MySQLгХЛЏЗНАИ
ЯыБиДѓМвЖМжЊЕР,УцЪдЦкМфвЛЬсЕНЪ§ОнПт,ОЭЛсСФЕНЪ§ОнПтгХЛЏЯрЙиЮЪЬтЁЃЭјЩЯЙигкЪ§ОнПтгХЛЏЕФЮФеТвВЪЧблЛЈчдТв,ВуГіВЛЧюЁЃНёЬьНЋЛсЭЈЙ§етЦЊЮФеТЯИЗжМИЕуИјДѓМвЛузмећРэГівЛЬзЙигкMySQLЪ§ОнПтЕФгХЛЏЗНАИ,ШУДѓМвЭЈЙ§бЇЯАетЦЊЮФеТВЛдйБЛУцЪдЙйЕѕДђ!

ГЩБО:гВМўгХЛЏ > ЯЕЭГХфжУгХЛЏ > БэНсЙЙгХЛЏ > SQLгяОфгХЛЏ > Ыїв§гХЛЏЁЃ
аЇЙћ:Ыїв§гХЛЏ > SQLгяОфгХЛЏ > БэНсЙЙгХЛЏ > ЯЕЭГХфжУгХЛЏ > гВМўгХЛЏЁЃ
ЮФеТФПТМ
(ЯТУцгЩИпГЩБОЕНЕЭГЩБОЯъЯИНВНтгХЛЏЗНАИ)
вЛ.гВМўгХЛЏ
гВМўгХЛЏЮоЗЧОЭЪЧЖдMySQLЫљдкЕФЗўЮёЦїCPU,ФкДц,ДХХЬНјаагХЛЏЁЃДѓФкДц,ИпIO,ЪЧЯжДњЛљгкwebЕФЪ§ОнПтЕФБиБИ (АйЖШЕФЗўЮёЦїФкДц :96G ЁЊ128Иі,2ИіЪЕР§ ,CPU8ЕН16ПХ)ЁЃВЛЭЌАцБОЕФMySQLЖдЖрКЫCPUЕФжЇГжвВВЛвЛбљЁЃ
ЗўЮёЦїгВМўЖдMySQLадФмЕФгАЯьМАгХЛЏЗНАИ
-
CPUЖдгкMySQLгІгУ,ЭЦМіЪЙгУS.M.P.МмЙЙЕФЖрТЗЖдГЦCPU,Р§Шч:ПЩвдЪЙгУСНПХIntel Xeon 3.6GHzЕФCPU,ЯждкЮвНЯЭЦМігУ4UЕФЗўЮёЦїРДзЈУХзіЪ§ОнПтЗўЮёЦї,ВЛНіНіЪЧеыЖдгкmysqlЁЃ
-
ЮяРэФкДцЖдгквЛЬЈЪЙгУMySQLЕФDatabase ServerРДЫЕ,ЗўЮёЦїФкДцНЈвщВЛвЊаЁгк2GB,ЭЦМіЪЙгУ4GBвдЩЯЕФЮяРэФкДц,ВЛЙ§ФкДцЖдгкЯждкЕФЗўЮёЦїЖјбдПЩвдЫЕЪЧвЛИіПЩвдКіТдЕФЮЪЬт,ЙЄзїжагіЕНСЫИпЖЫЗўЮёЦїЛљБОЩЯФкДцЖМГЌЙ§СЫ16GЁЃ
-
ДХХЬбАЕРФмСІ(ДХХЬI/O),вдФПЧАИпзЊЫйSCSIгВХЬ(7200зЊ/Уы)ЮЊР§,етжжгВХЬРэТлЩЯУПУыбАЕР7200ДЮ,етЪЧЮяРэЬиадОіЖЈЕФ,УЛгаАьЗЈИФБфЁЃMySQLУПУыжгЖМдкНјааДѓСПЁЂИДдгЕФВщбЏВйзї,ЖдДХХЬЕФЖСаДСППЩЯыЖјжЊЁЃЫљвд,ЭЈГЃШЯЮЊДХХЬI/OЪЧжЦдМMySQLадФмЕФзюДѓвђЫижЎвЛ,ЖдгкШеОљЗУЮЪСПдк100ЭђPVвдЩЯЕФЯЕЭГ,гЩгкДХХЬI/OЕФжЦдМ,MySQLЕФадФмЛсЗЧГЃЕЭЯТ!НтОіетвЛжЦдМвђЫиПЩвдПМТЧвдЯТМИжжНтОіЗНАИ: ЪЙгУRAID-0+1ДХХЬеѓСа,зЂвтВЛвЊГЂЪдЪЙгУRAID-5,MySQLдкRAID-5ДХХЬеѓСаЩЯЕФаЇТЪВЛЛсЯёФуЦкД§ЕФФЧбљПьЁЃ
зЂвт:вдЩЯетаЉЙцЛЎгІИУдкГѕЪМЩшМЦЯЕЭГЪБОЭгІИУПМТЧКУЁЃ
Жў.ЯЕЭГХфжУгХЛЏ
ЛљБОХфжУ
ЕБШЛЛЙгаЦфЫћЕФЩшжУПЩвдЦ№зїгУ,ШЁОігкФуЕФИКдиЛђгВМў:дкТ§ФкДцКЭПьДХХЬЁЂИпВЂЗЂКЭаДУмМЏаЭИКдиЧщПіЯТ,ФуНЋашвЊЬиЪтЕФЕїећЁЃШЛЖјетРяЕФФПБъЪЧЪЙЕУФуПЩвдПьЫйЕиЛёЕУвЛИіЮШНЁЕФMySQLХфжУ,ЖјВЛгУЛЈЗбЬЋЖрЪБМфдкЕїећвЛаЉЮоЙиНєвЊЕФMySQLЩшжУЛђЖСЮФЕЕевГіФФаЉЩшжУЖдФуРДЫЕКмживЊЩЯЁЃ
LinuxЯЕЭГжаMySQlХфжУЮФМўвЛАуЮЛгк/etc/my.cnf
innodb_buffer_pool_size
етЪЧФуАВзАЭъInnoDBКѓЕквЛИігІИУЩшжУЕФбЁЯюЁЃЛКГхГиЪЧЪ§ОнКЭЫїв§ЛКДцЕФЕиЗНЁЃФЌШЯДѓаЁЮЊ128MЁЃетИіжЕдНДѓдНКУОігкCPUЕФМмЙЙ,етФмБЃжЄФудкДѓЖрЪ§ЕФЖСШЁВйзїЪБЪЙгУЕФЪЧФкДцЖјВЛЪЧгВХЬЁЃЕфаЭЕФжЕЪЧ5-6GB(8GBФкДц),20-25GB(32GBФкДц),100-120GB(128GBФкДц)ЁЃ
innodb_log_file_size
етЪЧredoШежОЕФДѓаЁЁЃredoШежОБЛгУгкШЗБЃаДВйзїПьЫйЖјПЩППВЂЧвдкБРРЃЪБЛжИДЁЃвЛжБЕНMySQL 5.1,ЫќЖМФбгкЕїећ,вђЮЊвЛЗНУцФуЯыШУЫќИќДѓРДЬсИпадФм,СэвЛЗНУцФуЯыШУЫќИќаЁРДЪЙЕУБРРЃКѓИќПьЛжИДЁЃавдЫЕФЪЧДгMySQL 5.5жЎКѓ,БРРЃЛжИДЕФадФмЕФЕНСЫКмДѓЬсЩ§,етбљФуОЭПЩвдЭЌЪБгЕгаНЯИпЕФаДШыадФмКЭБРРЃЛжИДадФмСЫЁЃвЛжБЕНMySQL 5.5,redoШежОЕФзмГпДчБЛЯоЖЈдк4GB(ФЌШЯПЩвдга2ИіlogЮФМў)ЁЃетдкMySQL 5.6РяБЛЬсИпЁЃвЛПЊЪМОЭАбinnodb_log_file_sizeЩшжУГЩ512M(етбљга1GBЕФredoШежО)ЛсЪЙФугаГфдЃЕФаДВйзїПеМфЁЃШчЙћФужЊЕРФуЕФгІгУГЬађашвЊЦЕЗБЕФаДШыЪ§ОнВЂЧвФуЪЙгУЕФЪБMySQL 5.6,ФуПЩвдвЛПЊЪМОЭАбЫќЩшжУГЩ4GЁЃ
max_connections
ШчЙћФуОГЃПДЕНToo many connectionsДэЮѓ,ЪЧвђЮЊmax_connectionsЕФжЕЬЋЕЭСЫЁЃетЗЧГЃГЃМћвђЮЊгІгУГЬађУЛгае§ШЗЕФЙиБеЪ§ОнПтСЌНг,ФуашвЊБШФЌШЯЕФ151СЌНгЪ§ИќДѓЕФжЕЁЃmax_connectionжЕБЛЩшИпСЫ(Р§Шч1000ЛђИќИп)жЎКѓвЛИіжївЊШБЯнЪЧЕБЗўЮёЦїдЫаа1000ИіЛђИќИпЕФЛюЖЏЪТЮёЪБЛсБфЕФУЛгаЯьгІЁЃдкгІгУГЬађРяЪЙгУСЌНгГиЛђепдкMySQLРяЪЙгУНјГЬГигажњгкНтОіетвЛЮЪЬтЁЃ
InnoDBХфжУ
ДгMySQL 5.5АцБОПЊЪМ,InnoDBОЭЪЧФЌШЯЕФДцДЂв§ЧцВЂЧвЫќБШШЮКЮЦфЫћДцДЂв§ЧцЕФЪЙгУЖМвЊЖрЕУЖрЁЃФЧвВЪЧЮЊЪВУДЫќашвЊаЁаФХфжУЕФдвђЁЃ
innodb_file_per_table
етЯюЩшжУИцжЊInnoDBЪЧЗёашвЊНЋЫљгаБэЕФЪ§ОнКЭЫїв§ДцЗХдкЙВЯэБэПеМфРя(innodb_file_per_table = OFF) ЛђепЮЊУПеХБэЕФЪ§ОнЕЅЖРЗХдквЛИі.ibdЮФМў(innodb_file_per_table = ON)ЁЃУПеХБэвЛИіЮФМўдЪаэФудкdropЁЂtruncateЛђепrebuildБэЪБЛиЪеДХХЬПеМфЁЃетЖдгквЛаЉИпМЖЬиадвВЪЧгаБивЊЕФ,БШШчЪ§ОнбЙЫѕЁЃЕЋЪЧЫќВЛЛсДјРДШЮКЮадФмЪевцЁЃФуВЛЯыШУУПеХБэвЛИіЮФМўЕФжївЊГЁОАЪЧ:гаЗЧГЃЖрЕФБэ(БШШч10k+)ЁЃ
MySQL 5.6жа,етИіЪєадФЌШЯжЕЪЧON,вђДЫДѓВПЗжЧщПіЯТФуЪВУДЖМВЛашвЊзіЁЃЖдгкжЎЧАЕФАцБОФуБиашдкМгдиЪ§ОнжЎЧАНЋетИіЪєадЩшжУЮЊON,вђЮЊЫќжЛЖдаТДДНЈЕФБэгагАЯьЁЃ
innodb_flush_log_at_trx_commit
ФЌШЯжЕЮЊ1,БэЪОInnoDBЭъШЋжЇГжACIDЬиадЁЃЕБФуЕФжївЊЙизЂЕуЪЧЪ§ОнАВШЋЕФЪБКђетИіжЕЪЧзюКЯЪЪЕФ,БШШчдквЛИіжїНкЕуЩЯЁЃЕЋЪЧЖдгкДХХЬ(ЖСаД)ЫйЖШНЯТ§ЕФЯЕЭГ,ЫќЛсДјРДКмОоДѓЕФПЊЯњ,вђЮЊУПДЮНЋИФБфflushЕНredoШежОЖМашвЊЖюЭтЕФfsyncsЁЃНЋЫќЕФжЕЩшжУЮЊ2ЛсЕМжТВЛЬЋПЩПП(reliable)вђЮЊЬсНЛЕФЪТЮёНіНіУПУыВХflushвЛДЮЕНredoШежО,ЕЋЖдгквЛаЉГЁОАЪЧПЩвдНгЪмЕФ,БШШчЖдгкжїНкЕуЕФБИЗнНкЕуетИіжЕЪЧПЩвдНгЪмЕФЁЃШчЙћжЕЮЊ0ЫйЖШОЭИќПьСЫ,ЕЋдкЯЕЭГБРРЃЪБПЩФмЖЊЪЇвЛаЉЪ§Он:жЛЪЪгУгкБИЗнНкЕуЁЃ
innodb_flush_method
етЯюХфжУОіЖЈСЫЪ§ОнКЭШежОаДШыгВХЬЕФЗНЪНЁЃвЛАуРДЫЕ,ШчЙћФугагВМўRAIDПижЦЦї,ВЂЧвЦфЖРСЂЛКДцВЩгУwrite-backЛњжЦ,ВЂгазХЕчГиЖЯЕчБЃЛЄ,ФЧУДгІИУЩшжУХфжУЮЊO_DIRECT;Зёдђ,ДѓЖрЪ§ЧщПіЯТгІНЋЦфЩшЮЊfdatasync(ФЌШЯжЕ)ЁЃsysbenchЪЧвЛИіПЩвдАяжњФуОіЖЈетИібЁЯюЕФКУЙЄОпЁЃ
innodb_log_buffer_size
етЯюХфжУОіЖЈСЫЮЊЩаЮДжДааЕФЪТЮёЗжХфЕФЛКДцЁЃЦфФЌШЯжЕ(1MB)вЛАуРДЫЕвбОЙЛгУСЫ,ЕЋЪЧШчЙћФуЕФЪТЮёжаАќКЌгаЖўНјжЦДѓЖдЯѓЛђепДѓЮФБОзжЖЮЕФЛА,етЕуЛКДцКмПьОЭЛсБЛЬюТњВЂДЅЗЂЖюЭтЕФI/OВйзїЁЃПДПДInnodb_log_waitsзДЬЌБфСП,ШчЙћЫќВЛЪЧ0,діМгinnodb_log_buffer_sizeЁЃ
ЦфЫќЩшжУ
query_cache_size
query cache(ВщбЏЛКДц)ЪЧвЛИіжкЫљжмжЊЕФЦПОБ,ЩѕжСдкВЂЗЂВЂВЛЖрЕФЪБКђвВЪЧШчДЫЁЃ зюМббЁЯюЪЧНЋЦфДгвЛПЊЪМОЭЭЃгУ,ЩшжУquery_cache_size = 0(ЯждкMySQL 5.6ЕФФЌШЯжЕ)ВЂРћгУЦфЫћЗНЗЈМгЫйВщбЏ:гХЛЏЫїв§ЁЂдіМгПНБДЗжЩЂИКдиЛђепЦєгУЖюЭтЕФЛКДц(БШШчmemcacheЛђredis)ЁЃШчЙћФувбОЮЊФуЕФгІгУЦєгУСЫquery cacheВЂЧвЛЙУЛгаЗЂЯжШЮКЮЮЪЬт,query cacheПЩФмЖдФугагУЁЃетЪЧШчЙћФуЯыЭЃгУЫќ,ФЧОЭЕУаЁаФСЫЁЃ
log_bin
ШчЙћФуЯыШУЪ§ОнПтЗўЮёЦїГфЕБжїНкЕуЕФБИЗнНкЕу,ФЧУДПЊЦєЖўНјжЦШежОЪЧБиаыЕФЁЃШчЙћетУДзіСЫжЎКѓ,ЛЙБ№ЭќСЫЩшжУserver_idЮЊвЛИіЮЈвЛЕФжЕЁЃОЭЫужЛгавЛИіЗўЮёЦї,ШчЙћФуЯызіЛљгкЪБМфЕуЕФЪ§ОнЛжИД,ет(ПЊЦєЖўНјжЦШежО)вВЪЧКмгагУЕФ:ДгФузюНќЕФБИЗнжаЛжИД(ШЋСПБИЗн),ВЂгІгУЖўНјжЦШежОжаЕФаоИФ(діСПБИЗн)ЁЃЖўНјжЦШежОвЛЕЉДДНЈОЭНЋгРОУБЃДцЁЃЫљвдШчЙћФуВЛЯыШУДХХЬПеМфКФОЁ,ФуПЩвдгУ PURGE BINARY LOGS РДЧхГ§ОЩЮФМў,ЛђепЩшжУ expire_logs_days РДжИЖЈЙ§ЖрЩйЬьШежОНЋБЛздЖЏЧхГ§ЁЃ
МЧТМЖўНјжЦШежОВЛЪЧУЛгаПЊЯњЕФ,ЫљвдШчЙћФудквЛИіЗЧжїНкЕуЕФИДжЦНкЕуЩЯВЛашвЊЫќЕФЛА,ФЧУДНЈвщЙиБеетИібЁЯюЁЃ
skip_name_resolve
ЕБПЭЛЇЖЫСЌНгЪ§ОнПтЗўЮёЦїЪБ,ЗўЮёЦїЛсНјаажїЛњУћНтЮі,ВЂЧвЕБDNSКмТ§ЪБ,НЈСЂСЌНгвВЛсКмТ§ЁЃвђДЫНЈвщдкЦєЖЏЗўЮёЦїЪБЙиБеskip_name_resolveбЁЯюЖјВЛНјааDNSВщевЁЃЮЈвЛЕФОжЯоЪЧжЎКѓGRANTгяОфжажЛФмЪЙгУIPЕижЗСЫ,вђДЫдкЬэМгетЯюЩшжУЕНвЛИівбгаЯЕЭГжаБиаыИёЭтаЁаФЁЃ
Ш§.БэНсЙЙгХЛЏ
гЩгкMySQLЪ§ОнПтЪЧЛљгкаа(Row)ДцДЂЕФЪ§ОнПт,ЖјЪ§ОнПтВйзї IO ЕФЪБКђЪЧвдpage(block)ЕФЗНЪН,вВОЭЪЧЫЕ,ШчЙћЮвУЧУПЬѕМЧТМЫљеМгУЕФПеМфСПМѕаЁ,ОЭЛсЪЙУПИіpageжаПЩДцЗХЕФЪ§ОнааЪ§діДѓ,ФЧУДУПДЮ IO ПЩЗУЮЪЕФааЪ§вВОЭдіЖрСЫЁЃЗДЙ§РДЫЕ,ДІРэЯрЭЌааЪ§ЕФЪ§Он,ашвЊЗУЮЪЕФpageОЭЛсМѕЩй,вВОЭЪЧ IO ВйзїДЮЪ§НЕЕЭ,жБНгЬсЩ§адФмЁЃ
ДЫЭт,гЩгкЮвУЧЕФФкДцЪЧгаЯоЕФ,діМгУПИіpageжаДцЗХЕФЪ§ОнааЪ§,ОЭЕШгкдіМгУПИіФкДцПщЕФЛКДцЪ§ОнСП,ЭЌЪБЛЙЛсЬсЩ§ФкДцЛЛжаЪ§ОнУќжаЕФМИТЪ,вВОЭЪЧЛКДцУќжаТЪЁЃ
Ъ§ОнРраЭЕФбЁдё
Ъ§ОнПтВйзїжазюЮЊКФЪБЕФВйзїОЭЪЧIOДІРэ,ДѓВПЗжЪ§ОнПтВйзї 90% вдЩЯЕФЪБМфЖМЛЈдкСЫIOЖСаДЩЯУцЁЃЫљвдОЁПЩФмМѕЩйIOЖСаДСП,ПЩвддкКмДѓГЬЖШЩЯЬсИпЪ§ОнПтВйзїЕФадФмЁЃ
ЮвУЧЮоЗЈИФБфЪ§ОнПтжаашвЊДцДЂЕФЪ§Он,ЕЋЪЧЮвУЧПЩвддкетаЉЪ§ОнЕФДцДЂЗНЪНЗНУцЛЈвЛаЉаФЫМЁЃЯТУцЕФетаЉЙигкзжЖЮРраЭЕФгХЛЏНЈвщжївЊЪЪгУгкМЧТМЬѕЪ§НЯЖр,Ъ§ОнСПНЯДѓЕФГЁОА,вђЮЊОЋЯИЛЏЕФЪ§ОнРраЭЩшжУПЩФмДјРДЮЌЛЄГЩБОЕФЬсИп,Й§ЖШгХЛЏвВПЩФмЛсДјРДЦфЫћЕФЮЪЬтЁЃ
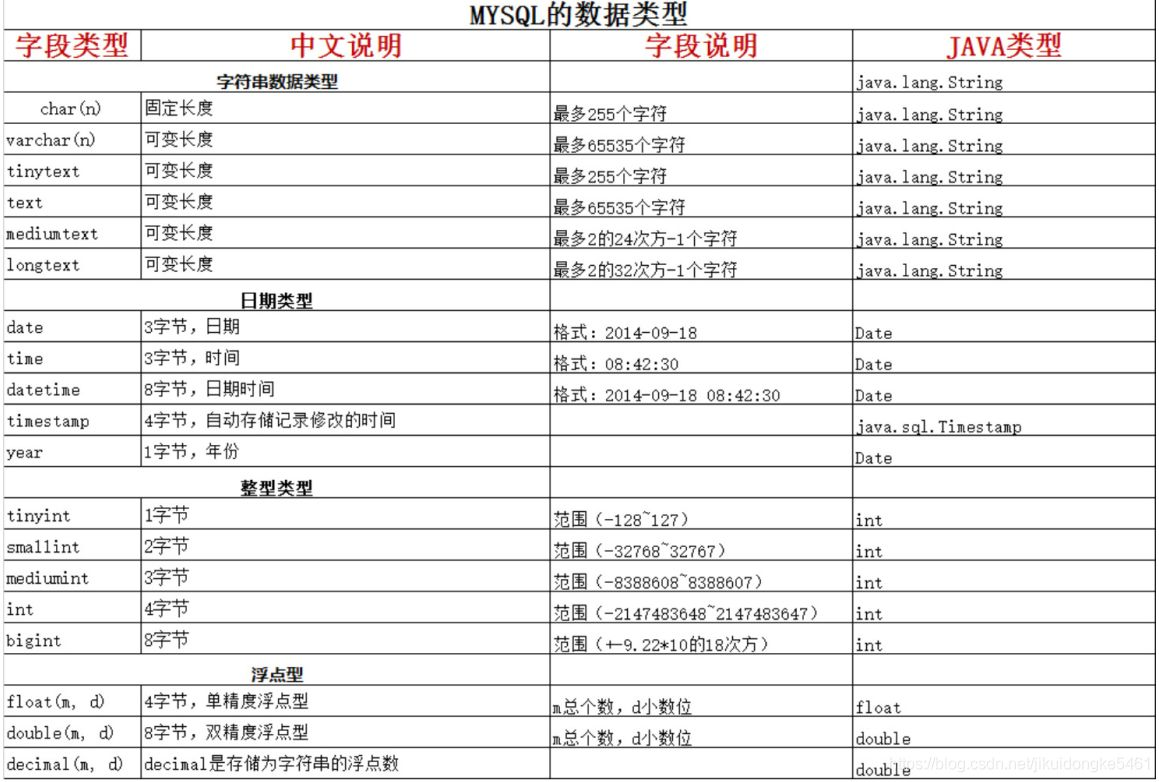
Ъ§зжРраЭ
ЗЧЭђВЛЕУвбВЛвЊЪЙгУdouble,ВЛНіНіжЛЪЧДцДЂГЄЖШЕФЮЪЬт,ЭЌЪБЛЙЛсДцдкОЋШЗадЕФЮЪЬтЁЃ
ЭЌбљ,ЙЬЖЈОЋЖШЕФаЁЪ§,вВВЛНЈвщЪЙгУdecimal,НЈвщГЫвдЙЬЖЈБЖЪ§зЊЛЛГЩећЪ§ДцДЂ,ПЩвдДѓДѓНкЪЁДцДЂПеМф,ЧвВЛЛсДјРДШЮКЮИНМгЮЌЛЄГЩБОЁЃ
ЖдгкећЪ§ЕФДцДЂ,дкЪ§ОнСПНЯДѓЕФЧщПіЯТ,НЈвщЧјЗжПЊ tinyint / int / bigint ЕФбЁдё,вђЮЊШ§епЫљеМгУЕФДцДЂПеМфвВгаКмДѓЕФВюБ№,ФмШЗЖЈВЛЛсЪЙгУИКЪ§ЕФзжЖЮ,НЈвщЬэМгunsignedЖЈвхЁЃЕБШЛ,ШчЙћЪ§ОнСПНЯаЁЕФЪ§ОнПт,вВПЩвдВЛгУбЯИёЧјЗжШ§ИіећЪ§РраЭЁЃ
зжЗћРраЭ
ЗЧЭђВЛЕУвбВЛвЊЪЙгУ text Ъ§ОнРраЭ,ЦфДІРэЗНЪНОіЖЈСЫЫќЕФадФмвЊЕЭгкcharЛђепЪЧvarcharРраЭЕФДІРэЁЃ
ЖдгкГЄЖШЙЬЖЈЕФзжЖЮ,НЈвщЪЙгУ char РраЭ,ВЛЖЈГЄЖШзжЖЮОЁСПЪЙгУ varchar,ЧвНіНіЩшЖЈЪЪЕБЕФзюДѓГЄЖШ,ЖјВЛЪЧЗЧГЃЫцвтЕФИјвЛИіКмДѓЕФзюДѓГЄЖШЯоЖЈ,вђЮЊВЛЭЌЕФГЄЖШЗЖЮЇ,MySQLвВЛсгаВЛвЛбљЕФДцДЂДІРэЁЃ
(зЂвт:char(n) ВЛЙмИУзжЖЮЪЧЗёДцДЂЪ§Он,ЖМеМnИізжЗћЕФДцДЂПеМф;varchar ВЛДцЕФЪБКђВЛеМПеМф,ДцЖрГЄЪ§ОнОЭеМЖрЩйПеМф,ПЩвдНкЪЁДцДЂПеМфЁЃ)
ЪБМфРраЭ
ОЁСПЪЙгУtimestampРраЭ,вђЮЊЦфДцДЂПеМфжЛашвЊ datetimeРраЭЕФвЛАыЁЃЕЋЪЧtimestampДцДЂЕФЪ§ОнЫљвдБЛЯожЦдкСЫ1970~2038ФъжЎФкЁЃ
ЖдгкжЛашвЊОЋШЗЕНФГвЛЬьЕФЪ§ОнРраЭ,НЈвщЪЙгУdateРраЭ,вђЮЊЫћЕФДцДЂПеМфжЛашвЊ3ИізжНк,БШtimestampЛЙЩйЁЃ
enumгыset
ЖдгкзДЬЌзжЖЮ,ПЩвдГЂЪдЪЙгУenumРДДцЗХ,вђЮЊПЩвдМЋДѓЕФНЕЕЭДцДЂПеМф,ЖјЧвМДЪЙашвЊдіМгаТЕФРраЭ,жЛвЊдіМггкФЉЮВ,аоИФНсЙЙвВВЛашвЊжиНЈБэЪ§ОнЁЃ
ШчЙћЪЧДцЗХПЩдЄЯШЖЈвхЕФЪєадЪ§ОнФи?ПЩвдГЂЪдЪЙгУsetРраЭ,МДЪЙДцдкЖржжЪєад,ЭЌбљПЩвдгЮШагагр,ЭЌЪБЛЙПЩвдНкЪЁВЛаЁЕФДцДЂПеМфЁЃ
зжЗћБрТыЕФбЁдё
зжЗћМЏжБНгОіЖЈСЫЪ§ОндкMySQLжаЕФДцДЂБрТыЗНЪН,гЩгкЭЌбљЕФФкШнЪЙгУВЛЭЌзжЗћМЏБэЪОЫљеМгУЕФПеМфДѓаЁЛсгаНЯДѓЕФВювь,ЫљвдЭЈЙ§ЪЙгУКЯЪЪЕФзжЗћМЏ,ПЩвдАяжњЮвУЧОЁПЩФмМѕЩйЪ§ОнСП,НјЖјМѕЩйIOВйзїДЮЪ§ЁЃ
-
ДПРЖЁзжЗћФмБэЪОЕФФкШн,УЛБивЊбЁдёlatin1жЎЭтЕФЦфЫћзжЗћБрТы,вђЮЊетЛсНкЪЁДѓСПЕФДцДЂПеМфЁЃ
-
ШчЙћЮвУЧПЩвдШЗЖЈВЛашвЊДцЗХЖржжгябд,ОЭУЛБивЊЗЧЕУЪЙгУutf8ЛђепЦфЫћunicodeзжЗћБрТы,етЛсдьГЩДѓСПЕФДцДЂПеМфРЫЗбЁЃ
Ъ§ОнПтБэЪЪЕБВ№Зж
гааЉЪБКђ,ЮвУЧПЩФмЛсЯЃЭћНЋвЛИіЭъећЕФЖдЯѓЖдгІгквЛеХЪ§ОнПтБэ,етЖдгкгІгУГЬађПЊЗЂРДЫЕЪЧКмгаКУЕФ,ЕЋЪЧгааЉЪБКђПЩФмЛсдкадФмЩЯДјРДНЯДѓЕФЮЪЬтЁЃ
ЕБЮвУЧЕФБэжаДцдкРрЫЦгкtextЛђепЪЧКмДѓЕФvarcharРраЭЕФДѓзжЖЮЕФЪБКђ,ШчЙћЮвУЧДѓВПЗжЗУЮЪетеХБэЕФЪБКђЖМВЛашвЊетИізжЖЮ,ЮвУЧОЭИУвхЮоЗДЙЫЕФНЋЦфВ№ЗжЕНСэЭтЕФЖРСЂБэжа,вдМѕЩйГЃгУЪ§ОнЫљеМгУЕФДцДЂПеМфЁЃетбљзіЕФвЛИіУїЯдКУДІОЭЪЧУПИіЪ§ОнПщжаПЩвдДцДЂЕФЪ§ОнЬѕЪ§ПЩвдДѓДѓдіМг,МШМѕЩйЮяРэ IO ДЮЪ§,вВФмДѓДѓЬсИпФкДцжаЕФЛКДцУќжаТЪЁЃ
БэЪ§ОнЪЪЖШШпгр
ЮЊЪВУДЮвУЧвЊШпгр?етВЛЪЧдіМгСЫУПЬѕЪ§ОнЕФДѓаЁ,МѕЩйСЫУПИіЪ§ОнПщПЩДцЗХМЧТМЬѕЪ§Т№?ШЗЪЕ,етбљзіЪЧЛсдіДѓУПЬѕМЧТМЕФДѓаЁ,НЕЕЭУПЬѕМЧТМжаПЩДцЗХЪ§ОнЕФЬѕЪ§,ЕЋЪЧдкгааЉГЁОАЯТЮвУЧШдШЛЛЙЪЧВЛЕУВЛетбљзіЁЃ
-
БЛЦЕЗБв§гУЧвжЛФмЭЈЙ§ Join 2еХ(ЛђепИќЖр)ДѓБэЕФЗНЪНВХФмЕУЕНЕФЖРСЂаЁзжЖЮЁЃ
-
етбљЕФГЁОАгЩгкУПДЮJoinНіНіжЛЪЧЮЊСЫШЁЕУФГИіаЁзжЖЮЕФжЕ,JoinЕНЕФМЧТМгжДѓ,ЛсдьГЩДѓСПВЛБивЊЕФ IO,ЭъШЋПЩвдЭЈЙ§ПеМфЛЛШЁЪБМфЕФЗНЪНРДгХЛЏЁЃВЛЙ§,ШпгрЕФЭЌЪБашвЊШЗБЃЪ§ОнЕФвЛжТадВЛЛсдтЕНЦЦЛЕ,ШЗБЃИќаТЕФЭЌЪБШпгрзжЖЮвВБЛИќаТЁЃ
default ОЁСПЪЙгУ not null(ФЌШЯжЕОЁСПЩшЮЊЗЧПе)
nullРраЭБШНЯЬиЪт,SQL ФбгХЛЏЁЃЫфШЛ MySQL nullРраЭКЭ Oracle ЕФnullгаВювь,ЛсНјШыЫїв§жа,ЕЋШчЙћЪЧвЛИізщКЯЫїв§,ФЧУДетИіNULL РраЭЕФзжЖЮЛсМЋДѓгАЯьећИіЫїв§ЕФаЇТЪЁЃДЫЭт,NULL дкЫїв§жаЕФДІРэвВЪЧЬиЪтЕФ,вВЛсеМгУЖюЭтЕФДцЗХПеМфЁЃ
КмЖрШЫОѕЕУnullЛсНкЪЁвЛаЉПеМф,ЫљвдОЁСПШУnullРДДяЕННкЪЁIOЕФФПЕФ,ЕЋЪЧДѓВПЗжЪБКђетЛсЪЪЕУЦфЗД,ЫфШЛПеМфЩЯПЩФмШЗЪЕгавЛЖЈНкЪЁ,ЕЙЪЧДјРДСЫКмЖрЦфЫћЕФгХЛЏЮЪЬт,ВЛЕЋУЛгаНЋIOСПЪЁЯТРД,ЗДЖјМгДѓСЫSQLЕФIOСПЁЃЫљвдОЁСПШЗБЃ defaultжЕВЛЪЧnull,вВЪЧвЛИіКмКУЕФБэНсЙЙЩшМЦгХЛЏЯАЙпЁЃ
ЮЊУПеХБэЩшжУвЛИіID
ЮвУЧгІИУЮЊЪ§ОнПтРяЕФУПеХБэЖМЩшжУвЛИіIDзіЮЊЦфжїМќ,ЖјЧвзюКУЕФЪЧвЛИіINTаЭЕФ(ЭЦМіЪЙгУUNSIGNED),ВЂЩшжУЩЯздЖЏдіМгЕФAUTO_INCREMENT(здді)БъжОЁЃ
ОЭЫуЪЧФу users БэгавЛИіжїМќНа ЁАemailЁБЕФзжЖЮ,ФувВБ№ШУЫќГЩЮЊжїМќЁЃЪЙгУ VARCHAR РраЭРДЕБжїМќЛсЪЙгУЕУадФмЯТНЕЁЃСэЭт,дкФуЕФГЬађжа,ФугІИУЪЙгУБэЕФIDРДЙЙдьФуЕФЪ§ОнНсЙЙЁЃ
ЖјЧв,дкMySQLЪ§Онв§ЧцЯТ,ЛЙгавЛаЉВйзїашвЊЪЙгУжїМќ,дкетаЉЧщПіЯТ,жїМќЕФадФмКЭЩшжУБфЕУЗЧГЃживЊ,БШШч,МЏШК,ЗжЧјЁЁ
дкетРя,жЛгавЛИіЧщПіЪЧР§Эт,ФЧОЭЪЧЁАЙиСЊБэЁБЕФЁАЭтМќЁБ,вВОЭЪЧЫЕ,етИіБэЕФжїМќ,ЭЈЙ§ШєИЩИіБ№ЕФБэЕФжїМќЙЙГЩЁЃЮвУЧАбетИіЧщПіНазіЁАЭтМќЁБЁЃБШ Шч:гавЛИіЁАбЇЩњБэЁБгабЇЩњЕФID,гавЛИіЁАПЮГЬБэЁБгаПЮГЬID,ФЧУД,ЁАГЩМЈБэЁБОЭЪЧЁАЙиСЊБэЁБСЫ,ЦфЙиСЊСЫбЇЩњБэКЭПЮГЬБэ,дкГЩМЈБэжа,бЇЩњIDКЭПЮ ГЬIDНаЁАЭтМќЁБЦфЙВЭЌзщГЩжїМќЁЃ
ЫФ.SQLгяОфгХЛЏ
1. ЖдВщбЏНјаагХЛЏ,гІОЁСПБмУтШЋБэЩЈУш,ЪзЯШгІПМТЧдк where МА order by ЩцМАЕФСаЩЯНЈСЂЫїв§ЁЃ
2. гІОЁСПБмУтдк where згОфжаЪЙгУ!=Лђ<>ВйзїЗћ,ЗёдђНЋв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУшЁЃ
3. гІОЁСПБмУтдк where згОфжаЖдзжЖЮНјаа null жЕХаЖЯ,ЗёдђНЋЕМжТв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУшЁЃ
Шч:
select id from t where num is null
ПЩвддкnumЩЯЩшжУФЌШЯжЕ0,ШЗБЃБэжаnumСаУЛгаnullжЕ,ШЛКѓетбљВщбЏ:
select id from t where num=0
4. гІОЁСПБмУтдк where згОфжаЪЙгУ or РДСЌНгЬѕМў,ЗёдђНЋЕМжТв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУшЁЃ
Шч:
select id from t where num=10 or num=20
ПЩвдетбљВщбЏ:
select id from t where num=10
union all
select id from t where num=20
5. ЯТУцЕФВщбЏвВНЋЕМжТШЋБэЩЈУшЁЃ
Шч:
select id from t where name like '%abc%'
ШєвЊЬсИпаЇТЪ,ПЩвдПМТЧШЋЮФМьЫїЁЃ
6. in КЭ not in вВвЊЩїгУ,ЗёдђЛсЕМжТШЋБэЩЈУшЁЃ
Шч:
select id from t where num in(1,2,3)
ЖдгкСЌајЕФЪ§жЕ,ФмгУ between ОЭВЛвЊгУinСЫ
select id from t where num between 1 and 3
7. ШчЙћдк where згОфжаЪЙгУВЮЪ§,вВЛсЕМжТШЋБэЩЈУшЁЃ
вђЮЊSQLжЛгадкдЫааЪБВХЛсНтЮіОжВПБфСП,ЕЋгХЛЏГЬађВЛФмНЋЗУЮЪМЦЛЎЕФбЁдёЭЦГйЕНдЫааЪБ,ЫќБиаыдкБрвыЪБНјаабЁдёЁЃШЛЖј,ШчЙћдкБрвыЪБНЈСЂЗУЮЪМЦЛЎ,БфСПЕФжЕЛЙЪЧЮДжЊЕФ,вђЖјЮоЗЈзїЮЊЫїв§бЁдёЕФЪфШыЯюЁЃ
ШчЯТУцгяОфНЋНјааШЋБэЩЈУш:
select id from t where num=@num
ПЩвдИФЮЊЧПжЦВщбЏЪЙгУЫїв§:
select id from t with(index(Ыїв§Ућ)) where num=@num
8. гІОЁСПБмУтдк where згОфжаЖдзжЖЮНјааБэДяЪНВйзї,етНЋЕМжТв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУшЁЃ
Шч:
select id from t where num/2=100
гІИФЮЊ:
select id from t where num=100*2
9. гІОЁСПБмУтдкwhereзгОфжаЖдзжЖЮНјааКЏЪ§Вйзї,етНЋЕМжТв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУшЁЃ
Шч:
select id from t where substring(name,1,3)='abc' --nameвдabcПЊЭЗЕФid
select id from t where datediff(day,createdate,'2005-11-30')=0 --'2005-11-30'ЩњГЩЕФid
гІИФЮЊ:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
10. ВЛвЊдк where згОфжаЕФЁА=ЁБзѓБпНјааКЏЪ§ЁЂЫуЪѕдЫЫуЛђЦфЫћБэДяЪНдЫЫу,ЗёдђЯЕЭГНЋПЩФмЮоЗЈе§ШЗЪЙгУЫїв§ЁЃ
11. дкЪЙгУЫїв§зжЖЮзїЮЊЬѕМўЪБ,ШчЙћИУЫїв§ЪЧИДКЯЫїв§,ФЧУДБиаыЪЙгУЕНИУЫїв§жаЕФЕквЛИізжЖЮзїЮЊЬѕМўЪБВХФмБЃжЄЯЕЭГЪЙгУИУЫїв§,ЗёдђИУЫїв§НЋВЛЛсБЛЪЙгУ,ВЂЧвгІОЁПЩФмЕФШУзжЖЮЫГађгыЫїв§ЫГађЯрвЛжТЁЃ
12. ВЛвЊаДвЛаЉУЛгавтвхЕФВщбЏЁЃ
ШчашвЊЩњГЩвЛИіПеБэНсЙЙ:
select col1,col2 into #t from t where 1=0
етРрДњТыВЛЛсЗЕЛиШЮКЮНсЙћМЏ,ЕЋЪЧЛсЯћКФЯЕЭГзЪдДЕФ,гІИФГЩетбљ:
create table #t(...)
13. КмЖрЪБКђгУ exists ДњЬц in ЪЧвЛИіКУЕФбЁдёЁЃ
select num from a where num in(select num from b)
гУЯТУцЕФгяОфЬцЛЛ:
select num from a where exists(select 1 from b where num=a.num)
14. ВЂВЛЪЧЫљгаЫїв§ЖдВщбЏЖМгааЇ,SQLЪЧИљОнБэжаЪ§ОнРДНјааВщбЏгХЛЏЕФ,ЕБЫїв§СагаДѓСПЪ§ОнжиИДЪБ,SQLВщбЏПЩФмВЛЛсШЅРћгУЫїв§,ШчвЛБэжагазжЖЮsex,maleЁЂfemaleМИКѕИївЛАы,ФЧУДМДЪЙдкsexЩЯНЈСЫЫїв§вВЖдВщбЏаЇТЪЦ№ВЛСЫзїгУЁЃ
15. Ыїв§ВЂВЛЪЧдНЖрдНКУ,Ыїв§ЙЬШЛПЩвдЬсИпЯргІЕФ select ЕФаЇТЪ,ЕЋЭЌЪБвВНЕЕЭСЫ insert МА update ЕФаЇТЪ,вђЮЊ insert Лђ update ЪБгаПЩФмЛсжиНЈЫїв§,ЫљвддѕбљНЈЫїв§ашвЊЩїжиПМТЧ,ЪгОпЬхЧщПіЖјЖЈЁЃвЛИіБэЕФЫїв§Ъ§зюКУВЛвЊГЌЙ§6Иі,ШєЬЋЖрдђгІПМТЧвЛаЉВЛГЃЪЙгУЕНЕФСаЩЯНЈЕФЫїв§ЪЧЗёгаБивЊЁЃ
16. гІОЁПЩФмЕФБмУтИќаТ clustered Ыїв§Ъ§ОнСа,вђЮЊ clustered Ыїв§Ъ§ОнСаЕФЫГађОЭЪЧБэМЧТМЕФЮяРэДцДЂЫГађ,вЛЕЉИУСажЕИФБфНЋЕМжТећИіБэМЧТМЕФЫГађЕФЕїећ,ЛсКФЗбЯрЕБДѓЕФзЪдДЁЃШєгІгУЯЕЭГашвЊЦЕЗБИќаТ clustered Ыїв§Ъ§ОнСа,ФЧУДашвЊПМТЧЪЧЗёгІНЋИУЫїв§НЈЮЊ clustered Ыїв§ЁЃ
17. ОЁСПЪЙгУЪ§зжаЭзжЖЮ,ШєжЛКЌЪ§жЕаХЯЂЕФзжЖЮОЁСПВЛвЊЩшМЦЮЊзжЗћаЭ,етЛсНЕЕЭВщбЏКЭСЌНгЕФадФм,ВЂЛсдіМгДцДЂПЊЯњЁЃетЪЧвђЮЊв§ЧцдкДІРэВщбЏКЭСЌНгЪБЛсж№ИіБШНЯзжЗћДЎжаУПвЛИізжЗћ,ЖјЖдгкЪ§зжаЭЖјбджЛашвЊБШНЯвЛДЮОЭЙЛСЫЁЃ
18. ОЁПЩФмЕФЪЙгУ varchar/nvarchar ДњЬц char/nchar ,вђЮЊЪзЯШБфГЄзжЖЮДцДЂПеМфаЁ,ПЩвдНкЪЁДцДЂПеМф,ЦфДЮЖдгкВщбЏРДЫЕ,дквЛИіЯрЖдНЯаЁЕФзжЖЮФкЫбЫїаЇТЪЯдШЛвЊИпаЉЁЃ
19. ШЮКЮЕиЗНЖМВЛвЊЪЙгУselect * from t,гУОпЬхЕФзжЖЮСаБэДњЬц*,ВЛвЊЗЕЛигУВЛЕНЕФШЮКЮзжЖЮЁЃ
20. ОЁСПЪЙгУБэБфСПРДДњЬцСйЪББэЁЃШчЙћБэБфСПАќКЌДѓСПЪ§Он,ЧызЂвтЫїв§ЗЧГЃгаЯо(жЛгажїМќЫїв§)ЁЃ
21. БмУтЦЕЗБДДНЈКЭЩОГ§СйЪББэ,вдМѕЩйЯЕЭГБэзЪдДЕФЯћКФЁЃ
22. СйЪББэВЂВЛЪЧВЛПЩЪЙгУ,ЪЪЕБЕиЪЙгУЫќУЧПЩвдЪЙФГаЉР§ГЬИќгааЇ,Р§Шч,ЕБашвЊжиИДв§гУДѓаЭБэЛђГЃгУБэжаЕФФГИіЪ§ОнМЏЪБЁЃЕЋЪЧ,ЖдгквЛДЮадЪТМў,зюКУЪЙгУЕМГіБэЁЃ
23. дкаТНЈСйЪББэЪБ,ШчЙћвЛДЮадВхШыЪ§ОнСПКмДѓ,ФЧУДПЩвдЪЙгУ select into ДњЬц create table,БмУтдьГЩДѓСПlog ,вдЬсИпЫйЖШЁЃШчЙћЪ§ОнСПВЛДѓ,ЮЊСЫЛККЭЯЕЭГБэЕФзЪдД,гІЯШcreate table,ШЛКѓinsertЁЃ
24. ШчЙћЪЙгУЕНСЫСйЪББэ,дкДцДЂЙ§ГЬЕФзюКѓЮёБиНЋЫљгаЕФСйЪББэЯдЪНЩОГ§,ЯШ truncate table ,ШЛКѓ drop table ,етбљПЩвдБмУтЯЕЭГБэЕФНЯГЄЪБМфЫјЖЈЁЃ
25. ОЁСПБмУтЪЙгУгЮБъ,вђЮЊгЮБъЕФаЇТЪНЯВю,ШчЙћгЮБъВйзїЕФЪ§ОнГЌЙ§1Эђаа,ФЧУДОЭгІИУПМТЧИФаДЁЃ
26. ЪЙгУЛљгкгЮБъЕФЗНЗЈЛђСйЪББэЗНЗЈжЎЧА,гІЯШбАевЛљгкМЏЕФНтОіЗНАИРДНтОіЮЪЬт,ЛљгкМЏЕФЗНЗЈЭЈГЃИќгааЇЁЃ
27. гыСйЪББэвЛбљ,гЮБъВЂВЛЪЧВЛПЩЪЙгУЁЃЖдаЁаЭЪ§ОнМЏЪЙгУ FAST_FORWARD гЮБъЭЈГЃвЊгХгкЦфЫћж№ааДІРэЗНЗЈ,гШЦфЪЧдкБиаыв§гУМИИіБэВХФмЛёЕУЫљашЕФЪ§ОнЪБЁЃдкНсЙћМЏжаАќРЈЁАКЯМЦЁБЕФР§ГЬЭЈГЃвЊБШЪЙгУгЮБъжДааЕФЫйЖШПьЁЃШчЙћПЊЗЂЪБМфдЪаэ,ЛљгкгЮБъЕФЗНЗЈКЭЛљгкМЏЕФЗНЗЈЖМПЩвдГЂЪдвЛЯТ,ПДФФвЛжжЗНЗЈЕФаЇЙћИќКУЁЃ
28. дкЫљгаЕФДцДЂЙ§ГЬКЭДЅЗЂЦїЕФПЊЪМДІЩшжУ SET NOCOUNT ON ,дкНсЪјЪБЩшжУ SET NOCOUNT OFF ЁЃЮоашдкжДааДцДЂЙ§ГЬКЭДЅЗЂЦїЕФУПИігяОфКѓЯђПЭЛЇЖЫЗЂЫЭ DONE_IN_PROC ЯћЯЂЁЃ
29. ОЁСПБмУтЯђПЭЛЇЖЫЗЕЛиДѓЪ§ОнСП,ШєЪ§ОнСПЙ§Дѓ,гІИУПМТЧЯргІашЧѓЪЧЗёКЯРэЁЃ
30. ОЁСПБмУтДѓЪТЮёВйзї,ЬсИпЯЕЭГВЂЗЂФмСІЁЃ

ЮДД§ајЭъ!МгИіЙизЂАЩ!