1���������ܵ���
1.1 ������Դ����
spark���ܵ��ŵ�һ������Ϊ�������������Դ,��һ���ķ�Χ��������Դ�ķ��������ܵ������dz����ȵġ�
bin/spark-submit \
--class com.yyds.spark.Wordcount \
--deploy-mode cluster \
--num-executors 10 \
--driver-memory 6g \
--executor-memory 6g \
--executor-cores 3 \
/usr/opt/spark/jars/spark.jar \
���Խ��з������Դ�����ʾ:
�Cnum-executors ���� Executor ������
�Cdriver-memory ���� Driver �ڴ�(Ӱ�첻��)
�Cexecutor-memory ����ÿ�� Executor ���ڴ��С
�Cexecutor-cores ����ÿ�� Executor �� CPU core ����
����ԭ��:����������������Դ���ڵ�����ʹ�õ���Դ������ȡ�
���ھ�����Դ�ķ���,���Ƿֱ����� Spark ������ Cluster ����ģʽ:
? ��һ���� Spark Standalone ģʽ,�����ύ����ǰ,һ��֪�����߿��Դ���ά���Ż�ȡ�������ʹ�õ���Դ���,�ڱ�д submit �ű���ʱ��,���ݿ��õ���Դ���������
Դ�ķ���,����˵��Ⱥ�� 15 ̨����,ÿ̨����Ϊ 8G �ڴ�,2 �� CPU core,��ô��ָ�� 15 �� Executor,ÿ�� Executor ���� 8G �ڴ�,2 �� CPU core��
? �ڶ����� Spark Yarn ģʽ,���� Yarn ʹ����Դ���н�����Դ�ķ���͵���,�ڱ�дsubmit �ű���ʱ��,���� Spark ��ҵҪ�ύ������Դ����,������Դ�ķ���,������
Դ������ 400G �ڴ�,100 �� CPU core,��ôָ�� 50 �� Executor,ÿ�� Executor ����8G �ڴ�,2 �� CPU core��
�Ը�����Դ�����˵��ں�,�õ������������������±���:
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-PAoWQJmq-1655089965075)(D:\works\spark-sql\azkban_files\pictures\executor����.png)]
��������spark�ű�������:
bin/spark-submit \
--class com.yyds.spark.Wordcount \
--deploy-mode cluster \
--num-executors 10 \
--driver-memory 6g \
--executor-memory 6g \
--executor-cores 3 \
--queue root.default \
--conf spark.yarn.executor.memoryOverhead=2048 \
--conf spark.core.connection.ack.wait.timeout=300 \
/usr/opt/spark/jars/spark.jar \
? --num-executors:50~100
? --driver-memory:1G~5G
? --executor-memory:6G~10G
? --executor-cores:3
? --master:ʵ����������һ��ʹ�� yarn
1.2 rdd���Ż�
(1) rdd�ij־û�
�� Spark ��,����ζ�ͬһ�� RDD ִ�����Ӳ���ʱ,ÿһ�ζ������� RDD ��֮ǰ�ĸ� RDD ���¼���һ��,��������DZ���Ҫ�����,��ͬһ�� RDD ���ظ������Ƕ���Դ
�ļ����˷�,���,����Զ��ʹ�õ� RDD ���г־û�,ͨ���־û������� RDD �����ݻ��浽�ڴ�/������,֮����ڹ��� RDD �ļ��㶼����ڴ�/������ֱ�ӻ�ȡ RDD ���ݡ�
? RDD �ij־û��ǿ��Խ������л���,���ڴ����� RDD �����������Ľ��д�ŵ�ʱ��,���Կ���ʹ�����л��ķ�ʽ��С�������,�����������洢���ڴ��С�
? ����������ݵĿɿ���Ҫ��ܸ�,�����ڴ����,����ʹ�ø�������,�� RDD ���ݽ��г־û������־û������˸�������ʱ,���ڳ־û���ÿ�����ݵ�Ԫ���洢һ������,
���������ڵ�����,�ɴ�ʵ�����ݵ��ݴ�,һ��һ���������ݶ�ʧ,����Ҫ���¼���,������ʹ������һ��������
(2) RDD���������filter����
��ȡ����ʼ RDD ��,Ӧ�ÿ��Ǿ���ع��˵�����Ҫ������,�������ٶ��ڴ��ռ��,�Ӷ����� Spark ��ҵ������Ч�ʡ�
1.3 ���жȵĵ���
Spark ��ҵ�еIJ��ж�ָ���� stage �� task ��������
������ж����ò����������²��жȹ���,�ᵼ����Դ�ļ����˷�,����,20 �� Executor,ÿ�� Executor ���� 3 �� CPU core,�� Spark ��ҵ�� 40 �� task,����ÿ�� Executor ���䵽��
task ������ 2 ��,���ʹ��ÿ�� Executor ��һ�� CPU core ����,������Դ���˷ѡ�
����IJ��ж�����,Ӧ�����ò��ж�����Դ��ƥ��,����˵��������Դ������ǰ����,���ж�Ҫ���õľ����ܴ�,�ﵽ���Գ�����ü�Ⱥ��Դ�����������ò��ж�,������������
Spark ��ҵ�����ܺ������ٶȡ�
** Spark �ٷ��Ƽ�,task ����Ӧ������Ϊ Spark ��ҵ�� CPU core ������ 2~3 ��.**
֮����û���Ƽ� task ������ CPU core �������,����Ϊ task ��ִ��ʱ�䲻ͬ,�е� task ִ���ٶȿ���е� task ִ���ٶ���,��� task ������ CPU core �������,��ôִ�п�� task ִ�����
��,����� CPU core ���е��������� task ��������Ϊ CPU core ������ 2~3 ��,��ôһ��
task ִ����Ϻ�,CPU core ������ִ����һ�� task,��������Դ���˷�,ͬʱ������ Spark��ҵ���е�Ч�ʡ�
// Spark ��ҵ���жȵ�����������ʾ:
val conf = new SparkConf()
.set("spark.default.parallelism", "500")
1.4 �㲥����
Ĭ�������,task �е����������ʹ�����ⲿ�ı���,ÿ�� task �����ȡһ�ݱ����ĸ���,���������ڴ�ļ������ġ�
һ����,��������� RDD ���г־û�,���ܾ����� RDD���ݴ����ڴ�,ֻ��д�����,���� IO ����������������;
��һ����,task �ڴ��������ʱ��,Ҳ���ᷢ�ֶ��ڴ�������´����Ķ���,��ͻᵼ��Ƶ���� GC,GC �ᵼ�¹����߳�ֹͣ,�������� Spark ��ͣ����һ��ʱ��,����Ӱ�� Spark ���ܡ�
���赱ǰ���������� 20 �� Executor,ָ�� 500 �� task,��һ�� 20M �ı��������� task����,��ʱ���� 500 �� task �в��� 500 ������,�ķѼ�Ⱥ 10G ���ڴ�,���ʹ���˹㲥��
��, ��ôÿ�� Executor ����һ������,һ������ 400M �ڴ�,�ڴ����ļ����� 5 ����
�㲥������ÿ�� Executor ����һ������,�� Executor ������ task ���ô˹㲥����,���ñ��������ĸ������������١�
�ڳ�ʼ��,�㲥����ֻ�� Driver ����һ�ݸ�����task �����е�ʱ��,��Ҫʹ�ù㲥�����е�����,��ʱ���Ȼ����Լ����ص� Executor ��Ӧ�� BlockManager �г��Ի�ȡ����,��
������û��,BlockManager �ͻ�� Driver ���������ڵ�� BlockManager ��Զ����ȡ�����ĸ���,���ɱ��ص� BlockManager ���й���;֮��� Executor ������ task ����ֱ�Ӵӱ��ص�BlockManager �л�ȡ����
1.5 Kryo���л�
Ĭ�������,Spark ʹ�� Java �����л����ơ�Java �����л�����ʹ�÷���,����Ҫ���������,��������ʹ�õı���ʵ�� Serializable �ӿڼ���,����,Java ���л����Ƶ�Ч�ʲ�
��,���л��ٶ����������л����������ռ�õĿռ���Ȼ�ϴ�
Kryo ���л����Ʊ� Java ���л������������ 10 ������,Spark ֮����û��Ĭ��ʹ��Kryo ��Ϊ���л����,����Ϊ����֧�����ж�������л�,ͬʱ Kryo ��Ҫ�û���ʹ��ǰע
����Ҫ���л�������,��������,���� Spark 2.0.0 �汾��ʼ,�����͡����������顢�ַ������͵� Shuffling RDDs �Ѿ�Ĭ��ʹ�� Kryo ���л���ʽ�ˡ�
public class MyKryoRegistrator implements KryoRegistrator
{
@Override
public void registerClasses(Kryo kryo)
{
kryo.register(StartupReportLogs.class);
}
}
// ���� Kryo ���л���ʽ��ʵ������:
//���� SparkConf ����
val conf = new SparkConf().setMaster(��).setAppName(��)
//ʹ�� Kryo ���л���,���Ҫʹ�� Java ���л���,��Ҫ�Ѹ������ε�
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//�� Kryo ���л�����ע���Զ�����༯��,���Ҫʹ�� Java ���л���,��Ҫ�Ѹ������ε�
conf.set("spark.kryo.registrator", "yyds.com.MyKryoRegistrator");
1.6 ���ڱ��ػ��ȴ�ʱ��
Spark ��ҵ���й�����,Driver ���ÿһ�� stage �� task ���з��䡣���� Spark �� task �����㷨,Spark ϣ�� task �ܹ���������Ҫ������������ڵĽڵ�(���ݱ��ػ�˼��),����
�Ϳ��Ա������ݵ����紫�䡣ͨ����˵,task ���ܲ��ᱻ���䵽���������������ڵĽڵ�,��Ϊ��Щ�ڵ���õ���Դ�����Ѿ��þ�,��ʱ,Spark ��ȴ�һ��ʱ��,Ĭ�� 3s,����ȴ�
ָ��ʱ�����Ȼ����ָ���ڵ�����,��ô���Զ�����,���Խ� task ���䵽�Ƚϲ�ı��ػ���������Ӧ�Ľڵ���,���罫 task ���䵽����Ҫ��������ݱȽϽ���һ���ڵ�,Ȼ���
�м���,�����ǰ������Ȼ����,��ô����������
�� task Ҫ���������ݲ��� task ���ڽڵ���ʱ,�ᷢ�����ݵĴ��䡣task ��ͨ�����ڽڵ�� BlockManager ��ȡ����,BlockManager �������ݲ��ڱ���ʱ,��ͨ�����紫�������
�������ڽڵ�� BlockManager ����ȡ���ݡ�
���紫�����ݵ���������Dz�Ը�⿴����,���������紫�������Ӱ������,���,����ϣ��ͨ�����ڱ��ػ��ȴ�ʱ��,����ڵȴ�ʱ�����ʱ����,Ŀ��ڵ㴦�������һ����
task,��ô��ǰ�� task ���л���õ�ִ��,�������ܹ����� Spark ��ҵ���������ܡ�
Spark �ı��ػ��ȼ������ʾ:
���� ����
PROCESS_LOCAL ���̱��ػ�,task ��������ͬһ�� Executor ��,������á�
NODE_LOCAL �ڵ㱾�ػ�,task��������ͬһ���ڵ���,����task�����ݲ���ͬһ�� Executor ��,������Ҫ�ڽ��̼���д��䡣
RACK_LOCAL ���ܱ��ػ�,task ��������ͬһ�����ܵ������ڵ���,������Ҫͨ�������ڽڵ�֮����д��䡣
NO_PREF ����task ��˵,�������ȡ��һ��,û�кû�֮�֡�
ANY task �����ݿ����ڼ�Ⱥ���κεط�,���Ҳ���һ��������,������
�� Spark ��Ŀ������,����ʹ�� client ģʽ�Գ�����в���,��ʱ,�����ڱ��ؿ����Ƚ�ȫ����־��Ϣ,��־��Ϣ������ȷ�� task ���ݱ��ػ��ļ���,����ֶ���
PROCESS_LOCAL,��ô��������е���,����������ֺܶ�ļ����� NODE_LOCAL��ANY,��ô��Ҫ�Ա��ػ��ĵȴ�ʱ�����е���,ͨ���ӳ����ػ��ȴ�ʱ��,���� task �ı�
�ػ�������û������,���۲� Spark ��ҵ������ʱ����û�����̡�
ע��,���̲���,��Ҫ�����ػ��ȴ�ʱ���ӳ��ع���,������Ϊ�����ĵȴ�ʱ��,ʹ��Spark ��ҵ������ʱ�䷴�������ˡ�
Spark ���ػ��ȴ�ʱ���������������ʾ:
val conf = new SparkConf()
.set("spark.locality.wait", "6")
2�����ӵ���
2.1 mapPartitions
��ͨ�� map ���Ӷ� RDD �е�ÿһ��Ԫ�ؽ��в���,�� mapPartitions ���Ӷ� RDD ��ÿһ���������в������������ͨ�� map ����,����һ�� partition �� 1 ��������,��ô map
�����е� function Ҫִ�� 1 ���,Ҳ���Ƕ�ÿ��Ԫ�ؽ��в�����
����� mapPartition ����,����һ�� task ����һ�� RDD �� partition,��ôһ�� task ֻ��ִ��һ�� function,function һ�ν������е� partition ����,Ч�ʱȽϸߡ�
����,��Ҫ�� RDD �е���������ͨ�� JDBC д������,���ʹ�� map ����,��ô��Ҫ�� RDD �е�ÿһ��Ԫ�ض�����һ�����ݿ�����,��������Դ�����ĺܴ�,���ʹ��
mapPartitions ����,��ô���һ������������,ֻ��Ҫ����һ�����ݿ����ӡ�
mapPartitions ����Ҳ����һЩȱ��:������ͨ�� map ����,һ�δ���һ������,����ڴ����� 2000 �����ݺ��ڴ治��,��ô���Խ��Ѿ�������� 2000 �����ݴ��ڴ�����������
��;�������ʹ�� mapPartitions ����,���������dz���ʱ,function һ�δ���һ������������,���һ���ڴ治��,��ʱ�������ڴ�,�Ϳ��ܻ� OOM,���ڴ������
���,mapPartitions ���������������������ر���ʱ��,��ʱʹ�� mapPartitions ���Ӷ����ܵ�����Ч�����Dz����ġ�(���������ܴ��ʱ��,һ��ʹ�� mapPartitions ����,�ͻ�
ֱ�� OOM)
����Ŀ��,Ӧ�����ȹ���һ�� RDD ����������ÿ�� partition ��������,�Լ������ÿ�� Executor ���ڴ���Դ,�����Դ����,���Կ���ʹ�� mapPartitions ���Ӵ��� map��
2.2 foreachPartition �Ż����ݿ����
������������,ͨ��ʹ�� foreachPartition ������������ݿ��д��,ͨ�� foreachPartition���ӵ�����,�����Ż�д���ݿ�����ܡ�
���ʹ�� foreach ����������ݿ�IJ���,���� foreach �����DZ��� RDD ��ÿ������,���,ÿ�����ݶ��Ὠ��һ�����ݿ�����,���Ƕ���Դ�ļ����˷�,���,����д���ݿ��
��,����Ӧ��ʹ�� foreachPartition ���ӡ�
�� mapPartitions ���ӷdz�����,foreachPartition �ǽ� RDD ��ÿ��������Ϊ��������,һ�δ���һ������������,Ҳ����˵,����漰���ݿ����ز���,һ������������ֻ��Ҫ
ʹ���� foreachPartition ���Ӻ�,���Ի�����µ���������:
? ��������д�� function ����,һ�δ���һ��������������;
? ����һ�������ڵ�����,����Ψһ�����ݿ�����;
? ֻ��Ҫ�����ݿⷢ��һ�� SQL ���Ͷ������;
������������,ȫ������ʹ�� foreachPartition ����������ݿ������foreachPartition ���Ӵ���һ������,�� mapPartitions ��������,���һ���������������ر��,���ܻ���� OOM,
���ڴ������
2.3 filter �� coalesce �����ʹ��
�� Spark ���������Ǿ�����ʹ�� filter ������� RDD �����ݵĹ���,�������ʼ��,�Ӹ��������м��ص����������������,����һ������ filter ���˺�,ÿ����������������
���ܻ���ڽϴ����,��ͼ��ʾ:
Ϣ���ǿ��Է�����������:
? ÿ�� partition ����������С��,���������֮ǰ�� partition ��ȵ� task ����ȥ������ǰ
����,�е��˷� task �ļ�����Դ;
? ÿ�� partition ����������һ��,�ᵼ�º����ÿ�� task ����ÿ�� partition ���ݵ�ʱ��,
ÿ�� task Ҫ��������������ͬ,����п��ܵ���������б���⡣
����ͼ��ʾ,�ڶ������������ݹ��˺�ֻʣ100��,�����������������ݹ��˺�ʣ��800��,����ͬ�Ĵ�������,�ڶ���������Ӧ�� task �������������������������Ӧ�� task ����
�����������ﵽ�� 8 ��,��Ҳ�ᵼ�������ٶȿ��ܴ��������IJ��,��Ҳ����������б���⡣
�����������������,���Ƿֱ���з���:
? ��Ե�һ������,��Ȼ��������������С��,����ϣ�����ԶԷ������ݽ������·���,���罫ԭ�� 4 ������������ת���� 2 ��������,����ֻ��Ҫ�ú�������� task ���д�
������,��������Դ���˷ѡ�
? ��Եڶ�������,��������͵�һ������Ľ�������dz�����,�Է����������·���,��ÿ�� partition �е����������,��ͱ�����������б���⡣
��ô����Ӧ�����ʵ������Ľ��˼·?������Ҫ coalesce ���ӡ�
repartition �� coalesce ���������������ط���,���� repartition ֻ�� coalesce �ӿ��� shuffleΪ true �ļ���ʵ��,coalesce Ĭ������²����� shuffle,���ǿ���ͨ�������������á�
��������ϣ����ԭ���ķ������� A ͨ�����·�����Ϊ B,��ô�����¼������:
? A > B(���������ϲ�Ϊ��������)
-
A �� B ���ֵ����
��ʱʹ�� coalesce ����,���� shuffle ���̡� -
A �� B ���ֵ�ܴ�
��ʱ����ʹ�� coalesce ���Ҳ����� shuffle ����,���ǻᵼ�ºϲ��������ܵ���,�����Ƽ����� coalesce �ĵڶ�������Ϊ true,������ shuffle ���̡�
? A < B(���������ֽ�Ϊ��������)
��ʱʹ�� repartition ����,���ʹ�� coalesce ��Ҫ�� shuffle ����Ϊ true,���� coalesce ��Ч��
���ǿ����� filter ����֮��,ʹ�� coalesce �������ÿ�� partition ��������������ͬ�����,ѹ�� partition ������,������ÿ�� partition ���������������Ƚ���,�Ա��ں���� task ����
�������,��ij�̶ֳ����ܹ���һ���̶����������ܡ�
ע��:local ģʽ�ǽ�����ģ�⼯Ⱥ����,�Ѿ��Բ��жȺͷ�����������һ�����ڲ��Ż�,��˲���ȥ���ò��жȺͷ���������
2.4 repartition���SparkSQL�Ͳ��ж�����
�ڳ������ܵ��������ǽ����˲��жȵĵ��ڲ���,����,���жȵ����ö���Spark SQL �Dz���Ч��,�û����õIJ��ж�ֻ���� Spark SQL ��������� Spark �� stage ��Ч��
Spark SQL �IJ��жȲ������û��Լ�ָ��,Spark SQL �Լ���Ĭ�ϸ��� hive ����Ӧ��HDFS �ļ��� split �����Զ�����Spark SQL ���ڵ��Ǹ� stage �IJ��ж�,�û��Լ�ͨ
spark.default.parallelism ����ָ���IJ��ж�,ֻ����û Spark SQL �� stage ����Ч��
���� Spark SQL ���� stage �IJ��ж����ֶ�����,����������ϴ�,���Ҵ� stage �к����� transformation �������Ÿ��ӵ�ҵ����,�� Spark SQL �Զ����õ� task ��������,
�����ζ��ÿ�� task Ҫ����Ϊ�����ٵ�������,Ȼ��Ҫִ�зdz����ӵĴ�����,��Ϳ��ܱ���Ϊ��һ���� Spark SQL �� stage �ٶȺ���,��������û�� Spark SQL �� stage ����
�ٶȷdz��졣
Ϊ�˽�� Spark SQL �����ò��жȺ� task ����������,���ǿ���ʹ�� repartition ���ӡ�
Spark SQL ��һ���IJ��жȺ� task �����϶���û�а취ȥ�ı���,����,����Spark SQL ��ѯ������ RDD,����ʹ�� repartition ����,ȥ���½��з���,������
�����·���Ϊ��� partition,�� repartition ֮��� RDD ����,���ڲ������ Spark SQL,��� stage �IJ��жȾͻ�������ֶ����õ�ֵ,�����ͱ����� Spark SQL ����
�� stage ֻ���������� task ȥ�����������ݲ�ִ�и��ӵ��㷨����
2.5 reduceByKey Ԥ�ۺ�
reduceByKey �������ͨ�� shuffle ����һ���������ص���ǻ���� map �˵ı��ؾۺ�,map �˻��ȶԱ��ص����ݽ��� combine ����,Ȼ������д����¸� stage ��ÿ�� task ����
���ļ���,Ҳ������ map ��,��ÿһ�� key ��Ӧ�� value,ִ�� reduceByKey ���Ӻ�����
groupByKey ������� map �˵ľۺ�,���ǽ����� map �˵����� shuffle ��reduce ��,Ȼ���� reduce �˽������ݵľۺϲ��������� reduceByKey �� map �˾ۺϵ�����,
ʹ�����紫�����������С,���Ч��Ҫ���Ը��� groupByKey��
3 Shuffle�ĵ���
3.1 ����map�˻�������С
�� Spark �������й�����,��� shuffle �� map �˴������������Ƚϴ�,���� map �˻���Ĵ�С�ǹ̶���,���ܻ���� map �˻�������Ƶ�� spill ��д�������ļ��е����,ʹ��
���ܷdz�����,ͨ������ map �˻���Ĵ�С,���Ա���Ƶ���Ĵ��� IO ����,�������� Spark������������ܡ�
map �˻����Ĭ�������� 32KB,���ÿ�� task ���� 640KB ������,��ô�ᷢ�� 640/32 = 20 ����д,���ÿ�� task ���� 64000KB ������,���ᷢ�� 64000/32=2000 ����д,���
�����ܵ�Ӱ���Ƿdz����صġ�
// ����map�˻������Ĵ�С
val conf = new SparkConf()
.set("spark.shuffle.file.buffer", "64")
3.2 ����reduce����ȡ���ݻ�������С
Spark Shuffle ������,shuffle reduce task �� buffer ��������С������ reduce task ÿ���ܹ������������,Ҳ����ÿ���ܹ���ȡ��������,����ڴ���Դ��Ϊ����,�ʵ�������ȡ��
�ݻ������Ĵ�С,���Լ�����ȡ���ݵĴ���,Ҳ�Ϳ��Լ������紫��Ĵ���,�����������ܡ�
reduce ��������ȡ�������Ĵ�С����ͨ�� spark.reducer.maxSizeInFlight ������������,Ĭ��Ϊ 48MB
// ����reduce����ȡ���ݻ�������С
val conf = new SparkConf()
.set("spark.reducer.maxSizeInFlight", "96")
3.3 ����reduce����ȡ�������Դ���
Spark Shuffle ������,reduce task ��ȡ�����Լ�������ʱ,�����Ϊ�����쳣��ԭ����ʧ�ܻ��Զ��������ԡ�������Щ�������ر��ʱ�� shuffle ��������ҵ,��������������
�����(���� 6 ��),�Ա������� JVM �� full gc �������粻�ȶ������ص��µ�������ȡʧ�ܡ�
��ʵ���з���,������Գ���������(��ʮ��~�ϰ���)�� shuffle ����,���ڸò������Դ���������ȶ��ԡ�
reduce ����ȡ�������Դ�������ͨ�� spark.shuffle.io.maxRetries ������������,�ò����ʹ����˿������Ե��������������ָ������֮����ȡ����û�гɹ�,�Ϳ��ܻᵼ����ҵ
ִ��ʧ��,Ĭ��Ϊ 3��
// ���� reduce ����ȡ�������Դ���
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "6")
3.4 ����reduce����ȡ���ݵȴ����
Spark Shuffle ������,reduce task ��ȡ�����Լ�������ʱ,�����Ϊ�����쳣��ԭ����ʧ�ܻ��Զ���������,��һ��ʧ�ܺ�,��ȴ�һ����ʱ�����ٽ�������,����ͨ���Ӵ�
���ʱ��(���� 60s),������ shuffle �������ȶ��ԡ�
reduce ����ȡ���ݵȴ��������ͨ�� spark.shuffle.io.retryWait ������������,Ĭ��ֵΪ 5s��
// ����reduce����ȡ���ݵȴ����
val conf = new SparkConf()
.set("spark.shuffle.io.retryWait", "60s")
3.5 ����SortShuffle���������ֵ
���� SortShuffleManager,��� shuffle reduce task ������С��ijһ��ֵ�� shuffle write �����в�������������,����ֱ�Ӱ���δ���Ż��� HashShuffleManager �ķ�ʽȥд����,��
�����Ὣÿ�� task ������������ʱ�����ļ����ϲ���һ���ļ�,���ᴴ�������������ļ���
����ʹ�� SortShuffleManager ʱ,�����ȷ����Ҫ�������,��ô���齫�����������һЩ,���� shuffle read task ������,��ô��ʱ map-side �Ͳ������������,�����������
���ܿ���,�������ַ�ʽ��,��Ȼ����������Ĵ����ļ�,��� shuffle write �����д���ߡ�
SortShuffleManager ���������ֵ�����ÿ���ͨ�� spark.shuffle.sort. bypassMergeThreshold ��һ������������,Ĭ��ֵΪ 200
// ����SortShuffle���������ֵ
val conf = new SparkConf()
.set("spark.shuffle.sort.bypassMergeThreshold", "400")
4 JVM�ĵ���
4.1 ����cache�������ڴ�ռ��
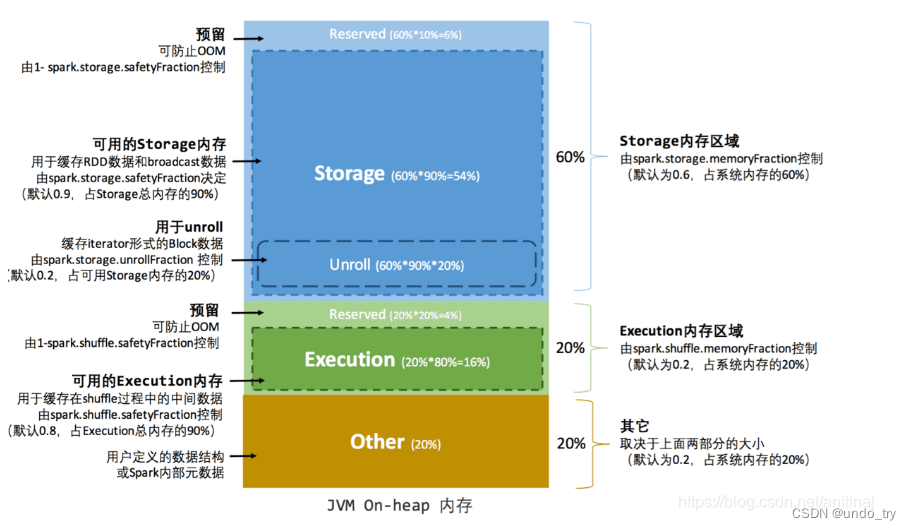
1. ��̬�ڴ��������
���� Spark ��̬�ڴ��������,���ڴ汻����Ϊ������,Storage �� Execution��Storage��Ҫ���ڻ��� RDD ���ݺ� broadcast ����,Execution ��Ҫ���ڻ����� shuffle �����в�����
�м�����,Storage ռϵͳ�ڴ�� 60%,Execution ռϵͳ�ڴ�� 20%,����������ȫ������
��һ�������,Storage ���ڴ涼�ṩ���� cache ����,���������ijЩ����� cache �����ڴ治�Ǻܽ���,�� task �������д����Ķ���ܶ�,Execution �ڴ�����Խ�С,��ص���Ƶ
���� minor gc,������Ƶ���� full gc,�������� Spark Ƶ����ֹͣ����,����Ӱ���ܴ�
�� Spark UI �п��Բ鿴ÿ�� stage ���������,����ÿ�� task ������ʱ�䡢gc ʱ��ȵ�,������� gc ̫Ƶ��,ʱ��̫��,�Ϳ��Կ��ǵ��� Storage ���ڴ�ռ��,�� task ִ�����Ӻ���
ʽ,�и�����ڴ����ʹ�á�
Storage �ڴ��������ͨ�� spark.storage.memoryFraction ��������ָ��,Ĭ��Ϊ 0.6,��60%,���������µݼ�
// ��̬�ڴ��������
val conf = new SparkConf()
.set("spark.storage.memoryFraction", "0.4")
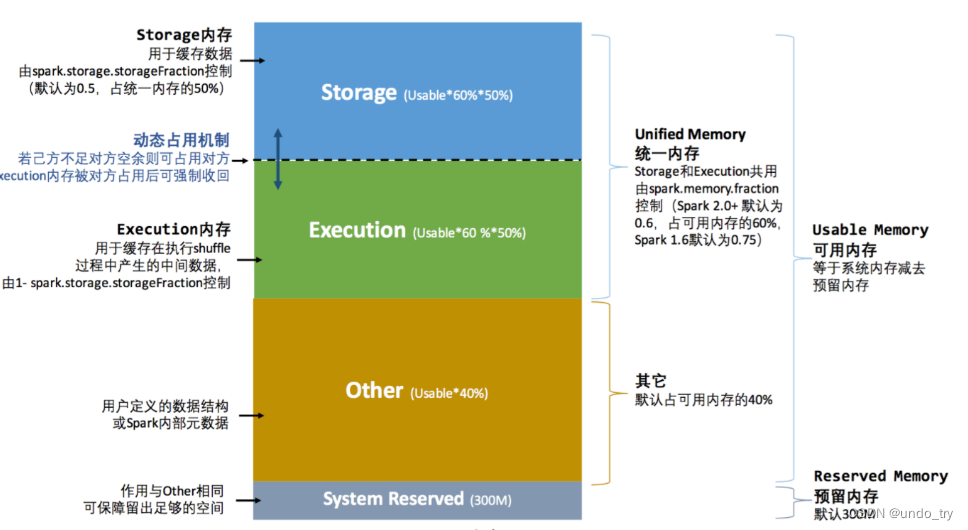
2. ͳһ�ڴ��������
spark��1.6��ʼ�����˶�̬�ڴ����ģʽ,��ִ���ڴ�ʹ洢�ڴ�֮����Ի�����ռ��
���� Spark ͳһ�ڴ��������,���ڴ汻����Ϊ������,Storage �� Execution��Storage��Ҫ���ڻ�������,Execution ��Ҫ���ڻ����� shuffle �����в������м�����,���������
���ڴ沿�ֳ�Ϊͳһ�ڴ�,Storage �� Execution ��ռͳһ�ڴ�� 50%,���ڶ�̬ռ�û��Ƶ�ʵ��,shuffle ������Ҫ���ڴ����ʱ,���Զ�ռ�� Storage ���ڴ�����,��������ֶ�����
���ڡ�
4.2 ����Executor�����ڴ�
Executor �Ķ����ڴ���Ҫ���ڳ���Ĺ����⡢Perm Space�� �߳� Stack ��һЩ Memory mapping ��, ������ C ��ʽ allocate object��
������ Spark ��ҵ�������������dz���,�ﵽ���ڵ�������,��ʱ���� Spark��ҵ��ʱ��ʱ�ر���,���� shuffle output file cannot find,executor lost,task lost,out of memory
��,������� Executor �Ķ����ڴ治̫����,���� Executor �����еĹ������ڴ������
stage �� task �����е�ʱ��,����Ҫ��һЩ Executor ��ȥ��ȡ shuffle map output �ļ�,���� Executor �����Ѿ������ڴ�����ҵ���,������� BlockManager Ҳû����,��Ϳ���
�ᱨ�� shuffle output file cannot find,executor lost,task lost,out of memory �ȴ���,��ʱ,�Ϳ��Կ��ǵ���һ�� Executor �Ķ����ڴ�,Ҳ�Ϳ��Ա��ⱨ��,���ͬʱ,�����ڴ���ڵıȽϴ��ʱ��,������������,Ҳ�����һ����������
Ĭ�������,Executor �����ڴ������Ϊ 300 �� MB,��ʵ�ʵ�����������,�Ժ������ݽ��д�����ʱ��,���ﶼ���������,���� Spark ��ҵ��������,������,��ʱ�ͻ�
ȥ�����������,������ 1G,������ 2G��4G��
Executor �����ڴ��������Ҫ�� spark-submit �ű�������\
--conf spark.yarn.executor.memoryOverhead=2048
4.3 �������ӵȴ�ʱ��
�� Spark ��ҵ���й�����,Executor ���ȴ��Լ����ع����� BlockManager �л�ȡij������,�������BlockManagerû�еĻ�,��ͨ��TransferServiceԶ�����������ڵ���Executor
�� BlockManager ����ȡ���ݡ�
��� task �����й����д�������������ߴ����Ķ���ϴ�,��ռ�ô������ڴ�,��ص���Ƶ������������,�����������ջᵼ�¹����ֳ�ȫ��ֹͣ,Ҳ����˵,��������һ��ִ
��,Spark �� Executor ���̾ͻ�ֹͣ����,���ṩ��Ӧ,��ʱ,����û����Ӧ,��������������,�ᵼ���������ӳ�ʱ��
������������,��ʱ������ file not found��file lost �������,�����������,���п����� Executor �� BlockManager ����ȡ���ݵ�ʱ��,����������,Ȼ��Ĭ�ϵ����ӵȴ�
ʱ�� 60s ��,����������ȡʧ��,����������Զ���ȡ��������,���ܻᵼ�� Spark ��ҵ�ı������������Ҳ���ܻᵼ�� DAGScheduler �����ύ���� stage,TaskScheduler �����ύ
���� task,����ӳ������ǵ� Spark ��ҵ������ʱ�䡣
��ʱ,���Կ��ǵ������ӵij�ʱʱ��,���ӵȴ�ʱ����Ҫ�� spark-submit �ű��н�������
--conf spark.core.connection.ack.wait.timeout=300