一:虚拟机准备
1、准备3台虚拟机,静态IP地址,关闭防火墙,设置主机名
?IP地址,主机名如下:
? ? ? ? ? 192.168.56.20,hadoop20
? ? ? ? ? 192.168.56.21,hadoop21
? ? ? ? ? 192.168.56.22,hadoop22
? 注意:记得关闭防火墙
? 修改主机名命令:hostnamectl set-hostname xxx
? 关闭防火墙命令:systemctl stop firewalld.service
? 查看防火墙命令:firewall-cmd --state2、3台虚机的/etc/hosts全部配置IP对应主机名
[kgf@hadoop20 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.56.20 hadoop20 192.168.56.21 hadoop21 192.168.56.22 hadoop22 [kgf@hadoop20 ~]$3、OK虚拟机准备完毕
二、SSH无密码登录
参考之前的hadoop2.X内容即可?
三、在hadoop20服务器上安装JDK和hadoop
1、安装JDK(跳过,参考之前的即可)
2、安装hadoop
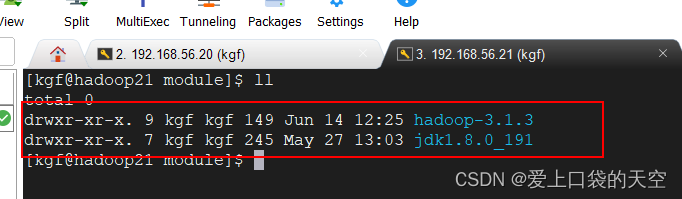
? ? 2.1、将下载的安装包上传到/opt/software/目录下,并解压安装文件到/opt/module下面
[kgf@hadoop20 software]$ ll total 330156 -rw-rw-r--. 1 kgf kgf 338075860 Jun 14 12:18 hadoop-3.1.3.tar.gz [kgf@hadoop20 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C ../module/ [kgf@hadoop20 module]$ ll total 0 drwxr-xr-x. 9 kgf kgf 149 Sep 12 2019 hadoop-3.1.3 drwxr-xr-x. 7 kgf kgf 245 Oct 6 2018 jdk1.8.0_191 [kgf@hadoop20 module]$ pwd /opt/module [kgf@hadoop20 module]$????2.2、将Hadoop添加到环境变量
? ? ? ?sudo vim? /etc/profile?
##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin? ? 2.3、 让修改后的文件生效
source /etc/profile? ? ?2.4、测试是否安装成功
[kgf@hadoop20 module]$ hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar [kgf@hadoop20 module]$
四、同步hadoop20服务的hadoop目录
1、使用之前配置的xsync脚本将hadoop目录同步到hadoop21和hadoop22服务器
[kgf@hadoop20 module]$ pwd /opt/module [kgf@hadoop20 module]$ xsync hadoop-3.1.3/
?
2、配置hadoop的环境变量?
五、配置集群
1、集群部署规划
?注意:
- NameNode和SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上
?2、配置文件说明
????????Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值
2.1、默认配置文件
2.2、自定义配置文件
????????core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置?
3、配置集群
3.1、配置core-site.xml、hadoop-env.sh以及yarn-env.sh
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop20:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为atguigu --> <property> <name>hadoop.http.staticuser.user</name> <value>kgf</value> </property> </configuration>
?
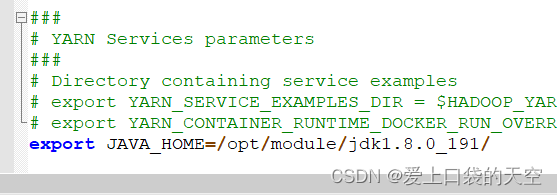
在上面hadoop-env.sh中配置jdk路径
?
在上面yarn-env.sh中配置jdk路径
?
3.2、配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop20:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop22:9868</value> </property> </configuration>3.3、配置yarn-site.xml
<?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop21</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>3.4、配置mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>3.5、在集群上分发配置好的Hadoop配置文件
[kgf@hadoop20 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/3.6、去103和104上查看文件分发情况
[kgf@hadoop21 hadoop-3.1.3]$ pwd /opt/module/hadoop-3.1.3 [kgf@hadoop21 hadoop-3.1.3]$ cat etc/hadoop/core-site.xml [kgf@hadoop22 hadoop-3.1.3]$ pwd /opt/module/hadoop-3.1.3 [kgf@hadoop22 hadoop-3.1.3]$ cat etc/hadoop/core-site.xml

六、启动集群
1、配置workers(3台服务器都配置)
[kgf@hadoop20 hadoop-3.1.3]$ vim etc/hadoop/workers [kgf@hadoop20 hadoop-3.1.3]$ cat etc/hadoop/workers hadoop20 hadoop21 hadoop22 [kgf@hadoop20 hadoop-3.1.3]$注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
2、启动集群
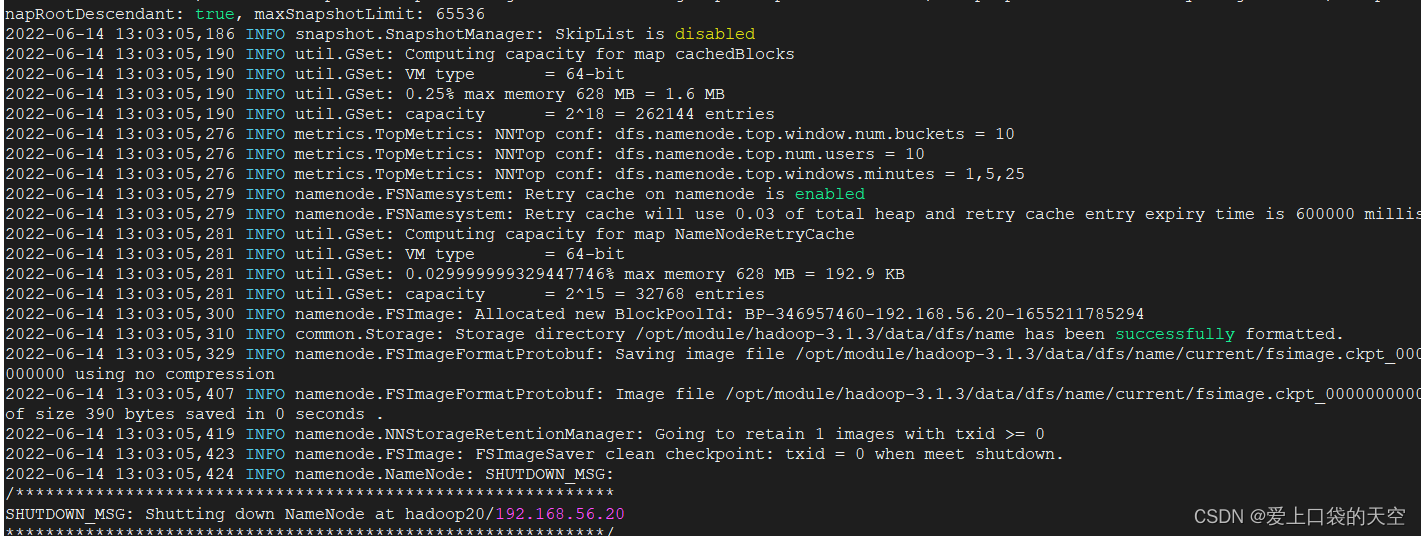
????????如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[kgf@hadoop20 hadoop-3.1.3]$ hdfs namenode -format
启动HDFS:
[kgf@hadoop20 hadoop-3.1.3]$ sbin/start-dfs.sh Starting namenodes on [hadoop20] Starting datanodes hadoop21: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. hadoop22: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. Starting secondary namenodes [hadoop22] [kgf@hadoop20 hadoop-3.1.3]$ jps 3009 DataNode 2854 NameNode 3225 Jps [kgf@hadoop20 hadoop-3.1.3]$[kgf@hadoop21 hadoop-3.1.3]$ jps 1872 Jps 1804 DataNode [kgf@hadoop21 hadoop-3.1.3]$[kgf@hadoop22 module]$ jps 1922 SecondaryNameNode 2004 Jps 1850 DataNode [kgf@hadoop22 module]$在配置了ResourceManager的节点(hadoop21)启动YARN
[kgf@hadoop21 hadoop-3.1.3]$ sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [kgf@hadoop21 hadoop-3.1.3]$ jps 2072 ResourceManager 2472 Jps 2203 NodeManager 1804 DataNode [kgf@hadoop21 hadoop-3.1.3]$[kgf@hadoop22 module]$ jps 1922 SecondaryNameNode 2211 Jps 2104 NodeManager 1850 DataNode [kgf@hadoop22 module]$[kgf@hadoop20 hadoop-3.1.3]$ jps 3009 DataNode 2854 NameNode 3303 NodeManager 3402 Jps [kgf@hadoop20 hadoop-3.1.3]$3、Web端查看HDFS的NameNode
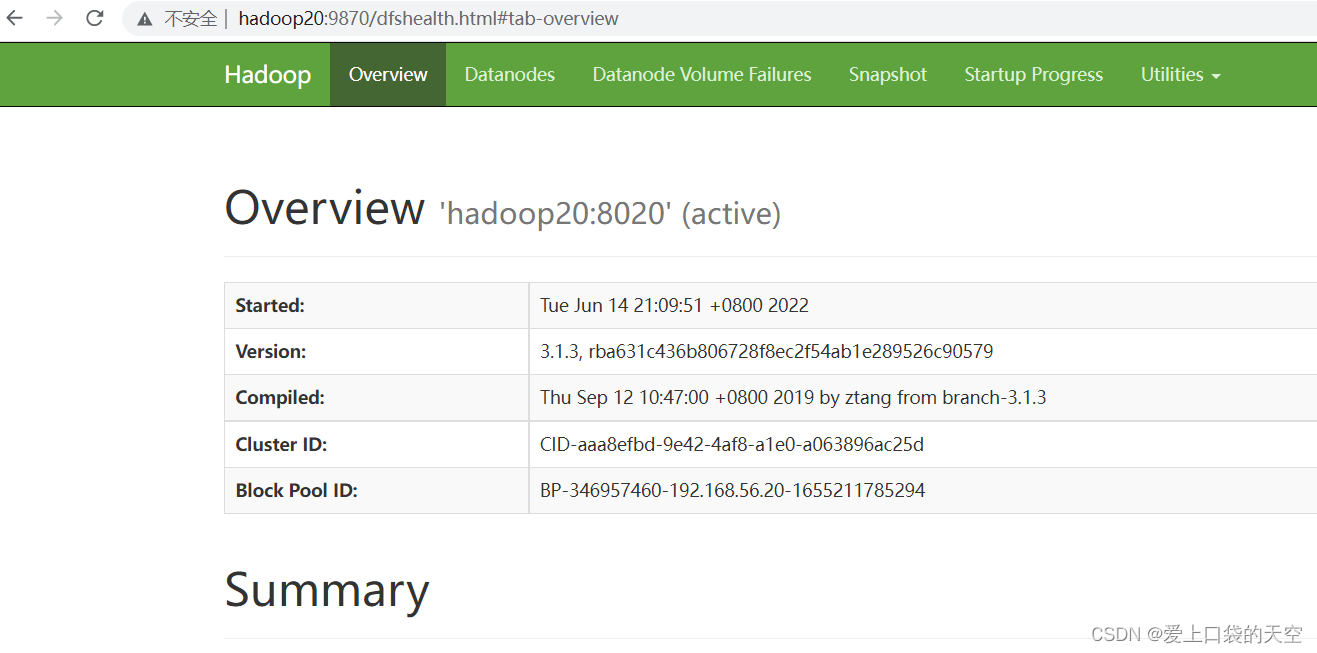
? ? ? ? ? ? ? (a)浏览器中输入:http://hadoop20:9870/
?????? ?????? (b)查看HDFS上存储的数据信息
????????
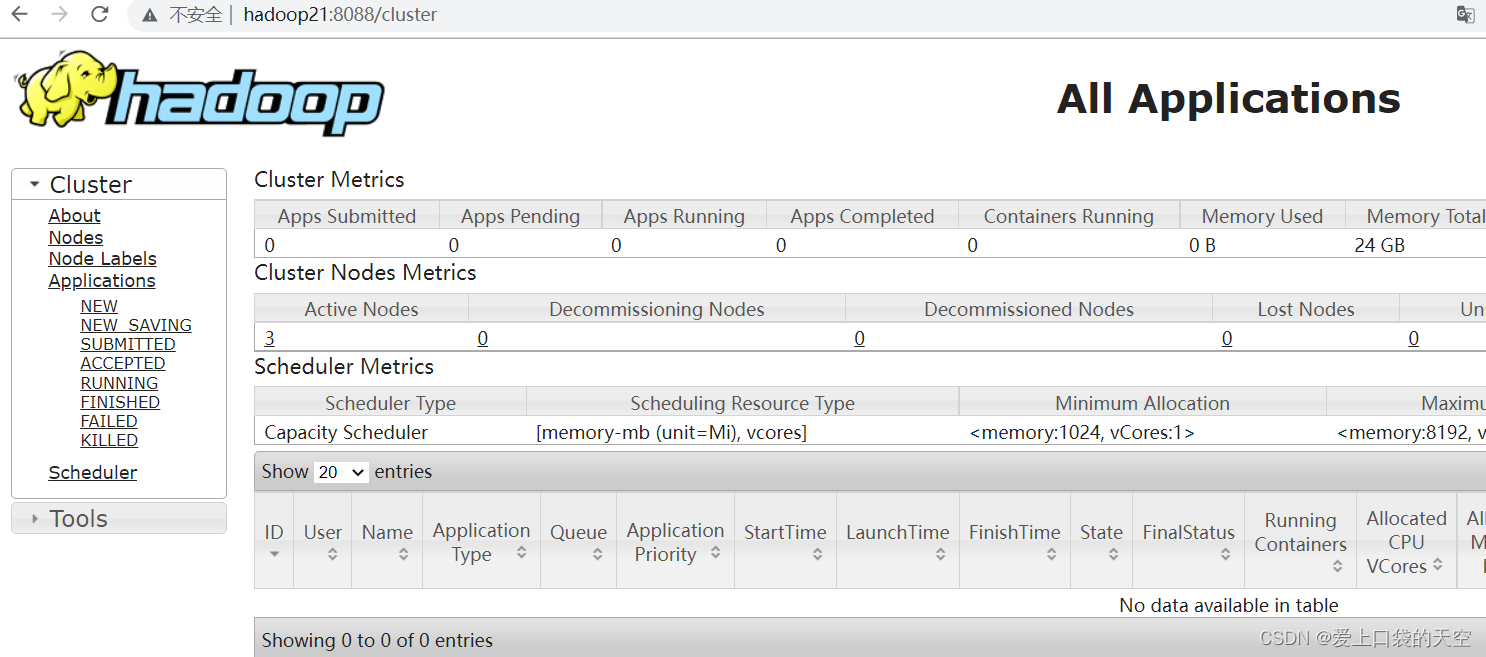
4、Web端查看YARN的ResourceManager
???????(a)浏览器中输入:http://hadoop21:8088/cluster
?????? (b)查看YARN上运行的Job信息
?
?
七、集群基本测试
1、上传文件到集群
1.1、上传小文件
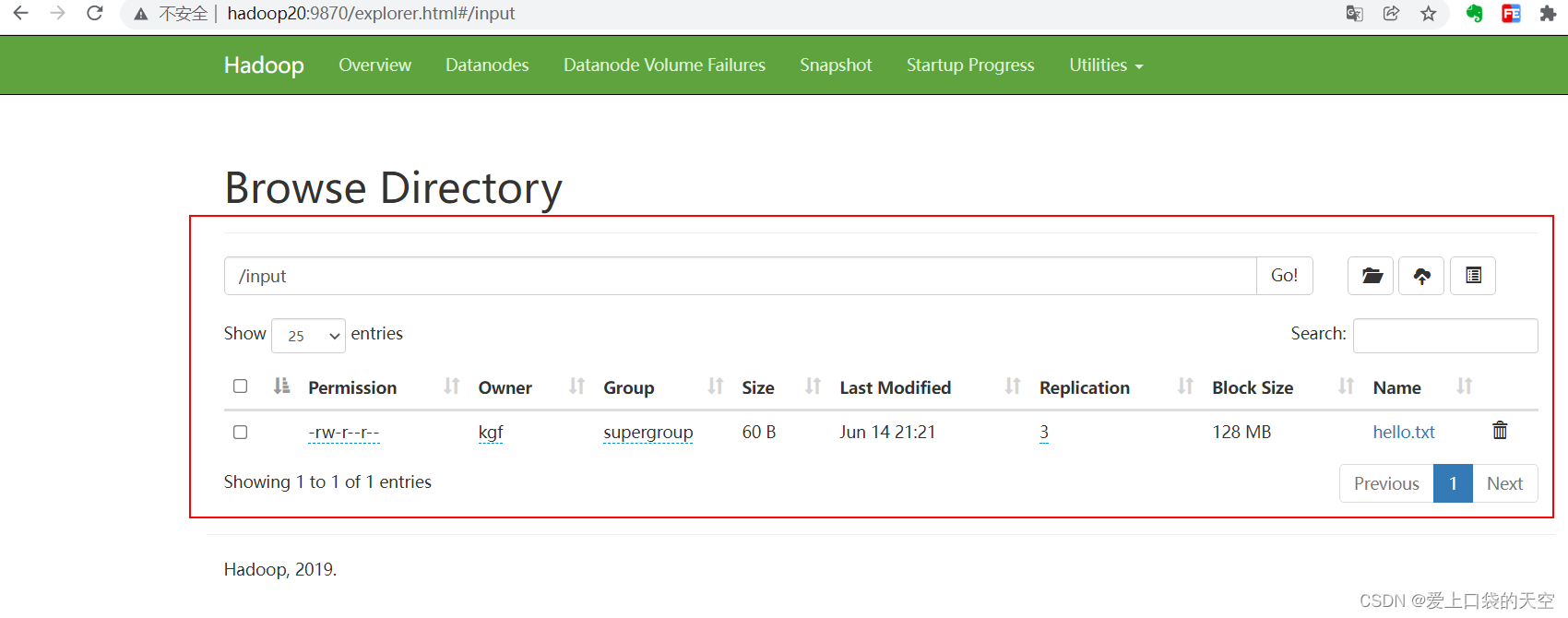
[kgf@hadoop20 hadoop-3.1.3]$ hadoop fs -mkdir /input [kgf@hadoop20 hadoop-3.1.3]$ ll wcinput/ total 4 -rw-rw-r--. 1 kgf kgf 60 Jun 14 13:20 hello.txt [kgf@hadoop20 hadoop-3.1.3]$ pwd /opt/module/hadoop-3.1.3 [kgf@hadoop20 hadoop-3.1.3]$ [kgf@hadoop20 hadoop-3.1.3]$ hadoop fs -put wcinput/hello.txt /input 2022-06-14 13:21:17,764 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [kgf@hadoop20 hadoop-3.1.3]$
?1.2、上传大文件
[kgf@hadoop20 hadoop-3.1.3]$ hadoop fs -put /opt/software/hadoop-3.1.3.tar.gz / 2022-06-14 13:24:12,505 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2022-06-14 13:24:14,059 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2022-06-14 13:24:16,001 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [kgf@hadoop20 hadoop-3.1.3]$
?

八、配置历史服务器
?为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1、配置mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop20:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop21:19888</value> </property>2、分发配置
[kgf@hadoop20 hadoop-3.1.3]$ xsync etc/hadoop/mapred-site.xml fname=mapred-site.xml pdir=/opt/module/hadoop-3.1.3/etc/hadoop ----------hadoop21-------- sending incremental file list mapred-site.xml sent 579 bytes received 43 bytes 414.67 bytes/sec total size is 1194 speedup is 1.92 ------hadoop22-------- sending incremental file list mapred-site.xml sent 579 bytes received 43 bytes 1244.00 bytes/sec total size is 1194 speedup is 1.92 [kgf@hadoop20 hadoop-3.1.3]$3、在hadoop102启动历史服务器
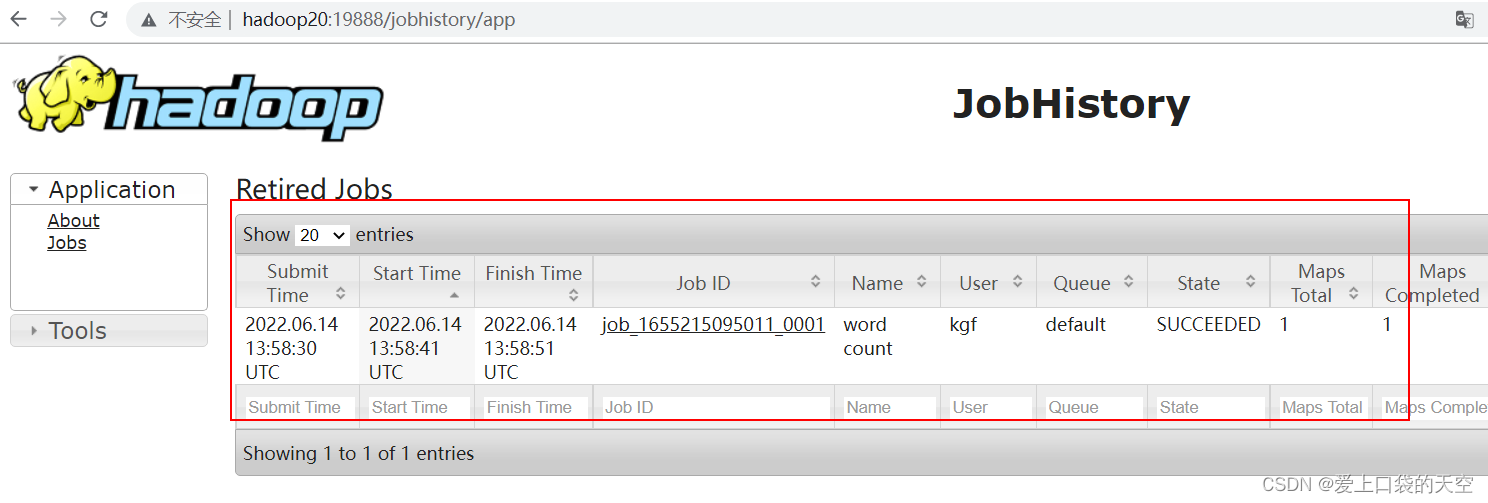
[kgf@hadoop20 hadoop-3.1.3]$ mapred --daemon start historyserver [kgf@hadoop20 hadoop-3.1.3]$ jps 3009 DataNode 2854 NameNode 3734 JobHistoryServer 3303 NodeManager 3759 Jps [kgf@hadoop20 hadoop-3.1.3]$ pwd /opt/module/hadoop-3.1.3 [kgf@hadoop20 hadoop-3.1.3]$4、查看JobHistory
?

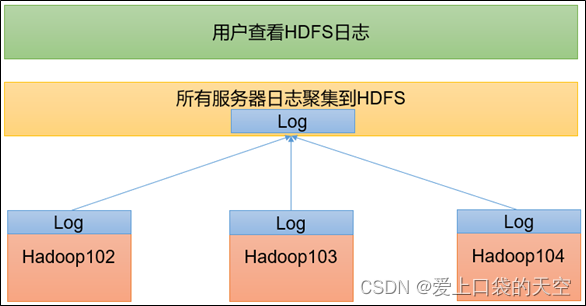
九、配置日志的聚集
?日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
1、配置yarn-site.xml
?在该文件里面增加如下配置
<!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop20:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>2、分发配置
[kgf@hadoop20 hadoop-3.1.3]$ xsync etc/hadoop/yarn-site.xml fname=yarn-site.xml pdir=/opt/module/hadoop-3.1.3/etc/hadoop ----------hadoop21-------- sending incremental file list yarn-site.xml sent 1028 bytes received 43 bytes 2142.00 bytes/sec total size is 1645 speedup is 1.54 ------hadoop22-------- sending incremental file list yarn-site.xml sent 1028 bytes received 43 bytes 2142.00 bytes/sec total size is 1645 speedup is 1.54 [kgf@hadoop20 hadoop-3.1.3]$3、关闭NodeManager 、ResourceManager和HistoryServer
[kgf@hadoop21 hadoop-3.1.3]$ jps 3304 ResourceManager 3131 DataNode 3436 NodeManager 3726 Jps [kgf@hadoop21 hadoop-3.1.3]$ sbin/stop-yarn.sh Stopping nodemanagers Stopping resourcemanager [kgf@hadoop21 hadoop-3.1.3]$ jps 3131 DataNode 4093 Jps [kgf@hadoop21 hadoop-3.1.3]$[kgf@hadoop20 hadoop-3.1.3]$ mapred --daemon stop historyserver [kgf@hadoop20 hadoop-3.1.3]$ jps 5317 Jps 4662 DataNode 4505 NameNode [kgf@hadoop20 hadoop-3.1.3]$4、启动NodeManager 、ResourceManage和HistoryServer
[kgf@hadoop21 hadoop-3.1.3]$ sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [kgf@hadoop21 hadoop-3.1.3]$ jps 4641 Jps 4218 ResourceManager 3131 DataNode 4351 NodeManager [kgf@hadoop21 hadoop-3.1.3]$[kgf@hadoop20 hadoop-3.1.3]$ mapred --daemon start historyserver [kgf@hadoop20 hadoop-3.1.3]$ jps 4662 DataNode 5542 JobHistoryServer 5383 NodeManager 4505 NameNode 5567 Jps [kgf@hadoop20 hadoop-3.1.3]$5、执行WordCount程序
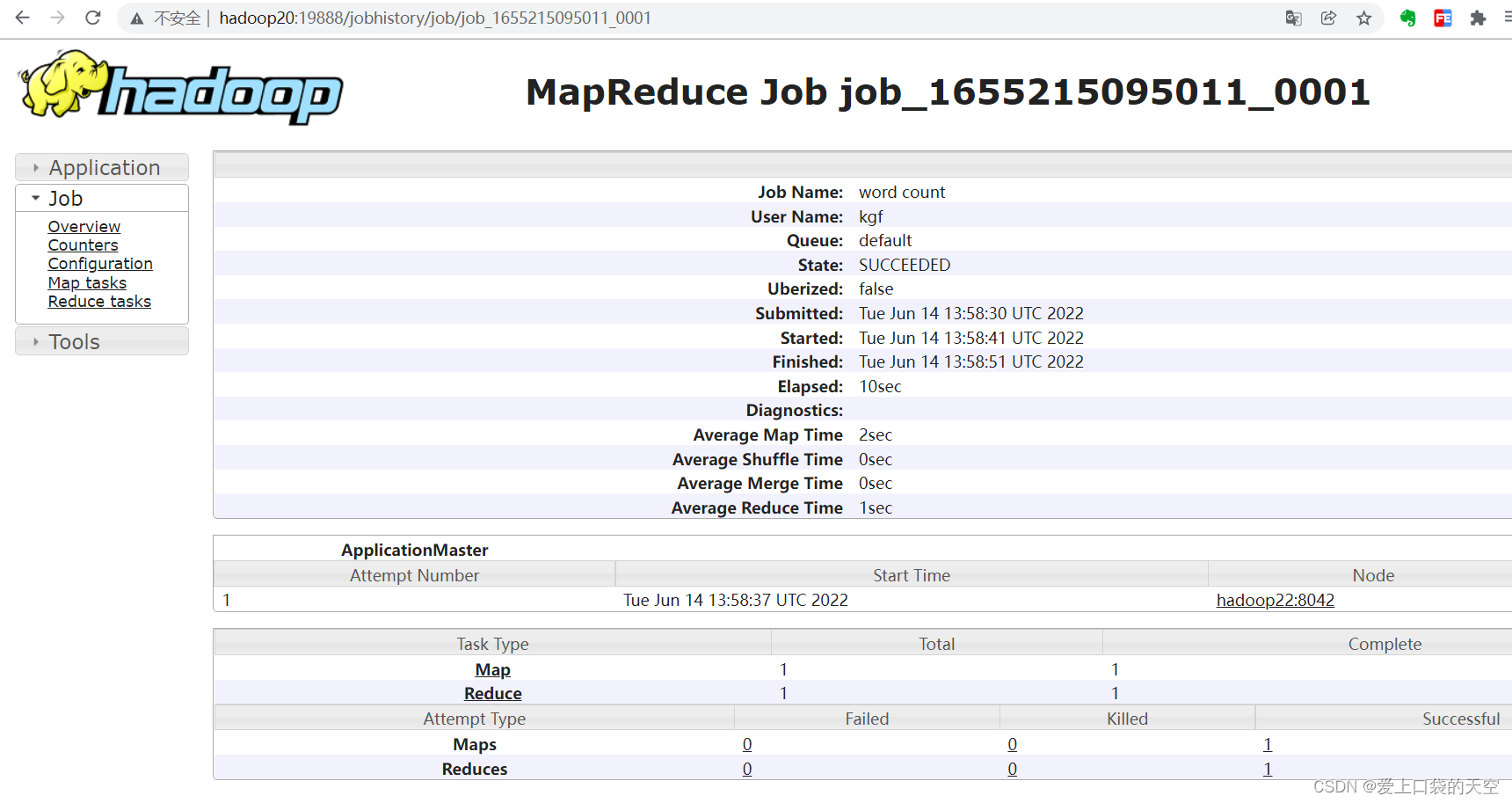
[kgf@hadoop20 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output 2022-06-14 13:58:29,712 INFO client.RMProxy: Connecting to ResourceManager at hadoop21/192.168.56.21:8032 2022-06-14 13:58:30,343 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/kgf/.staging/job_1655215095011_0001 2022-06-14 13:58:30,423 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2022-06-14 13:58:30,551 INFO input.FileInputFormat: Total input files to process : 1 2022-06-14 13:58:30,574 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2022-06-14 13:58:30,602 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2022-06-14 13:58:30,621 INFO mapreduce.JobSubmitter: number of splits:1 2022-06-14 13:58:30,732 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2022-06-14 13:58:30,763 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1655215095011_0001 2022-06-14 13:58:30,763 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2022-06-14 13:58:30,906 INFO conf.Configuration: resource-types.xml not found 2022-06-14 13:58:30,906 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2022-06-14 13:58:31,091 INFO impl.YarnClientImpl: Submitted application application_1655215095011_0001 2022-06-14 13:58:31,121 INFO mapreduce.Job: The url to track the job: http://hadoop21:8088/proxy/application_1655215095011_0001/ 2022-06-14 13:58:31,121 INFO mapreduce.Job: Running job: job_1655215095011_0001 2022-06-14 13:58:41,290 INFO mapreduce.Job: Job job_1655215095011_0001 running in uber mode : false 2022-06-14 13:58:41,291 INFO mapreduce.Job: map 0% reduce 0% 2022-06-14 13:58:47,396 INFO mapreduce.Job: map 100% reduce 0% 2022-06-14 13:58:52,453 INFO mapreduce.Job: map 100% reduce 100% 2022-06-14 13:58:52,462 INFO mapreduce.Job: Job job_1655215095011_0001 completed successfully 2022-06-14 13:58:52,767 INFO mapreduce.Job: Counters: 536、查看日志
?查看任务运行日志: