1. 相关问题
存储引擎属于插件式引擎,面试中遇到的可能非常大,下面总结一些常见的问题。
- 说一说了解的mysql 存储引擎及其使用场景?
- 在什么情况下innodb 无法在线修改表结构?
- 在无法进行在线修改表结构的情况下,要如何操作?
- innodb 是如何实现事务的?
- innodb 读操作是否会阻塞写操作?
2. 常用的mysql 存储引擎及使用场景
2.1 mysql 常用存储引擎

2.2 常见存储引擎使用场景
MYISAM 的特点
- 非事务存储引擎 (用到事务场景不适用)
- 以堆表方式存储 (叶子节点直接指向数据物理地址,而不是聚集索引位置,避免二次查找;单从性能看,查询效果myisam 优于innodb)
- 使用表级锁 (读操作会阻塞写操作,写操作也会阻塞读操作;所以不适合高并发场景)
- 支持Btree 索引,空间索引,全文索引
- 在物理机上有两个文件 (xxx.myd【数据文件】 和 xxx.myi 文件【索引文件】)mysql 8.0 版本
MYISAM 使用场景
- 读操作远远大于写操作的场景(不用进行二次查找特点)
- 不需要使用事务的场景
CSV 存储引擎
- 非事务型存储引擎
- 数据以CSV 格式存储
- 所有列都不能为NULL
- 不支持索引
- 可直接编辑数据文件修改存储的数据
CSV 使用场景
- 做为数据交换的中间表使用
Archive 存储引擎
- 非事务型存储引擎
- 表数据使用zlib 压缩
- 只支持insert 和select 操作 (日志)
- 只允许在自增 id 上建立索引
Archive 使用场景
- 日志和数据采集类应用
- 数据归档存储 (不需要更新,只需要的查询)
Memory 存储引擎
- 非事务型存储引擎
- 数据保存在内存中 (易丢失)
- 所有字段的长度固定
- 支持Btree 和 hash 索引
Memory 使用场景
- 用户缓存字典映射表
- 缓存周期性分析数据 (也可使用redis)
innodb 存储引擎
- 事务性存储引擎,支持ACID
- 数据按主键聚集存储 (和堆表方式存储不同)
- 支持行级锁及MVCC (在进行读写操作时,只会对该数据行上加锁;增加了并发能力)(MVCC:多版本并发控制)
- 支持Btree 和 自适应 Hash 索引
- 【5.7 之后】 支持全文和空间索引
innodb 使用场景
- 大多数 OLTP 场景 (联机事务处理(Online Transaction Processing),表示事务性非常高的系统)
NDB 存储引擎
- 事务性存储引擎
- 数据存储在内存中
- 支持行级锁
- 支持高可用集群
- 支持Ttree 索引
NDB 使用场景
- 需要数据完全同步的高可用场景
3. 在什么情况下INNODB 无法在线修改表
3.1 innodb 不支持在线修改表结构的场景

在线ddl 存在的问题
- 有部分语句不支持在线ddl
- 长时间的ddl 操作会引起严重的主从延迟
- 无法对ddl 操作进行资源限制
3.2 如何更安全的在线修改表结构
py-online-schema-change [OPTIONS] DSN
4. innodb 是如何实现事务的?
4.1 什么是事务
经典的例子:在银行汇款需要进行一系列操作,如果当中任何一个操作失败,则这个汇款操作就不能完成。
ACID : 原子性、一致性、隔离性(里面有分为几种)、持久性。

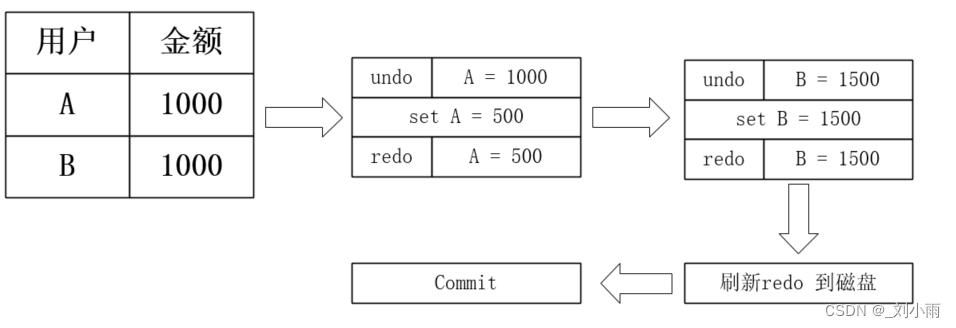
4.2 redo log 和 undo log 在事务实现中的作用
事务的实现方式, 引入了redo log 和undo log 两种日志,在任何事务型存储引擎中,都会有。

汇款例子演示:
卡 A 转账 卡B 500元
5. innodb 读是否会阻塞写?
5.1 读写应该相互阻塞吗?
- 查询需要对资源加共享锁(S)
- 数据修改需要对资源加排它锁(x)

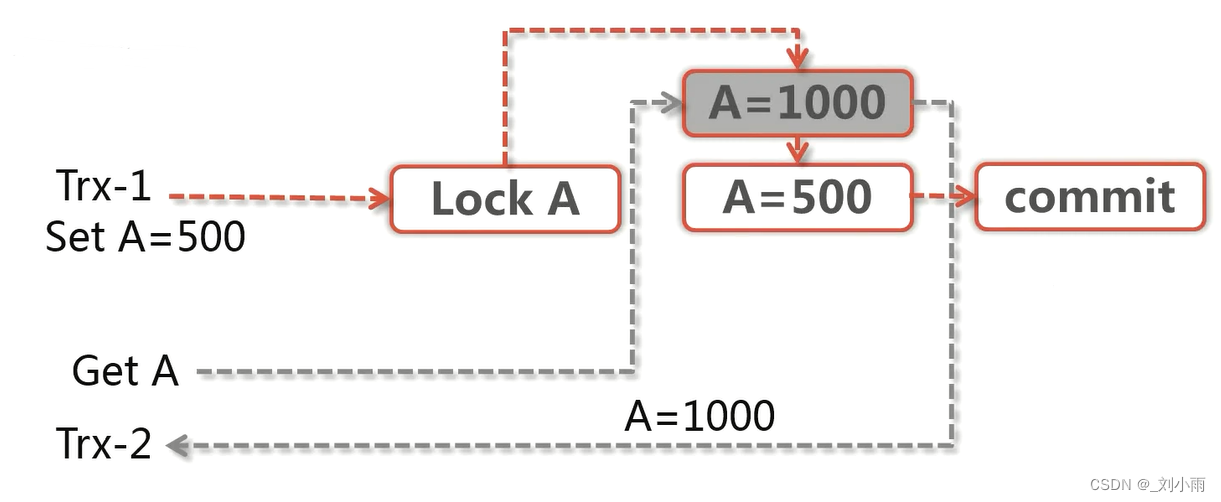
5.2 MVCC (多版本并发控制)
简化一些过程
事务A 修改A = 500, 事务2 查询A 的值
这里事务A 用了排它锁, 然后用undo log 记录 A 原先的值,redo log 记录更新的值;
由于事务A 加了排它锁,事务B 就从undo 中查询到的A 的值, 这里就是可重复读的级别