mysql
��һ�¸���:
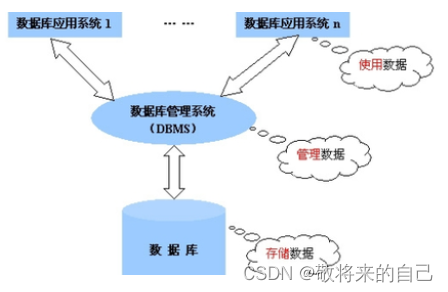
���ݿ�ĸ���
DB
���ݿ�(database):�洢���ݵġ��ֿ⡱����������һϵ������֯�����ݡ�
DBMS
���ݿ����ϵͳ(Database Management System)�����ݿ���ͨ��DBMS��
���Ͳ���������
SQL
�ṹ����ѯ����(Structure Query Language):ר�����������ݿ�ͨ�ŵ���
��
���ݿ���ص�:
����:��ϵ�����ݿ�:SQLite��Oracle��mysql
����:
1����ϵ�����ݿ�,��ָ�����˹�ϵģ������֯���ݵ����ݿ�;
����2����ϵ�����ݿ������ص���������һ����;
����3������˵,��ϵģ��ָ�ľ��Ƕ�ά����ģ��,��һ����ϵ�����ݿ�����ɶ�ά������֮�����ϵ����ɵ�һ��������֯��
�ŵ�:
1����������:��ά���ṹ�Ƿdz�����������һ������,��ϵģ�������״����ε�����ģ����˵����������;
����2��ʹ�÷���:ͨ�õ�SQL����ʹ�ò�����ϵ�����ݿ�dz�����;
����3������ά��:�ḻ��������(ʵ�������ԡ����������Ժ��û������������)��������������������ݲ�һ�µĸ���;
����4��֧��SQL,�����ڸ��ӵIJ�ѯ��
ȱ��:
1��Ϊ��ά��һ�����������ľ���۾������д���ܱȽϲ�;
����2���̶��ı��ṹ;
����3���߲�����д����;
����4���������ݵĸ�Ч�ʶ�д
����:�ǹ�ϵ�����ݿ�MongoDb��redis��HBase
����:
1��ʹ�ü�ֵ�Դ洢����;
����2���ֲ�ʽ;
����3��һ�㲻֧��ACID����;
����4���ǹ�ϵ�����ݿ��ϸ��ϲ���һ�����ݿ�,Ӧ����һ�����ݽṹ���洢�����ļ��ϡ�
�ŵ�:
1�����辭��sql��Ľ���,��д���ܸܺ�;
����2�����ڼ�ֵ��,����û�������,������չ;
����3���洢���ݵĸ�ʽ:nosql�Ĵ洢��ʽ��key,value��ʽ���ĵ���ʽ��ͼƬ��ʽ�ȵ�,�ĵ���ʽ��ͼƬ��ʽ�ȵ�,����ϵ�����ݿ���ֻ֧�ֻ������͡�
ȱ��:
1�����ṩsql֧��,ѧϰ��ʹ�óɱ��ϸ�;
����2����������,���ӹ���bi�ͱ�����֧��Ҳ����;
SQL���ŵ�:
1������ij���ض����ݿӦ��ר�е�����,��������DBMS��֧��SQL
2������ѧ
3����Ȼ��,��ʵ������һ��ǿ����������,���ʹ��������Ԫ��,���Խ��зdz����Ӻ������ݿ������
SQL���Է���
1��DML(Data Manipulation Language):���ݲ������,�������ӡ�ɾ�����ġ���ѯ���ݿ��¼,���������������
��������SQL���:
��INSERT:�������ݵ����ݿ���
��UPDATE:�����ݿ��е�����
��DELETE:ɾ�����ݿ��е�����
��SELECT:ѡ��(��ѯ)���� SELECT��SQL���ԵĻ���,��Ϊ��Ҫ��
2��DDL(Data Definition Language):���ݶ������,���ڿ�ͱ��Ĵ������ġ�ɾ����
��������SQL���:
��CREATE TABLE:�������ݿ��
��ALTER TABLE:���ı��ṹ�����ӡ�ɾ�������г���
��DROP TABLE:ɾ����
��CREATE INDEX:�ڱ��Ͻ�������
��DROP INDEX:ɾ������
3��DCL(Data Control Language):���ݿ������,���ڶ����û��ķ���Ȩ�Ͱ�ȫ����
��������SQL���:
��GRANT:�������Ȩ��
��REVOKE:��������Ȩ��
��COMMIT:�ύ������
��ROLLBACK:����������
��SAVEPOINT:�����
��LOCK:�����ݿ���ض����ֽ�������
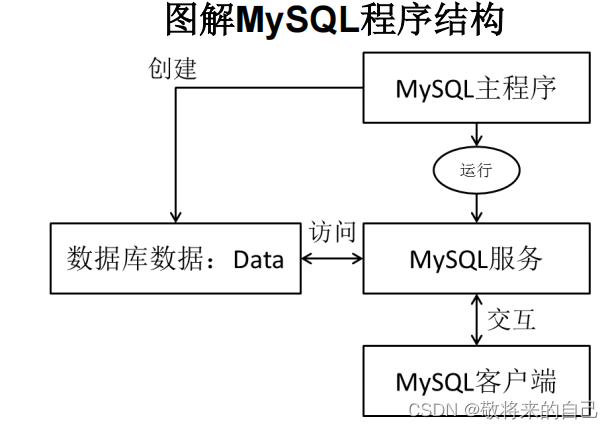
�ڶ���mysql��װ��ʹ��:
MySQL��Ʒ���ص�
- MySQL���ݿ�������MySQL AB��˾,��
��λ�����,��oracle�չ��� - �ŵ�:
�C �ɱ���:����Դ����,һ������������
�C ���ܸ�:ִ�кܿ�
�C ��:�����װ�װ��ʹ�� - DBMS��Ϊ����:
�C ���ڹ����ļ�ϵͳ��DBMS (Access )
�C ���ڿͻ���������������DBMS(MySQL��Oracle��SqlServer)
MySQL�İ汾
������(���) ��ҵ��(�շ�)
���ص�ַ:http://dev.mysql.com/downloads/mysql
������ֹͣMySQL����
��ʽһ:ͨ�������������ʽ�һ������������������������ֹͣMySQL����
��ʽ��:ͨ�������з�ʽ ����:net start mysql������ ֹͣ:net stop mysql������
MySQL����˵ĵ�¼���˳�
��¼ mysql �Ch ������ �Cu�û��� �Cp���� �˳� exit
MySQL��淶
- �����ִ�Сд
- ÿ�仰��;��\g��β
- ���Ӿ�һ�����д
- �ؼ��ֲ�����дҲ���ܷ���
- ������������Ŀɶ���
MySQL����
- ���� mysql, ��������������: mysql �Curoot �Cp#### (����:####��ʾ����)
mysql �Curoot �Cp####
- �鿴 mysql ������Щ�����ݿ�: show databases;
show databases;
- ʹ��һ�����ݿ�: use ���ݿ�����;
use mysql;
- �½�һ�����ݿ�: create database ���ݿ���
create database test;
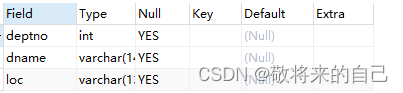
�����´���������:
������
- �
CREATE TABLE dept
(deptno INT(2),
dname VARCHAR(14),
loc VARCHAR(13));
- �鿴
DESCRIBE dept;
������������
������
CREATE TABLE emp (
#int����,����
emp_id INT AUTO_INCREMENT, #��ౣ��20����Ӣ���ַ�
emp_name CHAR (20),
#��λ��������15λ
salary DOUBLE,
#��������
birthday DATE,
#����
PRIMARY KEY (emp_id)
);
ʹ���Ӳ�ѯ������
- ʹ�� AS subquery ѡ��,���������Ͳ������ݽ������
CREATE TABLE table
[(column, column��)]
AS subquery;
- ָ�����к��Ӳ�ѯ�е���Ҫһһ��Ӧ
- ͨ��������Ĭ��ֵ������
- �������еı�:
create table emp1 as select * from employees;
create table emp2 as select * from employees where 1=2;
--������emp2�ǿձ���
ʹ���Ӳ�ѯ����������
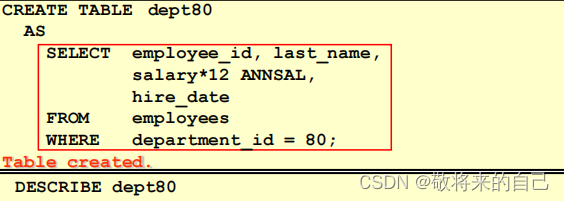
ALTER TABLE ���
ʹ�� ALTER TABLE ������ʵ��:
- �����еı���������
ALTER TABLE dept80
ADD job_id varchar(15);
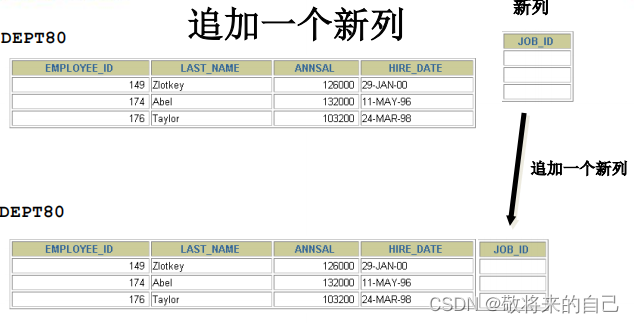
- ��������
�ٿ������е���������, �ߴ��Ĭ��ֵ
ALTER TABLE dept80
MODIFY (last_name VARCHAR(30));
�ڶ�Ĭ��ֵ����ֻӰ����Ա�����
ALTER TABLE dept80
MODIFY (salary double(9,2) default 1000);
- ɾ�����б��е���
ʹ�� DROP COLUMN �Ӿ�ɾ��������Ҫ����
ALTER TABLE dept80
DROP COLUMN job_id;
- ������������
ʹ�� CHANGE old_column new_column dataType�Ӿ���������
ALTER TABLE dept80
CHANGE department_name dept_name varchar(15);
ɾ����
?���ݺͽṹ����ɾ��
? �����������е���������ύ
? �������������ɾ��
? DROP TABLE ��䲻�ܻع�
DROP TABLE dept80;
��ձ�
? TRUNCATE TABLE ���:
�� ɾ���������е�����
�� �ͷű��Ĵ洢�ռ�
TRUNCATE TABLE detail_dept;
? TRUNCATE��䲻�ܻع�
? ����ʹ�� DELETE ���ɾ������,���Իع�
�ı���������
? ִ��RENAME���ı��, ��ͼ������
ALTER table dept
RENAME TO detail_dept;
? �����Ƕ����ӵ����
������������ɾ��:
���ݲ�������
? DML(Data Manipulation Language �C
���ݲ�������) ����������������ִ��:
�C �������������
�C ���ִ�����
�C ɾ���ִ�����
? ��������������������DML�����ɵ�
��������
INSERT ����
? ʹ�� INSERT �������в������ݡ�
INSERT INTO table [(column [, column��])]
VALUES (value [, value��]);
? ʹ�������һ��ֻ������в���һ�����ݡ�
? Ϊÿһ������һ����ֵ��
? ���е�Ĭ��˳���г������е�ֵ��
? �� INSERT �Ӿ��������г����������ǵ�ֵ��
? �ַ�������������Ӧ�����ڵ������С�
INSERT INTO departments(department_id, department_name,
manager_id, location_id)
VALUES (70, 'Public Relations', 100, 1700);
INSERT INTO
employees(employee_id,last_name,email,hire_date,job_id)
VALUES (300,��Tom��,��tom@126.com��,to_date(��2012-3-
21��,��yyyy-mm-dd��),��SA_RAP��);
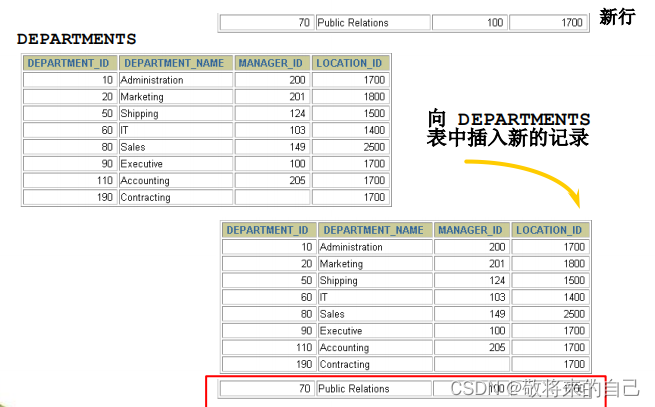
����в����ֵ
? ��ʽ��ʽ: ����������ʡ�Ը��е�ֵ��

? ��ʾ��ʽ: ��VALUES �Ӿ���ָ����ֵ��

����ָ����ֵ
NOW()����:��¼��ǰϵͳ�����ں�ʱ�䡣
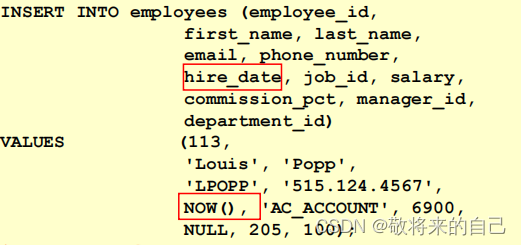
���������������
? �� INSERT ����м����Ӳ�ѯ��


? ������д VALUES �Ӿ䡣
? �Ӳ�ѯ�е�ֵ�б�Ӧ�� INSERT �Ӿ��е�������
Ӧ
��������
UPDATE ����
? ʹ�� UPDATE ���������ݡ�
UPDATE table
SET column = value [, column = value, ��]
[WHERE condition];
? ����һ�θ����������ݡ�
? �����Ҫ�ع�����,��Ҫ��֤��DMLǰ,��������:SET AUTOCOMMIT = FALSE;
? ʹ�� WHERE �Ӿ�ָ����Ҫ���µ����ݡ�

? ���ʡ�� WHERE �Ӿ�,����е��������ݶ���������
UPDATE copy_emp
SET department_id = 110;
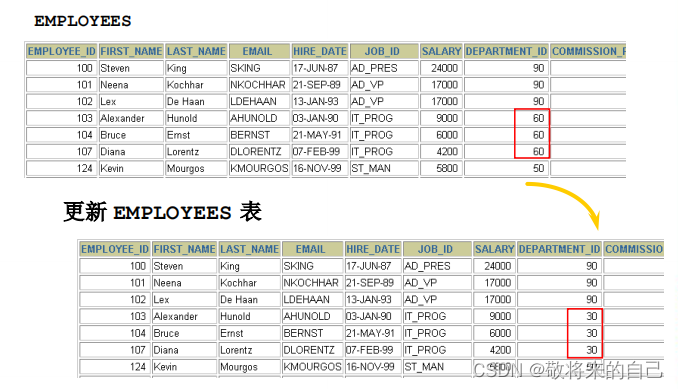
ɾ������
ʹ�� DELETE ���ӱ���ɾ�����ݡ�
DELETE FROM table
[WHERE condition];
? ʹ�� WHERE �Ӿ�ɾ��ָ���ļ�¼��
DELETE FROM departments
WHERE department_name = 'Finance';
1 row
? ���ʡ�� WHERE �Ӿ�,����е�ȫ�����ݽ���ɾ��
DELETE FROM emp;
���������ݲ�ѯ:
���� SELECT ���
SELECT *| {[DISTINCT] column|expression [alias],��}
FROM table;
? SELECT ��ʶѡ����Щ�С�
? FROM ��ʶ���ĸ�����ѡ��
ѡ��ȫ����

ѡ���ض�����
ע ��:
? SQL ������Сд�����С�
? SQL ����д��һ�л��߶���
? �ؼ��ֲ��ܱ���дҲ���ܷ���
? ���Ӿ�һ��Ҫ����д��
? ʹ������������Ŀɶ���
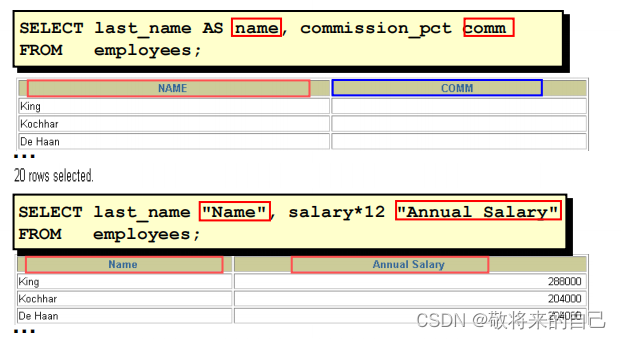
�еı���
? ������һ���С�
? ���ڼ��㡣
? ��������,Ҳ�����������ͱ���֮�����ؼ���
��AS��,����ʹ��˫����,�Ա��ڱ����а�����
���������ַ������ִ�Сд��
�ַ���
? �ַ��������� SELECT �б��е�һ���ַ�,����,��
�ڡ�
? ���ں��ַ�ֻ���ڵ������г��֡�
? ÿ������һ��ʱ,�ַ��������һ�Ρ�
��ʾ���ṹ
ʹ�� DESCRIBE ����,��ʾ���ṹ
DESC[RIBE] tablename
DESCRIBE employees
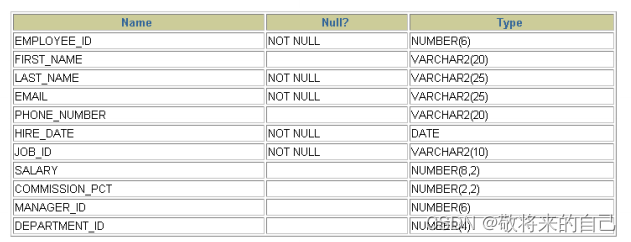
���˺���������
����
? ʹ��WHERE �Ӿ�,���������������й��˵���

? WHERE �Ӿ���� FROM �Ӿ䡣
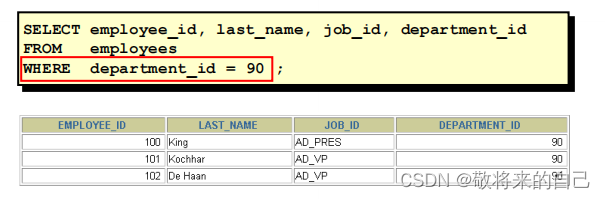
�Ƚ�����
| ������ | ���� |
|---|---|
| = | ���� (���� ==) |
| > | ���� |
| >= | ���ڡ����� |
| < | �� |
| <= | С�ڡ����� |
| <> | ������ (Ҳ������ !=) |
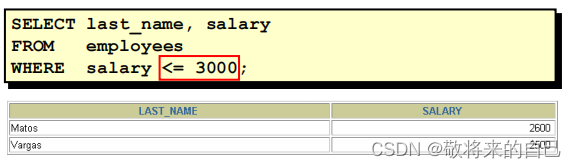
�����Ƚ�����
| ������ | ����. |
|---|---|
| BETWEEN��AND�� | ������ֵ֮�� (�����߽�) |
| IN(set) | ����ֵ�б��е�һ�� |
| LIKE | ģ����ѯ |
| IS NULL | ��ֵ |
BETWEEN
ʹ�� BETWEEN ��������ʾ��һ�������ڵ�ֵ
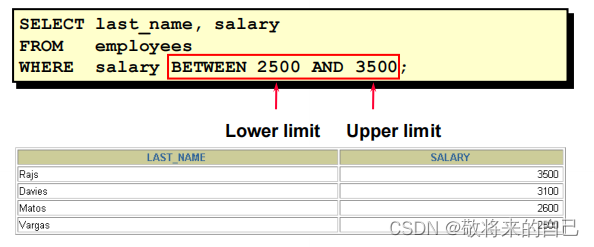
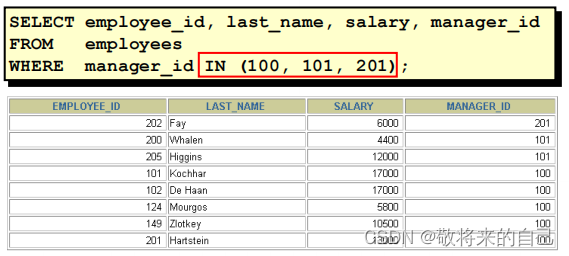
IN
ʹ�� IN������ʾ�б��е�ֵ
LIKE
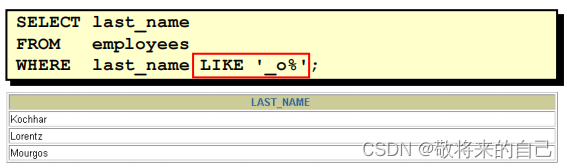
- ʹ�� LIKE ����ѡ�����Ƶ�ֵ
- ѡ�������������ַ�������:
��% ������������ַ�(������ַ�)��
��_ ����һ���ַ���

- ��%���͡�-������ͬʱʹ�á�
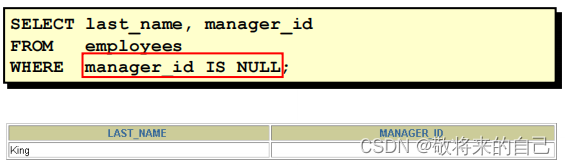
NULL
ʹ�� IS (NOT) NULL �жϿ�ֵ��
������
| ������ | ���� |
|---|---|
| AND | ���� |
| OR | ���� |
| NOT | ���� |
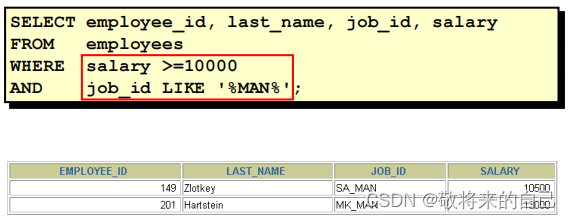
AND
AND Ҫ�Ĺ�ϵΪ�档
OR
OR Ҫ����ϵΪ�档
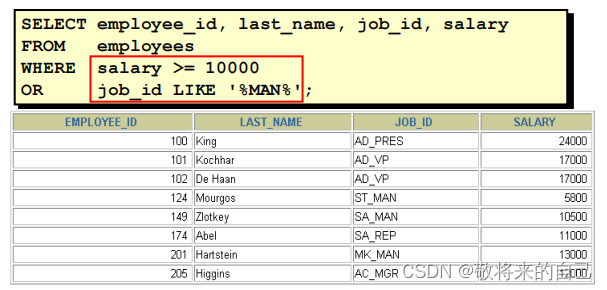
NOT
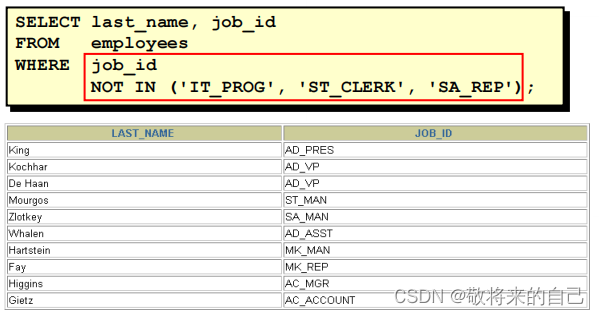
����
? ʹ�� ORDER BY �Ӿ�����
�C ASC(ascend): ����
�C DESC(descend): ����
? ORDER BY �Ӿ���SELECT���Ľ�β��
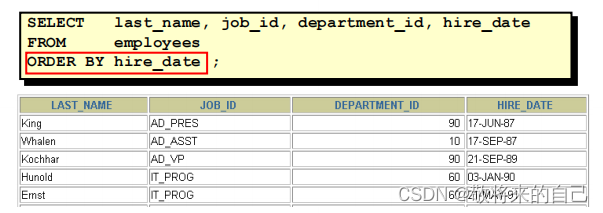
��������
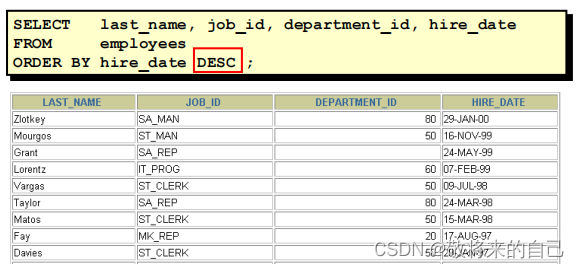
����������
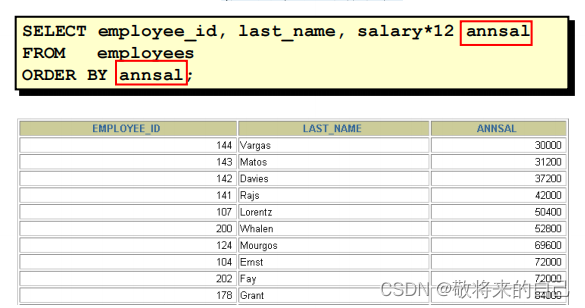
���������
? ����ORDER BY �б���˳������
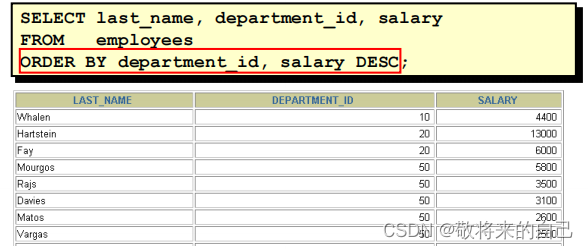
? ����ʹ�ò���SELECT �б��е�������
���麯��
ʲô�Ƿ��麯��
���麯��������һ������,����һ�����ݷ���һ��ֵ��

�麯������
? AVG()
? COUNT()
? MAX()
? MIN()
? SUM()
- �麯���
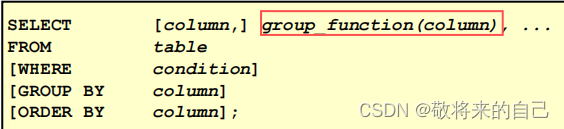
- AVG(ƽ��ֵ)�� SUM (�ϼ�)����
���Զ���ֵ������ʹ��AVG �� SUM ������
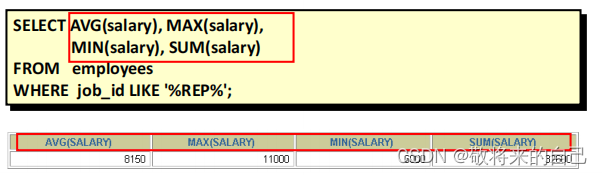
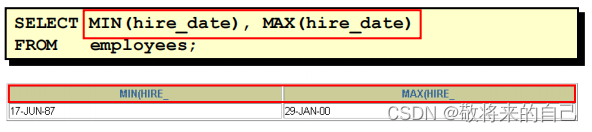
- MIN(��Сֵ)�� MAX(���ֵ)����
���Զ������������͵�����ʹ�� MIN �� MAX ������
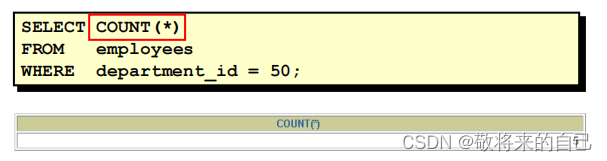
- COUNT(����)����
��COUNT(*) ���ر��м�¼����,�����������������͡�
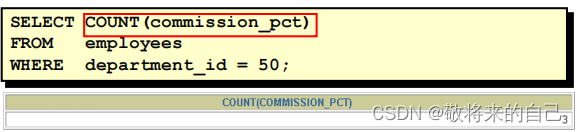
��COUNT(expr) ����expr��Ϊ�յļ�¼������
��������
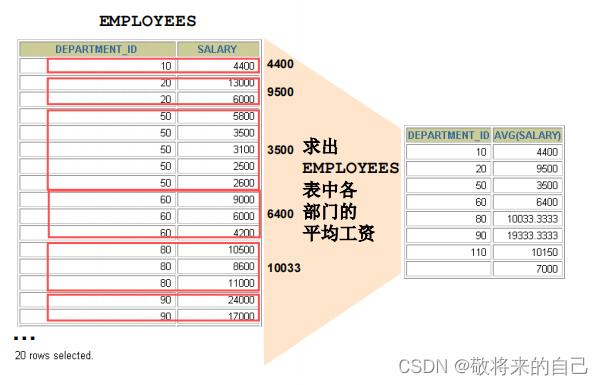
GROUP BY �Ӿ��
1. ����ʹ��GROUP BY�Ӿ佫���е����ݷֳ�������

2. ��SELECT �б�������δ�������麯���е��ж�Ӧ�ð���
�� GROUP BY �Ӿ��С�
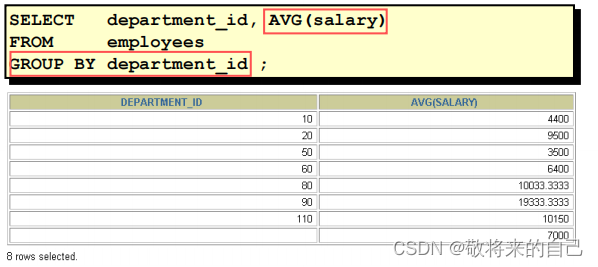
3. ������ GROUP BY �Ӿ��е��в��ذ�����SELECT �б���
ʹ�ö���з���
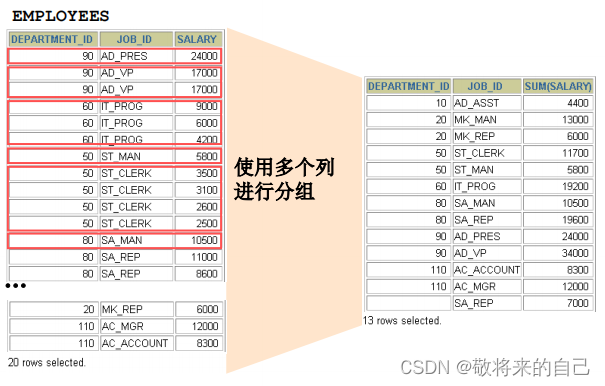
- ��GROUP BY�Ӿ��а��������
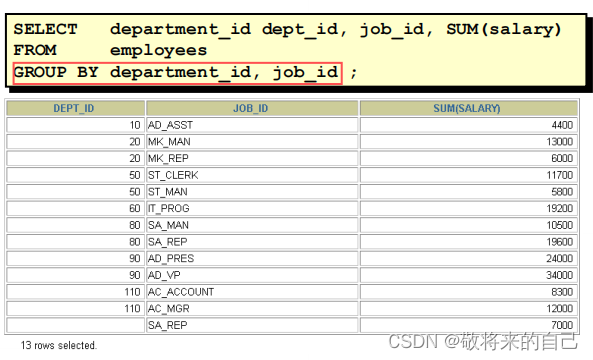
�Ƿ�ʹ���麯��
? ������ WHERE �Ӿ���ʹ���麯����
? ������ HAVING �Ӿ���ʹ���麯����

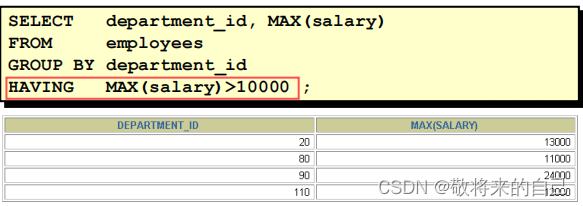
���˷���
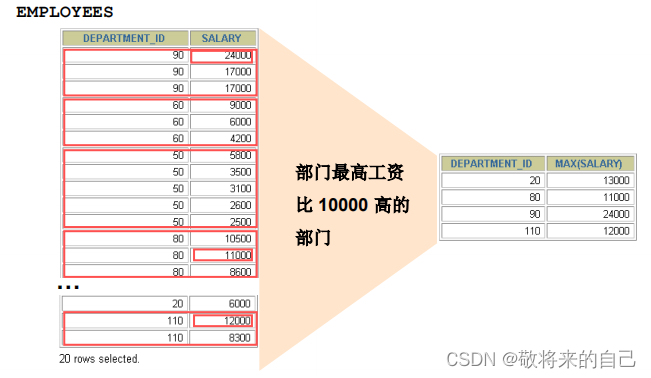
���˷���: HAVING �Ӿ�
- ���Ѿ������顣
- ʹ�����麯����
- ����HAVING �Ӿ��������ķ��齫����ʾ��
�����ѯ
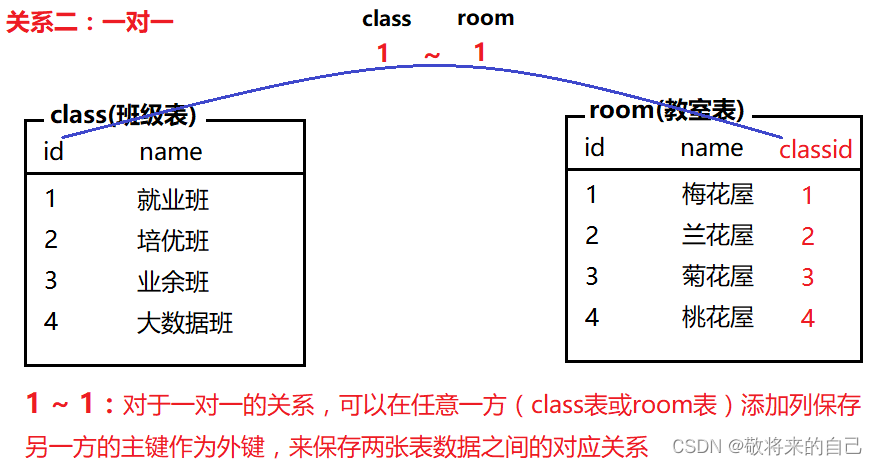
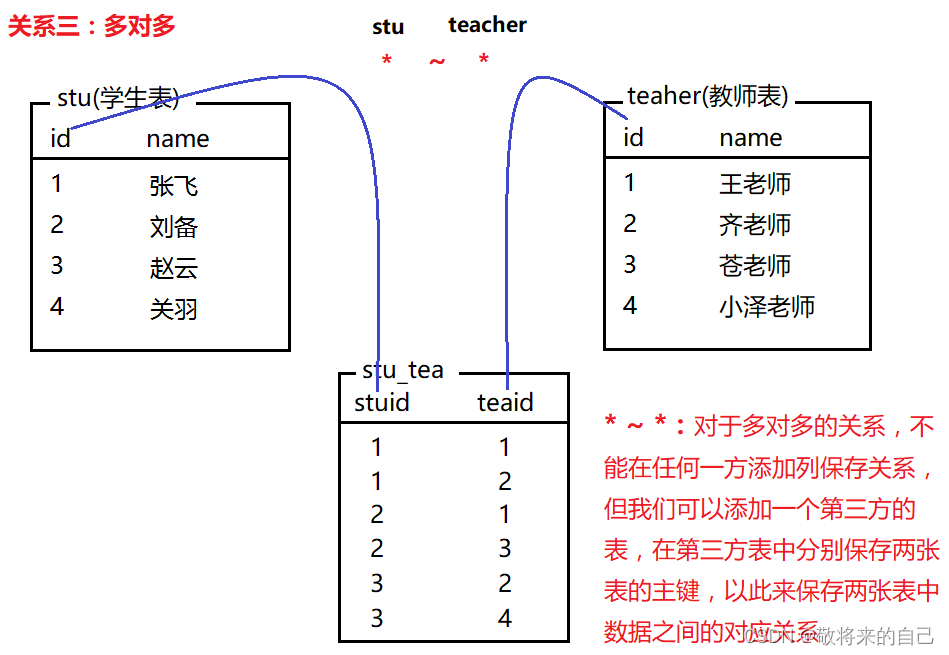
����ϵ
�����ı���ϵ��Ϊ��������:һ�Զ�(���һ)����һ��һ����Զ�
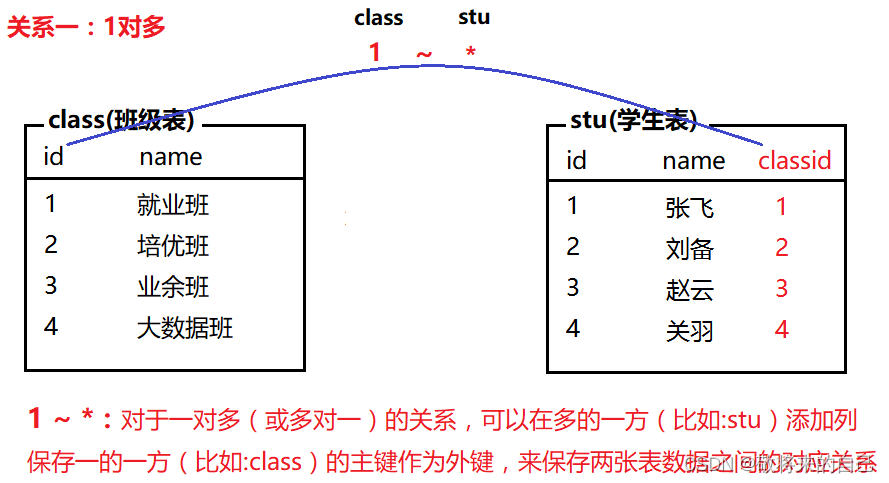
����:
-- ���ű�
create table dept(
id int primary key auto_increment, -- ���
name varchar(14) -- ��������
) ;
-- Ա����
create table emp(
id int primary key auto_increment,-- Ա�����
name varchar(10), -- Ա������ -
dept_id int not null -- ���ű��
);
insert into dept values(10,'����');
insert into dept values(30,'���۲�');
insert into dept values(40,'������');
insert into emp values(1,'��һ',10);
insert into emp values(2,'�¶�',30);
insert into emp values(3,'����',30);
insert into emp values(4,'����',20);
insert into emp values(5,'����',null);
- ��ѯ���źͲ��Ŷ�Ӧ��Ա����Ϣ
select * from dept,emp;
����IJ�ѯ�д��ڴ������������,һ�����Dz���ֱ��ʹ�����ֲ�ѯ��
�ѿ�������ѯ:��ν�ѿ�������ѯ����ָ,��ѯ���ű�,����һ�ű���m����¼,��һ�ű���n����¼,��ѯ�Ľ����m*n����
��Ȼ�ѿ�������ѯ�а���������������,�����ǿ���ͨ��where�Ӿ佫����������,���������ľ�����ȷ���ݡ�
-- ͨ��where�Ӿ佫�ѿ�������ѯ����д����������,������ȷ����!
select * from dept,emp
where emp.dept_id=dept.id;
-- ��Ϊid�����ű��ж�����,����Ϊ������,����������ǰ�����[����.]
ͨ��where�Ӿ佫�ѿ�������ѯ�еĴ���������,������ȷ������,��������Ӳ�ѯ!
- �����ظ�������:
? ʹ�ñ���ǰ�ڶ������������ͬ���С�
? �ڲ�ͬ���о�����ͬ�������п��������ı���
�������֡�
? ���ʹ���˱�����,����select�������Ҫʹ
�����������
? ���������֧��32���ַ�����,������Խ��Խ
�� - ���ı���
? ʹ�ñ������Լ�ѯ��
? ʹ�ñ���ǰ�������ִ��Ч������IJ�ѯ���Ի�������IJ�ѯ:
SELECT bt.id,NAME,boyname
FROM beauty bt,boys b;
WHERE bt.boyfriend_id=b.id ;
������
select * from dept inner join emp
on emp.dept_id=dept.id;
-- �����Ӳ�ѯ,�������������Ӳ�ѯ��ͬ!
��������
��ѯ�����в��š������Ŷ�Ӧ��Ա��,���ij��������û��Ա��,Ա����ʾΪnull
-- ��ѯ�Ľ���ж�����Ա���IJ��ź��в��ŵ�Ա��
select * from dept, emp
where emp.dept_id=dept.id;
-- ���Ҫ��ѯ���ű��е����в���,�Լ����Ŷ�Ӧ��Ա��
select * from dept left join emp
on emp.dept_id=dept.id;
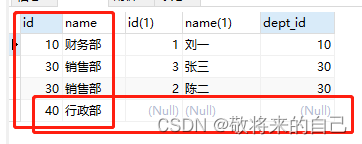
�������Ӳ�ѯ:���Խ���߱��е����м�¼����ѯ����,�ұ߱�ֻ��ʾ��������Ӧ������,�����߱���ijЩ��¼���ұ�û�ж�Ӧ������,�ұ���ʾΪnull���ɡ�
��������
��ѯ������Ա������Ա�������IJ���,���ij��Ա��û����������,������ʾΪnull����
-- ��ѯ�Ľ���ж�����Ա���IJ��ź��в��ŵ�Ա��
select * from dept, emp
where emp.dept_id=dept.id;
-- ���Ҫ��ѯ����Ա����Ա����Ӧ�IJ���
select * from dept right join emp
on emp.dept_id=dept.id;
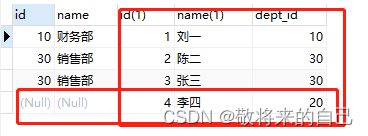
�������Ӳ�ѯ:���Խ��ұ߱��е����м�¼����ѯ����,��߱�ֻ��ʾ���ұ����Ӧ������,����ұ߱���ijЩ��¼�����û�ж�Ӧ������,������ʾΪnull��
��չ:����뽫���ű��е��������ݶ���ѯ����(����+���Ⲣȥ���ظ���¼),����ʹ��ȫ�����Ӳ�ѯ,����mysql�ֲ�֧��ȫ�����Ӳ�ѯ��
select * from dept left join emp on emp.dept_id=dept.id
union
select * from dept right join emp on emp.dept_id=dept.id;
����ʹ��union���������Ӳ�ѯ�Ľ�����������Ӳ�ѯ�Ľ���ϲ���һ��,��ȥ���ظ��ļ�¼������
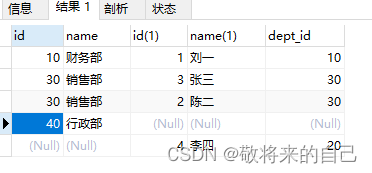
��Ҫע�����:union���Խ�����SQL���ִ�еĽ���ϲ�,������ǰ��:
1)����SQL����ѯ�Ľ����������һ��
2)����SQL����ѯ�Ľ��������˳��Ҳ����һ��
����unionĬ�ϾͻὫ������ѯ���ظ��ļ�¼ȥ��(�����ϣ��ȥ���ظ���¼,����ʹ��union all)��
���Ӷ����
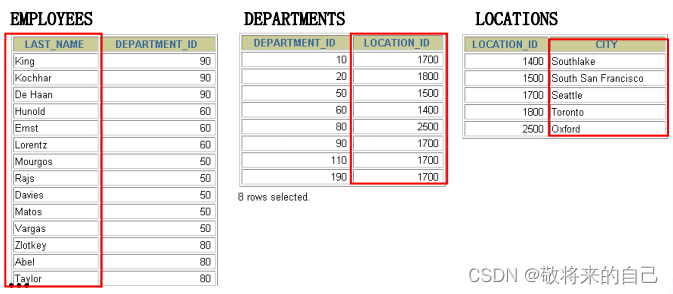
? ���� n����,������Ҫ n-1������������ ����:����������,������Ҫ��������������
SQL99:ʹ��ON �Ӿ䴴������
? ��Ȼ���������Ծ�����ͬ���ֵ���Ϊ���������ġ�
? ����ʹ�� ON �Ӿ�ָ�����������������
? ������������������������ֿ��ġ�
? ON �Ӿ�ʹ�����и��ߵ����ԡ�
Join�����ܽ�
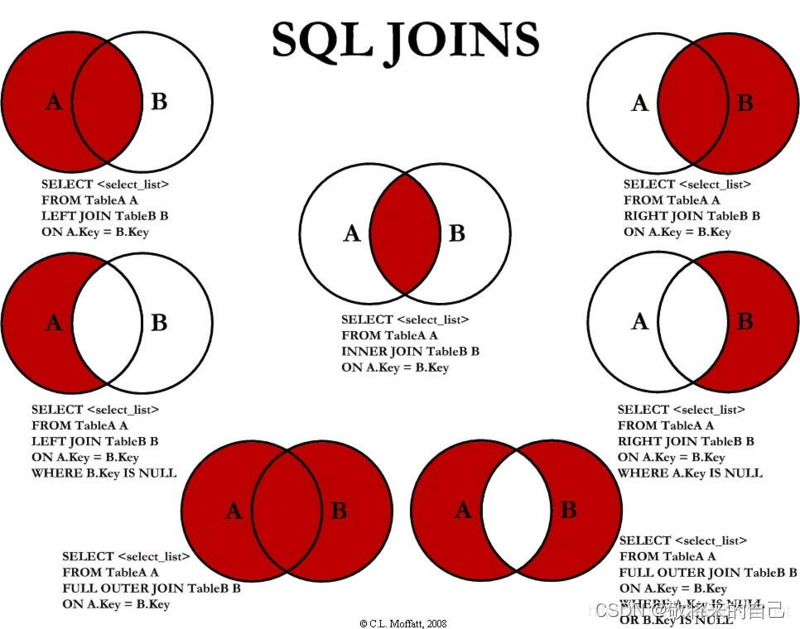
�����³�������:
�ַ�����
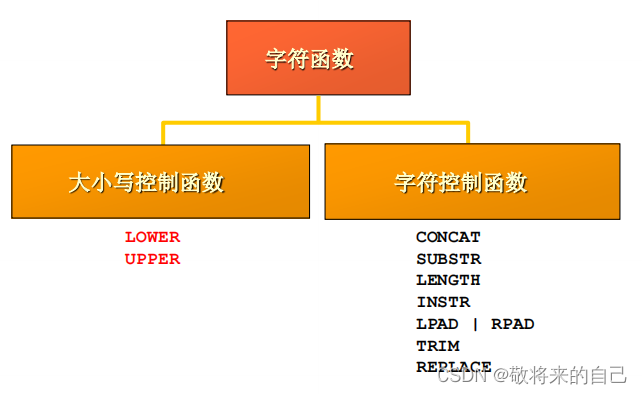
- ��Сд���ƺ��� : ���ຯ���ı��ַ��Ĵ�Сд��
| ���� | ��� |
|---|---|
| LOWER(��SQL Course��) | sql course |
| UPPER(��SQL Course��) | SQL COURSE |
- �ַ����ƺ���: ���ຯ�������ַ�:
| ���� | ��� |
|---|---|
| CONCAT(��Hello��, ��World��) | HelloWorld |
| SUBSTR(��HelloWorld��,1,5) | Hello |
| LENGTH(��HelloWorld��) | 10 |
| INSTR(��HelloWorld��, ��W��) | 6 |
| LPAD(salary,10,��*��) | *****24000 |
| RPAD(salary, 10, ��*��) | 24000***** |
| TRIM(��H�� FROM ��HelloWorld��) | elloWorld |
| REPLACE(��abcd��,��b��,��m��) | amcd |
��ѧ����
? ROUND: ��������

? TRUNCATE: �ض�

? MOD: ����

���ں���
? now:��ȡ��ǰ����
? str_to_date: �����ڸ�ʽ���ַ�ת����ָ����ʽ������
STR_TO_DATE(��9-13-1999��,��%m-%d-%Y��)
1999-09-13
? date_format:������ת�����ַ�
DATE_FORMAT(��2018/6/6��,��%Y��%m��%d�ա�)
2018��06��06��
| ��ʽ�� | ���� |
|---|---|
| %Y | ������ |
| %y | 2���� |
| %m | �·�(01,02��11,12) |
| %c | �·�(1,2,��11,12) |
| %d | ��(01,02,��) |
| %H | Сʱ(24Сʱ��) |
| %h | Сʱ(12Сʱ��) |
| %i | ����(00,01��59) |
| %s | ��(00,01,��59) |
��������ʽ
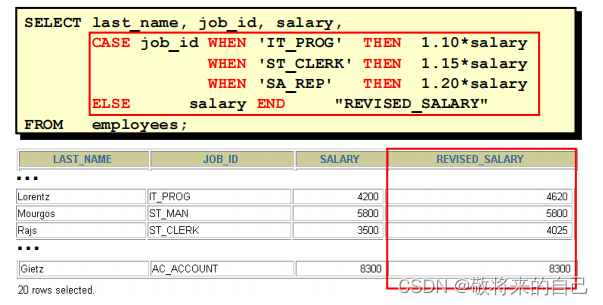
? �� SQL �����ʹ��IF-THEN-ELSE ��
? ʹ�÷���: �C CASE ����ʽ
CASE expr WHEN comparison_expr1 THEN return_expr1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
�������Ӳ�ѯ:
����:
��������������ڲ���select���,��Ϊ�Ӳ�ѯ���ڲ�ѯ
�ڲ�Ƕ������select���IJ�ѯ,��Ϊ���ѯ������ѯ
ʾ��:
select first_name from employees where
department_id in(
select department_id from departments
where location_id=1700
)
ע������:
? �Ӳ�ѯҪ�����������ڡ�
? ���Ӳ�ѯ���ڱȽ��������Ҳࡣ
? ���в�������Ӧ�����Ӳ�ѯ,���в�������Ӧ
�����Ӳ�ѯ
�Ӳ�ѯ����
�����Ӳ�ѯ
? ֻ����һ�С�
? ʹ�õ��бȽϲ�������
| ������ | ���� |
|---|---|
| = | Equal to |
| > | Greater than |
| >= | Greater than or equal to |
| < | Less than |
| <= | Less than or equal to |
| <> | Not equal to |
�Ӳ�ѯ�
? �Ӳ�ѯ (�ڲ�ѯ) ������ѯ֮ǰһ��ִ����ɡ�
? �Ӳ�ѯ�Ľ��������ѯ(���ѯ)ʹ�� ��
ʹ���Ӳ�ѯ�������
˭�Ĺ��ʱ� Abel ��?

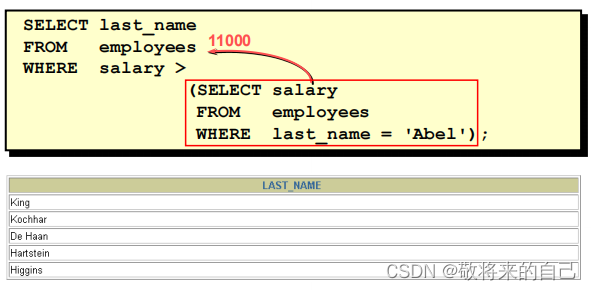
�Ӳ�ѯ�е� HAVING �Ӿ�
? ����ִ���Ӳ�ѯ��
? ������ѯ�е�HAVING �Ӿ䷵�ؽ����
�����Ӳ�ѯ
? ���ض��С�
? ʹ�ö��бȽϲ�������
| ������ | ���� |
|---|---|
| IN/NOT IN | �����б��е�����һ�� |
| ANY|SOME | ���Ӳ�ѯ���ص�ijһ��ֵ�Ƚ� |
| ALL | ���Ӳ�ѯ���ص�����ֵ�Ƚ� |
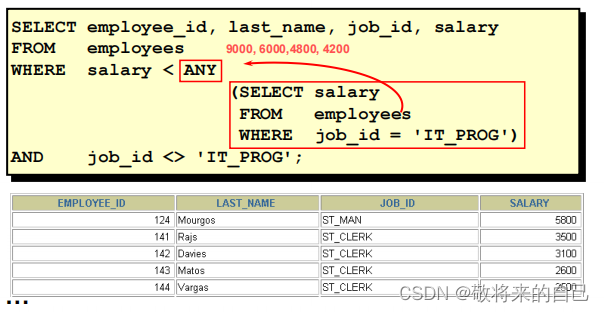
ʹ�� ANY ������:
ʹ�� ALL ������
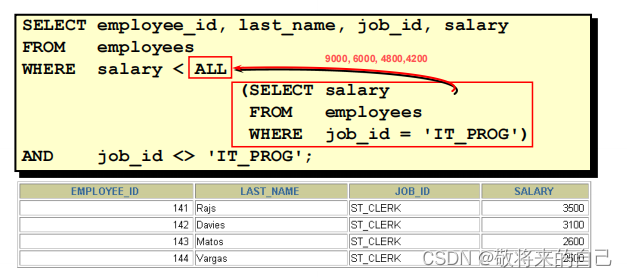
�� ��:�ڲ�ѯʱ����δ֪��ֵʱ,Ӧʹ���Ӳ�ѯ��
�ڰ�����������:
����
| �������� | �ֽ� | ��Χ |
|---|---|---|
| Tinyint | 1 | ���:-128~127 ����:0~255 |
| Smallint | 2 | ���:-32768~32767 ����:0~65535 |
| Mediumint | 3 | �з���:-8388608~8388607 ����:0~1677215 (�ð�,�����ܴ�,���ü�ס) |
| Int��integer | 4 | �з���:- 2147483648~2147483647 ����:0~4294967295 (�ð�,�����ܴ�,���ü�ס) |
| Bigint | 8 | �з���: -9223372036854775808 ~9223372036854775807 ����:0~ 9223372036854775807*2+1 (�ð�,�����ܴ�,���ü�ס) |
��
| ���������� | �ֽ� | ��Χ |
|---|---|---|
| float | 4 | ��1.75494351E-38~��3.402823466E+38(�ð�,�����ܴ�,���ü�ס) |
| double | 8 | ��2.2250738585072014E-308~ ��1.7976931348623157E+308(�ð�,�����ܴ�,���ü�ס) |
| ���������� | �ֽ� | ��Χ |
| DEC(M,D)DECIMAL(M,D) | M+2 | ���ȡֵ��Χ��double��ͬ,����decimal����Чȡֵ��Χ��M��D���� |
���
| λ���� | �ֽ� | ��Χ |
|---|---|---|
| Bit(M) | 1~8 | Bit(1)~bit(8) |
char��varchar���� ˵��:��������MySQL�н϶̵��ַ���
| �ַ������� | ����ַ��� | �������洢���� |
|---|---|---|
| char(M) | M | MΪ0~255֮������� |
| varchar(M) | M | MΪ0~65535֮������� |
binary��varbinary����
˵��:������char��varchar,��ͬ�������ǰ����������ַ������������Ƕ�
�����ַ���
Enum����
˵��:�ֳ�Ϊö������Ŷ,Ҫ������ֵ���������б���ָ����ֵ֮һ��
����б���ԱΪ1~255,����Ҫ1���ֽڴ洢
����б���ԱΪ255~65535,����Ҫ2���ֽڴ洢
�����Ҫ65535����Ա
Set����
˵��:��Enum��������,������Ա���0~64����Ա����Enum����������
����:SET����һ�ο���ѡȡ�����Ա,��Enumֻ��ѡһ��
���ݳ�Ա������ͬ,�洢��ռ���ֽ�Ҳ��ͬ
| ��Ա�� | �ֽ��� |
|---|---|
| 1~8 | 1 |
| 9~16 | 2 |
| 17~24 | 3 |
| 25~32 | 4 |
| 33~64 | 8 |
��������
| ���ں�ʱ������ | �ֽ� | ��Сֵ | ���ֵ |
|---|---|---|---|
| date | 4 | 1000-01-01 | 9999-12-31 |
| datetime | 8 | 1000-01-01 00:00:00 | 9999-12-31 23:59:59 |
| timestamp | 4 | 19700101080001 | 2038���ij��ʱ�� |
| time | 3 | -838:59:59 | 838:59:59 |
| year | 1 | 1901 | 2155 |
datetime��timestamp������
1��Timestamp֧�ֵ�ʱ�䷶Χ��С,ȡֵ��Χ:19700101080001����2038���ij��ʱ��Datetime��ȡֵ��Χ:1000-1-1 ����9999��12-31
2��timestamp��ʵ��ʱ���й�,���ܷ�ӳʵ�ʵ�����,��datetime��ֻ�ܷ�ӳ������ʱ�ĵ���ʱ��
3��timestamp��������Mysql�汾��SQLMode��Ӱ��ܴ�
�ھ���Լ�����ҳ:
ʲô��Լ��
? Ϊ�˱�֤���ݵ�һ���Ժ�������,SQL�淶��Լ���ķ�ʽ�Ա����ݽ��ж�����������ơ�
? Լ���DZ�����ǿ�ƹ涨
? �����ڴ�����ʱ�涨Լ��(ͨ�� CREATE TABLE ���),�����ڱ�����֮��Ҳ����(ͨ�� ALTER TABLE ���)
����������Լ��
�C NOT NULL �ǿ�Լ��,�涨ij���ֶβ���Ϊ��
�C UNIQUE ΨһԼ��,�涨ij���ֶ�������������Ψһ��
�C PRIMARY KEY ����(�ǿ���Ψһ) �C FOREIGN KEY ���
�C CHECK ���Լ��
�C DEFAULT Ĭ��ֵ
ע��: MySQL��֧��checkԼ��,������ʹ��checkԼ��,��û���κ�Ч��
? ����Լ�������е�����,Լ���ɷ�Ϊ:
�C ����Լ��:ÿ��Լ��ֻԼ��һ��
�C ����Լ��:ÿ��Լ����Լ����������
? ����Լ�������÷�Χ,Լ���ɷ�Ϊ:
�C �м�Լ��ֻ��������һ������,�����еĶ������
�C ����Լ�����������ڶ������,������һ��,���ǵ�������
NOT NULL Լ��
- �ǿ�Լ������ȷ����ǰ�е�ֵ��Ϊ��ֵ,�ǿ�Լ��ֻ�ܳ����ڱ���������ϡ�
- Null��������:
�����е����͵�ֵ��������null,����int��float����������
�ڿ��ַ�������������null,0Ҳ������null
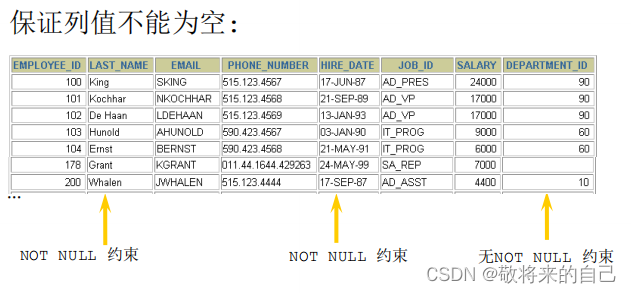
һ������ not null Լ��:
CREATE TABLE emp(
id INT(10) NOT NULL,
NAME VARCHAR(20) NOT NULL DEFAULT ��abc��,
sex CHAR NULL
);
�������� not null Լ��:
ALTER TABLE emp
MODIFY sex VARCHAR(30) NOT NULL;
����ȡ�� not null Լ��:
ALTER TABLE emp
MODIFY sex VARCHAR(30) NULL;
�ġ�ȡ�� not null Լ��,����Ĭ��ֵ:
ALTER TABLE emp
MODIFY NAME VARCHAR(15) DEFAULT ��abc�� NULL;
UNIQUE Լ��
? ΨһԼ��,�������ֶ����ֵ:NULL��
? ͬһ���������ж��ΨһԼ��,�������ϵ�Լ����
�ڴ���ΨһԼ����ʱ��,�������ΨһԼ������,��
Ĭ�Ϻ�������ͬ��
? MySQL���ΨһԼ��������Ĭ�ϴ���һ��Ψһ����
CREATE TABLE USER(
id INT NOT NULL,
NAME VARCHAR(25),
PASSWORD VARCHAR(16),
#ʹ�ñ���Լ���
CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD)
);
? ��ʾ�û�����������ϲ����ظ�
һ������ΨһԼ��
ALTER TABLE USER
ADD UNIQUE(NAME,PASSWORD);
ALTER TABLE USER
ADD CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD) ;
ALTER TABLE USER
MODIFY NAME VARCHAR(20) UNIQUE;
����ɾ��Լ��
ALTER TABLE USER
DROP INDEX uk_name_pwd;
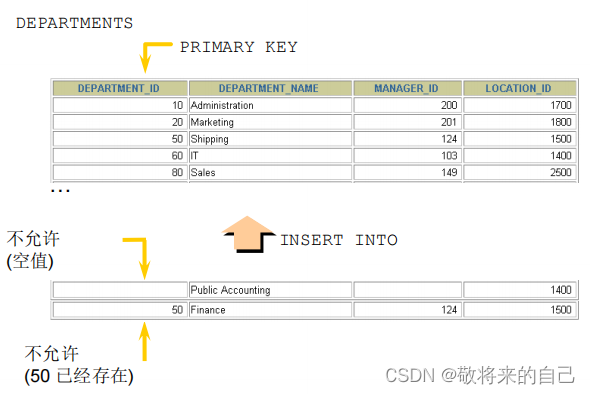
PRIMARY KEY Լ��
? ����Լ���൱��ΨһԼ��+�ǿ�Լ�������,����Լ���в������ظ�,Ҳ���������ֿ�ֵ
? ����Ƕ�����ϵ�����Լ��,��ô��Щ�ж�������Ϊ��ֵ,������ϵ�ֵ�������ظ���
? ÿ�������ֻ����һ������,��������Լ���������м���,Ҳ�����ڱ������ϴ�����
? MySQL������������PRIMARY,����������Լ��ʱ,ϵͳĬ�ϻ������ڵ��к�������Ͻ�����Ӧ��Ψһ������
- �м�ģʽ
CREATE TABLE emp4(
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(20)
);
- ����ģʽ
CREATE TABLE emp5(
id INT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20),
pwd VARCHAR(15),
CONSTRAINT emp5_id_pk PRIMARY KEY(id)
);
- ���ģʽ
CREATE TABLE emp6(
id INT NOT NULL,
NAME VARCHAR(20),
pwd VARCHAR(15),
CONSTRAINT emp7_pk PRIMARY KEY(NAME,pwd)
);
һ��ɾ������Լ��
ALTER TABLE emp5
DROP PRIMARY KEY;
������������Լ��
ALTER TABLE emp5
ADD PRIMARY KEY(NAME,pwd);
����������Լ��
ALTER TABLE emp5
MODIFY id INT PRIMARY KEY;
FOREIGN KEY Լ��

? ���Լ���DZ�֤һ����������֮��IJ���������,����ǹ�����һ�����������ֶλ����������������ֶ�֮��IJ��չ�ϵ��
? �ӱ������ֵ���������������ҵ�����Ϊ�ա��������ļ�¼���ӱ�����ʱ,�����ļ�¼��������ɾ��,���Ҫɾ������,��Ҫ��ɾ���ӱ��������ü�¼������,Ȼ��ſ���ɾ�����������ݡ�
? ����һ�־��Ǽ���ɾ���ӱ����ݡ�
? ע��:���Լ���IJ�����,�����������õ�ֻ����������Ψһ��Լ������
? ͬһ���������ж�����Լ��
һ���������Լ��:
����
CREATE TABLE dept(
dept_id INT AUTO_INCREMENT PRIMARY KEY,
dept_name VARCHAR(20)
);
�ӱ�
CREATE TABLE emp(
emp_id INT AUTO_INCREMENT PRIMARY KEY,
last_name VARCHAR(15),
dept_id INT,
); CONSTRAINT emp_dept_id_fk FOREIGN KEY(dept_id)
REFERENCES dept(dept_id)
������������������,����ʹ�ñ���Լ��:
����
CREATE TABLE classes(
id INT,
NAME VARCHAR(20),
number INT,
PRIMARY KEY(NAME,number)
);
�ӱ�
CREATE TABLE student(
id INT AUTO_INCREMENT PRIMARY KEY,
classes_name VARCHAR(20),
classes_number INT,
FOREIGN KEY(classes_name,classes_number)
REFERENCES classes(NAME,number)
);
����ɾ�����Լ��:
ALTER TABLE emp
DROP FOREIGN KEY emp_dept_id_fk;
�ġ��������Լ��:
ALTER TABLE emp
ADD [CONSTRAINT emp_dept_id_fk] FOREIGN KEY(dept_id)
REFERENCES dept(dept_id);
FOREIGN KEY Լ���Ĺؼ���
�C FOREIGN KEY: �ڱ���ָ���ӱ��е���
�C REFERENCES: ��ʾ�ڸ����е���
�CON DELETE CASCADE(����ɾ��): �������е��б�ɾ��
ʱ,�ӱ������Ӧ����Ҳ��ɾ��
�CON DELETE SET NULL(�����ÿ�): �ӱ�����Ӧ�����ÿ�
CREATE TABLE student(
id INT AUTO_INCREMENT PRIMARY KEY,
NAME VARCHAR(20),
classes_name VARCHAR(20),
classes_number INT,
/�������������/
FOREIGN KEY(classes_name, classes_number)
REFERENCES classes(NAME, number) ON DELETE CASCADE);
CHECK Լ��
? MySQL����ʹ��checkԼ��,��checkԼ����������֤û���κ�����,��������ʱ,û���κδ����
CREATE TABLE temp(
id INT AUTO_INCREMENT,
NAME VARCHAR(20),
age INT CHECK(age > 20),
PRIMARY KEY(id)
);
��ҳ
MySQL��ʹ��limitʵ�ַ�ҳ
? ����
��ѯ���صļ�¼̫����,�鿴�����ܲ�����,��ô���ܹ�ʵ�ַ�ҳ��ѯ��?
? ��ҳԭ��
��ν��ҳ��ʾ,���ǽ����ݿ��еĽ����,һ��һ����ʾ������Ҫ������
? ��ô�ֶ�,��ǰ�ڵڼ���(ÿҳ�м���,��ǰ�ڵڼ�ҳ)
ǰ10����¼:
SELECT * FROM table LIMIT 0,10;
��11��20����¼:
SELECT * FROM table LIMIT 10,10;
��21��30����¼:
SELECT * FROM table LIMIT 20,10;
��ʽ:
(��ǰҳ��-1)*ÿҳ����,ÿҳ����
SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize;
ע��: limit�Ӿ�������������ѯ�������!
��ʮ������:
����:
�����ɵ�����Ԫ��һ������SQL������,�������Ԫ��,ÿ��MySQL�����������ġ� ������������Ԫ��Ϊһ�����ɷָ������,�����Ԫ��ij��SQL���һ
��ִ��ʧ�ܻ��������,������Ԫ����ع��������ܵ�Ӱ������ݽ����ص����↑ʼ��ǰ��״̬;�����Ԫ�е�����SQL����ִ�гɹ�,�����ﱻ˳��ִ�С�
MySQL �еĴ洢����:
1������:��mysql�е������ø��ֲ�ͬ�ļ����洢���ļ�(���ڴ�)�С�
2��ͨ��show engines;���鿴mysql֧�ֵĴ洢���档
3�� ��mysql���õ����Ĵ洢������:innodb,myisam ,memory �ȡ�����innodb֧������,��myisam��memory�Ȳ�֧������
�����ACID(acid)����
-
ԭ����(Atomicity)
ԭ������ָ������һ�����ɷָ�Ĺ�����λ,�����еIJ���Ҫô������,Ҫô���������� -
һ����(Consistency)
�������ʹ���ݿ��һ��һ����״̬�任������һ��һ����״̬�� -
������(Isolation)
����ĸ�������ָһ�������ִ�в��ܱ������������,��һ�������ڲ��IJ�����ʹ�õ����ݶԲ��������������Ǹ����,����ִ�еĸ�������֮�䲻�ܻ�����š� -
�־���(Durability)
�־�����ָһ������һ�����ύ,�������ݿ������ݵĸı���������Ե�,���������������������ݿ���ϲ�Ӧ�ö������κ�Ӱ�� -
�Ե�һ�� DML ����ִ����Ϊ��ʼ
-
�����������֮һ��Ϊ����: ? COMMIT �� ROLLBACK ���
��DDL �� DCL ���(�Զ��ύ)
���û��Ự��������
��ϵͳ�쳣����
���ݿ�ĸ��뼶��
- ����ͬʱ���еĶ������, ����Щ����������ݿ�����ͬ������ʱ, ���û�в�ȡ��Ҫ�ĸ������, �ͻᵼ�¸��ֲ�������:
�� ���: ������������ T1, T2, T1 ��ȡ���Ѿ��� T2 ���µ���û�б��ύ���ֶ�. ֮��, �� T2 �ع�, T1��ȡ�����ݾ�����ʱ����Ч��.
�� �����ظ���: ������������T1, T2, T1 ��ȡ��һ���ֶ�, Ȼ�� T2 �����˸��ֶ�. ֮��, T1�ٴζ�ȡͬһ���ֶ�, ֵ�Ͳ�ͬ��.
�� �ö�: ������������T1, T2, T1 ��һ�����ж�ȡ��һ���ֶ�, Ȼ�� T2 �ڸñ����� ����һЩ�µ���. ֮��, ��� T1 �ٴζ�ȡͬһ����, �ͻ�������. - ���ݿ�����ĸ�����: ���ݿ�ϵͳ������и��벢�����и������������,
ʹ���Dz����Ӱ��, ������ֲ�������. - һ�������������������ij̶ȳ�Ϊ���뼶��. ���ݿ�涨�˶��������
�뼶��, ��ͬ���뼶���Ӧ��ͬ�ĸ��ų̶�, ���뼶��Խ��, ����һ���Ծ�
Խ��, ��������Խ��. - ���ݿ��ṩ�� 4 ��������뼶��:

��Oracle ֧�ֵ� 2 ��������뼶��:READ COMMITED, SERIALIZABLE�� Oracle Ĭ�ϵ�������뼶��Ϊ: READ COMMITED
��Mysql ֧�� 4 ��������뼶��. Mysql Ĭ�ϵ�������뼶��Ϊ: REPEATABLE REA
�� MySql �����ø��뼶��
- ÿ����һ�� mysql ����, �ͻ���һ�����������ݿ�����. ÿ�����ݿ����Ӷ���һ��ȫ�ֱ��� @@tx_isolation, ��ʾ��ǰ��������뼶��.
- �鿴��ǰ�ĸ��뼶��: SELECT @@tx_isolation;
- ���õ�ǰ mySQL ���ӵĸ��뼶��:
. set transaction isolation level read committed;
- �������ݿ�ϵͳ��ȫ�ֵĸ��뼶��:
set global transaction isolation level read committed;
��ʮһ����ͼ:
����:
MySQL��5.0.1�汾��ʼ�ṩ��ͼ���ܡ�һ��������ڵı�,�к��е��������Զ�����ͼ�IJ�ѯ��ʹ�õı�,��������ʹ����ͼʱ��̬���ɵ�,ֻ������sql��,�������ѯ���
Ӧ�ó���:
�C ����ط��õ�ͬ���IJ�ѯ���
�C �ò�ѯ���ʹ�õ�sql���ϸ���
ʾ��:
CREATE VIEW my_v1
AS
SELECT studentname,majorname
FROM student s
INNER JOIN major m
ON s.majorid=m.majorid
WHERE s.majorid=1;
��ͼ�ĺô�:
? ����sql���
? ���ӵ�sql����,����֪�����IJ�ѯϸ��
? ��������,��߰�ȫ��
һ��������ͼ���:
create [or replace] view view_name
As select_statement
[with|cascaded|local|check option]
create view view_name
AS
select * from dept;
��������ͼ���:
alter view view_name
As select_statement
[with|cascaded|local|check option]
alter view view_name
AS
select name from dept;
������ͼ�Ŀɸ����Ժ���ͼ�в�ѯ�Ķ����й�ϵ,�������͵���ͼ�Dz��ܸ��µġ�
? �������¹ؼ��ֵ�sql���:���麯����distinct��group by��having��union����union all
? ������ͼ
? Select�а����Ӳ�ѯ
? join
? fromһ�����ܸ��µ���ͼ
? where�Ӿ���Ӳ�ѯ������from�Ӿ��еı�
�ġ�ɾ����ͼ���:
�û�����һ��ɾ��һ�����߶����ͼ,ǰ���DZ����и���ͼ��dropȨ��
drop view [if exists] view_name,view_name ��[restrict|cascade]
drop view if exists view_name;
�塢�鿴��ͼ���:
show tables;
�����Ҫ��ѯij����ͼ�Ķ���,����ʹ��show create view������в鿴:
show create view view_name;
��ʮ���´洢���̺ͺ���:
����:
���Ⱦ������벢�洢�����ݿ��е�һ��sql���ļ���
ʹ�úô�:
1����Ӧ�ÿ�����Ա�ĺܶ��
2���������������ݿ��Ӧ�÷�����֮��Ĵ���
3����������ݴ�����Ч��
һ�������洢����:
create procedure �洢������ ([proc_parameter[,��]])
[characteristic��]routine_body
delimiter$$
create procedure d(in id varchar(20))
begin
select name from emp
where dept_id=id;
end $$
delimiter ;
����: call �洢������(�����б�)
call d(20);
������������:
create function ������([func_parameter[,��]])
returns type
[characteristic��]routine_body
delimiter $$
create function func1(sid varchar(20)) returns varchar(20) #�ں���������һ��Ҫ����returns ������������
READS SQL DATA #һ��������䲻Ȼ�ᱨ��
begin
declare cid varchar(20); #�ں����ж���һ������,�������պ�������ֵ
select emp.name into cid #�Ѳ�ѯ�����ֵ��cid����
from emp
where emp.dept_id=sid;
return cid; #��������ֵ,����cid
end $$
delimiter;
����: Select ������(�����б�)
select func1(20);
�����Ĵ洢����:
alter procedure �洢������ [charactristic��]
�ġ��ĺ���:
alter function ������ [charactristic��]
�塢ɾ���洢���̻���:
˵��:һ��ֻ��ɾ��һ���洢���̻��ߺ���,����Ҫ���иù��̻�����alter routine Ȩ��
drop procedure [if exists] �洢������
drop function [if exists] ������
�����鿴�洢���̻���
1.�鿴�洢���̻�����״̬:
show {procedure|function} status like �洢���̻�����
2.�鿴�洢���̻����Ķ���:
show create {procedure|function} �洢���̻�����
3.ͨ���鿴information_schema.routines�˽�洢���̺ͺ�������Ϣ(�˽�)
select * from rountines where rounine_name =�洢������|������
��ʮ�������̿��ƽṹ:
case�ṹ������Ϊ����ʽ

case�ṹ������Ϊ���������

ѭ���ṹ
