?官网链接 https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
?单词计算代码官网链接 https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0
一、下载安装hadoop2.7.1
?下述两种版本任选其一下载,建议下载第二种,不需要做加入.dll和.exe操作,但是空间大。我都下了,使用时,只需要把环境变量路径变一下即可。
?1.版本hadoop2.7.1下载
?链接:
https://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/

emsp;解压 D:\Env\hadoop-2.7.1
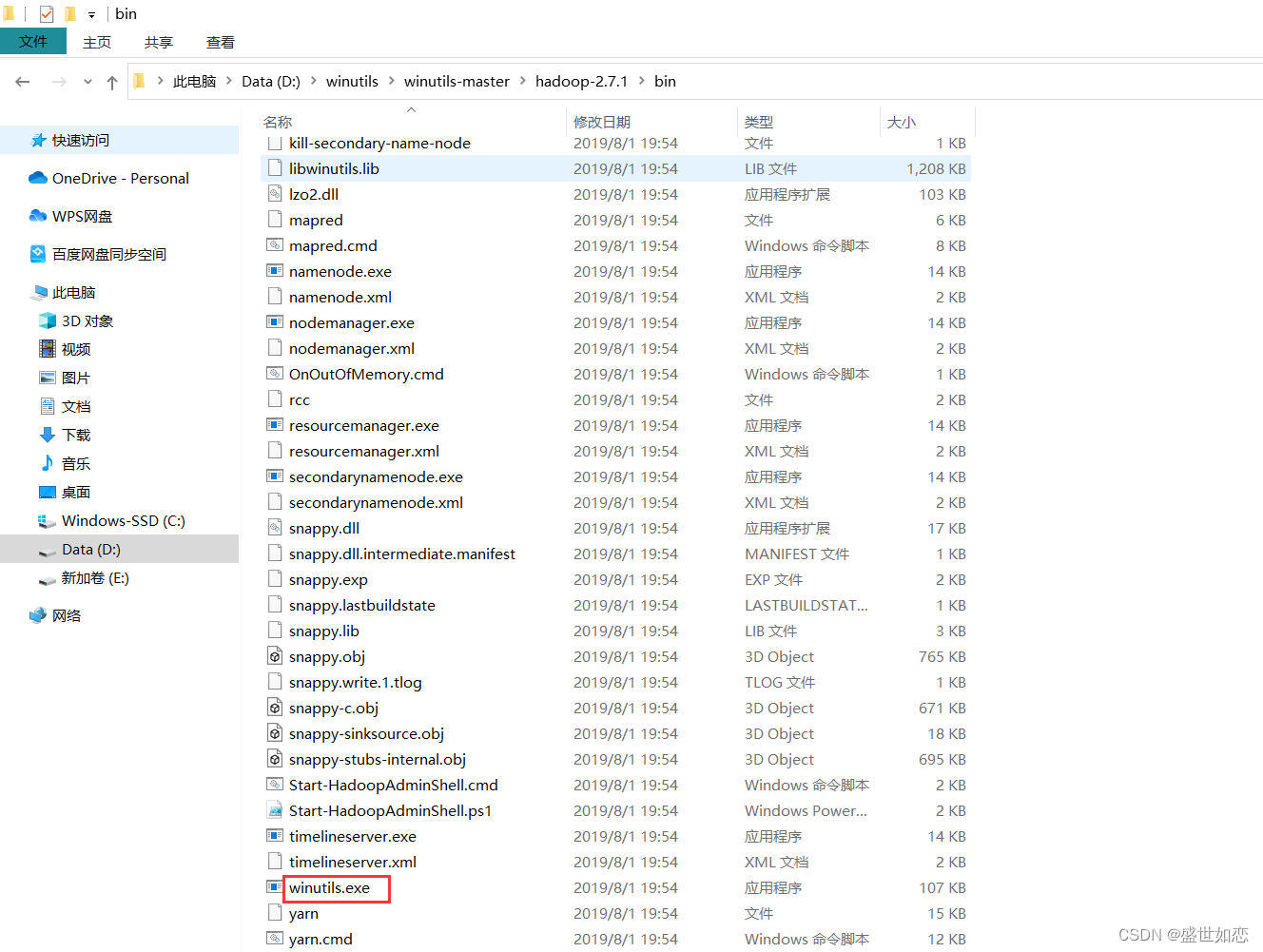
?2.其他版本下载
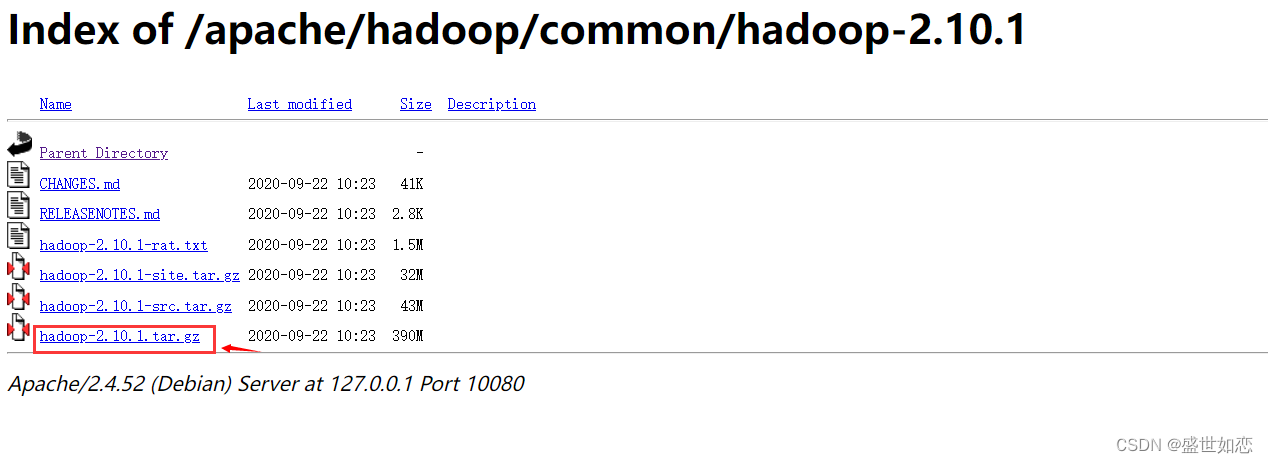
?链接:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
?下面以2.10.1为例:

?我安装的路径D:\Env\hadoop-2.10.2
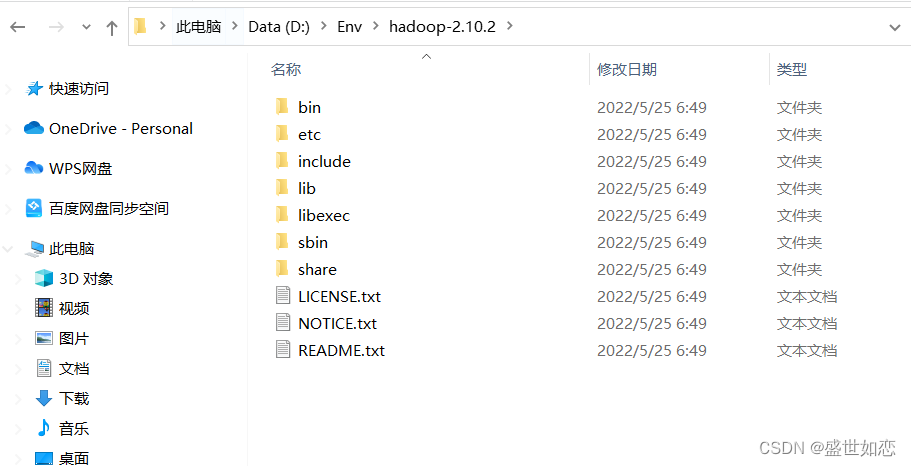
?把这个路径给复制了。
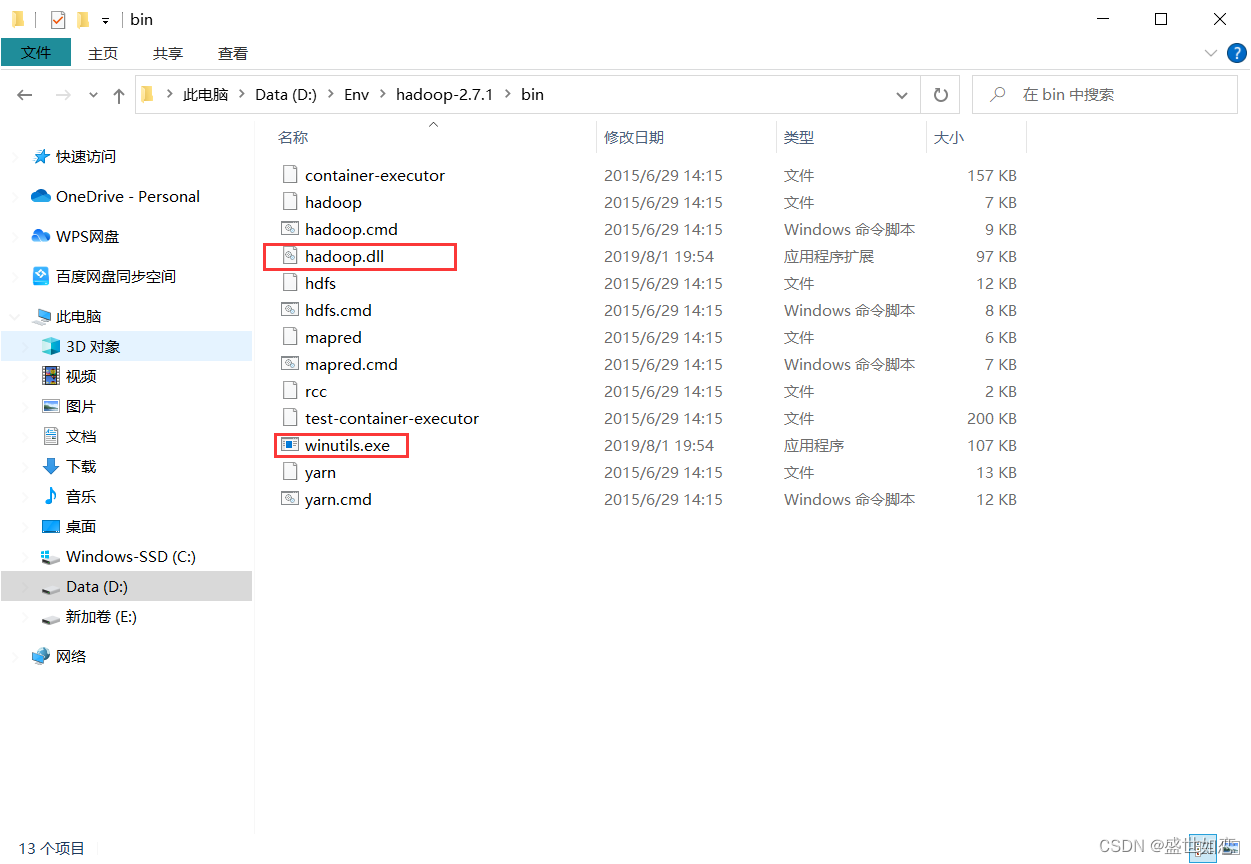
?最后还要添加hadoop.dll和winutils.exe文件到你hadoop的bin目录下
?再此处下载https://github.com/steveloughran/winutils
?解压之后,找到对应版本的放进去
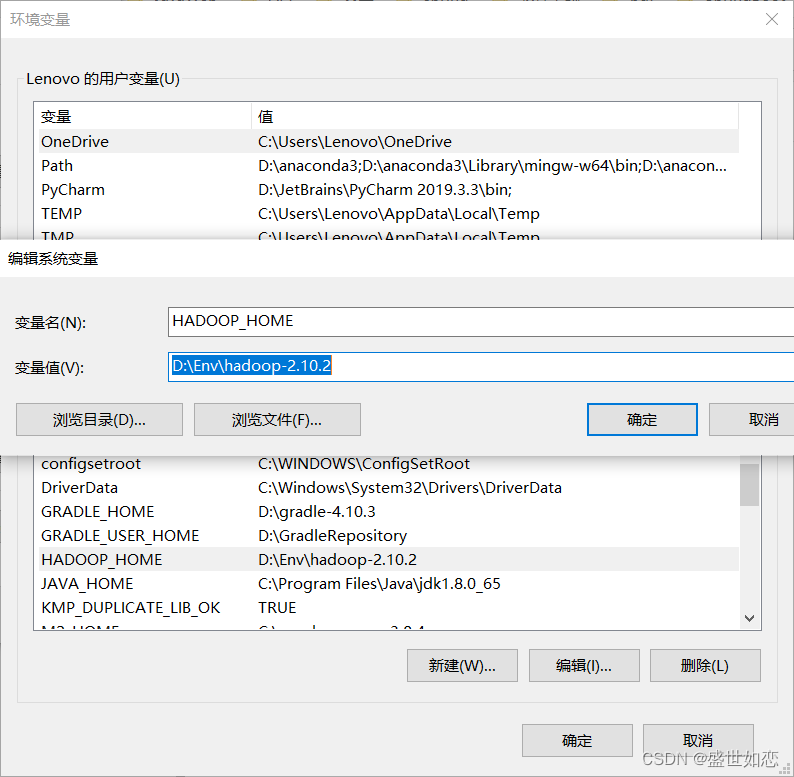
二、配置环境变量
?D:\Env\hadoop-2.10.2
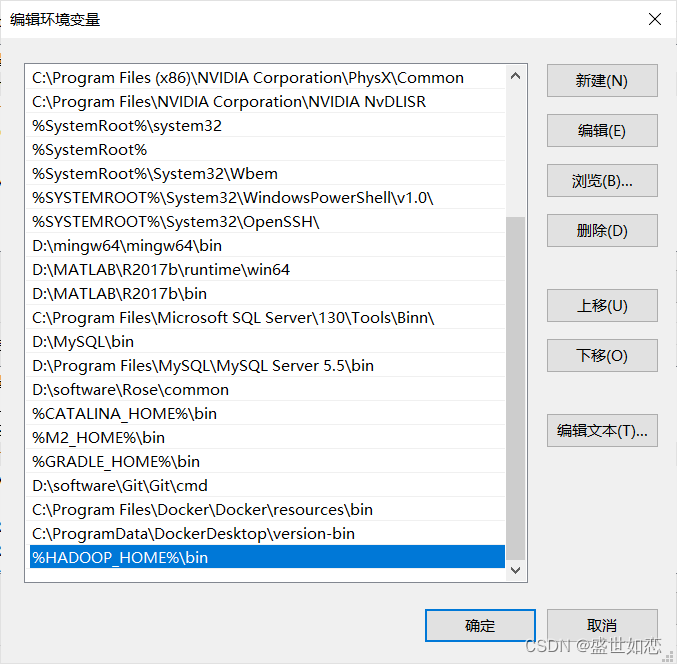
?%HADOOP_HOME%\bin
三、IDEA运行单词计算
?创建一个Maven项目,并且再pom.xml加入如下依赖:
<properties>
<java.version>1.8</java.version>
<!-- <hadoop.version>2.7.1</hadoop.version>-->
<hadoop.version>2.10.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
?创建一个WordCount的类
?官网上也有,只需要把 如下改成自己本地的输入输出地址即可
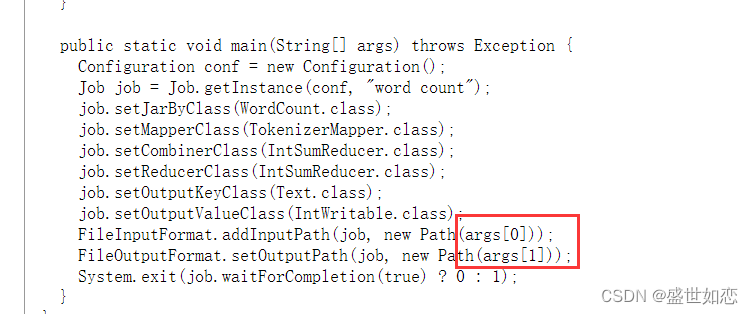
? 测试文件: D:\\test\\a.txt

import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path( "D:\\test\\a.txt" ));
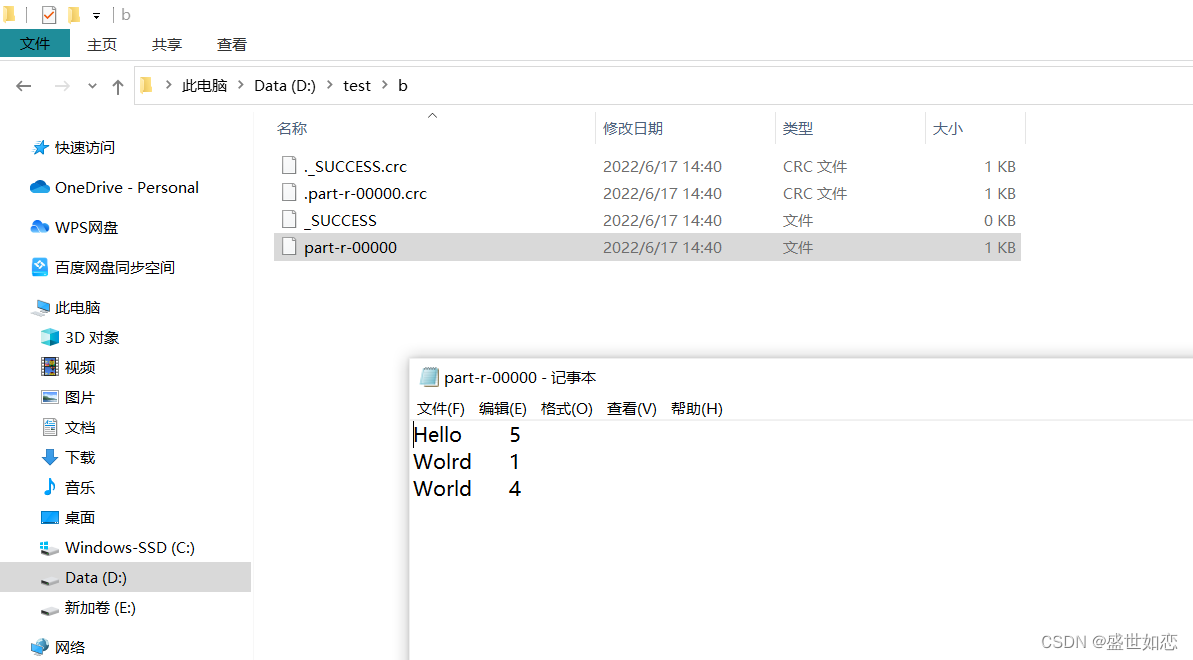
FileOutputFormat.setOutputPath(job, new Path("D:\\test\\b" ));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
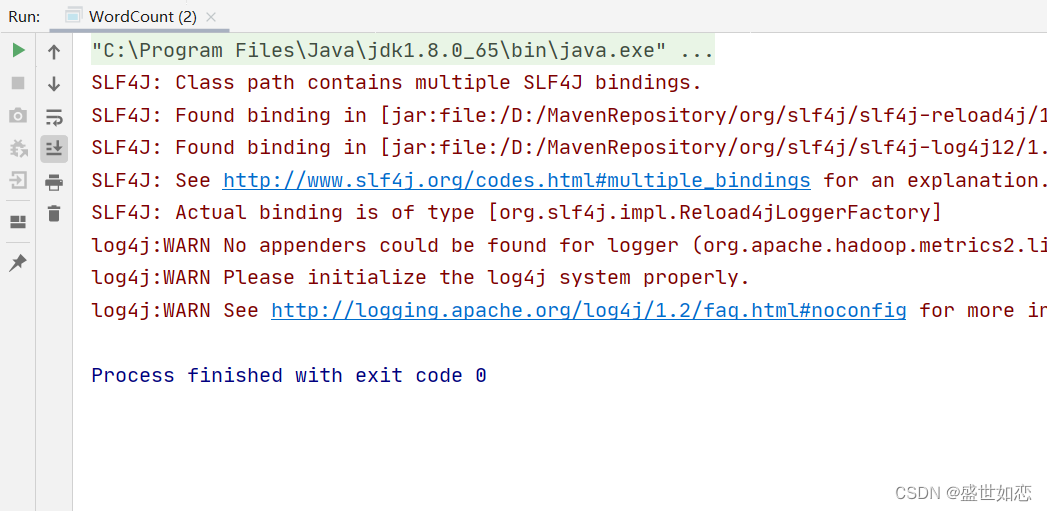
?运行代码: