Hadoop
1.Hadoop����
1.1 ʲô��Hadoop?
Hadoop����apache������������ķֲ�ʽϵͳ�����ܹ�,Hadoop��ʹ��Java��д,�����ֲ��ڼ�Ⱥ,ʹ�üı��ģ�͵ļ�����������ݼ�������Apache�Ŀ�Դ��ܡ� Hadoop���Ӧ�ù����ṩ��������Ⱥ�ķֲ�ʽ�洢�ͼ���Ļ����� Hadoop��רΪ�ӵ�һ����������ǧ̨������չ,ÿ�������������ṩ���ؼ���ʹ洢��
��������������˵Hadoop����һ����̬Ȧ,���Ǽ��ΪHadoop��̬Ȧ
1.2 Hadoop��չ��ʷ
- Hadoop��ʼ��Doug Cutting,Ϊ��ʵ�ָ�Google���Ƶ�ȫ����������,����Lucene��ܵĻ����Ͻ������Ż�����,��ѯ�������������,��Hadoop��ͼ�������Դ�������ӵ�С����ż��

-
2001�����Lucene��ΪApache������һ������Ŀ��
-
���ں������ݵij���,Lucene��������Googleͬ��������,����洢������������,���������ٶ�����(��ʱ�����о�������Щ������������Ļ��������ܷ�չ��ô��,�Դ��¾���Щ�������������)��

-
ѧϰ��ģ��Google�����Щ����ķ���:�Ͱ�Nutch
-
��ij����������˵,Google��Hadoop��˼��֮Դ
(������tor�ϲ���Google�ڴ����ݷ������ƪ����)
GFS�C>HDFS
Map-Reduce�C>MR
BigTable�C>HBase -
��2003-2004��,Google�����˲���GFS��MapReduce˼���ϸ��,�Դ�Ϊ����DougCutting��������2��ҵ��ʱ��ʵ����HDFS��MapReduce����,ʹNutch���ܹ�����
-
2005��Hadoop��ΪLucene������ĿNutch��һ������ʽ����Apache����ᡣ
-
2006�����·�,Map-Reduce��Nutch Distributed Fie Svstem(NDFS)�ֱ����뵽Hadoop��Ŀ,��,Hadoop�ʹ���ʽ����,��־�Ŵ�����ʱ�����١�
��������һ����ʷ�ԵĴ���,�о�����������i���������
1.3 Hadoop�������а汾
Hadoop�����а汾:Apache��Cloudera��Hortonworks��
Apache�汾��ԭʼ(�����)�İ汾,��������ѧϰ��á�2006
Cloudera�ڲ������˺ܶ�����ݿ��,��Ӧ��ƷCDH��2008
Hortonworks�ĵ��Ϻ�,��Ӧ��ƷHDP��2011
Hortonworks�����Ѿ���Cloudera��˾�չ�,�Ƴ��µ�Ʒ��CDP��

1)Apache Hadoop
������ַ:
http://hadoop.apache.org
���ص�ַ:
https://hadoop.apache.org/releases.html
2)Cloudera Hadoop
������ַ:
https://www.cloudera.com/downloads/cdh
���ص�ַ:
https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_6_download.html
(1)2008�������Cloudera�����罫Hadoop���õĹ�˾,Ϊ��������ṩHadoop�����ý������,��Ҫ�ǰ���֧�֡���ѯ������ѵ��
(2)2009��Hadoop�Ĵ�ʼ��Doug CuttingҲ����Cloudera��˾��Cloudera��Ʒ��ҪΪCDH,Cloudera Manager,Cloudera Support
(3)CDH��Cloudera��Hadoop���а�,��ȫ��Դ,��Apache Hadoop�ڼ�����,��ȫ��,�ȶ�����������ǿ��Cloudera�ı��Ϊÿ��ÿ���ڵ�10000��Ԫ��
(4)Cloudera Manager�Ǽ�Ⱥ�������ַ����������ƽ̨,�����ڼ���Сʱ�ڲ����һ��Hadoop��Ⱥ,���Լ�Ⱥ�Ľڵ㼰�������ʵʱ��ء�
3)Hortonworks Hadoop
������ַ:https://hortonworks.com/products/data-center/hdp/
���ص�ַ:https://hortonworks.com/downloads/#data-platform
(1)2011�������Hortonworks���Ż����ȷ�Ͷ��˾Benchmark Capital�����齨��
(2)��˾����֮���������˴�Լ25����30��ר���о�Hadoop���Ż�����ʦ,��������ʦ����2005�꿪ʼЭ���Ż�����Hadoop,������Hadoop80%�Ĵ��롣
(3)Hortonworks�������Ʒ��Hortonworks Data Platform(HDP),Ҳͬ����100%��Դ�IJ�Ʒ,HDP����������Ŀ�������Ambari,һ�Դ�İ�װ����ϵͳ��
(4)2018��HortonworksĿǰ�Ѿ���Cloudera��˾�չ���
1.4 Hadoop����ʲô������?
1.�߿ɿ���:Hadoop�ײ�ά���˶�����ݸ���,���Լ�ʹHadoop��Ⱥij���ڵ����Ԫ�ػ��ߴ洢�����˹���Ҳ���ᵼ�����ݶ�ʧ��

2.����չ��:��Hadoop��Ⱥ�������������,�ɷ������չ��ǧΪ��λ�Ľڵ㡣

3.��Ч��:��MapReduce��˼����,Hadoop�����Dz��й�����,�����ӿ�����Ĵ����ٶȡ�

4.���ݴ���:�ܹ��Զ���ʧ�ܵ��������·��䡣

1.5 Hadoop�����(�����ص�!!!)
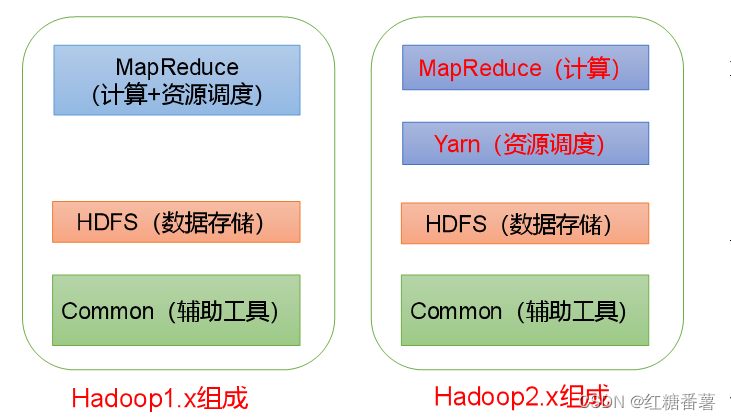
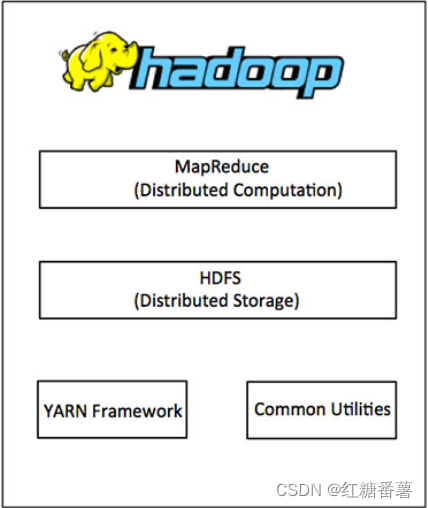
��Hadoop1.xʱ��, Hadoop�е�MapReduceͬʱ����ҵ�����������Դ�ĵ���,����Խϴ�
��Hadoop2xʱ��,������Yarn��Yarnֻ������Դ�ĵ���, MapReduceֻ�������㡣
Hadoop3.x�������û�б仯��
1.5.1 HDFS���
Hadoop�ļ�ϵͳʹ�÷ֲ�ʽ�ļ�ϵͳ��ƿ�����������������ͨӲ�������������ķֲ�ʽϵͳ,HDFS�Ǹ߶��ݴ��Լ�ʹ�õͳɱ���Ӳ����ơ�
HDFSӵ�г����͵�������,���ṩ�����ɵط��ʡ�Ϊ�˴洢��Щ�Ӵ������,��Щ�ļ����洢�ڶ�̨��������Щ�ļ����洢������ķ�ʽ������ϵͳ���ܿ��ܵ�������ʧ,�ڷ�������ʱ�� HDFSҲʹ�ÿ����ڲ��д�����Ӧ�ó���
(1)HDFS���ص�
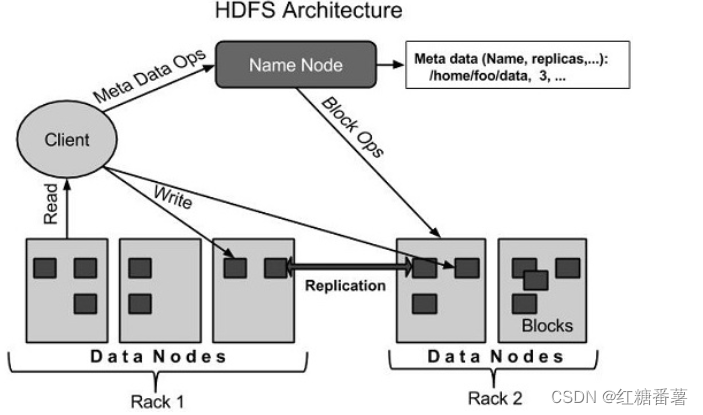
���������ڷֲ�ʽ�洢�ʹ�����
Hadoop�ṩ������ӿ���HDFS���н�����
���ƽڵ�����ݽڵ�İ����û����õķ������ܹ����ɵؼ�鼯Ⱥ��״̬��
��ʽ�����ļ�ϵͳ���ݡ�
HDFS�ṩ���ļ���Ȩ����֤��
(2)HDFS�ܹ�
HDFS��ѭ���Ӽܹ�,����������Ԫ�ء�
1)���ƽڵ� - Namenode
���ƽڵ��ǰ���GNU/Linux����ϵͳ���������ƽڵ����ͨӲ��������һ����������ƷӲ�������е��������������ƽڵ�ϵͳ��Ϊ��������,��ִ����������:
- �����ļ�ϵͳ�����ռ䡣 �淶�ͻ��˶��ļ��ķ��ʡ�
- ��Ҳִ���ļ�ϵͳ����,��������,�رպʹ��ļ���Ŀ¼��
2)���ݽڵ� - Datanode
Datanode����GNU/Linux����ϵͳ������Datanode����ͨӲ�������ڼ�Ⱥ�е�ÿ���ڵ�(��ͨӲ��/ϵͳ),��һ�����ݽڵ㡣��Щ�ڵ�������ݴ洢�����ǵ�ϵͳ��
���ݽڵ��ϵ��ļ�ϵͳִ�еĶ�д����,���ݿͻ�������
���������ƽڵ��ָ��ִ�в���,���Ĵ���,ɾ�����ơ�
3)��
һ���û����ݴ洢��HDFS�ļ�����һ���ļ�ϵͳ�е��ļ���������Ϊһ�������κ�/��洢�ڸ������ݵĽڵ㡣��Щ�ļ��α���Ϊ�顣���仰˵,���ݵ�HDFS���Զ�ȡ��д�����С������Ϊһ���顣ȱʡ�Ŀ��СΪ64MB,�����������Ӱ���Ҫ��HDFS�������ı䡣
(3)HDFS��Ŀ��
���ϼ��ͻָ�:����HDFS������������ͨӲ��,��������Ƶ�������HDFSӦ�þ��п��ٺ��Զ����ϼ��ͻָ����ơ�
������ݼ�:HDFS�����ٸ���Ⱥ�ڵ����������Ӵ�����ݼ���Ӧ�ó���
����Ӳ��:���������,�����㷢�����õ����ݿ��Ը�Ч����ɡ��漰������ݼ��ر���������������ͨ����,����������������
�����������й�ȵ�һ��������ͼ

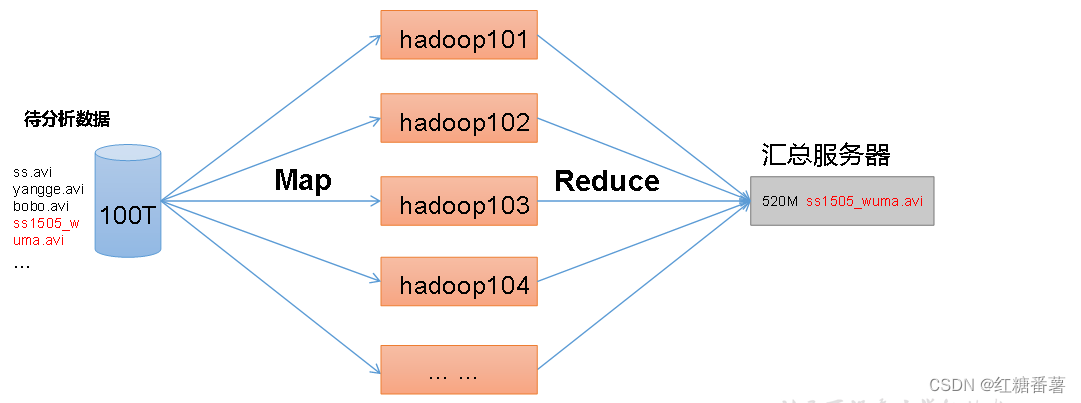
1.5.2 ��ʶMapReduce
MapReduce��һ�ִ��������ͳ���ģ�ͻ���Java�ķֲ�ʽ���㡣 MapReduce�㷨������������Ҫ����,��Map �� Reduce��Map������һ������,������ת������һ������,����,����Ԫ�����ֽ��Ԫ��(��/ֵ��)�����,��������,����Ҫ��Map ��Ϊ���벢�����Щ����Ԫ��ɵ�һ��С��Ԫ���������ΪMapReduce��ʾ�����Ƶ�������Map��ҵ֮��ִ��reduce����
MapReduce��Ҫ�ŵ���,�������״��ģ���ݴ����ڶ������ڵ㡣����MapReduceģ����,���ݴ�����ԭ�ﱻ��Ϊӳ�����ͼ��������ֽ����ݴ���Ӧ�õ�ӳ�����ͼ�������ʱ����ͨ�ġ����DZ�дMapReduce��ʽ��Ӧ��,��չӦ�ó��������ڼ���,��ǧ,�����������Ⱥ�еĽ�����һ�����õĸ��ġ�����Ŀ���չ�����������ڶ����Աʹ��MapReduceģ�͡�
MapReduce��������̷�Ϊ������:Map��Reduce
1)Map�β��д�����������
2)Reduce�ζ�Map������л���
1.5.3 ��ʶYarn
Yet Another Resource Negotiator���YARN ,��һ����ԴЭ����,��Hadoop����Դ��������
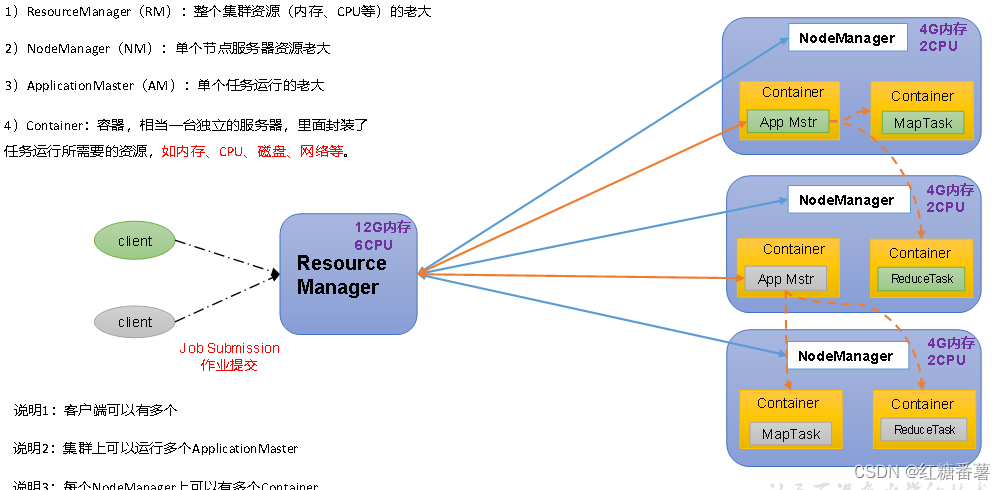
1.6 HDFS MapReduce Yarn���ߵĹ�ϵ
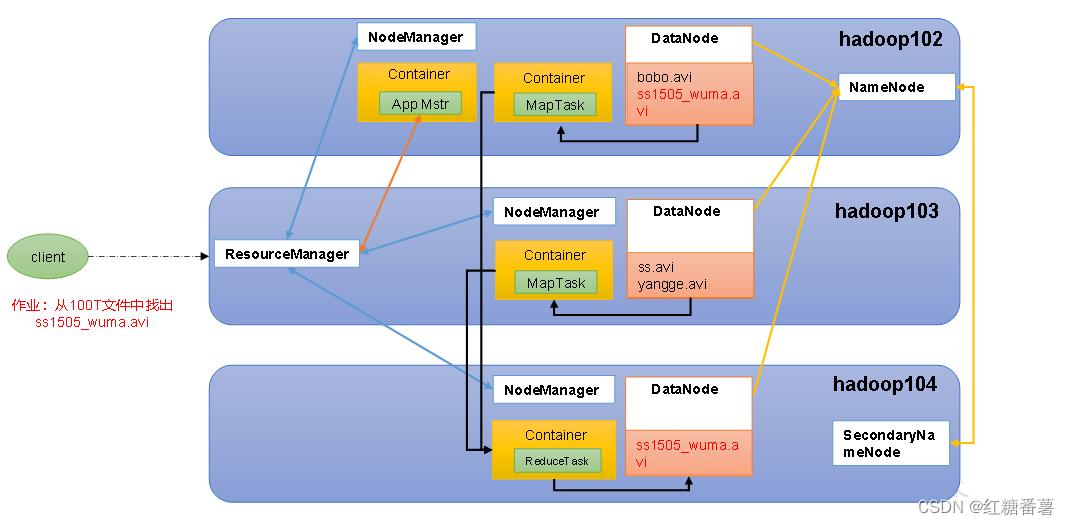
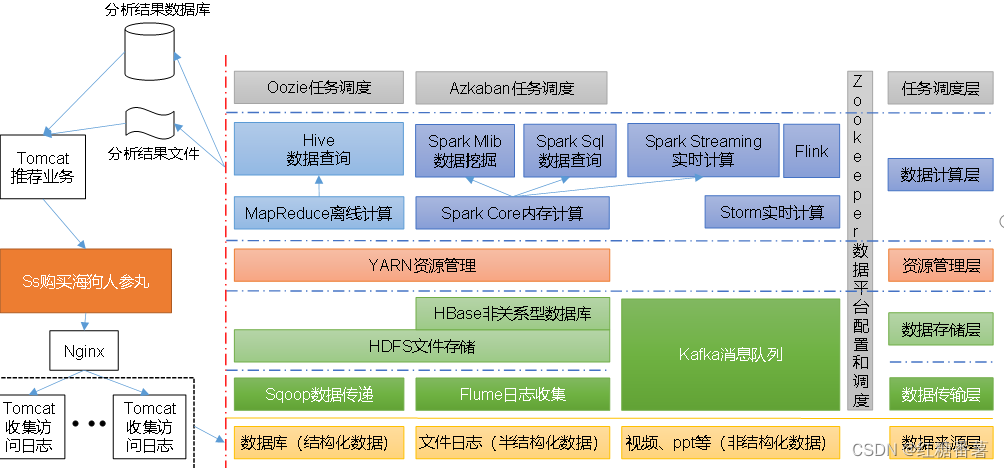
2.��������̬��ϵ����

1)Sqoop:Sqoop��һ�Դ�Ĺ���,��Ҫ������Hadoop��Hive�봫ͳ�����ݿ�(MySQL)��������ݵĴ���,���Խ�һ����ϵ�����ݿ�(���� :MySQL,Oracle ��)�е����ݵ�����Hadoop��HDFS��,Ҳ���Խ�HDFS�����ݵ�������ϵ�����ݿ��С�
2)Flume:Flume��һ���߿��õ�,�߿ɿ���,�ֲ�ʽ�ĺ�����־�ɼ����ۺϺʹ����ϵͳ,Flume֧������־ϵͳ�ж��Ƹ������ݷ��ͷ�,�����ռ�����;
3)Kafka:Kafka��һ�ָ��������ķֲ�ʽ����������Ϣϵͳ;
4)Spark:Spark�ǵ�ǰ�����еĿ�Դ�������ڴ�����ܡ����Ի���Hadoop�ϴ洢�Ĵ����ݽ��м��㡣
5)Flink:Flink�ǵ�ǰ�����еĿ�Դ�������ڴ�����ܡ�����ʵʱ����ij����϶ࡣ
6)Oozie:Oozie��һ������Hadoop��ҵ(job)�Ĺ������̵��ȹ���ϵͳ��
7)Hbase:HBase��һ���ֲ�ʽ�ġ������еĿ�Դ���ݿ⡣HBase��ͬ��һ��Ĺ�ϵ���ݿ�,����һ���ʺ��ڷǽṹ�����ݴ洢�����ݿ⡣
8)Hive:Hive�ǻ���Hadoop��һ�����ݲֿ��,���Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ��,���ṩ��SQL��ѯ����,���Խ�SQL���ת��ΪMapReduce����������С����ŵ���ѧϰ�ɱ���,����ͨ����SQL������ʵ�ּ�MapReduceͳ��,���ؿ���ר�ŵ�MapReduceӦ��,ʮ���ʺ����ݲֿ��ͳ�Ʒ�����
9)ZooKeeper:����һ����Դ��ͷֲ�ʽϵͳ�Ŀɿ�Э��ϵͳ,�ṩ�Ĺ��ܰ���:����ά�������ַ��ֲ�ʽͬ���������ȡ�
��β
�������Hadoop�����Ž����������,����н���ֱ�����۲����Ϳ�����,�����������Ľ�,���ϣ���������ǵ����ָ�������������,����?
�����һ�����Թ�ȵĴ�����ϵͳ�Ƽ�����ջ