flink消费kafka 算是最常用的一种source了.
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(topics, new SimpleStringSchema(),properties);
那么当flink消费kafka数据的时候,该group针对的该topic 的offset 如何提交呢?如何保证flink能够exactly once 消费.
1.由kafka自行管理
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"true"); properties.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"50");
2.由flink自行管理
?StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment();
env.enableCheckpointing(60000); //flink开启checkpoint
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(topics, new SimpleStringSchema(),properties);
consumer.setStartFromGroupOffsets(); //从上次提交的offset的位置继续消费consumer.setCommitOffsetsOnCheckpoints(true);//checkpoint的时候提交offset
最开是使用的flink管理offset,测试了几次没问题.
后面在本地跑个小任务的时候,发现warn,具体现象就是
比如kafka里由3000条数据,我flink跑了300条后,我停掉flink任务后,按道理后面会从301条开始继续跑,但是还是从第1条开始.查看日志如下
WARN ?org.apach.flink.strea.conne.kafka.inter.KafkaFetcher - Committing offsets to Kafka takes longer than the checkpoint interval. Skipping commit of previous offsets because newer complete checkpoint offsets are available. This does not compromise Flink's checkpoint integrity.?
这句话就是说kafka提交offset时间很长,长到超过了我设置的checkpoint间隔? 我checkpoint设置的60s.我最开始认为是网络原因,提交offset失败
问题是说在flink执行checkpoint的间隔内,从kafka中拉取到的数据还没有处理完成,导致offset没办法提交,而下一次的checkpoint已经开始了,这样flink会跳过对offset的提交。
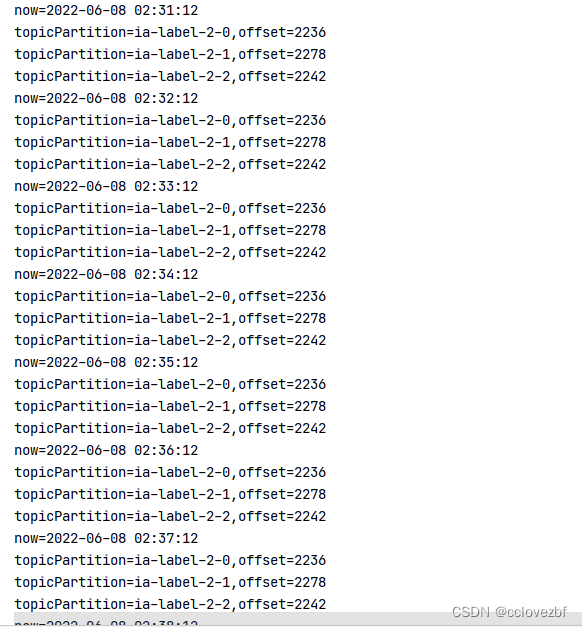
后面我为了看flink消费过程中是否提交了offset,写了一个程序,发现flink运行过程中,offset没有任何变化,但是当所有数据都消费完了 offset还是提交了.
这就奇了怪了.....
?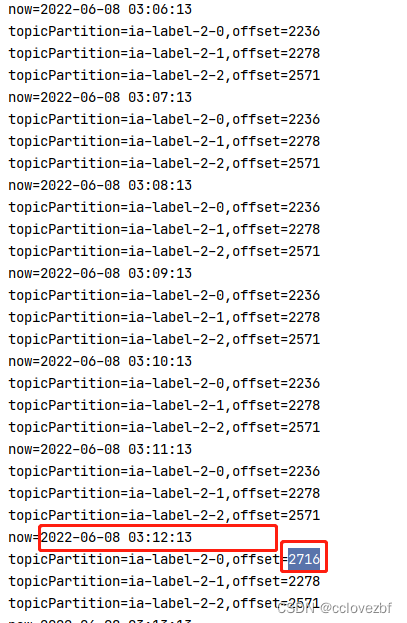
到后面只提交了一个partition的offset,这还没问题?
发现问题就要解决,解决问题需要学习很多东西.
1.checkpoint是什么? warn里就和这个扯上关系了,为什么出现这个问题?
2.别人的代码checkpoint也是这么设置的 为什么就我的代码出现了?flink针对我?
3.这个问题的原因是什么 我们该怎么解决.
checkpoint这个说起来很麻烦.....先不说了.
package flink;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Properties;
/**
* @Author: cc
* @Date: 2022/4/28 16:21
*/
public class FlinkKafkaConsumerTest {
private static final Logger logger = LoggerFactory.getLogger(FlinkKafkaConsumerTest.class);
public static void main(String[] args) throws Exception {
//配置kafka的参数
FlinkKafkaConsumer<String> consumer = buildKafkaStreamConsumer();
//初始化flink的streaming环境
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
env.enableCheckpointing(60000); //60s
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);//1s
System.out.println("env.getParallelism()="+env.getParallelism()); //12
env.setParallelism(3);//设置12 没有用的 我的kafka topic partition=3
DataStream<String> stream = env.addSource(consumer);
SingleOutputStreamOperator<String> streamOperator = stream.map(new RichMapFunction<String, String>() { //这里用rich 普通的map也行
@Override
public String map(String s) throws Exception {
//获取该数据被分配到哪个task
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
String format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS").format(new Date());
//打印日志 方便查找问题.
System.out.println(format+"-"+indexOfThisSubtask+"-"+s);
//do something
Thread.sleep(1000); //耗费时间5s
return s;
}
});
env.execute("cas-job");
}
private static FlinkKafkaConsumer<String> buildKafkaStreamConsumer(){
String bootstrapServers="9.135.68.xxx:9092";
String topic="ia-label-2";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", bootstrapServers);
properties.setProperty("group.id", "cc123");
List<String> topics = new ArrayList<>();
topics.add(topic);
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(topics, new SimpleStringSchema(), properties);
//从最新的还是最老开始消费
consumer.setStartFromEarliest();//用earlist可以每次都消费.为了检查问题
//consumer.setStartFromGroupOffsets();
//checkpoint的时候 提交offset
consumer.setCommitOffsetsOnCheckpoints(true);
return consumer;
}
}
kafka 获取group的topic的offset
public void getConsumerGroupOffset(String groupName,String topicName) throws ExecutionException, InterruptedException {
Properties properties = new Properties() {{
this.put("bootstrap.servers", "9.135.68.xxx:9092");
}};
AdminClient adminClient = AdminClient.create(properties);
for (int i = 0; i < Integer.MAX_VALUE; i++) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
Date date = new Date();
System.out.println("now=" + format.format(date));
ListConsumerGroupOffsetsResult result = adminClient.listConsumerGroupOffsets(groupName);
KafkaFuture<Map<TopicPartition, OffsetAndMetadata>> mapKafkaFuture = result.partitionsToOffsetAndMetadata();
Map<TopicPartition, OffsetAndMetadata> topicPartitionOffsetAndMetadataMap = mapKafkaFuture.get();
for (Map.Entry<TopicPartition, OffsetAndMetadata> entry : topicPartitionOffsetAndMetadataMap.entrySet()) {
TopicPartition topicPartition = entry.getKey();
String topic = topicPartition.topic();
if (topic.equals(topicName)){
OffsetAndMetadata offsetAndMetadata = entry.getValue();
long offset = offsetAndMetadata.offset();
System.out.println("topicPartition=" + topicPartition + ",offset=" + offset);
}
}
Thread.sleep(10000);
}
adminClient.close();
}先说我的代码问题出在哪?
背景,kafka 该topic已经有1w条数据了, 然后我启动flink消费,同时启动kafkaAdmin去每10s遍历查看offset是否提交.
为什么kafka针对我?
原因是kafka本身就有1w条数据(这个不是重点),然后我map方法里对获取的数据做了一些操作,比较耗时,比如msg是一个公司名,我在map里要根据这个公司名去调十几个工商接口,获取一些信息,最后拼接为一个map.总之就是很耗时 差不多5s.
所以我在代码里模拟了Thread.sleep(5000).
warn原因:flink在启动初期一次性就消费了1w条数据,然后进行map,注意我的并行度是3,每次对3条数据进行map,每条数据耗时5s.
我们的checkpoint间隔是1分钟,也就是说本身会在1分钟后提交本次消费完kafka的数据的offset,结果呢? 1分钟我最多处理了 60s/5s*3并行度=36条消息....消息还没处理完,checkpoint有到期了,所以就会有个警告,就是说我们处理的太慢了,现在再看大佬的翻译是不是一目了然....
问题是说在flink执行checkpoint的间隔内,从kafka中拉取到的数据还没有处理完成,导致offset没办法提交,而下一次的checkpoint已经开始了,这样flink会跳过对offset的提交。
场景重现...
已知 kafka内有1w条消息,我们并行度是3,那么每个slot就是要处理3000多条消息,我们的checkpoint是60s,所以我们每条数据的处理时间差不多20ms, 那么我们设置50ms,肯定还会报错!!!

?果然报错了......
其实这样还不直观,来点更直观的.
此时我们修改两个文件 properties.setProperty("group.id", "cc1234"); 换个group
先启动kafkaAdmin 每5s打印一次offset
now=2022-06-08 04:27:35//这个是一次offset都没提交所以不打印
now=2022-06-08 04:27:40
now=2022-06-08 04:27:45
now=2022-06-08 04:27:50
topicPartition=ia-label-2-0,offset=941 //第一次提交 应该是04:27:45-04:27:50之间
topicPartition=ia-label-2-1,offset=941
topicPartition=ia-label-2-2,offset=941
now=2022-06-08 04:28:20
topicPartition=ia-label-2-0,offset=941
topicPartition=ia-label-2-1,offset=941
topicPartition=ia-label-2-2,offset=941
now=2022-06-08 04:28:25
topicPartition=ia-label-2-0,offset=2858
topicPartition=ia-label-2-1,offset=2861
topicPartition=ia-label-2-2,offset=2858
now=2022-06-08 04:29:11
topicPartition=ia-label-2-0,offset=2858
topicPartition=ia-label-2-1,offset=2861
topicPartition=ia-label-2-2,offset=2858
now=2022-06-08 04:29:16
topicPartition=ia-label-2-0,offset=3228
topicPartition=ia-label-2-1,offset=3293
topicPartition=ia-label-2-2,offset=3249
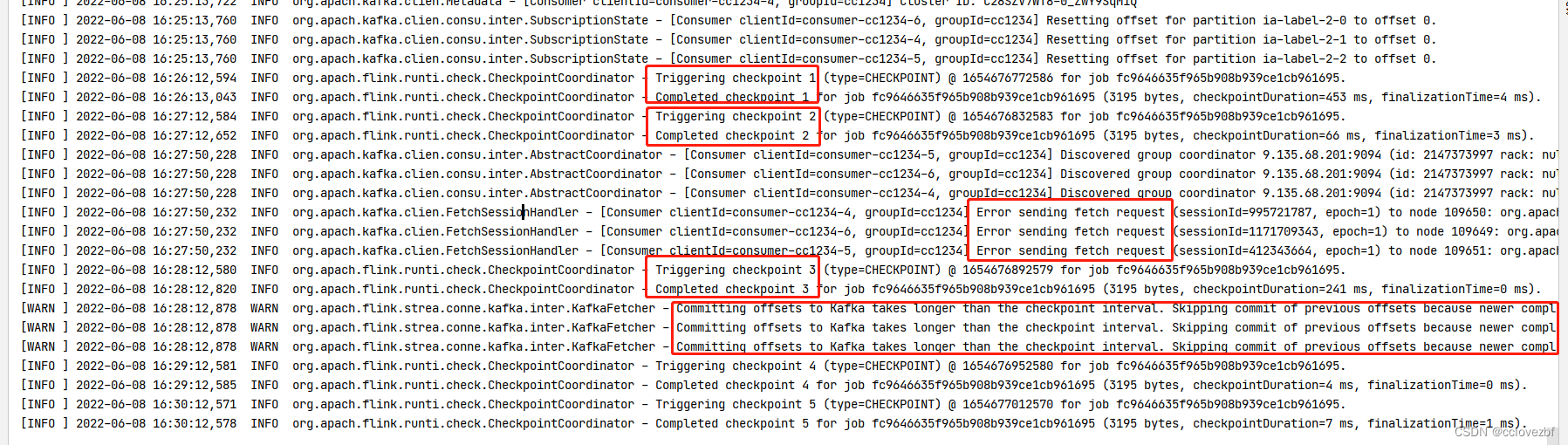
可以看到再checkpoint 1 和checkpoint2 complete的时候offset根本就没有提交.
至于后面为啥提交了...个人能力有限 还不能解决.
这都是很危险的..
所以问题就出在我们map的方法耗费的时间太长,解决也很简单,
1.之前我们是串行去调用工商接口,改为线程池并行去调用即可
2.还有最开始就要了解需求,kafka parittion设置太少,直接设置10个!!!
3.或者不要用flink提交,改为kafka提交模式....这种也存在一定的风险