版本描述:Hbase 2.X 版本
CRUD场景描述:
- 批量新增数据
循环put...那是不可能的..可以使用put(List<Put> puts) 需要注意的是当一部分数据插入成功后,此时某个RegionServer出现异常,之前的数据是不会回滚的,对于插入失败的数据hbase默认会进行重试直到到达最大重试次数还是失败即会结束重试(失败数据在写缓冲区),不过如果列族错误了,那么不会进行重试,直接抛出异常
- 批量查询数据
get(List<Get> gets) 返回一个Result数组,如果一部分数据失败,一部分数据查询成功,最终hbase还是会返回异常,如果你希望不要抛出异常而是返回成功部分的数据,那么可以使用batch接口进行查询
- Scan 扫描查询
常见的OLTP数据库,最常用的就是各种join语法,不过在hbase可不支持这种语法,那么当我们需要通过部分条件查询批量数据的时候就会用到scan命令,不过考虑到性能那么我们一般使用scan(byte[] startRow,Filter filter) 这里的filter是用来翻页的,这个时候hbase会返回一个ResultScanner对象(这个时候hbase还没有真正的去scan数据,只是返回了你这个构建器对象而已)
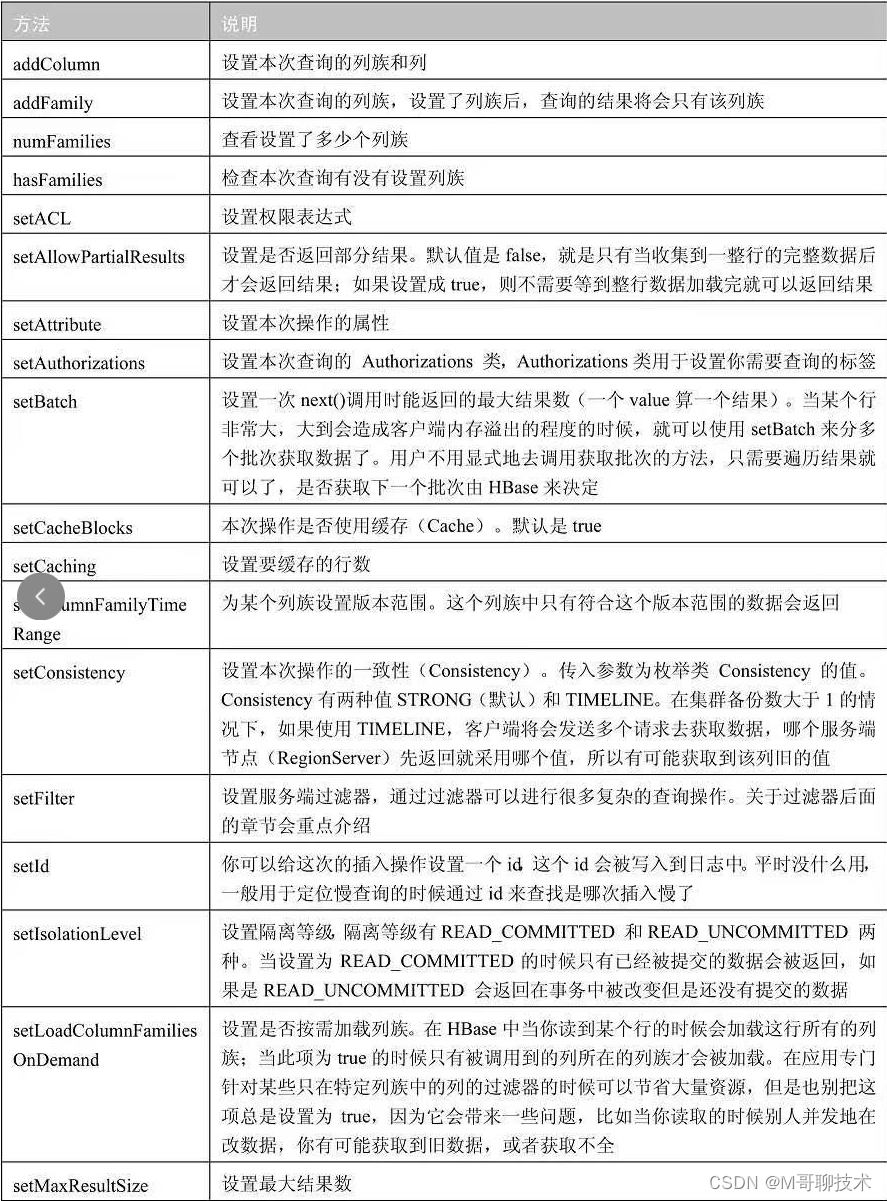
Hbase 数据结构:
- Namespace(表命名空间),可以直接使用默认值,不过一般你的表特别多并且可以分不同场景管理的时候才需要考虑设置,方便对一种纬度的批量表进行统一管理
- Table(表),一个表由一个或者多个列族组成,很多表的属性都可以在列族中指定,列入TTL、压缩算法等
- Row(行),一个行包含了许多列,这些列通过列族来分类
- Column Family(列族),列族是多个列的集合,列族最大的最用是为了将一个场景/纬度下的列放在一个节点进行维护,这样可以提高性能和降低hbase架构复杂度
- 列,多个列组成一个行,列可以随意定义,一个行中的列不限名字、不限制数量,只限定列族
- Cell(单元格),一个列中可以存储多个版本的数据,每个版本就是一个单元格,相比传统数据库,hbase数据库的数据颗粒度更加细小,同一个数据还存在多个版本
- Timestamp(时间戳/版本号),可以定义自己的版本号
当然hbase也和常见数据库一样有一个行数据主键(Rowkey),每一个行都有一个rowkey,这个是按照字典排序的
Hbase必知概念:
-
?WAL(预写日志),当写操作到达Region的时候,hbase会先将数据WAL,这个也是hbase用来故障恢复的依赖,因为hbase的写缓冲区是在内存中的,需要积累一定量的数据后才会刷写,那么这段时间如果Down机了,那么数据就会没了,所以才有了WAL
-
Region 这个相当于数据库的分区表或者mongo的分片概念,每一个Region都有起始rowkey和结束rowkey,代表了当前分区存储的范围,这个就和很多MQ的commitlog存储形式一样,每一条消息的头部字节都存储了当前消息的长度和结束位置
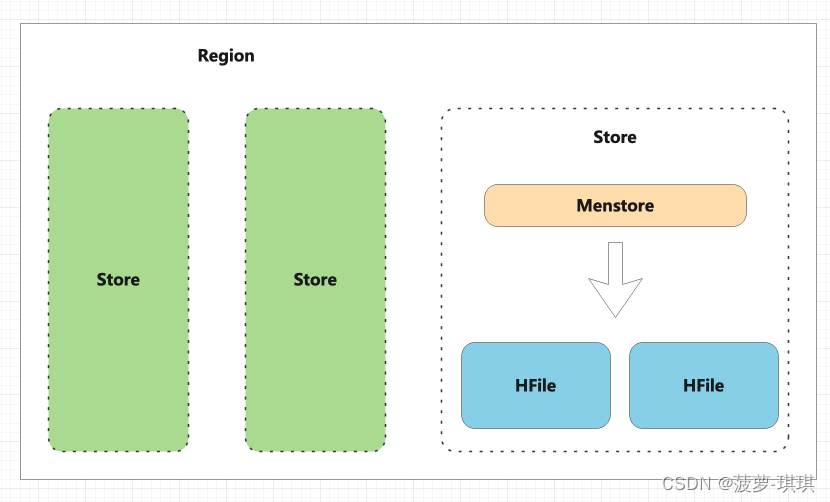
- 一个region包含多个store,一个store对应一个列族的数据,如果一个表有2个列族,那么在一个region里面就有2个store
- store内部有menstore和hfile组成?
很多MQ架构中都提供了异步刷盘/同步刷盘机制,其实hbase的WAL也和这个是一样的逻辑,WAL同样提供了异步/同步方式,同步方式对性能损耗较大但是数据100%安全,根据自己业务场景的实际需要改变
我刚开始的时候也有一个疑问,这种架构总觉得怪怪的,后来我发现是我肤浅了,我的疑问是:数据先写到WAL中,然后内存store汇聚数据,在写道hfile中,但是WAL和HFile的存储介质都是HDFS,那么不是有点多此一举么,其实这么设计的问题在于数据的顺序性,因为HDFS上的文件不能编辑,而数据库数据存放的顺序性是很重要的,如果我们数据一到就写到HDFS中,那么你很难保障数据的是顺序的,那么Menstore的价值就是在于内存整理顺序批量一次性的写到硬盘,那么这批数据的顺序性就是有保障的
- HFile,hbase数据存储的实际载体
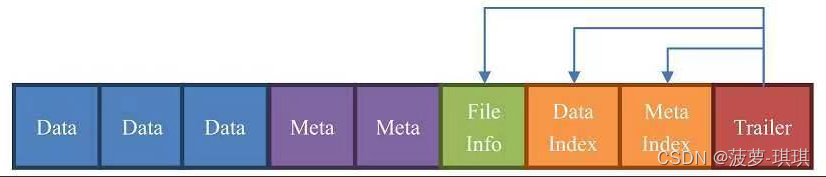
HFile是由一个个块组成的,默认每个块64KB
- ?Data块:数据块,表中的数据就在这里
- Meta:元数据块
- FileInfo:文件信息,这里面描述了最后一个key等信息
- DataIndex:存储Data块的索引信息,索引的偏移值
Hbase之疑问?
hbase是一个随机读写数据库,并且上面也说到HDFS时不支持编辑文件内容的,那么hbase怎么完成CRUD的?
其实hbase基本都一直再做新增操作,刚刚说道CELL是多份的,当你编辑的时候其实hbase新增了一份cell,只是内部的版本号信息比之前的大,当你删除一条数据的时候,hbase还是做了新增操作,只是这条数据没有value,并且类型是DELETE,常用术语墓碑标记
那么疑问又来了,一直在做insert操作,第一个是垃圾数据会非常的庞大,第二个是数据的顺序性肯定不对了,其实hbase每隔一段时间会进行一次合并(这个操作和CK很类似)合并分为两种类型(minor和major)major合并过程中如果发现墓碑标记,那么就会忽略这条数据,这个时候这条数据才是真正的被物理删除了
Hbase数据的读取
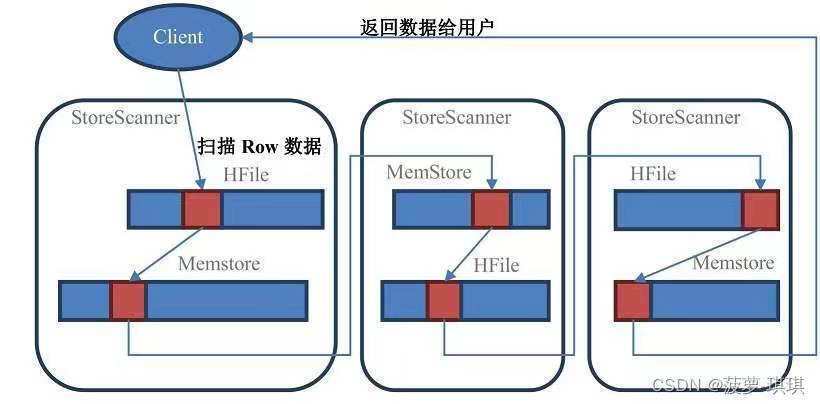
Hbase实际的读取顺序是先从BlockCache中找数据,找不到了再去Memstore和HFile中查询数据。
由于HDFS的文件不可变特性,你不可能在一个KeyValue被新建之后删除它,HBase所能做的也就是帮你加上一个墓碑标记。但是你别忘了HDFS是不能修改的,所以墓碑标记和数据不在一个存储地,所以当我们再用Scan进行数据扫描读取的时候,就算已经查到了用户分页指定数据,hbase还是会继续往后扩大的读取,因为只有这样才能知道是否存在墓碑标记,所以性能最高的scan方式是加上起始-结束标记,这样可以限定hbase扩展读取的范围
在Scan扫描的时候store会创建StoreScanner实例。StoreScanner会把MemStore和HFile结合起来扫描,所以具体从MemStore还是HFile中读取数据,外部的调用者都不需要知道具体的细节。当StoreScanner打开的时候,会先定位到起始行键
Client? -? Region
最早期的hbase采用了三层查询方式,现在已经废弃了因为代码复杂还没啥实际意义
现在已经变成了两层查询方式,
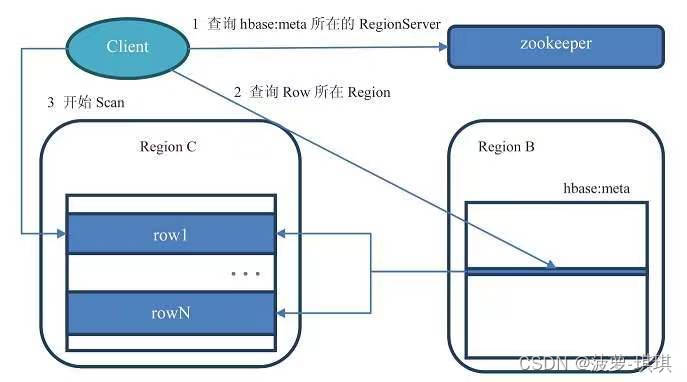
- ?客户端先通过ZooKeeper的/hbase/meta-region-server节点查询到哪台RegionServer上有hbase:meta表。
- 客户端连接含有hbase:meta表的RegionServer。hbase:meta表存储了所有Region的行键范围信息,通过这个表就可以查询出你要存取的rowkey属于哪个Region的范围里面,以及这个Region又是属于哪个RegionServer。
- 获取这些信息后,客户端就可以直连其中一台拥有你要存取的rowkey的RegionServer,并直接对其操作。
- 客户端会把meta信息缓存起来,下次操作就不需要进行以上加载hbase:meta的步骤了。
Hbase 进阶
过滤器,在scan查询的时候经常用到,可以看成SQL语句中的where条件,在遍历过程中,不满足filter条件的数据就会被过滤
过滤器的模糊值匹配?
//这段代码等同于SQL中like '%boluo%'
Filter filter = new ValueFilter( CompareOperator.EQUAL,
new SubstringComparator( "boluo" ) );上面那段代码会有个小问题就是一个列族下其他列也满足这个条件的话数据也会被捞出,那么指定列进行值匹配的话需要看下面的代码
//这段代码等同于SQL中name like '%boluo%'
Filter filter = new SingleColumnValueFilter( Bytes.toBytes( "列族" ),Bytes.toBytes( "列名") ,CompareOperator.EQUAL,new SubstringComparator( "boluo" ) );过滤器的精确值匹配
Filter filter = new SingleColumnValueFilter( Bytes.toBytes( "列族" ),Bytes.toBytes( "列名") ,CompareOperator.EQUAL,new BinaryComparator( Bytes.toBytes( "boluo" ) ) );过滤器的值预算匹配
Filter filter = new SingleColumnValueFilter( Bytes.toBytes( "列族" ),Bytes.toBytes( "列名") ,CompareOperator.GREATER,new BinaryComparator( Bytes.toBytes( "boluo" ) ) );Hbase的分页
hbase 并没有SQL的limit现成功能,需要传入PageFilter并且当第一页数据取完,想获取第二页数据的时候需要将前一页最后条数据的rowkey记录下来,变成第二页的startRowkey来使用。
不过Hbase的分页有个坑,一般初次使用很容易被坑进去,它并不能精确的按照你的分页条数返回数据,可能会比你定义的分页条数多,主要原因是因为你的Filter会到各个Region中执行,所以如果想要精确的条数,还需要自己在内存中排序处理下
结果集返回指定列族
列族过滤器,FamilyFilter
Filter filter = new FamilyFilter( CompareOperator.EQUAL,new BinaryComparator( Bytes.toBytes( "boluo" ) ) );结果集返回指定列
Filter filter = new QualifierFilter( CompareOperator.EQUAL,new BinaryComparator( Bytes.toBytes( "boluo" ) ) );Hbase 调优
作者刚进得物的时候就接手了一个hbase调优的任务项,当时的场景是hbase的get缓存命中率在92%以上,但是P99 在8~10MS之间,期望调优后可以将P99稳定在4~5MS之间,要知道Hbase是java开发的,那么避免不了就是GC的问题
本文从几个角度考虑hbase的调优
- 默认的RegionServer的内存才1GB,而Memstore默认是占40%,所以分配给Memstore的才400MB,在实际场景下,很容易就写阻塞了。可以通过指定HBASE_HEAPSIZE参数来调整所有HBase实例(不管是Master还是RegionServer)占用的内存大小。
- 随着内存的加大,有一个不容忽视的问题也出现了,那就是JVM的堆内存越大,Full GC的时间越久。Full GC有时候可以达到好几分钟,这个时候会有一个更加致命的风险,那就是ZK发送心跳请求的时候,由于节点在FC导致没有响应,ZK会认为这个节点失联了....所以GC调优很关键,如果你的机器内存 > 4G 那么推荐你直接使用G1GC,因为就算CMSGC在特定场景下还是会发生FULLGC
- Region的拆分,传统OLTP数据库单表数据量过大的时候一般我们会采用分库分表解决,那么在hbase中其实也一样,一个region就是rowkey数据的集合,当单个region数据量过大的时候,hbase会采用拆分策略,可以使用文件大小拆分或者自定义拆分策略
- 按文件大小拆分的劣势就是可能相似场景的rowkey数据被拆分到不同region中,那么查询的性能势必会被降低
- 自定义拆分策略可以使用相似前缀的拆分点进行考虑,不过如果你的rowkey业务场景的前缀都差不多那么就不要使用这种策略了

- ?WAL优化
- 调整WAL在region的文件数量,因为WAL是滚动生成的,一旦到达最大文件数量就会对之前的WAL进行清理
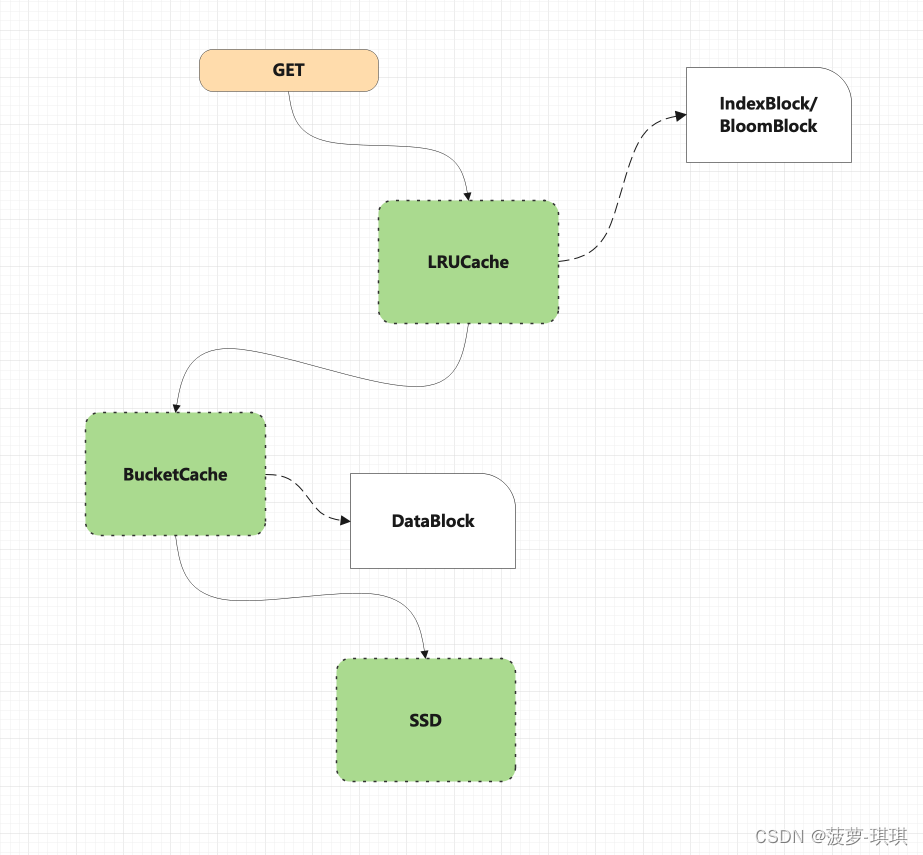
- BlockCache优化,一个regionServer只有一个BlockCache,所有读取请求都会先经过BlockCache如果没有找到数据才会去MS或者HDFS中查找
- 开启BlockCache
- LRU策略,常用的一种计算策略,最近最少使用算法,不过缺点是利用JVM的堆内内存,那么势必避免不了GC的影响
- BucketCache策略,一种对外内存的计算策略,其实内部是使用了NIO的DirectByteBuffers进行堆外字节的操作,堆外内存足够的情况下我们可以考虑使用不需要担心内存泄露,并且不限于堆外存储介质,这个策略还能配置堆内,SSD作为存储介质,灵活性很高,性能也很高
- 组合模式,虽然BucketCache很优秀,但是在不考虑FULLGC的前提下堆外的性能还是无法直接和堆内比,所以就出现了组合模式,可以简单理解为三级存储,一级是堆内,二级是对外,三级是SSD,但是并不是简单的复制存储,而是数据量从小到大的一种模式,堆内存储索引和文件信息,对外存储热点数据,SSD存储全量数据
- ?Menstore优化,因为数据会先去WAL,然后再Menstore中汇聚等待刷写,大部分性能问题可能和Menstore阻塞有关系
- 如果你的Menstore刷写策略是按照指定时间+指定大小,那么在高并发场景中,还未到达指定时间前,突然一大波写入请求导致Menstore数据瞬间达到指定大小,这个时候你后续所有的写都会被阻塞,直到Menstore完成当前刷写空出内存空间为止,调整阻塞阈值是一个暂时可以解决问题的思路,不过并不能解决所有场景
- 有一些场景可能采用手动刷写的思路更加合适,在明确知道本次处理的数据量很大的场景下,手动先刷写Menstore数据,给本次请求腾出空间,当然更好的是设置HFile的合并
- HFile合并(minor/major)
- Minor 合并策略,TTL到期的数据会被移除但是手动删除的数据不会被真正删除,合并触发时间较短
- Major 合并策略,会真正删除手动删除的数据,这个策略频率较低,可以控制触发时机