1、InnoDB数据页结构
? 页是InnoDB 管理存储空间的基本单位,一个页的大小一般是16KB 。可以理解为创建一个表时,会创建一个大小为16KB大小的空间,也就是数据页。新增数据时会往该页中User Records中添加数据,如果页的大小不够使用了继续创建新的页。也就是说一般情况下一次最少从磁盘读取16kb的内容到内存,一次最少把16kb的内容刷新到磁盘中,其作用有点缓存行的意思。
局部性原理:
? 就是说当我们需要1个字节的数据时,系统会根据局部性原理,在磁盘取出该数据相邻的数据一起放入内存重中,预备后续使用。在操作系统中以“页”为单位取值为4kb,同理在Innodb数据库中也是以“页”为单位(16kb)。
综上,可以知道我们的数据是存储在“页”中的,而每次查询数据到内存都是以“页”为单位读取到内存中。
数据页结构 :
? ? ? ? ? ? ? ? ? ? ??? ? ? ?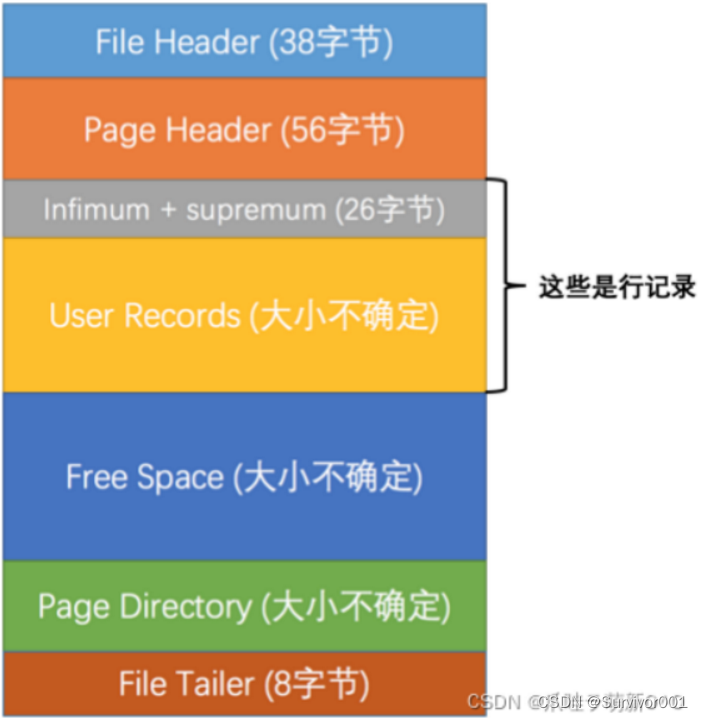
?每一个数据页都包含以上几块内容:
| 名称 | 中文名 | 占用空间(字节) | 简单描述 |
|---|---|---|---|
| File Header | 文件头 | 38 | 页的通用信息,如编号、上一页、下一页等等 |
| Page Header | 页面头 | 56 | 数据页专有的信息,因为数据页不仅仅有数据,也可以作为索引页。 |
| Infimum + Supremum | 最大、最小记录 | 26 | 两个虚拟的行记录 |
| User Records | 用户记录 | 不确定 | 实际存储的行记录内容 |
| Free Space | 空闲空间 | 不确定 | 页中尚未使用的空间 |
| Page Directory | 页面目录 | 不确定 | 页中的某些记录的相对位置 |
| File Trailer文件尾8校验页是否完整 |
?备注:File Header 并不是所有类型的页都有上一个页(FIL_PAGE_PREV)和下一个页(FIL_PAGE_NEXT)的属性,但数据页是有这两个数据属性的,如一张表数据量过大,16kb存不下,就会分成很多个页,此时就这两个属性作用就发挥作用。
这里核心我们了解User Records、Free Space、Page Directory即可
过程:在一开始创建数据页时,User Records其实也就是Free Space,当插入一条数据后,会从Free Space中分配出空间作为User Records来存储数据,直到Free Space使用完。
Page Directory 下来逻辑中介绍。
数据存储逻辑:
假如现在有一张test表,插入n条数据 :
2 - C - 3 - 100 ;
3 - B - 5- 100;
1 - A - 2- 100 ;
........
我们都知道InnoDB有个特点,必须要有一个主键或者唯一索引,如果没有默认添加rowId作为主键。 在插入数据时会根据主键的大小从小到大默认排序插入。
假如上面的数据 第一列为主键,那么这些数据会是下面这这样存储:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??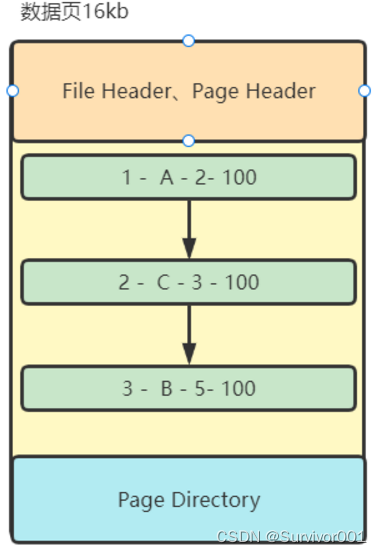
?行数据在数据页中以链的方式链接,每次插入数据时都会根据其主键大小顺序进行插入到指定位置,所以为什么说主键推荐使用“主键自增”,且比较小,因为自增就不会出现往中间插入的情况,只会一只往尾部插入。如果主键打比较大,占用页空间就大,可能就需要更多的数据页来存储。
如果说当一个数据页的空间使用完了,那么剩下的数据就会创建新的数据页取存储,这种情况也叫 数据页溢出,那这时查询数据就需要夸页查找。
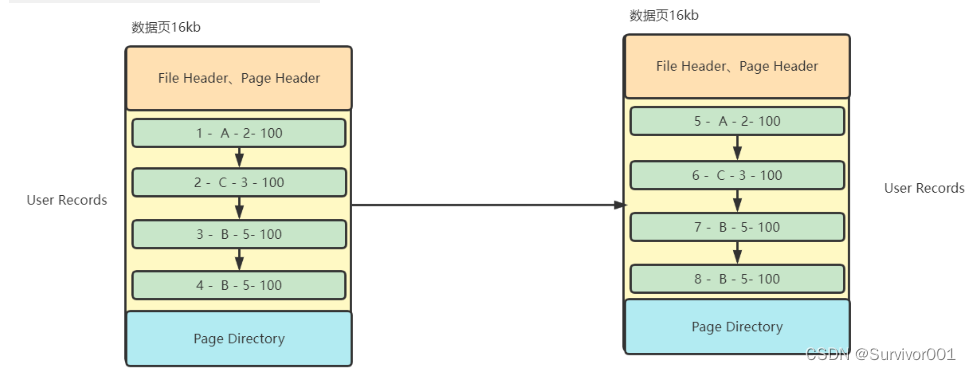
?那么问题来了,InnoDB存储数据时会将数据根据主键进行排序插入呢,这样不是会影响插入效率吗?
确实会影响插入效率,但是InnoDB后续做法,会大大提交查询效率,接着看:
如果就是这样,那么可想而知如果想要查询主键4的数据,那就必须去完全扫描第一个数据页(真实情况下一个数据也存储数据很多),效率肯定很差。
InnoDB是这样做的,它将UserReords中的数据按照一定量进行分组,将最小值最为key生成一个目录,也就是页目录Page Directory。
如果是这样,那么现在如果想要找主键为4的数据,那这样就不会直接去扫描一条条数据了,因为 3 < 4 < 5
因为以最小值去作为目录内容,所以主键为4的数据,就可以定位在 3目录下了,这只需要扫描 2条数据就可以定位到数据了。
根据上述的解释,是不是理解了为什么InnoDB为什么需要主键了或者唯一索引了吧。
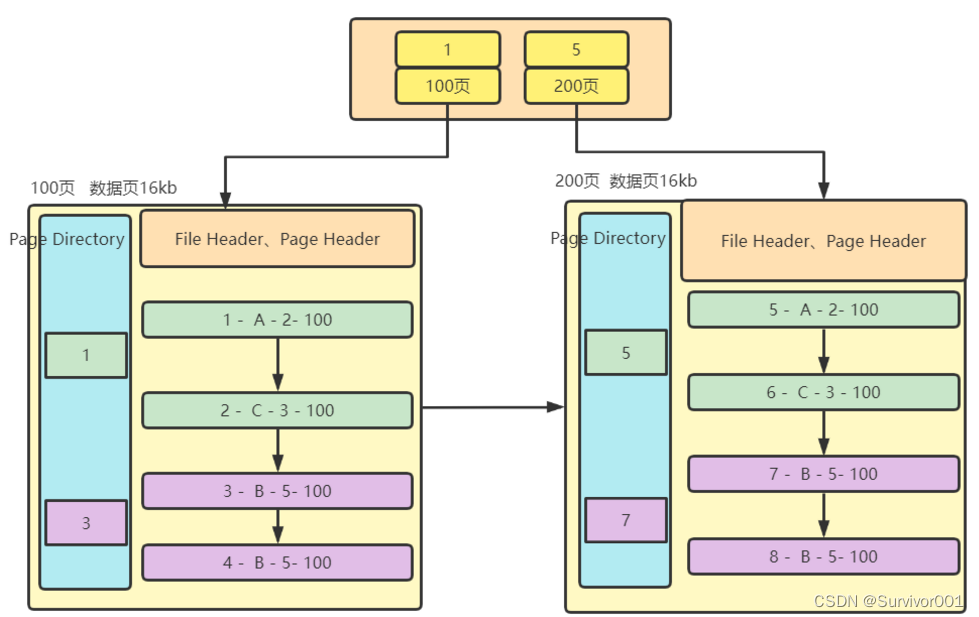
那现在问题又来了,如果我的数据页非常多,那无法知道数据是在哪个数据页中,如果对所有页扫描肯定也是不行的?
InnoDB是这样做的,再创建一个页,为目录页,这个页可以用来记录 该页主键最小数据作为key,页号(每个页地址)作为value。
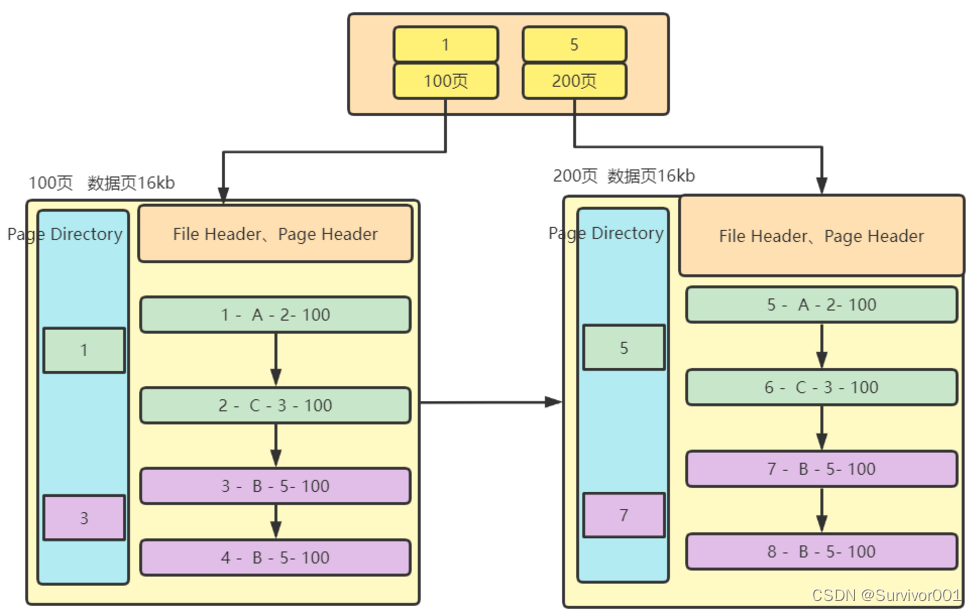
像这样,那么在查找主键为5的数据时,会优先通过 目录页使用以上同样的方式定位到第200页,然后再通过200页内的页目录去查找数据。 注意:因为目录页也是数据页,大小也是16kb。
突然我们好像发现了什么,这不就是B+树结构吗? 是的,这就是InnoDB数据存储结构。当数据量很大时,目录页页会被优化,需要更多目录页来处理,则高度增加。
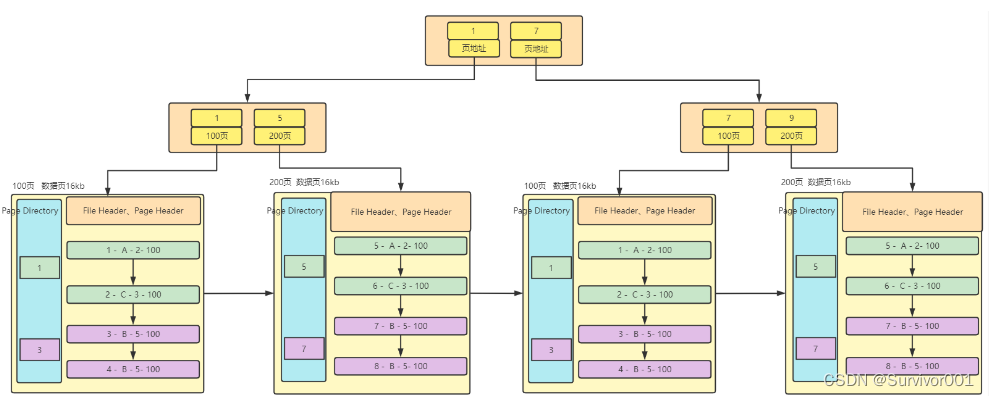
一般2层高度结构大概存储20000条左右数据量:16384 / (8+6) * 16 = ~18714 【8字节:主键空间 ,6字节 :指针空间 - 每一页的地址,如果每行数据算1kb,那么每个页存储16行数据 ,16384 / (8+6) 代表目录页的键值对数 】
一般3层高度结构大概存储20000条左右数据量:2000万条数据
以上就是InnoDB数据存储结构原理,同时这样用于目录查询功能的字段也就是聚合索引(一般就是主键或者唯一索引)。