Redis 是基于key-value存储结构的NoSQL 数据库,是内存数据库。
一、非关系型数据库NoSQL 和关系型数据库RDBMS,两种数据库管理系统的区别?优点和缺点?
答:
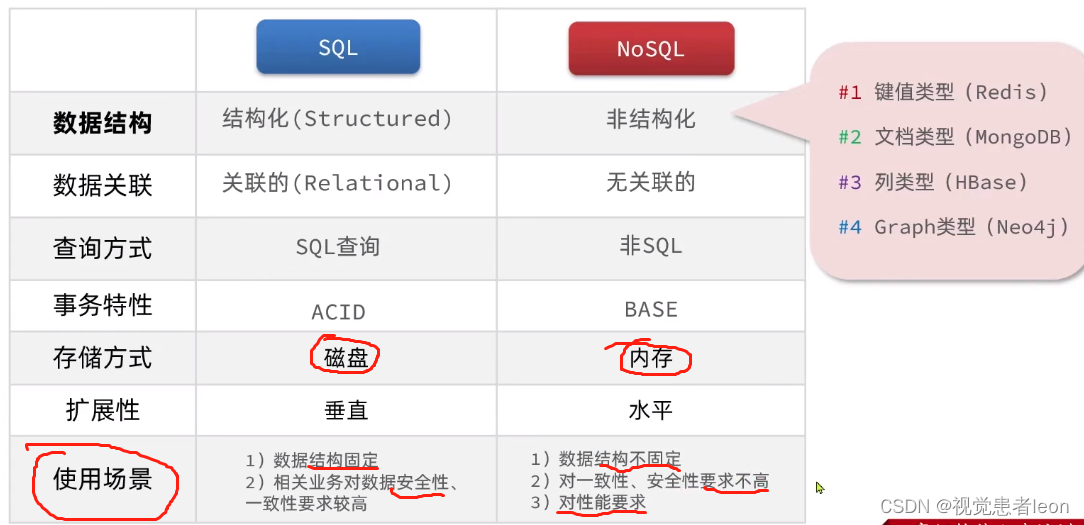
Redis是 NoSQL(非关系型数据库) 类型数据库,在NoSQL 数据库中数据之间是无联系的,无关系的。数据的结构是松散的,可变的。
1.区别
1)从存储的表结构上说:
RDBMS的表结构一般比较固定,不会轻易修改。
NOSQL的表结构比较随意,有key-value结构、json文档、图结构。
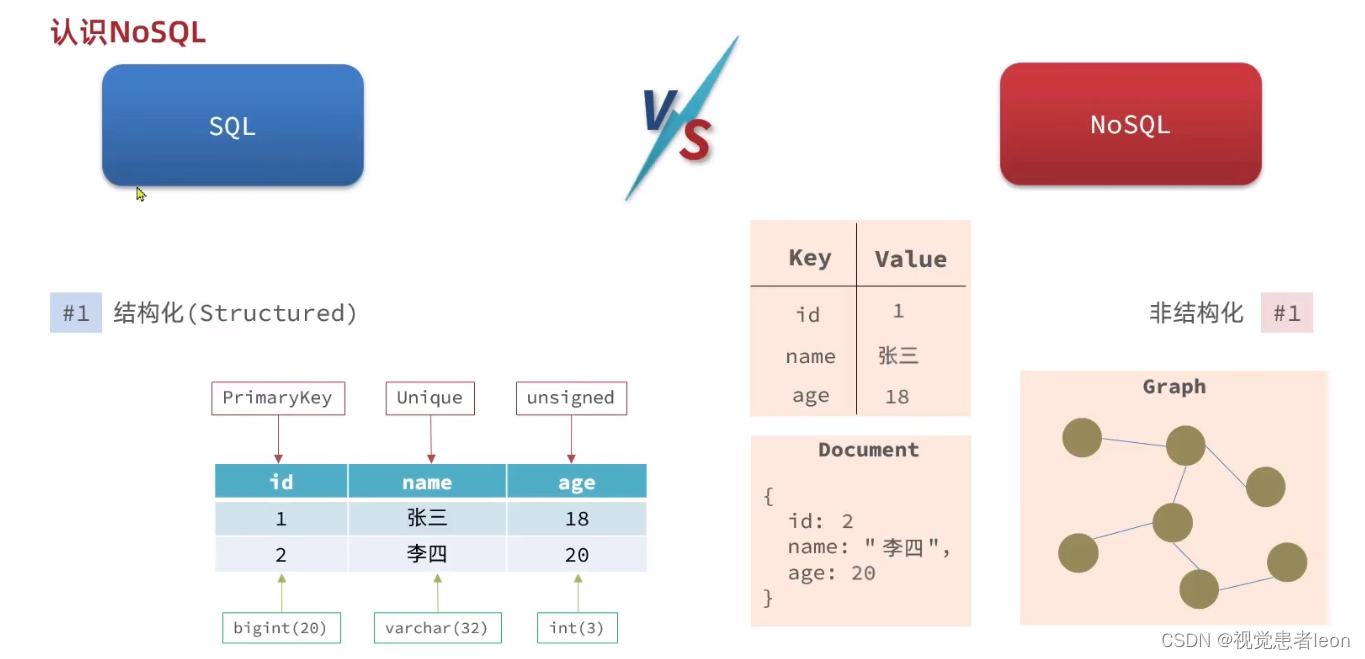
2)从表中数据的关联性上说:
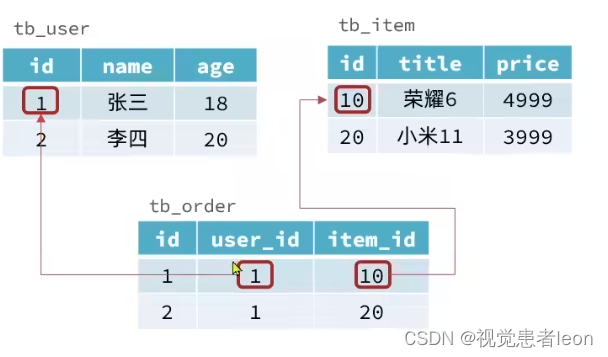
RDBMS的表中数据一般存在关联性。
NOSQL的表中数据一般不存在关联性,因此往往需要消耗更多的存储空间。

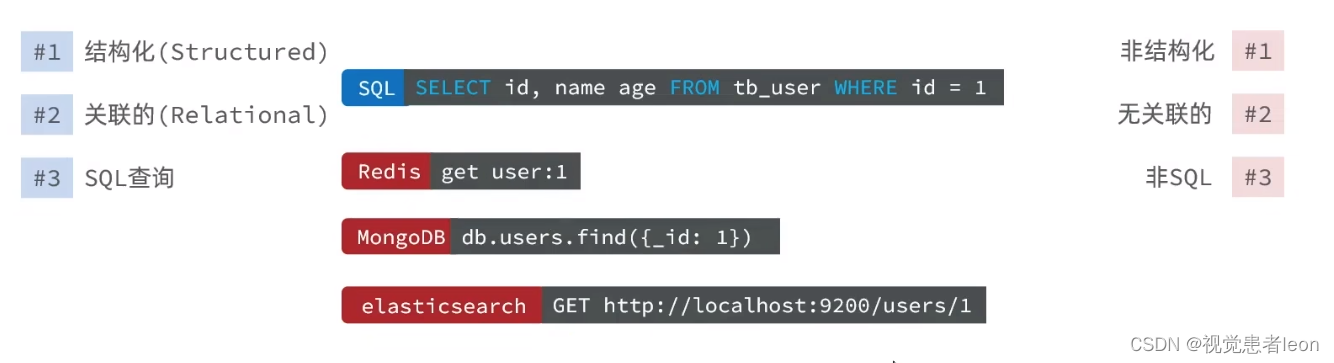
3)从数据库查询上来说:
RDBMS的所有数据库查询语句有统一的语法
NOSQL的查询针对每一种数据库都有所不同。
4)从事务上来说:
RDBMS满足ACID,数据具有安全性。
NOSQL不满足ACID,数据不具有安全性。
总结区别:
2.优缺点
关系型数据库的瓶颈:
(1)无法应对每秒上万次的读写请求,无法处理大量集中的高并发操作。关系型数据是 IO密集的应用,硬盘 IO 也变为性能瓶颈。
(2)表中存储记录数量有限,横向可扩展能力有限,一张表最大二百多列。纵向数据可承受能力也是有限的,一张表的数据到达百万级,读写的速度就会逐渐的下降。面对海量数据, 必须使用主从复制,分库分表。这样的系统架构是难以维护的。
大数据查询 SQL 效率极低,数据量到达一定程度时,查询时间会呈指数级别增长
(3)无法简单地通过增加硬件、服务节点来提高系统性能。数据整个存储在一个数据库中的。多个服务器没有很好的解决办法,来复制这些数据。
(4)关系型数据库大多是收费的,对硬件的要求较高。软件和硬件的成本花费比重较大。
非关系型数据库优势:
(1) 大数据量,高性能
NoSQL 数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。关系型数据库(例如 MySQL)使用查询缓存。这种查询缓存在更新数据后,缓存就是失效了。在频繁的数据读写交互应用中。 缓存的性能不高。NoSQL 的缓存性能要高的多。
(2) 灵活的数据模型
NoSQL 无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦。尤其在快速变化的市场环境中,用户的需求总是在不断变化的。
(3) 高可用
NoSQL 在不太影响性能的情况,就可以方便的实现高可用的架构。
NoSQL 能很好的解决关系型数据库扩展性差的问题。弥补了关系数据(比如 MySQL) 在某些方面的不足,在某些方面能极大的节省开发成本和维护成本。
MySQL 和 NoSQL 都有各自的特点和使用的应用场景,两者结合使用。让关系数据库关注在关系上,NoSQL 关注在存储上。
(4) 低成本
这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的 License 成本
非关系型数据库劣势:
(1) 无关系,数据之间是无联系的。数据存在冗余,存储空间浪费。
(2) 不支持标准的 SQL,没有公认的 NoSQL 标准
(3) 没有关系型数据库的约束,大多数也没有索引的概念
(4) 没有事务,不能依靠事务实现 ACID.
(5) 没有丰富的数据类型(数值,日期,字符,二进制,大文本等)
综上所述:
由于关系型数据库和非关系型数据库它们的底层数据结构(表结构和数据类型)存在本质不同,导致它们在CURD、高并发、存储量等使用场景存在很大不同。
目前在互联网领域海量数据的项目中NoSQL应用非常广泛。
二、redis的五种基本数据类型和底层实现原理(数据结构)
参考:Redis 常见数据类型和应用场景
Redis 数据结构并不是指 String(字符串)对象、List(列表)对象、Hash(哈希)对象、Set(集合)对象和 Zset(有序集合)对象,因为这些是 Redis 键值对中值的数据类型,也就是数据的保存形式,这些对象的底层实现的方式就用到了数据结构,因为数据类型就是对底层数据结构和合法操作进行了封装。
Redis 的键值对中的 key 就是字符串对象,而 value 可以是字符串对象,也可以是集合数据类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
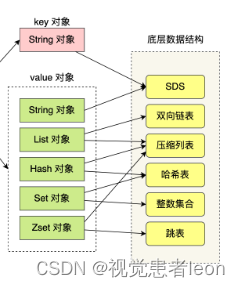
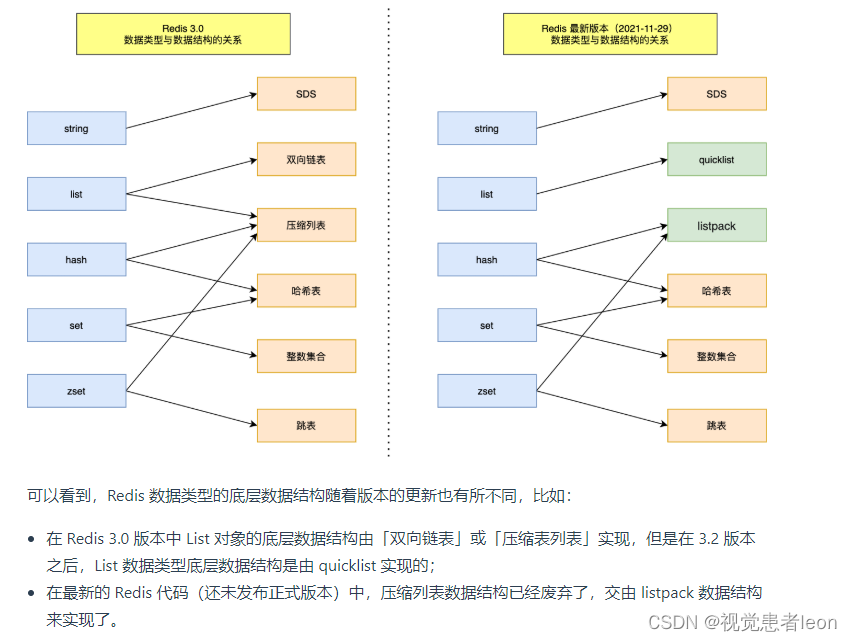
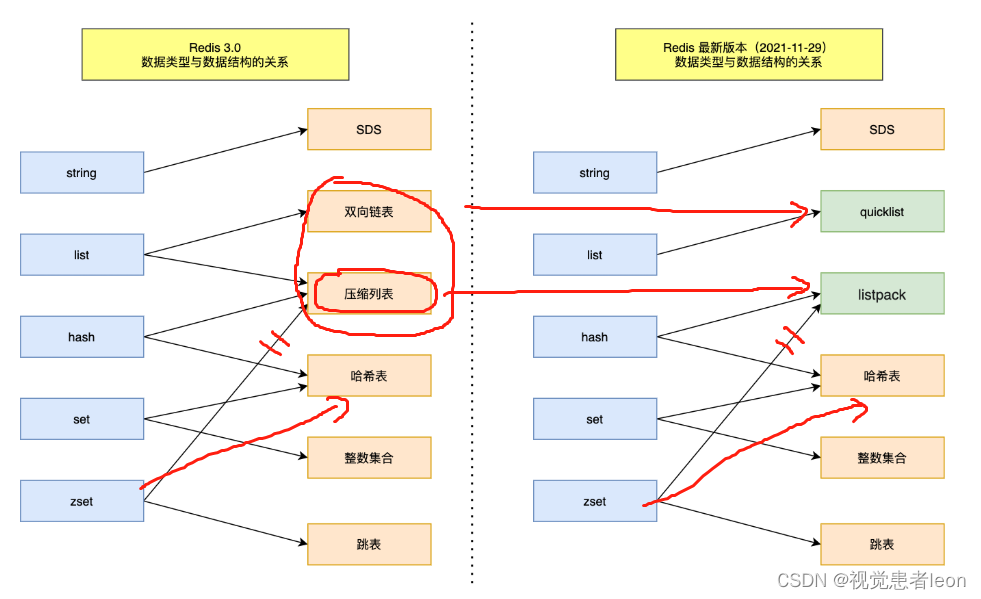
共有 8 种数据结构:SDS、双向链表、压缩列表、哈希表、跳表、整数集合、quicklist、listpack。
1)底层数据结构
1.简单动态字符串(simple dynamic string,SDS)
答:
字符串在 Redis 中是很常用的,键值对中的键是字符串类型,值有时也是字符串类型。
Redis 是用 C 语言实现的,但是它没有直接使用 C 语言的 char* 字符数组来实现字符串,而是自己封装了一个名为简单动态字符串(simple dynamic string,SDS) 的数据结构来表示字符串,也就是 Redis 的 String 数据类型的底层数据结构是 SDS。
既然 Redis 设计了 SDS 结构来表示字符串,肯定是 C 语言的 char* 字符数组存在一些缺陷。
●获取字符串长度的时间复杂度为 O(N);
●字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0” 字符,因此不能保存二进制数据;
●字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止;
Redis 实现的 SDS 的结构就把上面这些问题解决了

2.双向链表
答:
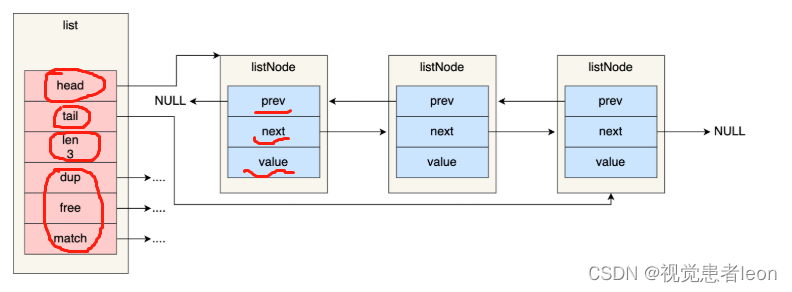
redis的链表具有前置结点和后置结点,并且数据域也采用指针形式。
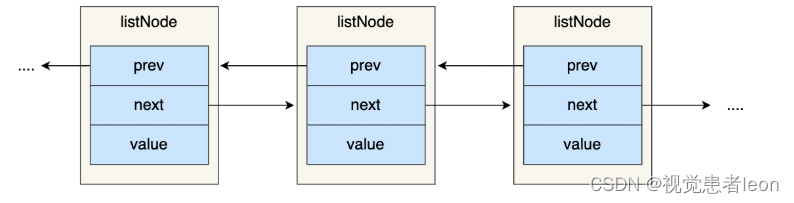
Redis 在 listNode 结构体基础上又封装了 list 这个数据结构,list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
3.压缩列表
答:

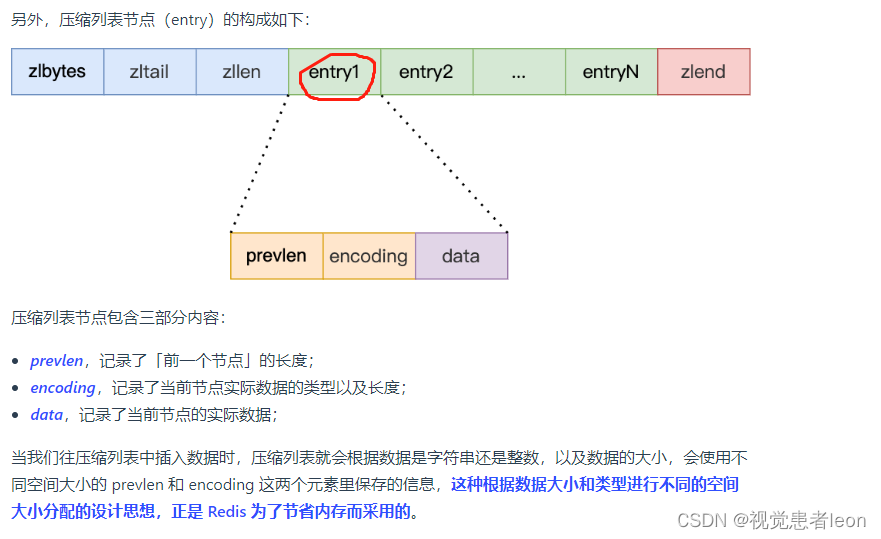
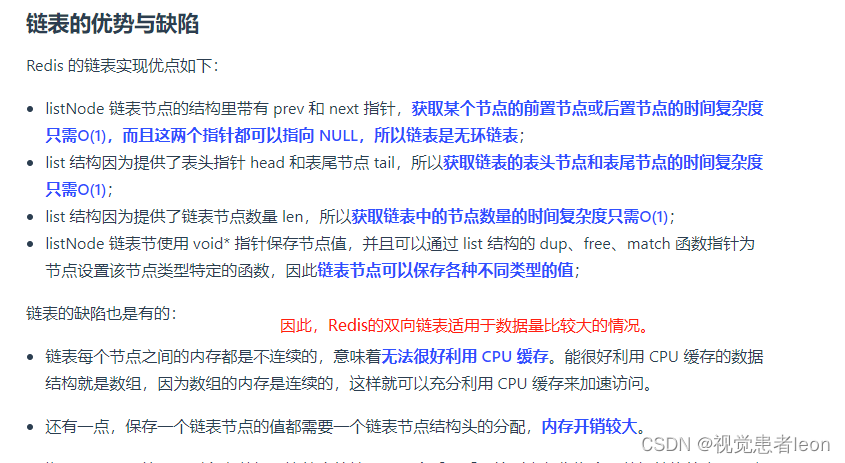
压缩列表的最大特点,就是它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
但是,压缩列表的缺陷也是有的:
●不能保存过多的元素,否则查询效率就会降低;
●新增或修改某个元素时,压缩列表占用的内存空间需要重新分配,甚至可能引发连锁更新的问题。
(连续更新发生的原因是:后一节点会记录前一个结点所占内存的字节长度大小,如果新增结点所占字节数大于等于255,会导致后一节点的prelen属性所占内存重新分配,进而导致后一节点的整个字节数增大,又会再影响下下个结点,因此产生各个结点内存大小需要更新的连锁反应)
因此,Redis 对象(List 对象、Hash 对象、Zset 对象)包含的元素数量较少,或者元素值不大的情况才会使用压缩列表作为底层数据结构。
4.哈希表
答:
redis的哈希表是一个数组(dictEntry **table),数组的每个元素是一个指向「哈希表节点(dictEntry)」的指针。
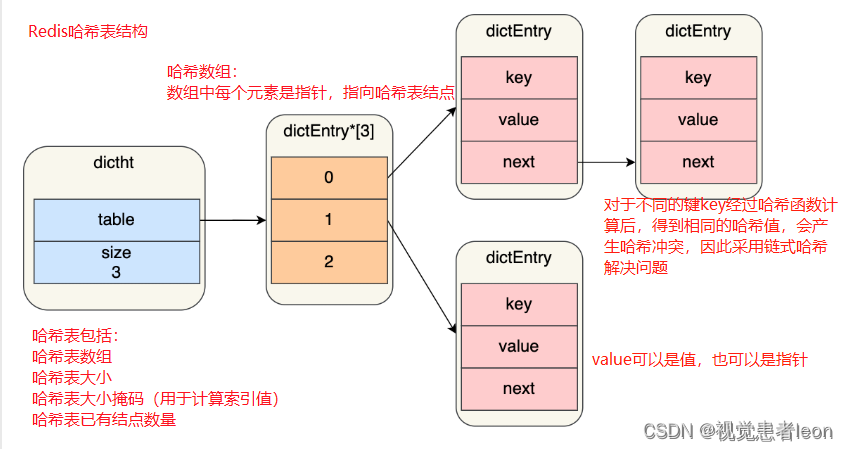
rehash:
虽然链式哈希解决了哈希冲突问题,但是随着链表的长度增大,查询效率会越来越低。为了解决这个问题,采用rehash对哈希表的大小进行扩展。
rehash就是redis使用哈希表时,定义了两个哈希表。
思路是,
正常服务请求阶段,插入的数据都会写入到哈希表1。
到哈希表1中的数据增加到一定数量,会将哈希表1中的数据迁移到哈希表2。
并且释放哈希表1空间,并将哈希表2设置为哈希表1,同时新建一个新的哈希表2。
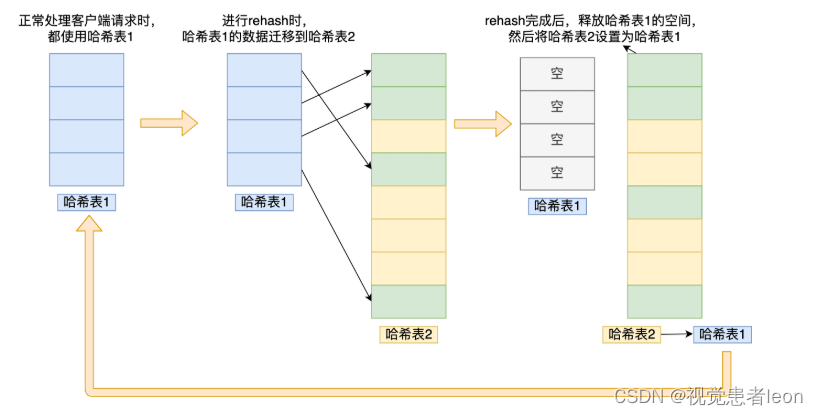
渐进式 rehash,也就是将数据的迁移的工作不再是一次性迁移完成,而是分多次迁移。

5.整数集合
答:
整数集合是 Set 对象的底层实现之一。
定义:
当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现。
整数集合本质上是一块连续内存空间,即数组。数组中元素的数据类型可以是int16、int32、int64。
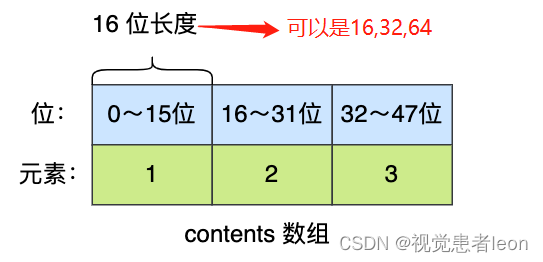
节省内存思路:
只有当新添加的元素,其类型比当前类型所占位数高时,才会对整数集合进行升级,这个升级是对于整数集合中所有元素而言,而且不可逆。因此,能用位数少的数据类型就用少的,尽可能节省资源。
6.跳表
答:
链表在查找元素的时候,因为需要逐一查找,所以查询效率非常低,时间复杂度是O(N),于是就出现了跳表。
跳表是在链表基础上改进过来的,实现了一种**「多层**」的有序链表,这样的好处是能快读定位数据。
跳表的数据结构:
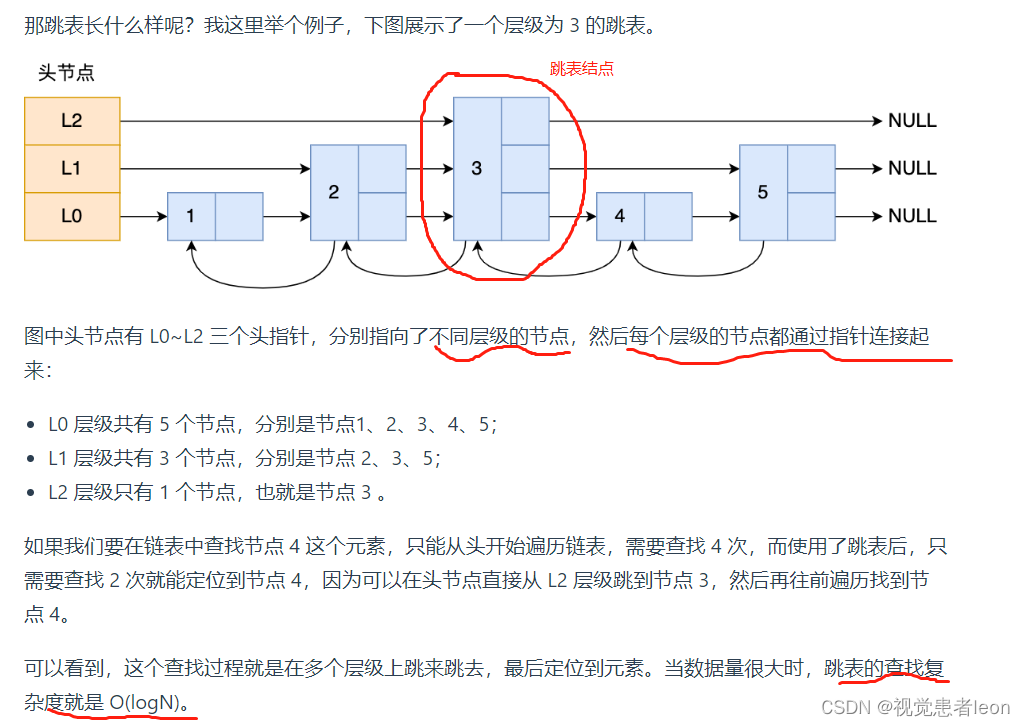
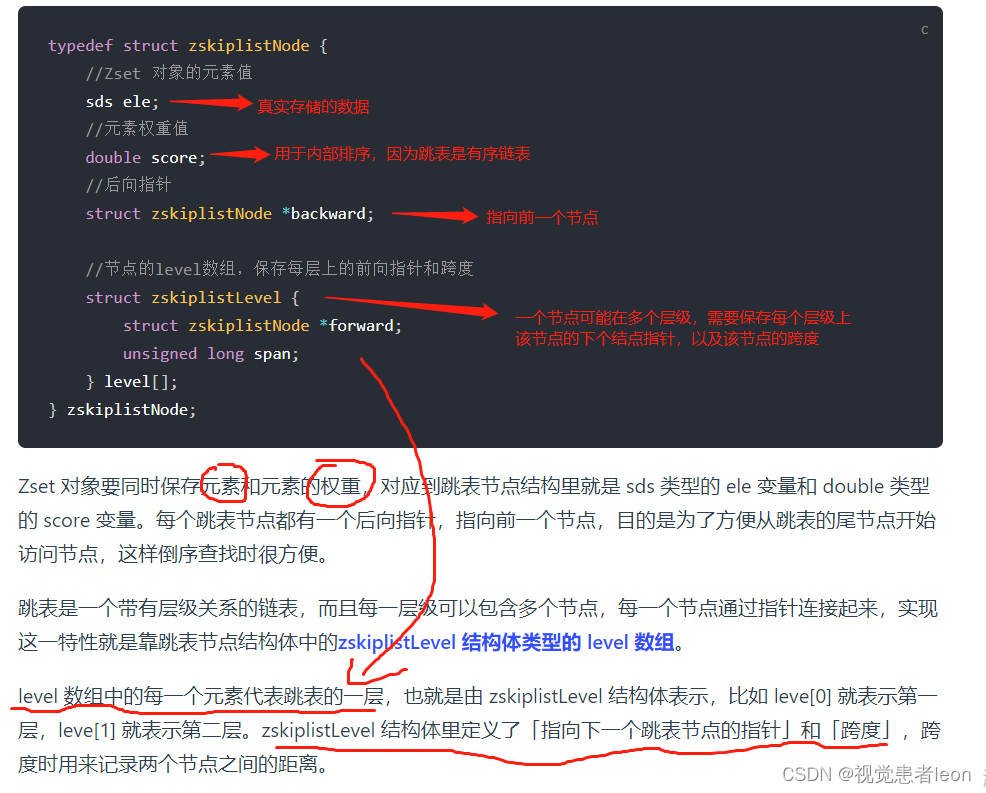
跳表结点的数据结构:

跳表的查询:
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。
在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断,共有两个判断条件:
如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找。
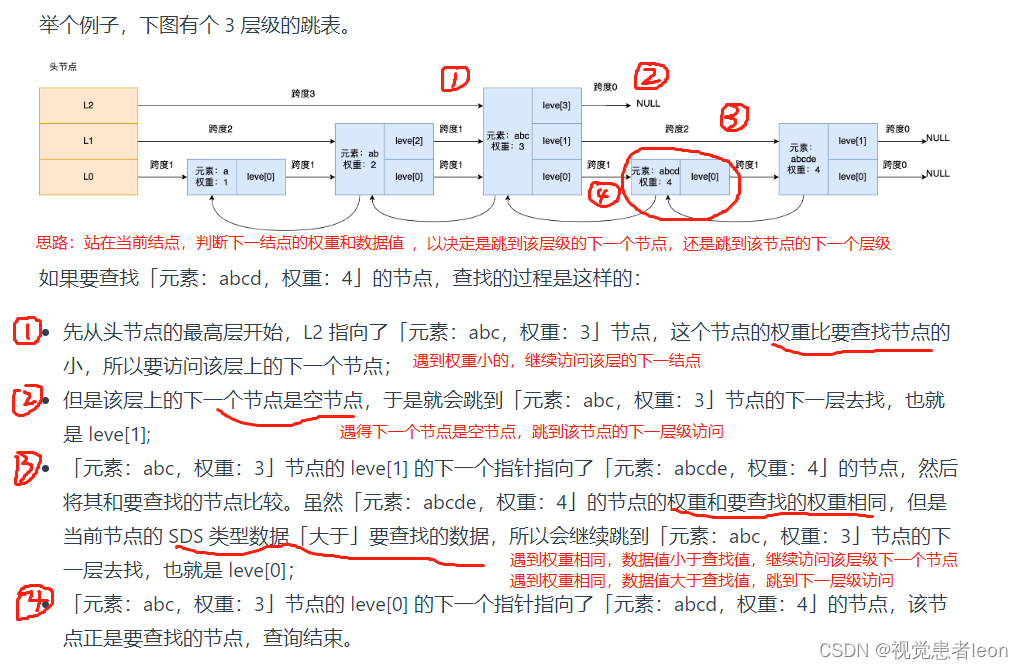
Redis 则采用一种巧妙的方法是,跳表在创建节点的时候,随机生成每个节点的层数,并没有严格维持相邻两层的节点数量比例为 2 : 1 的情况。
具体的做法是,跳表在创建节点时候,会生成范围为[0-1]的一个随机数,如果这个随机数小于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续生成下一个随机数,直到随机数的结果大于 0.25 结束,最终确定该节点的层数。
这样的做法,相当于每增加一层的概率不超过 25%,层数越高,概率越低,层高最大限制是 64。
跳表的插入:
7.quicklist
答:
quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
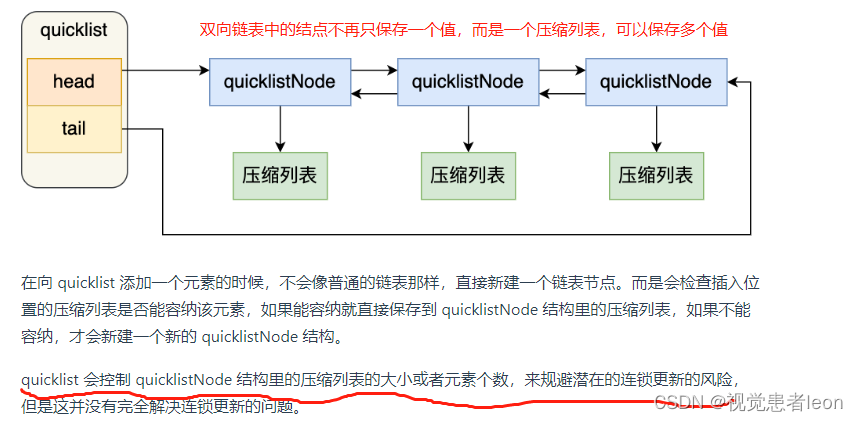
quicklist 解决压缩列表连锁更新的办法:
通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
8.listpack
答:
listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。

Q:压缩列表每个结点为什么要记录前一个结点的长度呢?
2)5种基本数据类型和4种新数据类型
1.字符串
答:
单键单值
string的底层数据结构是SDS。
String是Redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M。
当前字符串实际分配的空间capacity一般要高于实际字符串长度len。
当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
2.哈希
答:
底层是listpack或者哈希表
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
3.列表
答:
单键多值,Redis 列表是简单的字符串列表。
底层数据结构是快速列表(quicklist)
4.集合
答:
单键多值,并且去重
底层数据结构是哈希表和整数集合
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择。
并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个hash表,所以添加,删除,查找的复杂度都是O(1)。
5.有序集合
答:
底层结构是跳表或压缩列表。
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
3、Redis事务
4、Redis持久化技术
5、Redis主从复制
1)RDB
Redis Database(RDB),就是在指定的时间间隔内将内存中的数据集快照写入磁盘,数据恢复时将快照文件直接再读到内存。
2)AOF
Append-only File(AOF),Redis 每次接收到一条改变数据的命令时,它将把该命令写到一个 AOF 文件中(只记录写操作,读操作不记录),当 Redis 重启时,它通过执行 AOF 文件中所有的命令来恢复数据。