1、安装DolphinScheduler
2、创建租户信息
注意:租户名称就是Linux的执行命令的用户名称,所以不能出错

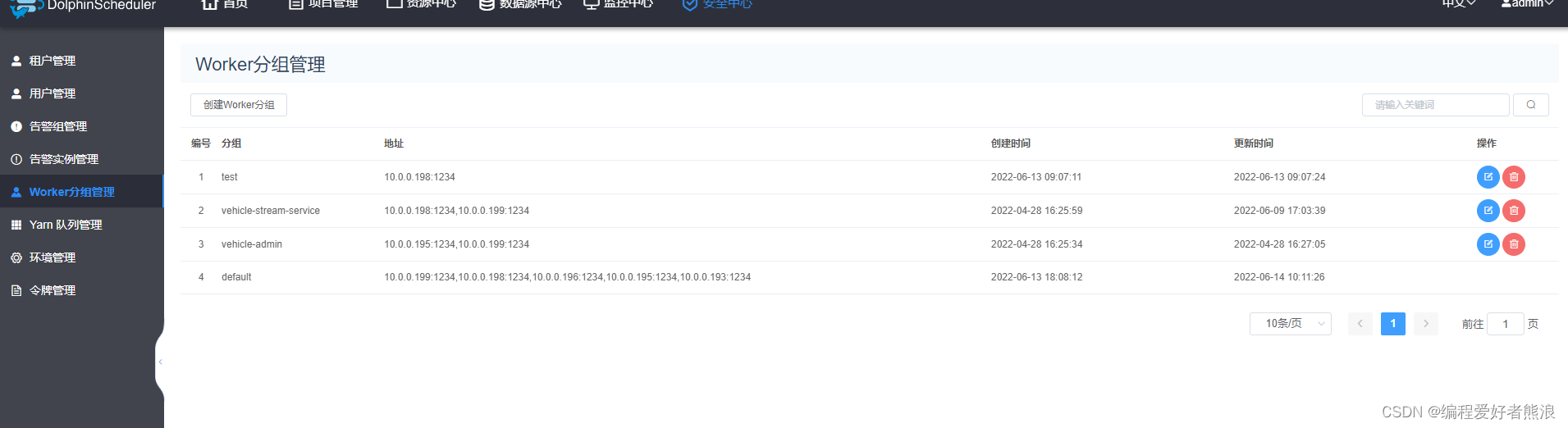
3、根据实际情况确定是否需要创建工作组,存在一个default默认工作组,是当前的所有机器,可以通过组信息来确定定特定的机器执行某个任务,比如DataX插件执行同步任务,可以只在某个机器上安装DataX,之后通过组信息来确定某个安装了同步插件的机器执行同步任务,这样可以降低每台机子上安装的插件个数,但可能会存在,某个机子宕机,任务不能执行的风险
4、环境管理
默认使用 ./dolphinscheduler/conf/env/dolphinscheduler_env.sh文件配置的环境变量信息,可以通过此处指定某个命令使用特定的环境配置信息
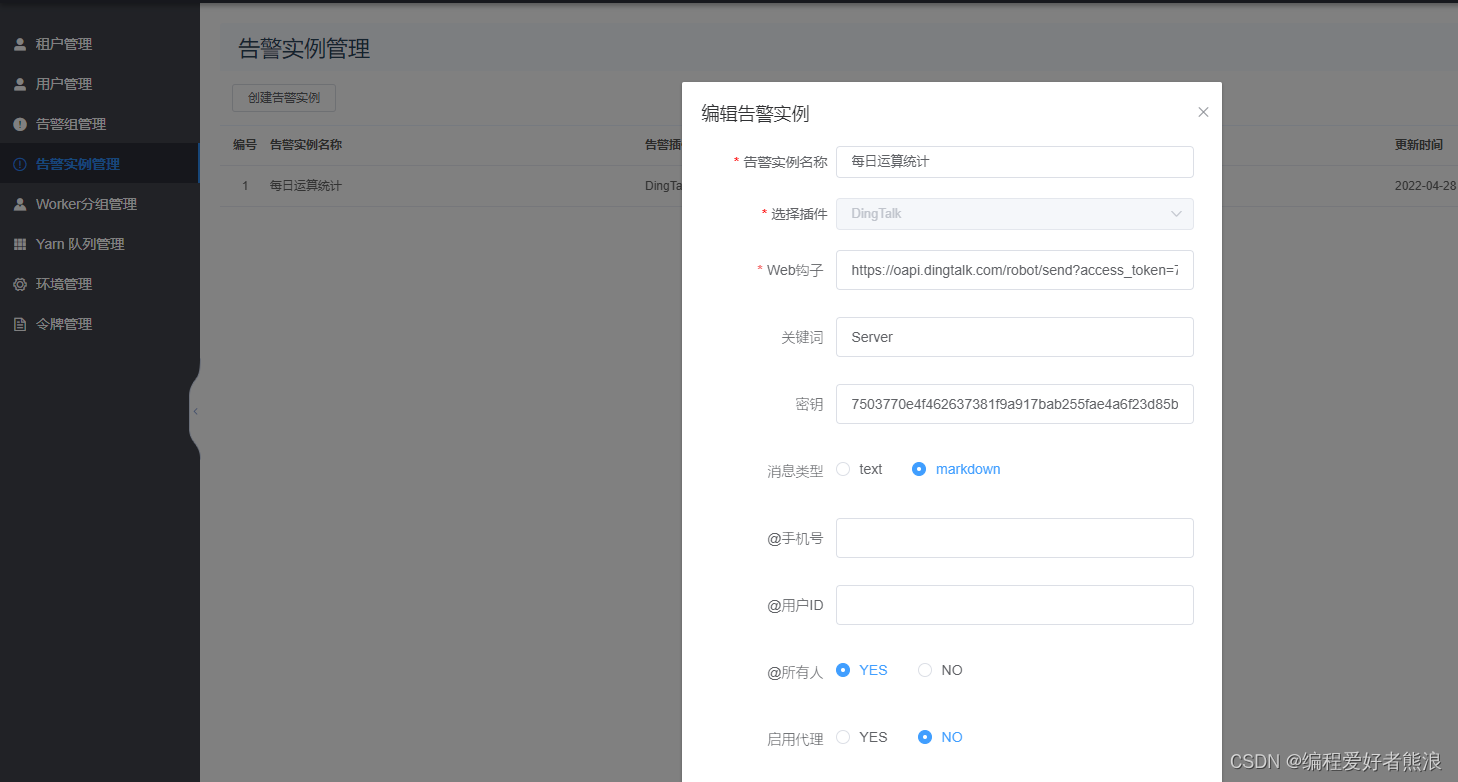
5、告警信息(需要在群里面设置告警机器人)
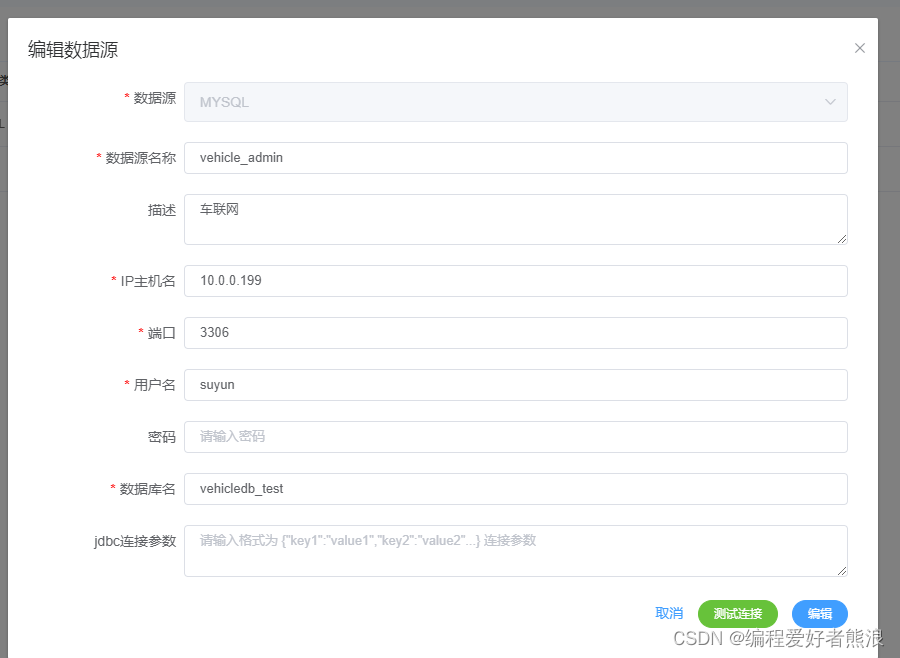
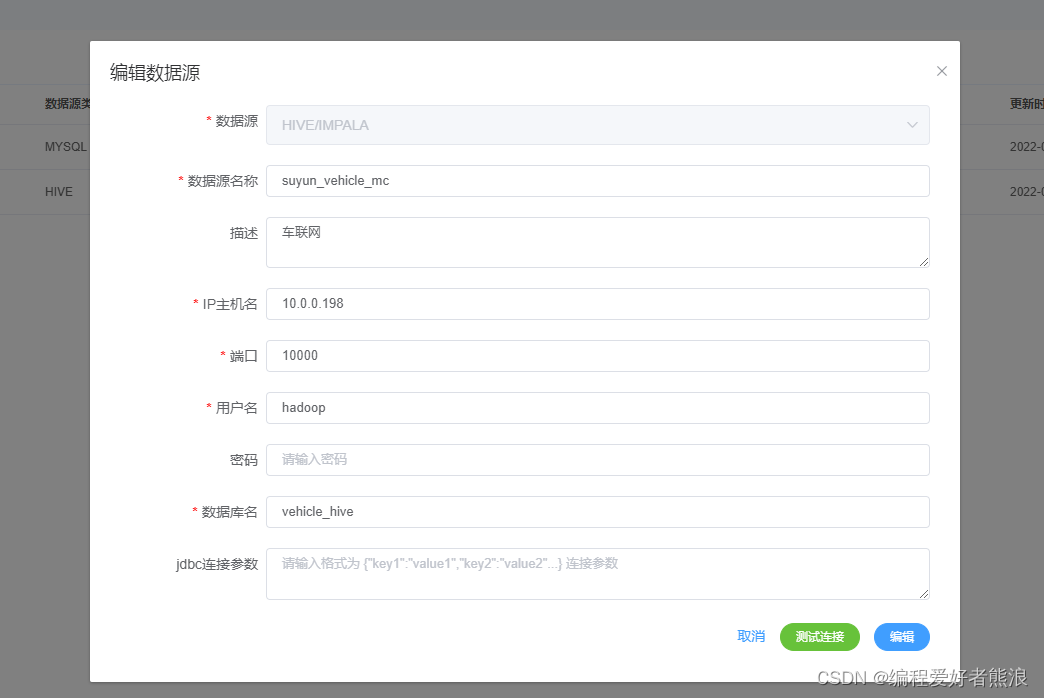
6、创建数据源(可以通过测试连接判断是否设置正确)
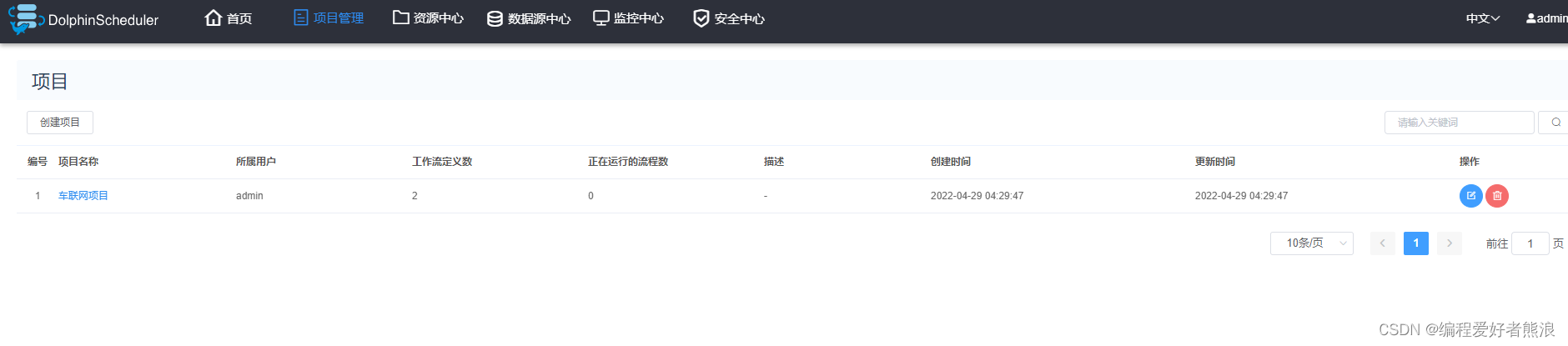
7、新建项目
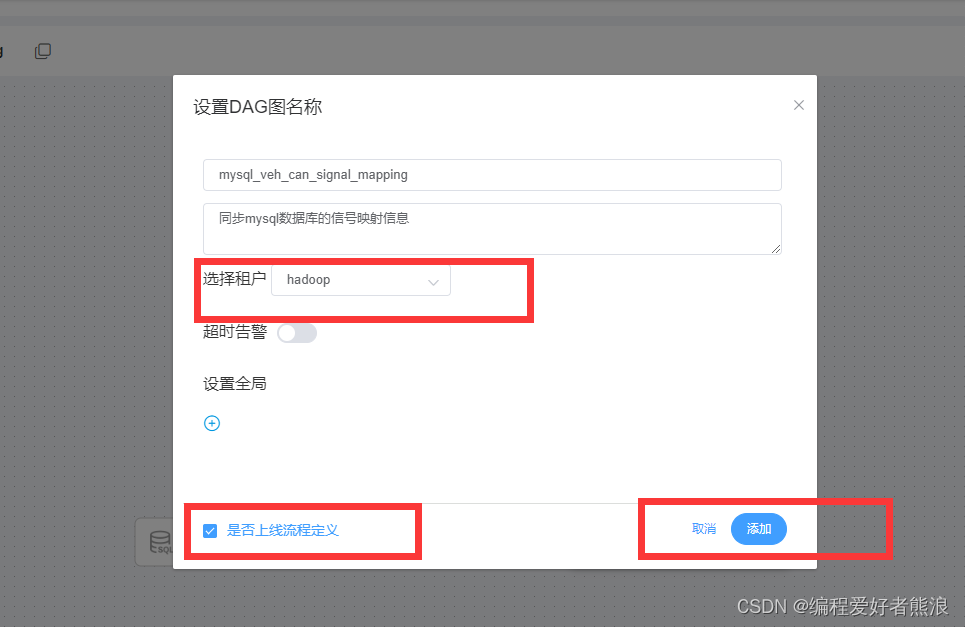
8、点击新建项目,进入流程配置
9、同步Mysql表数据到Hive
注意:
1、Hive语句不需要分号结尾,换行就是一句
2、Mysql需要分号结尾
3、sql类型,SELECT为查询,其余的为费查询
4、租户选择能执行hive语句的租户
5、选择的执行任务组的服务器需要安装DataX
(一)、新增Hive表
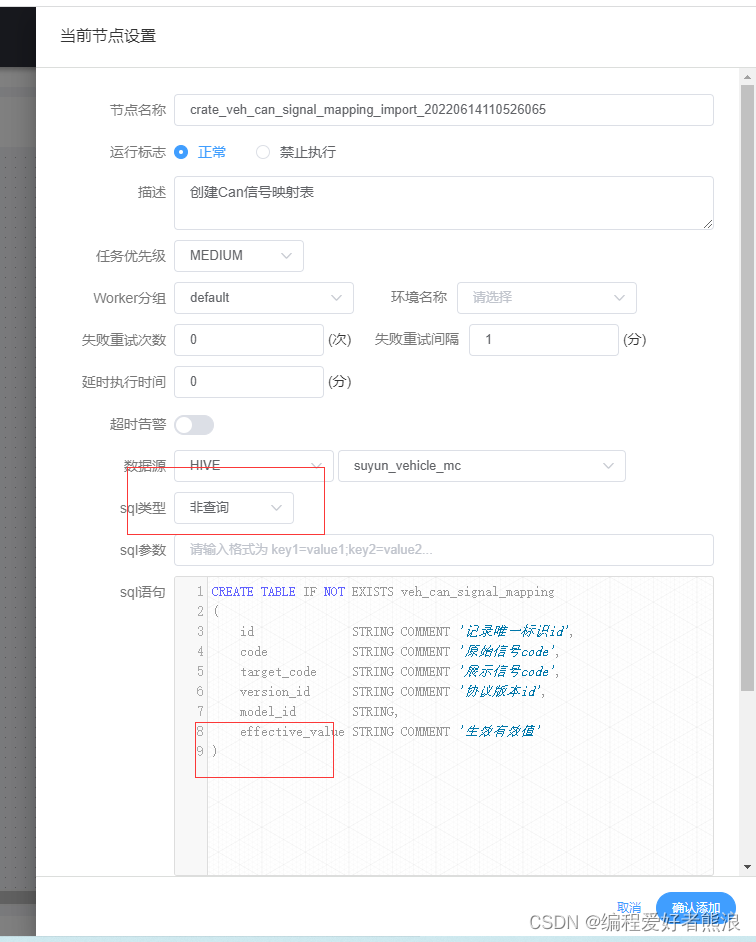
#创建普通表
CREATE TABLE IF NOT EXISTS veh_can_signal_mapping
(
id STRING COMMENT '记录唯一标识id',
code STRING COMMENT '原始信号code',
target_code STRING COMMENT '展示信号code',
version_id STRING COMMENT '协议版本id',
model_id STRING,
effective_value STRING COMMENT '生效有效值'
)
row format delimited
fields terminated by '\t' #列分割符,跟写入文件时的分割符一致
lines terminated by '\n' #行分割符,跟写入文件时的分割符一致
stored as textfile
#创建分区表
CREATE TABLE IF NOT EXISTS t_veh_data_distinct_unzip
(
company_id STRING,
vehicle_id STRING,
timestamp BIGINT,
value STRING,
bucket_id STRING COMMENT '为数据迁移准备,正常情况下可以为空'
)
PARTITIONED BY(dt STRING COMMENT '日期-yyyyMMdd')
row format delimited
fields terminated by '\t' #列分割符,跟写入文件时的分割符一致
lines terminated by '\n' #行分割符,跟写入文件时的分割符一致
stored as textfile
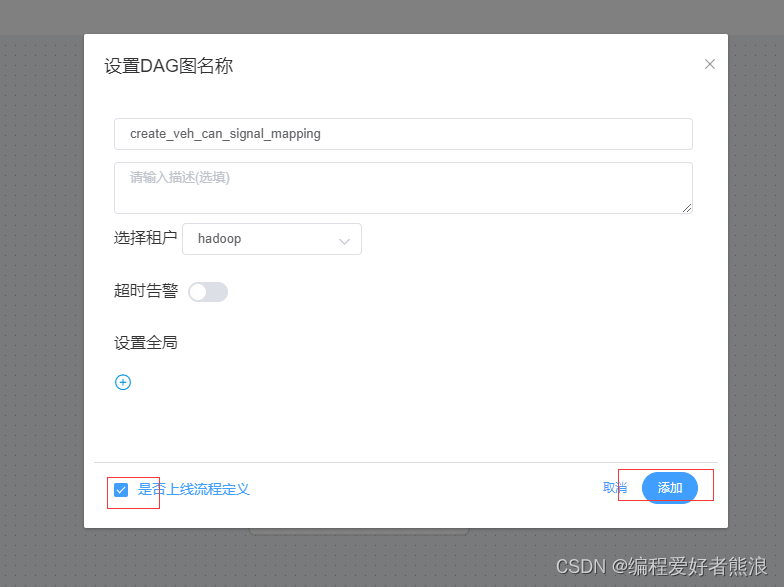
10、执行

通过甘特图查看执行进度

查看状态和日志

11、新增同步任务,清除历史数据(建表也可以在这个流水线上,加上IF NOT EXISTS就可以)
选择SQL
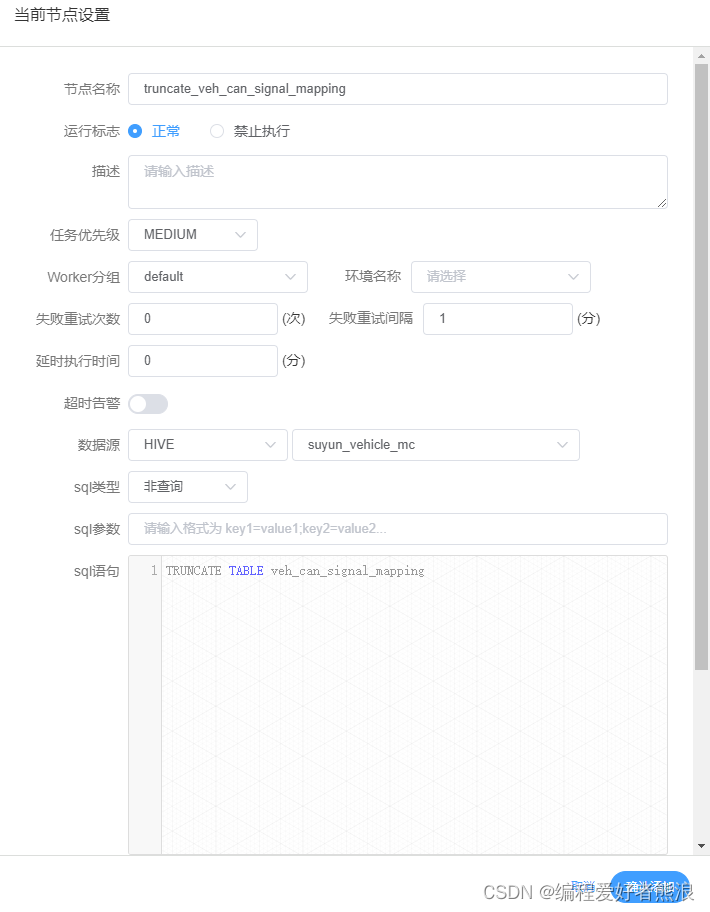
TRUNCATE TABLE veh_can_signal_mapping
INSERT OVERWRITE TABLE t_veh_data_daily;
#分区表覆盖可以使用${bdp.system.bizdate}参数可以换成具体的值
INSERT OVERWRITE TABLE t_veh_data_daily PARTITION(dt='${bdp.system.bizdate}')
选择DataX
没有Hive数据源,所以需要使用自定义模板
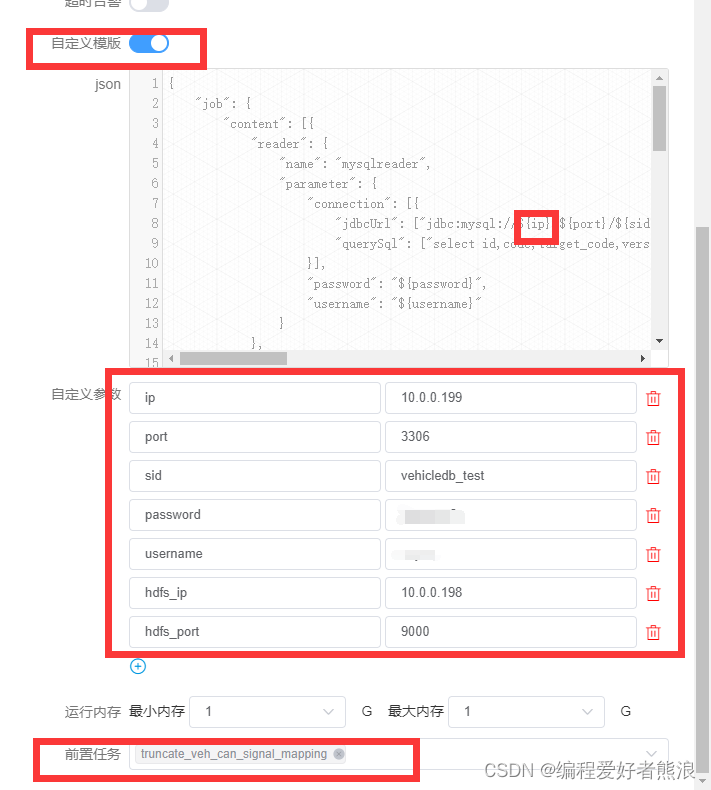
可以参看阿里云的最佳实践编写JSON,DataX是阿里云开源的数据同步工具,阿里云使用的是商业版,但语法很多类似
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [{
"jdbcUrl": ["jdbc:mysql://${ip}:${port}/${sid}?useSSL=false"],
"querySql": ["select id,code,target_code,version_id,model_id,CASE WHEN effective_value IS NULL OR effective_value = '' THEN 'null' ELSE effective_value END effective_value from veh_can_signal_mapping WHERE del_flag = '0' AND target_code IS NOT NULL AND target_code!=''"]
}],
"password": "${password}",
"username": "${username}"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://${hdfs_ip}:${hdfs_port}",
"fileType": "text",
"path": "/data/hadoop/dfs/vehicle_hive.db/veh_can_signal_mapping",
"fileName": "veh_can_signal_mapping",
"column": [{
"name": "id",
"type": "STRING"
}, {
"name": "code",
"type": "STRING"
}, {
"name": "traget_code",
"type": "STRING"
},{
"name": "version_id",
"type": "STRING"
}, {
"name": "model_id",
"type": "STRING"
}, {
"name": "effective_value",
"type": "STRING"
}],
"writeMode": "append",
"fieldDelimiter": "\t",
"encoding": "utf-8"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}