1、安装Hadoop和HIVE
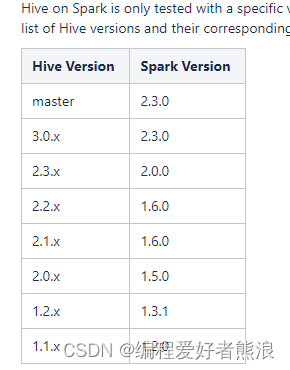
2、Scala安装
3、下载对应的版本
4、下载对应的Spark的bin包
5、上传解压,文件赋权给HIVE用户
tar -zxvf spark-2.3.0-bin-without-hadoop.tgz
#可以不用修改文件夹名称
mv spark-2.3.0-bin-without-hadoop ./spark
#赋权给HIVE执行用户,我的hive用户使用的是hadoop用户
chown -R hadoop:hadoop spark-2.3.0-bin-without-hadoop
su hadoop
cd ./spark/conf
6、编辑配置文件
#复制配置文件
cp spark-env.sh.template ./spark-env.sh
vim spark-env.sh
export JAVA_HOME=/opt/jdk1.8.0_101
export SCALA_HOME=/opt/scala
export HADOOP_HOME=/opt/hadoop
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export HADOOP_YARN_CONF_DIR=/opt/hadoop/etc/hadoop
export LD_LIBRARY_PATH=/opt/hadoop/lib/native
export SPARK_HOME=/opt/spark
export SPARK_WORKER_MEMORY=4096m
export SPARK_EXECUTOR_MEMORY=4096m
export SPARK_DRIVER_MEMORY=4096m
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hdp01:2181,hdp02:2181,hdp03:2181 -Dspark.deploy.zookeeper.dir=/ha-on-spark"
#复制配置文件
cp slaves.template ./slaves
vim slaves
hdp01
hdp02
hdp03
hdp04
修改HIVE安装目录下的/opt/hive/conf/hive-site.xml文件
vim /opt/hive/conf/hive-site.xml
新增下面的配置
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>true</value>
</property>
<property>
<name>spark.home</name>
<value>/opt/spark</value>
</property>
<property>
<name>spark.master</name>
<value>yarn</value>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://hdp01:9000/data/hadoop/spark/spark-hive-jobhistory</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>512m</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>512m</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hdp01:9000/data/hadoop/spark/spark-jars/*</value>
</property>
<property>
<name>hive.spark.client.server.connect.timeout</name>
<value>300000</value>
</property>
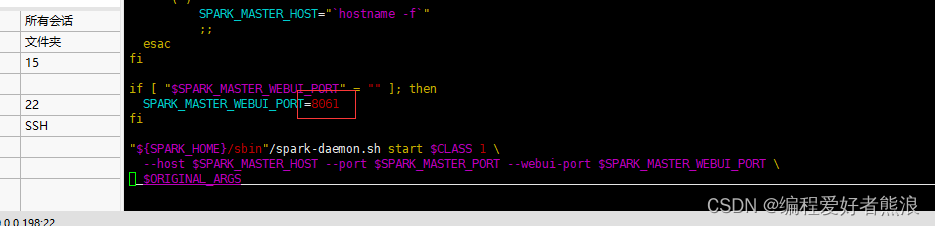
修改端口,spark默认使用的端口是8080,根据实际情况修改
cd /opt/spark/sbin
vim start-master.sh
复制/opt/hive/lib下的jar包到/opt/spark/jars下面
cd /opt/hive/lib/
cp hive-beeline-3.1.3.jar /opt/spark/jars
cp hive-cli-3.1.3.jar /opt/spark/jars
cp hive-exec-3.1.3.jar /opt/spark/jars
cp hive-jdbc-3.1.3.jar /opt/spark/jars
cp hive-metastore-3.1.3.jar /opt/spark/jars
复制/opt/spark/jars下的jar包到/opt/hive/lib下面
cd /opt/spark/jars
cp chill-java-0.8.4.jar /opt/hive/lib/
cp chill_2.11-0.8.4.jar /opt/hive/lib/
cp jackson-module-paranamer-2.7.9.jar /opt/hive/lib/
cp jackson-module-scala_2.11-2.6.7.1.jar /opt/hive/lib/
cp jersey-container-servlet-core-2.22.2.jar /opt/hive/lib/
cp jersey-server-2.22.2.jar /opt/hive/lib/
cp json4s-ast_2.11-3.2.11.jar /opt/hive/lib/
cp kryo-shaded-3.0.3.jar /opt/hive/lib/
cp minlog-1.3.0.jar /opt/hive/lib/
cp scala-library-2.11.8.jar /opt/hive/lib/
cp scala-xml_2.11-1.0.5.jar /opt/hive/lib/
cp spark-core_2.11-2.3.0.jar /opt/hive/lib/
cp spark-launcher_2.11-2.3.0.jar /opt/hive/lib/
cp spark-network-common_2.11-2.3.0.jar /opt/hive/lib/
cp spark-network-shuffle_2.11-2.3.0.jar /opt/hive/lib/
cp spark-unsafe_2.11-2.3.0.jar /opt/hive/lib/
cp xbean-asm5-shaded-4.4.jar /opt/hive/lib/
复制/opt/hadoop/etc/hadoop/yarn-site.xml,hdfs-site.xml和/opt/hive/conf/hive-site.xml到/opt/spark/conf中
cd /opt/spark/conf
cp /opt/hadoop/etc/hadoop/yarn-site.xml ./
cp /opt/hadoop/etc/hadoop/hdfs-site.xml ./
cp /opt/hive/conf/hive-site.xml ./
log4j-2.15.0.jar
slf4j-api-1.7.7.jar
slf4j-log4j12-1.7.25.jar
curator-client-2.4.0.jar
curator-framework-2.4.0.jar
curator-recipes-2.4.0.jar
guava-14.0.1.jar
spark-hive_2.11-2.3.0.jar
spark-hive-thriftserver_2.11-2.3.0.jar

7、上传/opt/spark/jars下面的jar包到hdf上,所有能访问hdf的IP都可以使用Spark引擎,路径为hive-site.xml中配置的spark.yarn.jars值
#日志存放路径
hadoop fs -mkdir -p /data/hadoop/spark/spark-hive-jobhistory
#创建jar包文件夹
hadoop fs -mkdir -p /data/hadoop/spark/spark-jars
#上传所有的jar包到hdf上
hdfs dfs -put /opt/spark/jars/*.jar /data/hadoop/spark/spark-jars/
#查看jars包是否上传成功
hdfs dfs -ls hdfs://hdp01:9000/data/hadoop/spark/spark-jars/
cd /opt/spark/conf
cp spark-defaults.conf.template ./spark-defaults.conf
vim spark-defaults.conf
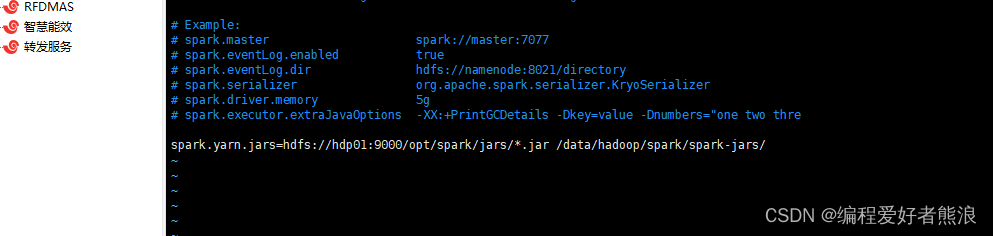
spark.yarn.jars=hdfs://hdp01:9000/opt/spark/jars/*.jar /data/hadoop/spark/spark-jars/
#保存
8、复制spark(root账号,scp复制无需root用户:scp -r /opt/spark hdp02:/opt)
rsync -av /opt/spark hdp02:/opt
rsync -av /opt/spark hdp03:/opt
rsync -av /opt/spark hdp04:/opt
9、启动Spark,hadoop添加了环境变量,启动脚本也是start-all.sh/stop-all.sh,所以需要到文件目录下启动
cd /opt/spark/sbin
sh ./start-all.sh
10、验证是否启动成功
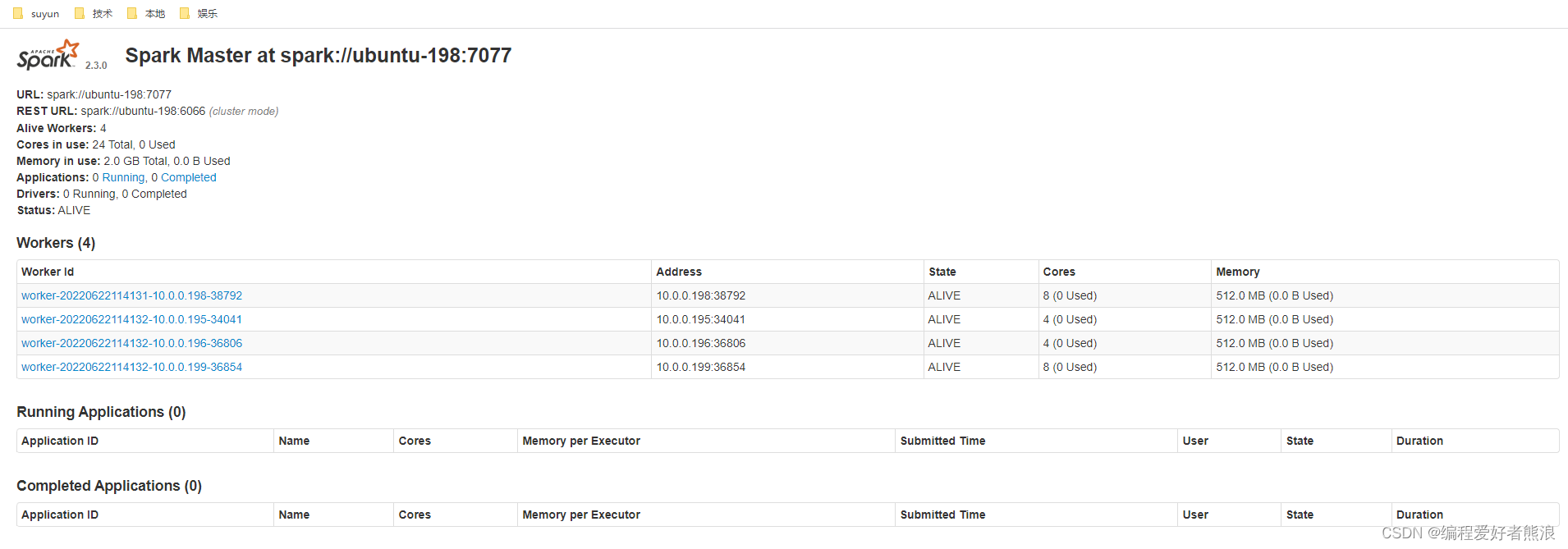
注意:如果从服务器启动不了,连接不上7077端口,但防火墙端口已经开放,可能原因是主服务器/etc/hosts里面存在127.0.0.1 域名,连接的刚好是这个域名,导致连接IP变成了127.0.0.1,从服务器本机,从服务器端口7077肯定没有开启,所以连接不通,可以注释掉所有主从服务器的127.0.0.1映射。
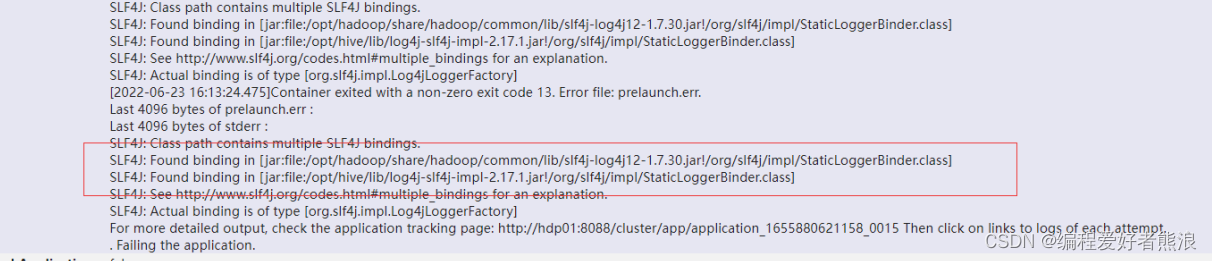
jar包冲突,移除hive的log4j-slf4j-impl-2.17.1.jar

移除/opt/hive/lib/guava-19.0.jar
上传 guava-13.0.jar
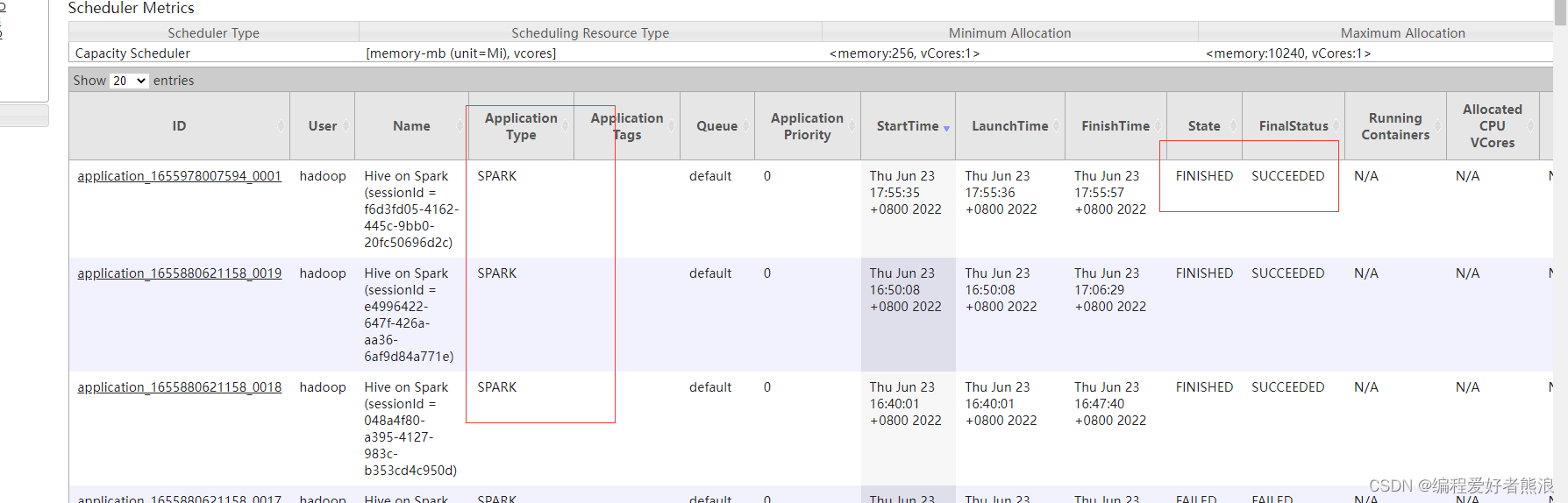
执行HIVESQL
http://hdp01:8088/cluster/apps