首先我查询线上日志,很轻松就定位出有问题的sql
然后我连上生产数据库查看了表的数据量

好家伙,一亿多条记录,而我们的sql是这样的
select zion_core_task.uk_task_id from zion_core_task
WHERE
zion_core_task.scene_id = 36732
ORDER BY
zion_core_task.gmt_create DESC
LIMIT 1
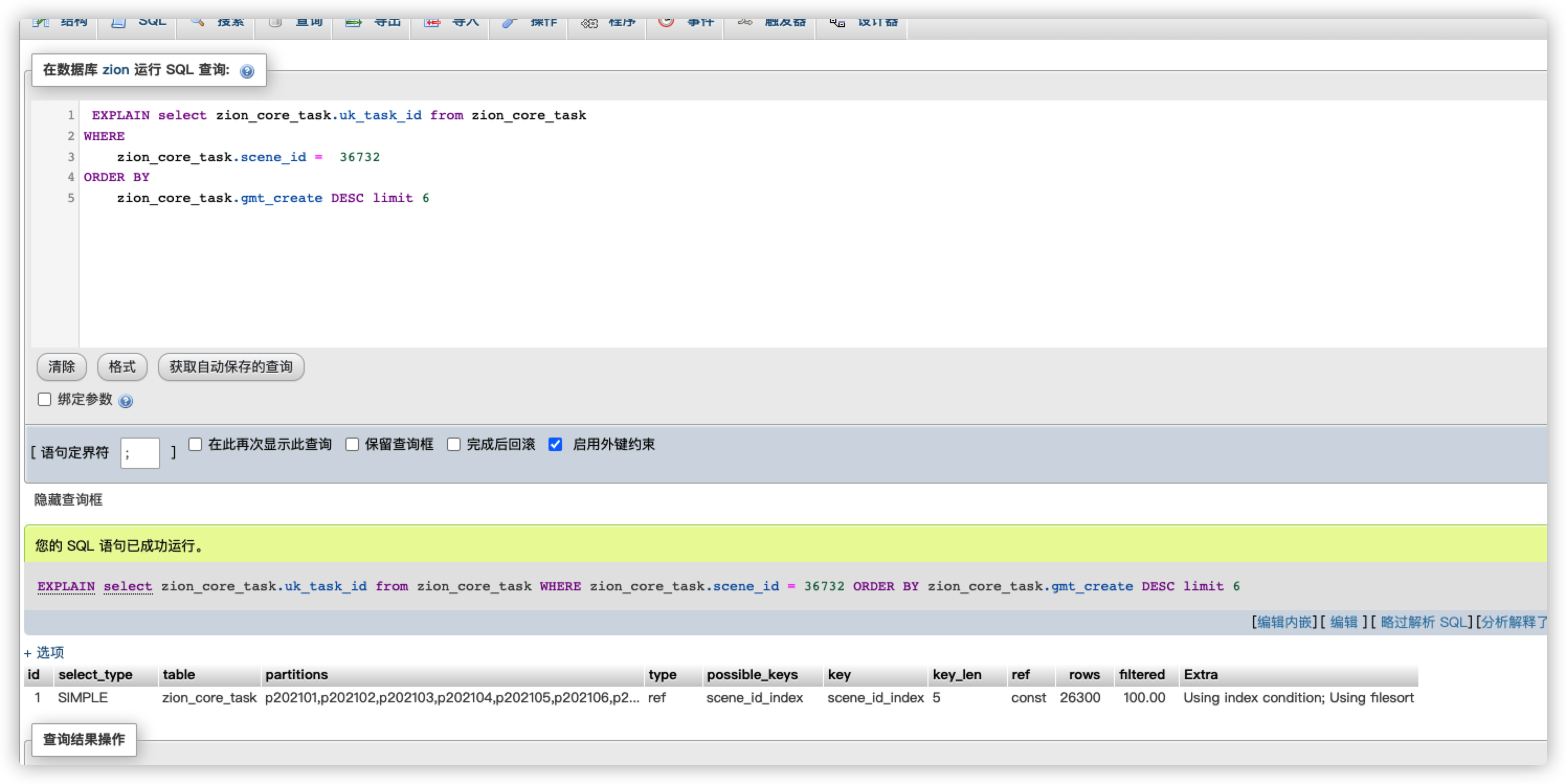
我直接在数据库工具上执行这条sql,果然没有让我失望

啥也不说,直接上执行计划

type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL ,一般来说,得保证查询至少达到range级别,最好能达到ref。
明显我们这条sql和全表扫描没差了,那为什么其他数据没问题呢,我查询了其他数据,执行计划是这样的
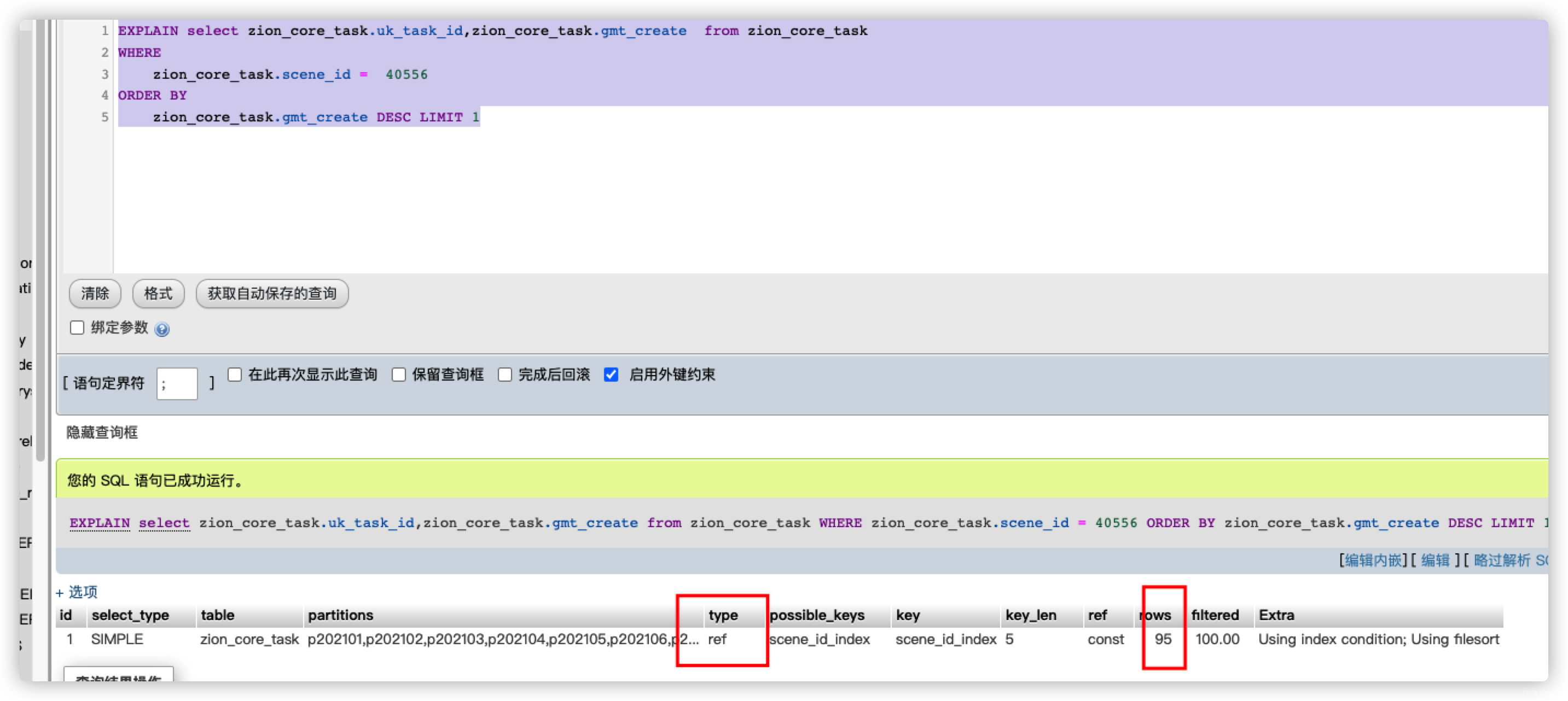
居然是ref,但是影响行只有几十行,没有像我们的目标数据有五千多行,明显得出一个结论,当我们where后的数据量达到一定值后,我们的索引模式就会变更,
在相同的sql下,这个可以说是没问题的,但我墙裂怀疑limit这个东西有鬼,所以我把limit 1去掉再去看执行计划
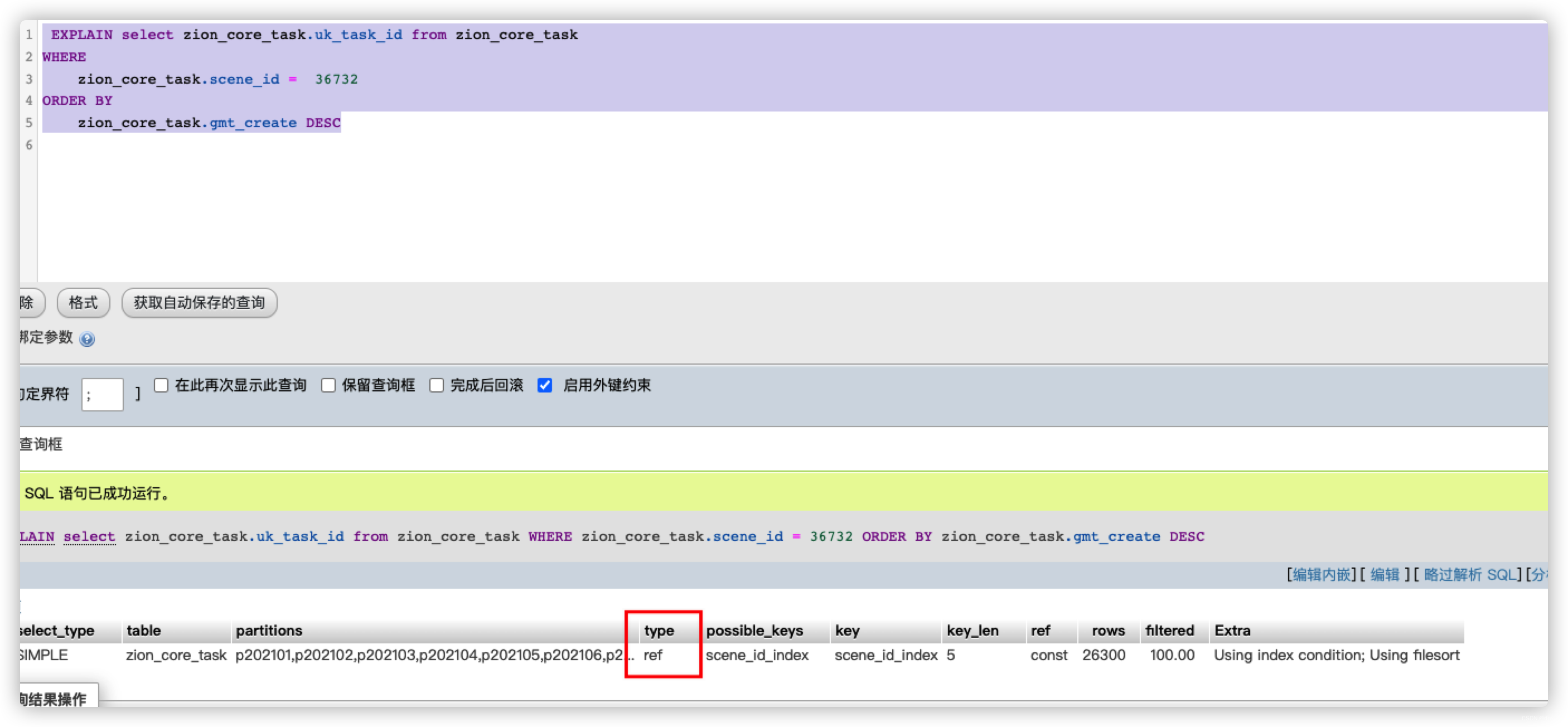
果然有毒,去掉limit后走正常的索引了,之前看过一片文章说mysql的limit会根据后面数据的大小的限制去做不同的优化,经过反复测试,发现在这个数量下当limit=5的时候索引type还是index,为6后则为ref
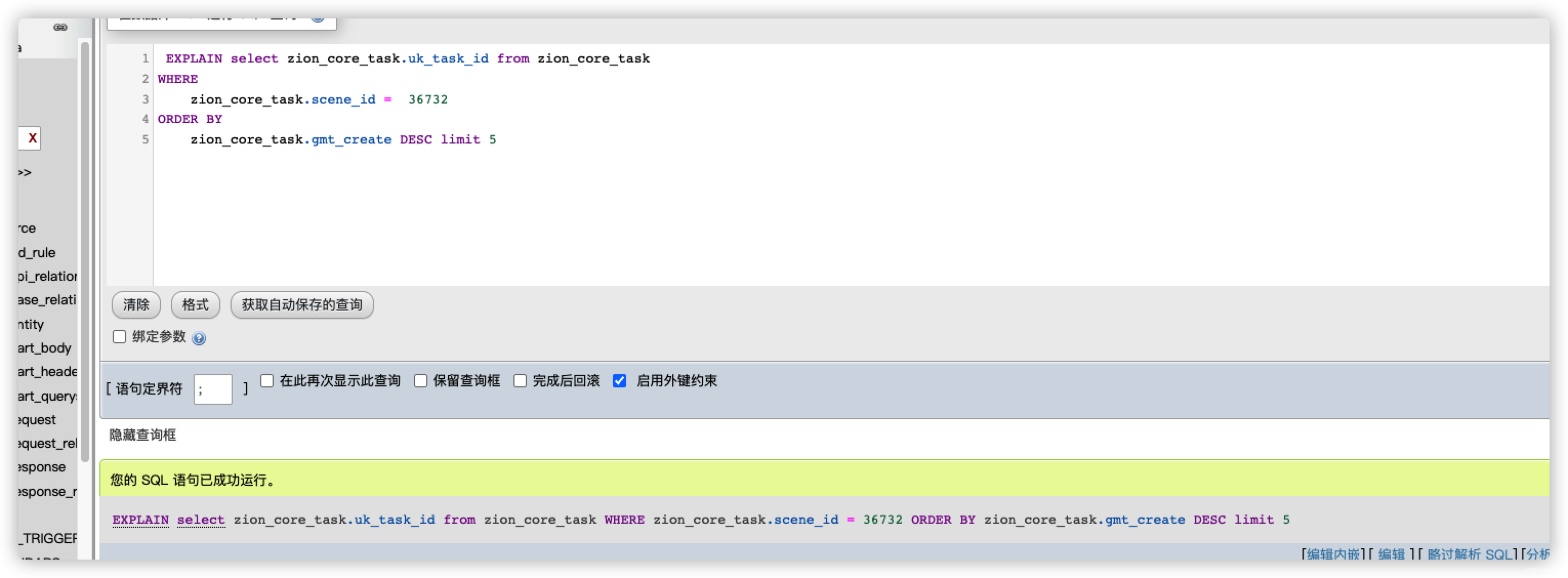
找到问题所在后,我们去查问官方的相关优化
If you combine LIMIT row_count with ORDER BY, MySQL stops sorting as soon as it has found the first row_count rows of the sorted result, rather than sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query without the LIMIT clause are selected, and most or all of them are sorted, before the first row_count are found. After the initial rows have been found, MySQL does not sort any remainder of the result set.
One factor that affects the execution plan is LIMIT, so an ORDER BY query with and without LIMIT may return rows in different orders.
结果很是笼统,反而我是在一篇博客上找到问题所在,大体是limit的存在会影响我们的顺序的变化,它不一定是按照我们设定的先通过where条件取出数据后排序,而可能直接通过排序limit后再与where条件进行匹配,这样就会造成全表扫描
我们回归的问题本身,我们这条sql的原意是取满足条件的最后一条记录,而我们的id是自增的,所以我们可以将sql改成以id作为排序,我们的id聚簇索引本身是有序的,所以能很快的查询到
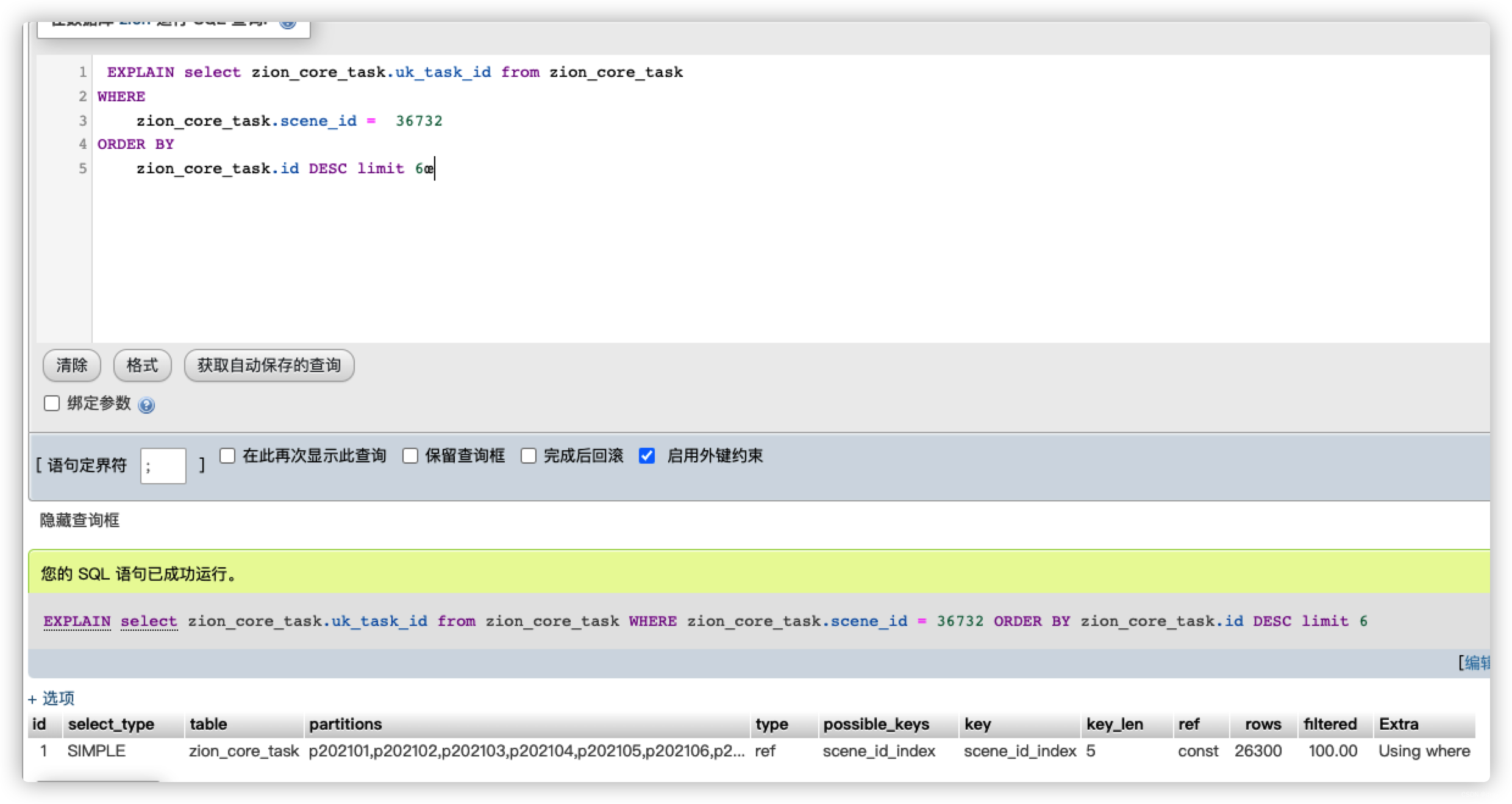
到此问题解决了,在解决过程中我们也遇到其他的问题,比如我们的时间发现是可以重复的,而我们limit 1取到的结果则会是随机的,对我们结果的准确性有影响,同时我们也可以参考博客中的解决方案加联合索引,但是我们当前场景下肯定id排序是最优的方式。