
你从没想过要翩然离去?
心里又渴望留下
? ? ? ?-----《Scent of a Woman》?
目录
本章录入基础函数
1.having
关于having这个函数,其实在工作中不常用,具体原因在数据库优化中说。
1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用相当于WHERE 3.WHERE 后面的条件中不能有聚集函数,比如SUM(),AVG()等,而HAVING 可以
比如:查数量大于500的那些商品类型
select goods_type,count(*) from table a group by goods_type having count(1)>500;
2.truncate
truncate table tableName;
与delete from tableName一样的地方都是删除表数据,保留表结构;使用truncate语句删除数据时,通常要比使用delete语句快得多,这是因为使用truncate语句删除数据时,不会产生任何回退信息,因此执行truncate语句操作也不能回退,且使用的系统和事务日志资源少。
DELETE语句每删除一条记录都是一个事务,每次删除一行,并在事务日志中为所删除的每行记录一项;但TRUNCATE是释放整个数据页(一个页8K),通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
3.int(M)
int数值范围:-2,147,483,648到2,147,483,647;
int默认是11,比如设置字段类型为int(),则数据库会自动设置为int(11);
M指最大显示宽度,意思是,如果是 int(10),字段存的值是 10,则,显示会自动在之前补 8 个 0,显示为 0000000010;
number(4,3)是表示这个数一共有4位是有效位,后面的3表示有3个是小数也就是这个数只能是1.234,这样格式的最大只能是9.999;
4.exists
in与exists区别:
从sql编程角度来说:
in直观,exists不直观多一个select,in可以用于各种子查询,而exists只用于关联子查询;
从性能上说,
用in,会优先查询子查询,然后匹配外层查询;in用的是hash join,是把外表和内表作hash join,所以内表如果小,效率就高;如果内表大,外表如果也很大就很慢了,这时候exists才真正的会快过in的方式。
用exists,则oracle会优先查询外层表,然后再与内层表匹配。exists是用loop的方式,循环的次数影响大,外表一定要记录数少。
最优化匹配原则,拿最小记录匹配大记录。换句话说小表驱动大表以减少扫描次数;
例如:?摘自:博客
1)select * from A?where id in(select id from B)?
in()只执行一次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录;
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A);
Array B=(select id from B);
for(int i=0;i<A.length;i++) {
for(int j=0;j<B.length;j++) {
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
return resultSet;当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次,所以子查询数据要小;
如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差.
再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升;
2)select a.* from A a?where exists(select 1 from B b where?a.id=b.id)
以上查询使用了exists语句,exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false;
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A)
for(int i=0;i<A.length;i++) {
if(exists(A[i].id) { //执行select 1 from B b where b.id=a.id是否有记录返回
resultSet.add(A[i]);
}
}
return resultSet;当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行;
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等;
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果;
再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快;
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用;
实际上在8i时代,这经常是正确的,现在已经11+了,很多SQL虽然写法不同,但是ORACLE优化器会根据既定规则进行查询重写,重写为优化器觉得效率最高的SQL,所以可能SQL写法不同,但是执行计划却是完全一样的。
IN与EXISTS有一点要记住:IN一般是用于非相关子查询,而EXISTS一般用于相关子查询
not in与not?exists区别:
not in内外表都进行全表扫描,没有用到索引;not extsts 的子查询能用到表上的索引。
所以推荐用not exists代替not in
5.hash join
最基本的解释:
是oracle里面一个非常强悍的功能,当做hash join时,oracle会选择一个表作为驱动表,先根据过滤条件排除不必要的数据,然后将结果集做成hash表,放入进程的hash area,接着扫描第二张表,将行的键值做hash运算,到内存的hash表里面去探测,如果探测成功,就返回数据,否则这行就丢弃掉。
算法步骤:
i. Hash Join连接对象依然是两个数据表,首先选择出其中一个“小表”。这里的小表,就是参与连接操作的数据集合数据量小。对连接列字段的所有数据值,进行Hash函数操作。Hash函数是计算机科学中经常使用到的一种处理函数,利用Hash值的快速搜索算法已经被认为是成熟的检索手段。Hash函数处理过的数据特征是“相同数据值的Hash函数值一定相同,不同数据值的Hash函数值可能相同”;
ii. 经过Hash处理过的小表连接列,连同数据一起存放到Oracle PGA空间中。PGA中存在一块空间为hash_area,专门存放此类数据。并且,依据不同的Hash函数值,进行划分Bucket操作。每个Bucket中包括所有相同hash函数值的小表数据。同时建立Hash键值对应位图。
iii. 之后对进行Hash连接大表数据连接列依次读取,并且将每个Hash值进行Bucket匹配,定位到适当的Bucket上(应用Hash检索算法);
iv. 在定位到的Bucket中,进行小规模的精确匹配。因为此时的范围已经缩小,进行匹配的成功率精确度高。同时,匹配操作是在内存中进行,速度较Merge Sort Join时要快很多;
这个了解原理即可,平时看表执行计划经常看到;
6.minus
minus和not exists的效果是一样的,
minus的意思是使用第一个查询的结果作为基础数据减去另一个查询结果作为最终结果集;
表A{1,2,3,4,5,}? ? ? 表B{4,5,6,7,8,}
select * from A minus select * from B;
结果:1,2,3
select * from B minus select * from A;
结果为:6,7,8
7.join
left join 、right join 、inner join之间的区别,平常用的左连接、右连接,都是外连接中的一种
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录;
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录;
inner join(等值连接) 只返回两个表中联结字段相等的行;
有如下两个表
create table tableA(stuid int,classid varchar2(5),stuname varchar2(10));
create table tableB(classid varchar2(5),stuname varchar2(10));
1)内连接join?,inner join
如下3个sql的执行结果都一样
select * from TableA a inner join TableB b on a.classid=b.classid;
select * from TableA a join TableB b on a.classid=b.classid;
select * from TableA a,TableB b where a.classid=b.classid;
2)左外连接示例:left join?
elect * from TableA a left join TableB b on a.classid=b.classid;
select * from TableA a,TableB b where a.classid=b.classid(+);1 --左连接 :列出左边表全部的,及右边表符合条件的,不符合条件的以空值代替。 2 --在(+)计算时,哪个带(+)哪个需要条件符合的,另一个全部的。即放左即右连接,放右即左连接。
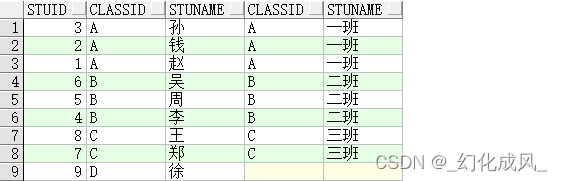
3)右外连接示例:right join??
select * from TableA a right join TableB b on a.classid=b.classid;
select * from TableA a,TableB b where a.classid(+)=b.classid;
?4)全连接示例:full join
全连接 :产生M+N的结果集,列出两表全部的,不符合条件的,以空值代替
select * from TableA a full join TableB b on a.classid=b.classid;
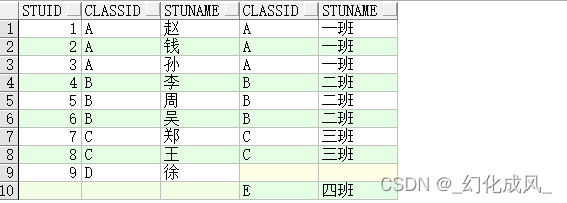
?5)笛卡尔连接,cross join
笛卡儿乘积连接 :即不加任何条件,达到 M*N 的结果集
select * from TableA a cross join TableB b;
select * from TableA a,TableB b;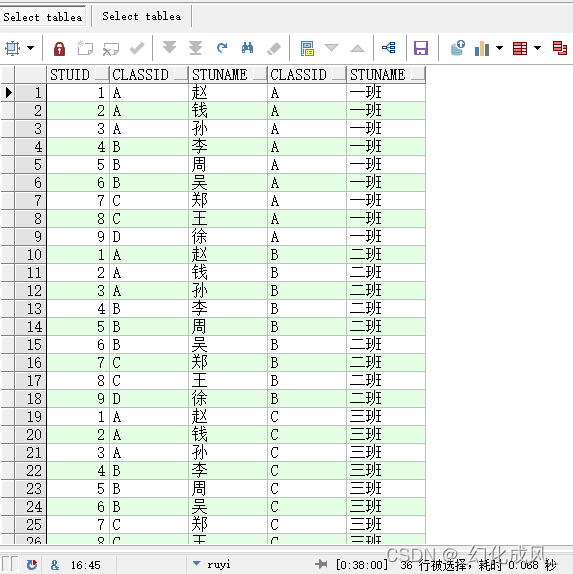
注意:如果cross join加上where a.classid=b.classid条件,会产生跟自连接一样的结果:
select * from TableA a cross join TableB b on a.classid=b.classid;
引自:博客
8.using
using字句可以实现内连接:
select * from emp join dept using(deptno);
等于
select * from emp e,dept d where e.deptno = d.deptno;
如果在连接查询时使用了两个表中相同的多个列,那么就可以在using子句中指定多个列名;
select... from table1 inner join table2 using(column1,column2)上述的语句相当于下面的语句:
select... from table1 inner join table2
on table1.column1=table2.column2
and table1.column2=table2.column2;
如果是多个表关联呢?
select... from table1,table2,table3
where table1.column1=table2.column1
and table2.column2=table3.column2;
对应如下
select... from table1
inner join table2 using(column1)
inner join table3 using(column2);
9.alter
一般需要修改表结构的,就用到alter语句,实际工作中不常用到;
1)增加一个列:alter table 表名 add(列名 数据类型);
如:alter table emp add(weight number(38,0))
2)修改一个列的数据类型(一般限于修改长度,修改为一个不同类型时有诸多限制):
ALTER TABLE 表名 MODIFY(列名 数据类型);
如:alter table emp modify(weight number(3,0) not null);
3)给列改名:alter table 表名 rename column 当前列名 to 新列名;
如:alter table emp rename column weight to weight_new;
4)删除一个列:alter table 表名 drop column 列名;
如:alter table emp drop column weight_new;
5)将一个表改名:alter table 当前表名 rename to 新表名;
如:alter table emp rename to?weight_new;
10.rowid去重
rowid是oracle中的一个重要的概念。用于定位数据库中一条记录的一个相对唯一的地址值。通常情况下,该值在该行数据插入到数据库表时即被确定且唯一。rowid它是一个伪列,它并不实际存在于表中。它是oracle在读取表中数据行时,根据每一行数据的物理地址信息编码而成的一个伪列。所以根据一行数据的rowid能找到一行数据的物理地址信息,从而快速地定位到数据行。数据库的大多数操作都是通过rowid来完成的,而且使用rowid来进行单行记录定位速度是最快的。
引自:博客
--创建test表
create table test(
name varchar(20),
age number(3),
sex varchar(10),
weight number(3)
);
--添加数据
insert into test values('貂蝉',22,'女',96);
insert into test values('小乔',24,'女',95);
insert into test values('孙尚香',21,'女',92);
insert into test values('露娜',20,'女',94);
insert into test values('女娲',26,'女',97);
insert into test values('甄姬',23,'女',91);
insert into test values('安琪拉',22,'女',98);
insert into test values('貂蝉',22,'女',96);
insert into test values('小乔',24,'女',95);
insert into test values('孙尚香',21,'女',92);
insert into test values('露娜',20,'女',94);
insert into test values('女娲',26,'女',97);
insert into test values('甄姬',23,'女',91);
insert into test values('安琪拉',22,'女',98);
--查看rowid
select name,age,sex,weight,rowid from test order by age desc;
现在来完成一个操作:将所有相同的记录只保留一份
也就是说删除重复的数据
--找到每组最小的rowid,也可以取最大的
select min(rowid) from test group by name,sex,age,weight;
?然后删除不在其中的即可
delete from test where rowid not in (select min(rowid) from test group by name,sex,age,weight);
commit;
11.trunc函数
Oracle中的trunc()函数是对时间类型或者数字进行截取操作的
1)trunc(日期,‘截止日期单位’)
select sysdate from dual--显示2015/05/06 11:17:25
select trunc(sysdate) from dual--返回当前的日期,默认后面为dd 显示2015/05/06
select trunc(sysdate,'yy') from dual--返回当前年份的第一天,yy与yyyy相同 显示2015/01/01
select trunc(sysdate,'mm') from dual--返回当前月份的第一天 显示 2015/05/01
select trunc(sysdate,'dd') from dual-- 2015/05/06 (并不显示其他时间单位)
select trunc(sysdate, 'hh') from dual--返回当前小时的初始值 显示 2015/05/06 11:00:00
select trunc(sysdate, 'mi') from dual--返回当前分钟初始秒 2015/05/06 11:17:00
--特殊情况
select trunc(add_months(sysdate,-12), 'yy') from dual--返回当前年的第一天
select trunc(sysdate, 'd') from dual--返回当前星期的第一天
2)trunc(number)
a.若n=0,则相当于只保留整数部分
b.若n<0, 则相当于截取到小数点前的第n位
c.若n>0,则表示小数点后面保留n位
以下为trunc第一种用法的所有情况使用
select trunc(25.569,2) from dual;--25.56
select trunc(25.569,4) from dual;--25.569
select trunc(25.569,0) from dual;--25
select trunc(25.569) from dual;--25
select trunc(25.569,-1) from dual;--20
select trunc(25.569, -2) from dual;--0
select trunc(25.569,-3) from dual;--0
select trunc(25.569,-9) from dual; --0
select trunc(215.569,-2) from dual;--200
select trunc(123.458,4) from dual;--123.458