目录
1、并发数与QPS和平均耗时的关系
在压测思想里面,基本上很少会单独讨论高并发的概念,因为并发并不容易被量化,所以单纯的讨论高并发问题是不现实的。与并发有关的还有另外两个相关的概念,QPS和平均耗时,这也是今天这一章要讨论的内容。
1.1、什么是并发数、QPS、平均耗时avg
在后台开发中,经常要涉及到QPS和并发数的概念。在很多场景下都需要进行压力测试,所以,有必要弄清它们之间的关系。QPS和并发数的概念容易混淆,比如:1秒内并发地来了100个请求,这个100是QPS还是并发数? 来看看它们的含义:
QPS:请求进入的速度
并发数:系统中同时存在的请求数
平均耗时avg:即一个请求从被接收到,到处理完成所耗费的平均时间
1.2、并发数、QPS和平均耗时三者关系
上述三者有一个关系即:并发数=QPS * avg。
这个公式可以这么理解:假设qps=1000,avg=50ms,设并发数为x。那么这x个请求是系统正在处理的,他们平均需要50ms处理完成。那么50ms内系统能处理多少请求呢?就是1000 * 50ms=1000 * 0.05s=50个。也就是当前的并发数x=50。
再比如,每秒钟能处理100个请求(qps)。每个请求处理2秒(avg)。那么每个时刻都有200个请求(并发量)在处理,并发数为200。
系统实时并发数低,并不代表系统的处理能力差。相反,在系统处理较快时,没有请求积压,并发数接近于0。
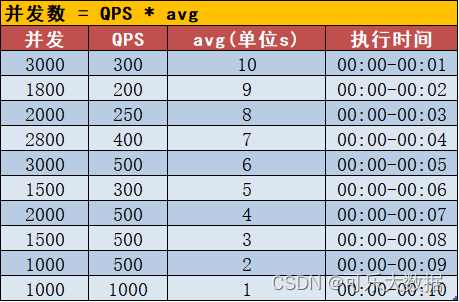
由上图可以很清晰的看到并发数与QPS和平均耗时avg成正相关。如果需要实现高并发的场景,在平均耗时avg不变的情况下,提高QPS是唯一途径。
1.3、QPS和并发数,究竟是何种关系?
我解释的可能并不清楚,大家可以参考涛哥依旧的文章。
https://mp.weixin.qq.com/s/bGwkkQp64V5Pmz0HlKW8cQ
2、Elasticsearch 集群架构
Elasticsearch是一个非常著名的开源搜索和分析系统,目前被广泛应用于互联网多种领域中,尤其是以下三个领域特别突出。一是搜索领域,相对于solr,真正的后起之秀,成为很多搜索系统的不二之选。二是Json文档数据库,相对于MongoDB,读写性能更佳,而且支持更丰富的地理位置查询以及数字、文本的混合查询等。三是时序数据分析处理,目前是日志处理、监控数据的存储、分析和可视化方面做得非常好,可以说是该领域的引领者了。
2.1、Elasticsearch 关键概念
- 节点(Node):物理概念,一个运行的Elasticsearch实例,一般是一台机器上的一个进程。
- 索引(Index),逻辑概念,包括配置信息mapping和倒排正排数据文件,一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。索引的另外一层意思是倒排索引文件。
- 分片(Shard):为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。一个节点(Node)一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种,主分片和副本分片。
- 副本(Replica):同一个分片(Shard)的备份数据,一个分片可能会有0个或多个副本,这些副本中的数据保证强一致或最终一致。
这几个概念的关系可以用如下图形表示:
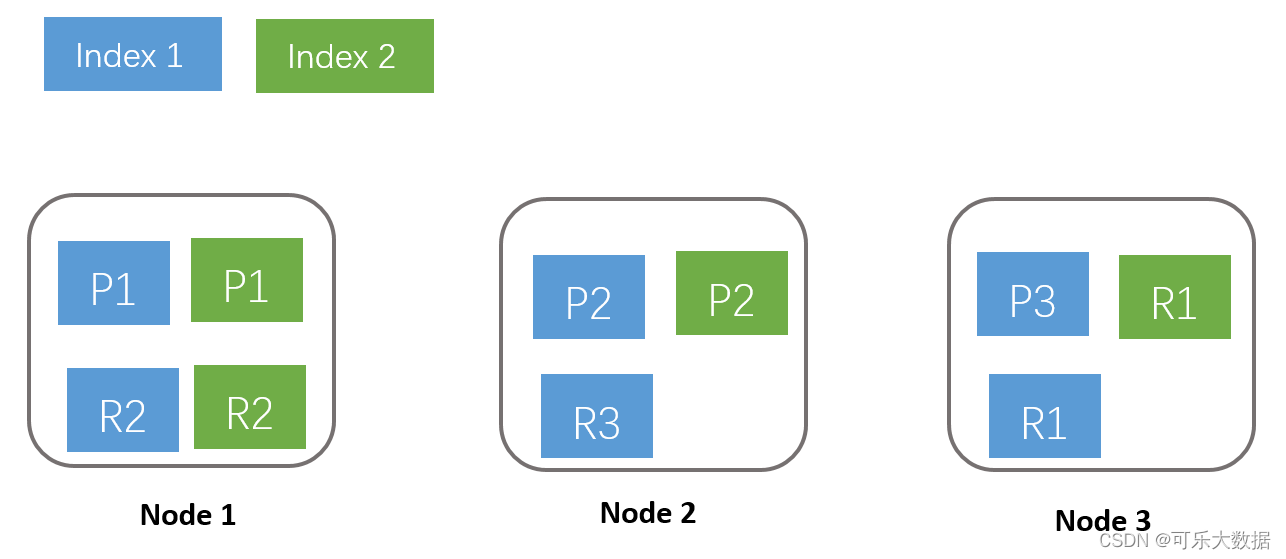
- Index 1:蓝色部分,有3个shard,分别是P1,P2,P3位于3个不同的Node中。并且每个shard有一个replica,分别是R1,R2,R3。
- Index 2:绿色部分,有2个shard,分别是P1,P2,位于2个不同的Node中。并且每个shard有一个replica,分别是R1和R2。
基于系统可用性的考虑,同一个shard的primary和replica不能位于同一个Node中。这里index 2的P1和R1分别位于Node1和Node3中,如果某一刻Node1发生宕机,服务基本不会受影响,因为还有一个P2和R1都还是可用的。因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
2.2、创建索引流程
创建索引(Index)的时候,一个Doc先是经过路由规则定位到主Shard,发送这个doc到主Shard上建索引,成功后再发送这个Doc到这个Shard的副本上建索引,等副本上创建索引成功后才返回成功。
在这种架构中,索引数据全部位于Shard中,主Shard和副本Shard各存储一份。当某个副本Shard或者主Shard丢失(比如机器宕机,网络中断等)时,需要将丢失的Shard在其他Node中恢复回来,这时候就需要从其他副本(Replica)全量拷贝这个Shard的所有数据到新Node上构造新Shard。这个拷贝过程需要一段时间,这段时间内只能由剩余主副本来承载流量,在恢复完成之前,整个系统会处于一个比较危险的状态,直到failover结束。
这里就体现了副本(Replica)存在的一个理由,避免数据丢失,提高数据可靠性。副本(Replica)存在的另一个理由是读请求量很大的时候,一个Node无法承载所有流量,这个时候就需要一个副本来分流查询压力,目的就是扩展查询能力。
3、如何提高并发?
在第一章并发与QPS关系里面我们知道如果需要提高并发, 就需要降低avg平均耗时,或者提高QPS。
3.1、优化分片的数量,控制分片的大小
在7.0.0之前的Elasticsearch版本,默认分片为5,之后版本默认的分片都是1。如果数据量比较大,建议设置多个分片,同理数据量特别小的,建议直接改为1。7.0.0之前的Elasticsearch版本建议不要使用默认值。
目前官网建议一个分片的大小在10G-50G之间,太大的话查询时会比较慢,另外在做副本修复的时,耗时比较多;分片太小的话,会导致一个索引的分片数目很多,查询时带来的fanin-fanout 太大。合理优化分片如果能大幅度降低查询耗时,那对avg平均耗时来说是一个好消息。
3.2、通过横向扩展节点,提高副本数量
在2.2中,我们提到了“副本(Replica)存在的另一个理由是读请求量很大的时候,一个Node无法承载所有流量,这个时候就需要一个副本来分流查询压力,目的就是扩展查询能力。”
所以我们按照这个思路来考虑,先横向扩展Node节点数量,再提高副本的数量,保证每个副本平均分配在一个节点上,不出现互相交叉的情况。在图1的基础上,我们做一次横向扩展看一下效果图,如图2。
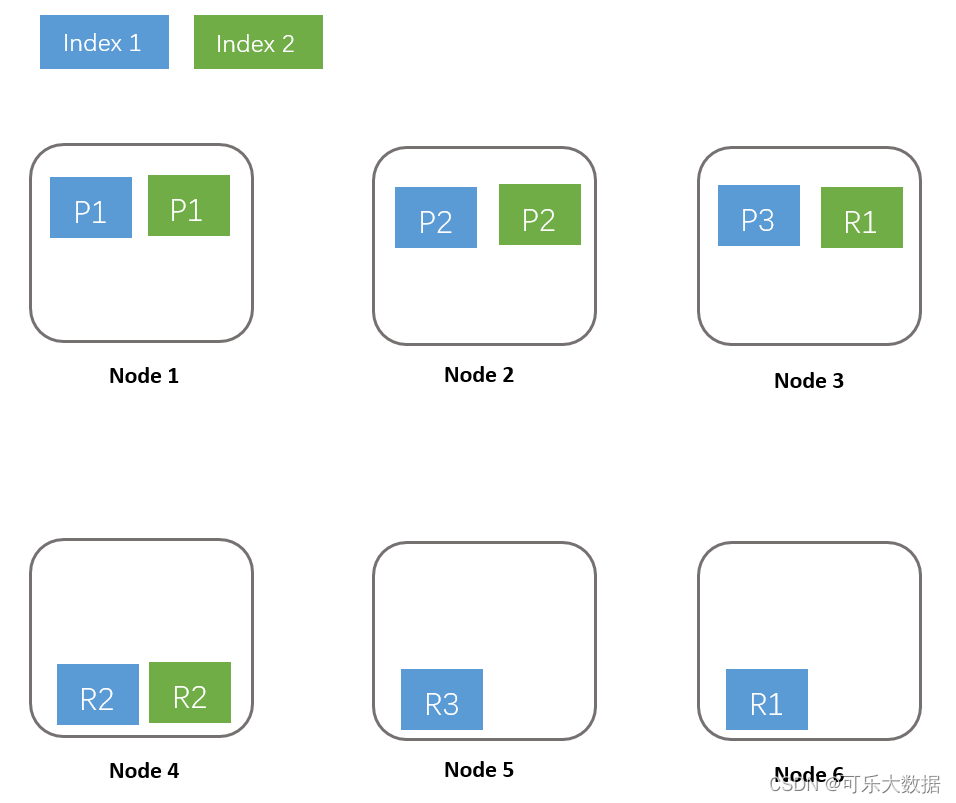
通过上图可以发现,随着横向扩展3个Node节点后,分片数据得到了重新分配。重新分配后的分片,基本上可是实现单个索引单个分片分配在一个节点上。
实践案例中,我们有一个搜索系统索引数据量最大只有2G,整个集群索引也不超过5个。为了提高QPS,我们将集群扩容到133台(配置:16C32G500G),3台为独立master,另外130台为data节点。这套集群当时可以为业务提供18万的QPS,基本上可以满足大促的要求。
4、总结
本文介绍的方案只是个例,很难适配所有业务。但是合并小分片和横向扩展Node节点个数,基本上是百用百灵的方法。但是可能有些业务资源紧张,无法通过增加机器实现横向扩展。不过也不用担心,如果是物理机,我们可以合理重新规划资源,比如:
- 如果是物理机,可以采用单机双实例的方式,将资源做到合理利用;
- master资源消耗少的角色,可以单独享有一个实例,同时分配较少的资源;
- 对于历史数据查询非常低的业务,可以采用冷热分离的方式,将数据定时移动到冷节点;
对于es来说,没有最好的方案,只有最合适的方案。以上只是想法,不构成建议,欢迎评论区讨论。
欢迎各位朋友关注公众号交流
https://mp.weixin.qq.com/s/UY2gjPlUIHLvilOERjMX_A?![]() https://mp.weixin.qq.com/s/UY2gjPlUIHLvilOERjMX_A?
https://mp.weixin.qq.com/s/UY2gjPlUIHLvilOERjMX_A?