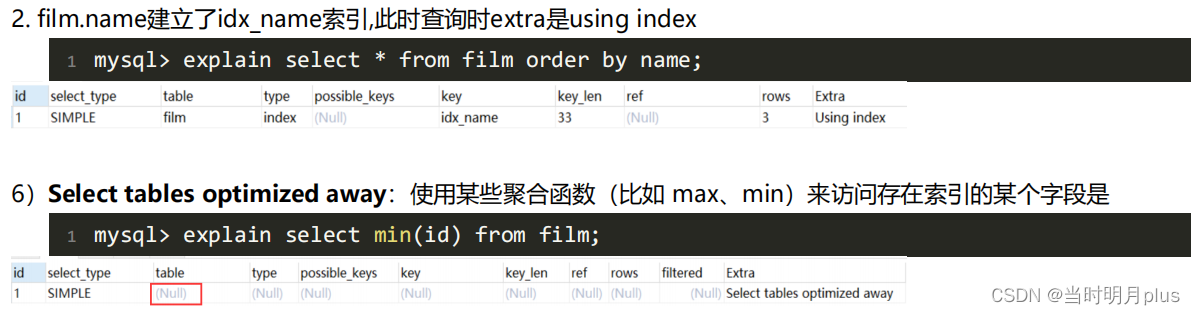
4.10. Extra��
 ?
?
 ?
?
5.�������ʵ��

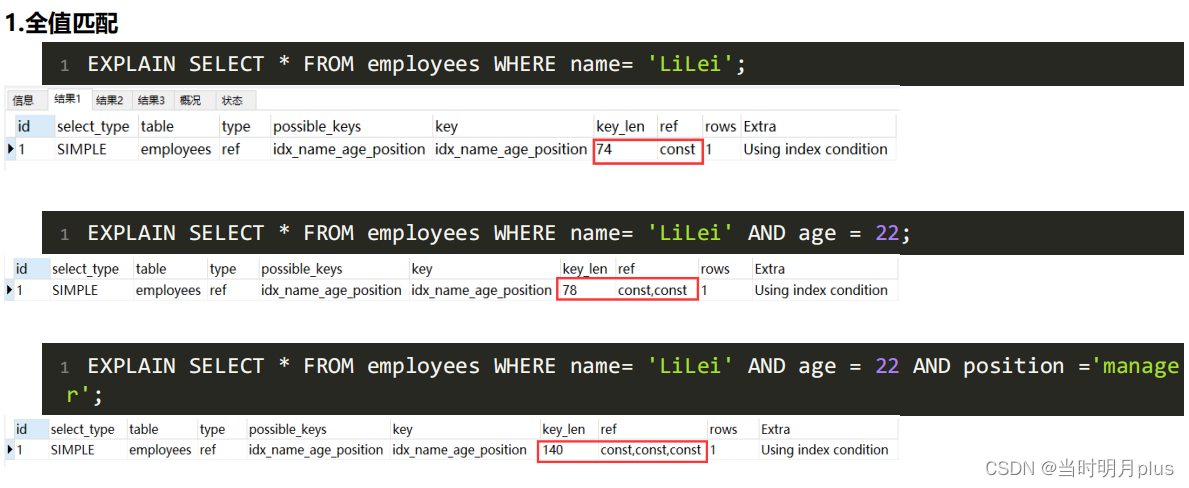 ?
?
 ?
?
 ?
?
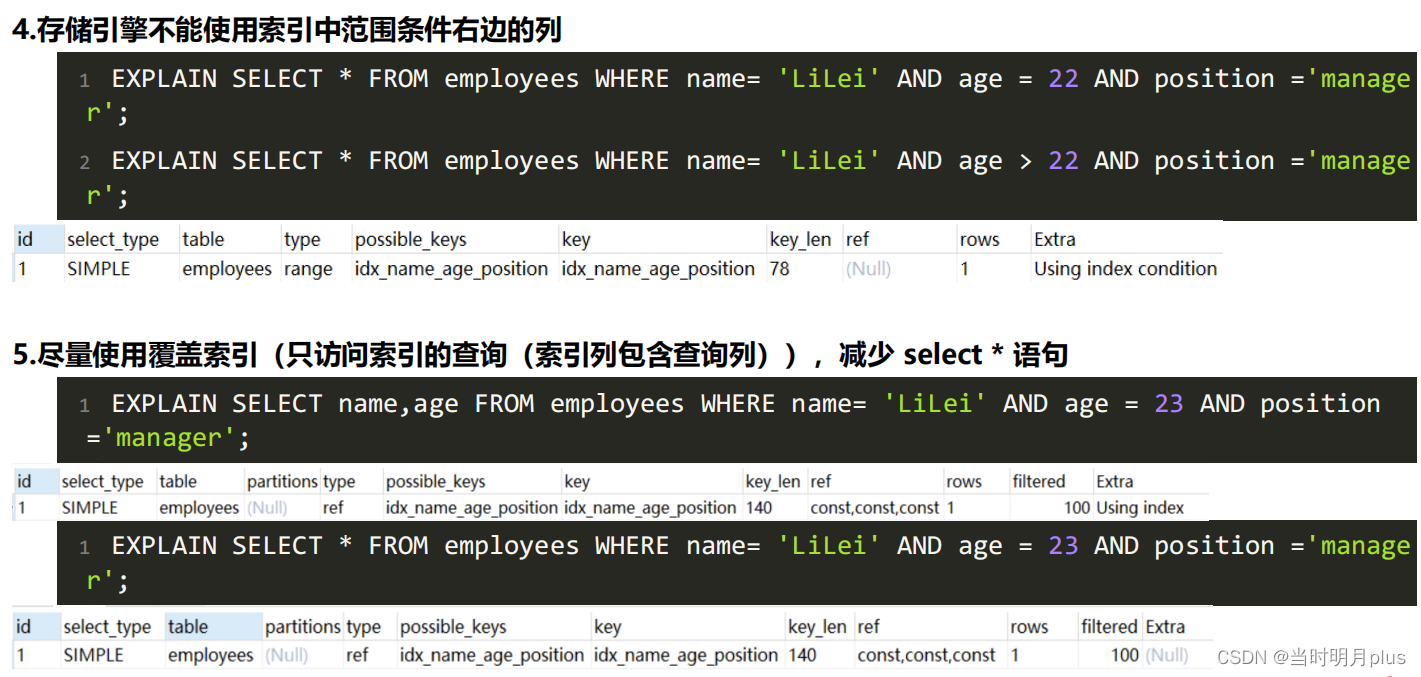 ?
?
 ?
?
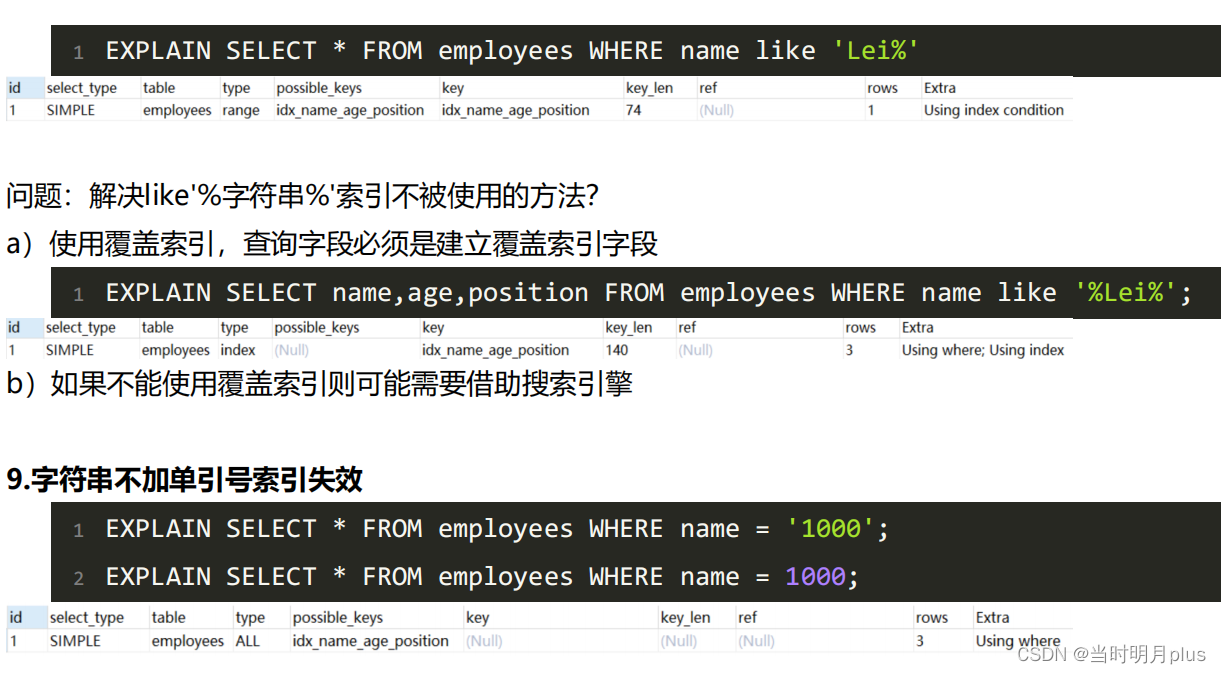 ?
?
 ?
?
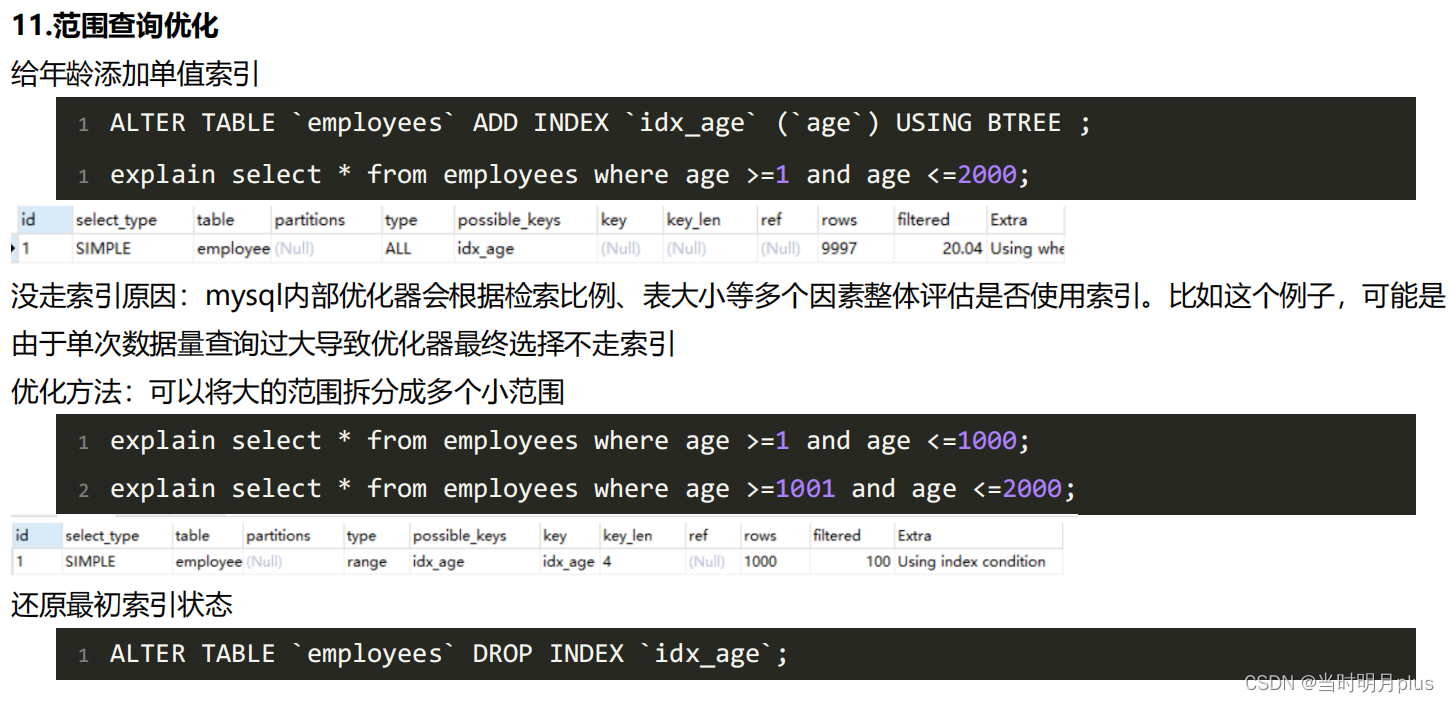 ?
?
����ʹ���ܽ�:
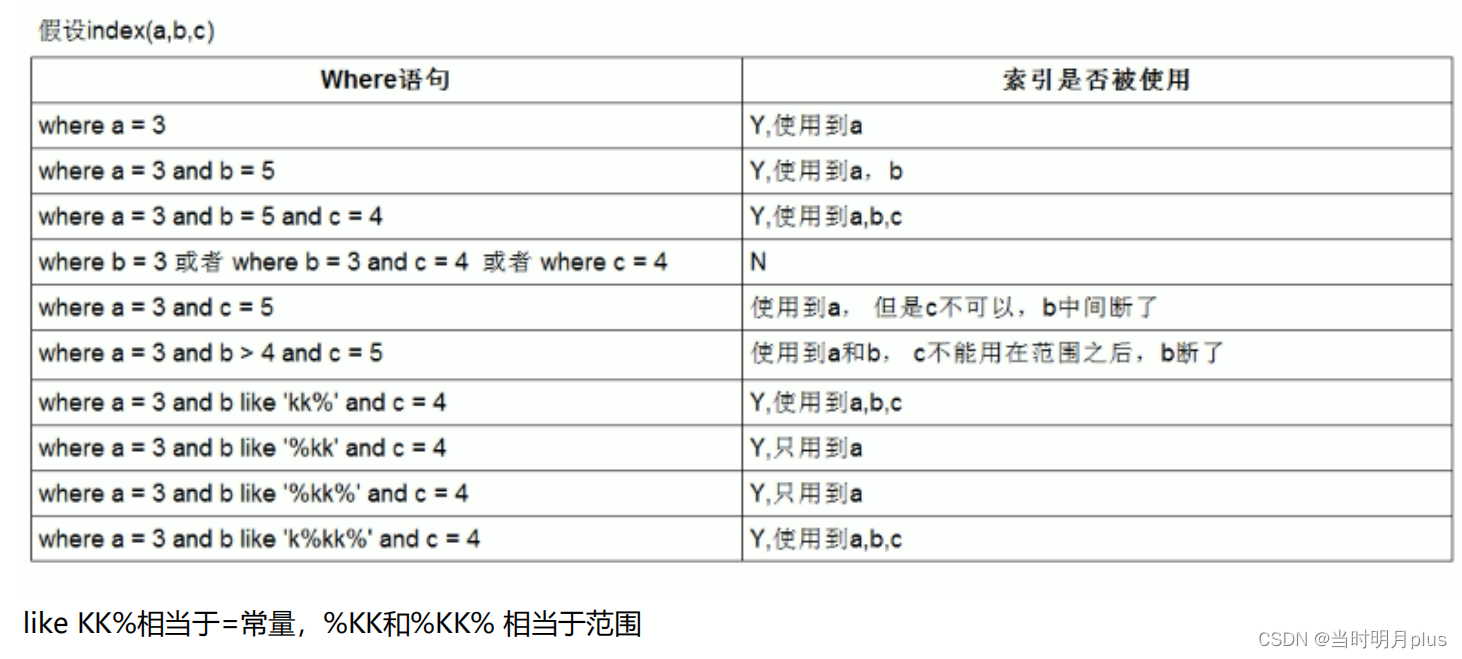 ?
?
?