Hive 支持的文件存储格式
Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式
- TextFile(文本格式)
- RCFile(行列式文件)
- SequenceFile(二进制序列化文件)
- AVRO
- ORC(优化的行列式文件)
- Parquet 格式
使用最多的是TextFile,SequenceFile,ORC和Parquet,今天此篇就从ORC 和 Parquet讲讲这两种文件存储格式,在讲之前再认识下 TextFile 文件存储格式。
TextFile
TextFile 的特点就是行存储文件(每一行就是一条记录),可以使用任意的分隔符进行分割,但是无压缩,所以数据存储空间大。可以结合GZIP,SNAPPY 等使用,但是hive并不会对数据进行切分,所以就无法对数据进行并行处理操作。
总结:TextFile 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
row format delimited fields terminated by '\t'
stored as textfile;
ORC
ORC文件以二进制方式存储,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据。ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储。
列式存储与行列式存储
列式存储,是按照一列一列存储的,如果查询一个列(字段)的数据,就等于是索引查询,效率高。但是如果需要查全表(所有列),因为需要取所有的列最后汇总,反而更占用资源,然而ORC存在以下特点。
特点
(1)在需要全表扫描时,可以按照行组读取。
(2)如果需要取列数据,在行组的基础上,读取指定的列,而不需要所有行组内所有行的数据和一行内所有字段的数据。
所以要看下ORC的存储结构。
ORC的存储结构
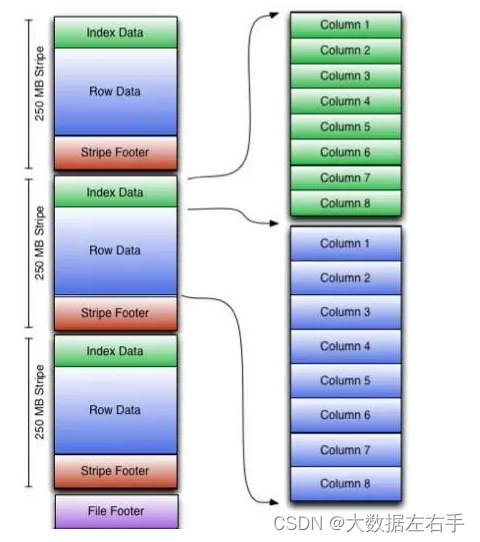
(1)stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
(2)Index Data:存数据的一些统计信息和位置索引信息。
(3)Row Data:数据存储的地方,有多个行组组成。
(4)Stripe Footer:保存文件所在的文目录。
(5)File Footer:文件脚注,包含了文件中stripe的列表,每个stripe的行数和行的数据类型,以及每列的最值和聚合信息。
(6)Poststripe:包含压缩参数大小相关的信息。
ORC提供了3级索引,文件级、条带级(stripe)、行组级,所以在查询的时候,利用这些索引可以规避大部分不满足查询条件的文件和数据块。
ORC的事务ACID
ORC格式的表还支持事务ACID,然而支持事务的表必须是分桶表,这是因为Hive表没有分桶,那么数据文件的散乱的,hive的事务机制无法有效的读取,所以适用于更新大批量的数据,不建议用事务频繁的更新小批量的数据。
Hive 事务支持
(1) 建的表必须是分桶表。
(2)建表的类型文件:stored as orc
(3) tblproperties(‘transactional’=‘true’);
#必须支持分桶
clustered by (id) into 2 buckets
#在表属性中添加支持事务
stored as orc
TBLPROPERTIES('transactional'='true');
其他参数配置
#开启并发支持,支持插入、删除和更新的事务
SET hive.support.concurrency = true;
#支持ACID事务的表必须为分桶表
SET hive.enforce.bucketing = true;
#开启事物需要开启动态分区非严格模式
SET hive.exec.dynamic.partition.mode = nonstrict;
#设置事务所管理类型为 org. apache.hive.q1. lockage. DbTxnManager
#原有的org. apache. hadoop.hive.q1.1 eckmar. DummyTxnManager不支持事务
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
#开启在相同的一个 meatore实例运行初始化和清理的线程
SET hive.compactor.initiator.on = true;
#设置每个 metastore实例运行的线程数 hadoop
SET hive.compactor.worker.threads = 1;
ORC存储与压缩选择
ORC格式存储与Snappy压缩
stored as orc
tblproperties ('orc.compress'='snappy');
注意:
(1) snappy本身是不可切分的。
(2) snappy作用在文本类文件格式上不可切分。
(3) snappy压缩格式作用在parquet、orc等这些文件格式上,能够支持切分。这里切分并不是因为snappy变的可切分了,而是因为这些文件格式可以。
ORC 总结
(1)ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。
(2)文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
(3)提供了多种索引,row group index、bloom filter index。
(4)ORC可以支持复杂的数据结构。
Parquet
Parquet为了使Hadoop生态系统中的任何项目都可以使用压缩的,被称为高效的列式数据表示形式。
特点
(1)跨平台。
(2)可被各种文件系统识别的格式。
(3)按列存储数据。
(4)存储元数据。
Parquet的存储结构
Parquet文件是以二进制方式存储的,所以不可以直接读取,和ORC一样,文件的元数据和数据一起存储,所以Parquet格式文件是自解析的。
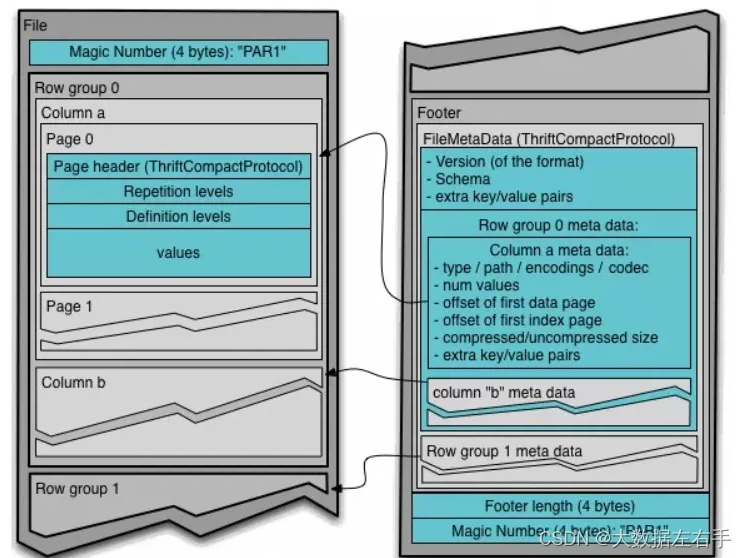
(1)Row Group:每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
(2)Column Chunk:在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)Page:每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
(4)Header:存储文件的校验码。
(5)Footer:存储文件的Schema等信息。
Parquet存储与压缩选择
Parquet格式存储与Lzo压缩
stored as parquet
tblproperties ('parquet.compression'='lzo');
Parquet格式存储与Snappy压缩
stored as parquet
tblproperties ('parquet.compression'='snappy');
总结
压缩方式
| 压缩格式 | 是否分割 | 平均压缩速度 | 文本文件压缩效率 | Hadoop压缩样式 |
|---|---|---|---|---|
| gzip | 否 | 快 | 高 | org.apache.hadoop.io.compress.GzipCodec |
| lzo | 是 | 非常快 | 中等 | com.hadoop.compression.lzo.LzoCodec |
| bzip2 | 是 | 慢 | 非常高 | org.apache.hadoop.io.compress.Bzip2Codec |
| zlib | 否 | 慢 | 中等 | org.apache.hadoop.io.compress.DefaultCodec |
| Snappy | 否 | 非常快 | 低 | org.apache.hadoop.io.compress.SnappyCodec |
ORC 与 Parquet 对比
| ORC | Parquet | |
|---|---|---|
| 嵌套结构 | 不可直接实现(map间接实现) | 支持嵌套结构 |
| 导入数据和数据查询速度 | 快 | 相比ORC慢 |
| ACID | 支持 | 不支持 |
| 更新操作 | 支持 | 不支持 |
| 默认压缩 | Zlib | Uncompressed |
| 压缩格式 | Node、Zlib、Snappy | Uncompressed、Snappy、Gzip、Lzo |
| 数据压缩 | 最优(相比textFile50倍的磁盘空间) | Parquet使用gzip压缩率高,使用lzo、snappy效率高 |
| SQL查询 | 较快 | 较快 |