检查点队列–实例崩溃恢复原理剖析
什么叫检查点队列?
检查点队列是将脏块连接起来,按照第一次脏的数据块依次往后串联起来,形成一个队列。
检查点的作用是什么?
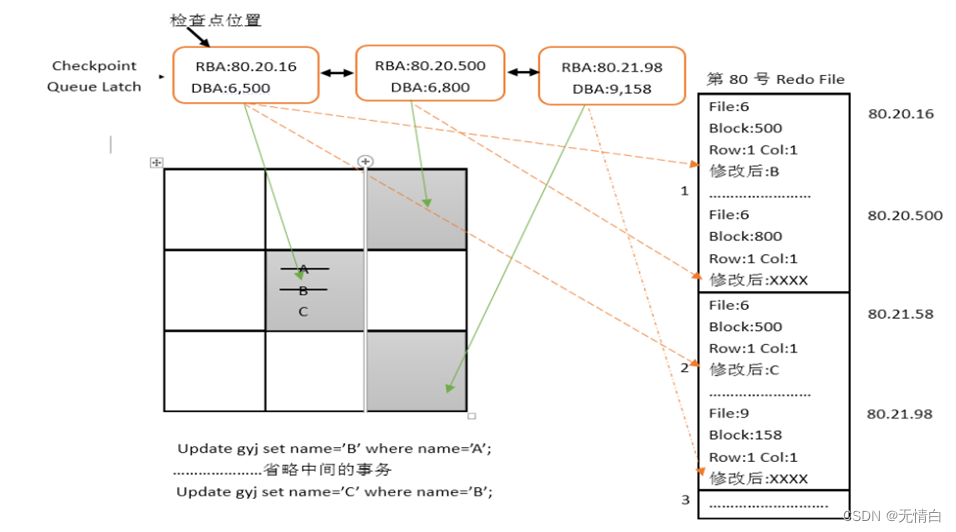
检查点只是一个数据库事件,它存在的根本意义在于减少崩溃恢复时间,Oracle8i以前是没有检查点队列这个说法的,当数据库宕机或者异常关闭的时候(shutdown abort) 再次启动数据库会根据全部的redo log日志将已提交的数据进行恢复,消耗很长时间,检查点队列出现以后只需要找到第一个脏快所对应的redo log的地址和最后被脏的脏快对应的redo log地址进行恢复,缩短了恢复的时间。如下图:
先来认识几个名词:
RBA: redo block address日志的地址,日志块的地址。 如我们对一个数据库进行修改并且提交了将会在redo log里产生对应的日志。RBA正是记录被修改的数据块对应的日志地址。
扩展:对每个脏块来讲有LRBA和HRBA,LRBA数据块指的是最早被脏的日志地址 HRBA数据块最近被脏的日志地址也是对应当前数据块最后一次被修改的日志地址。假设最近一次是第五次被脏,它也对应着一个地址叫HRBA地址。
LRBA 记录着最早被脏的数据块地址,而日志是按照时间顺序记录着buffercache的变化历程,也就是在它后面被脏的数据库都会在它后面也就是检查点队列的后面所有的数据块,它们的脏所对应的日志,都在LRBA对应的日志地址的下面。
如图中的数据块(文件后6 Block500)被修改为B 因为他对应的时间是最早被修改的,所以它可以理解为LRBA,所以对应的redo log它也排在第一位,而在被修改为A之后,又进行了一次事务,虽然不知道具体做了哪些修改,但它仅仅是在修改为A的事务之后发生的,所以排在第二位,redo log的地址也是仅在LRBA之后,紧接着又产了一个事务,将之前修改为B的数据块的名字修改为C,为了控制检查点队列的长度以及性能,相同的数据块再次被修改是不会再次被挂到链上的。所以在链上是看不出来的,但还是会依次记录在redo log中,这就是数据块被修改并且提交的过程。
后台进程和恢复:检查点(CKPT)
要了解实例恢复,需要了解特定后台进程的功能。
每隔三秒(或频率更高),CKPT 进程就在控制文件中存储一次数据,以记录DBWn 从
SGA 写入到磁盘的已修改数据块。这就称为“检查点”。检查点的用途是标识联机重做
日志文件开始进行实例恢复的位置(这个位置称为“检查点位置”)。
如果使用日志切换,CKPT 进程还会将这个检查点信息写入到数据文件头。
使用检查点的原因如下:
? 确保定期将内存中的已修改数据块写入磁盘,以便在系统或数据库出现故障的情况
下不会丢失数据
? 减少实例恢复所需的时间。在进行恢复时只需处理跟在最后一个检查点后面的联机
重做日志文件
? 确保在关闭过程中所有已提交数据都写入到数据文件中
由CKPT 进程写入的检查点信息包括检查点位置、系统更改号、联机重做日志文件中开始
恢复的位置、关于日志的信息等等。
注:CKPT 进程并不将数据块写入到磁盘,也不将重做块写入到联机重做日志文件。
检查点进程工作方式:
在启动数据库后输入ps -ef|grep ora 会发现有一个进程ora_ckpt这个进程就是检查点进程
这个进程有两种工作方式
完全检查点:当完全检查点发生的时候,CKPT进程会触发DBWR,将所有的脏块写到磁盘上。
增量检查点:将检查点队列最早被脏的日志地址记录在控制文件中,如果发现脏快太多,触发DBWR,缩短检查点队列。
完全检查点案列:
最经典的是关闭数据库的时候,oracle会发生一个完全检查点,CKPT会触发DBWR将所有的脏缓冲区写到磁盘上,这样数据库是干净的关闭了。
数据库正常运行的时候只有正常关闭的时候才会发生完全检查点,所以一般数据库正常运行期间完全检查点几乎不发生,它就会发生增量检查点。oracle每隔3秒钟会发生一次增量检查点。
我们可以用一条sql来查看当前被脏的数据块
select CPDRT,CPLRBA_SEQ||'.'||CPLRBA_BNO||'.'||CPLRBA_BOF "Low RBA",
CPODR_SEQ||'.'||CPODR_BNO||'.'||CPODR_BOF "On disk RBA",CPODS,CPODT,CPHBT
from x$kcccp;
执行结果
SQL> select CPDRT,CPLRBA_SEQ||'.'||CPLRBA_BNO||'.'||CPLRBA_BOF "Low RBA",
CPODR_SEQ||'.'||CPODR_BNO||'.'||CPODR_BOF "On disk RBA",CPODS,CPODT,CPHBT
from x$kcccp; 2 3
CPDRT Low RBA On disk RBA CPODS CPODT CPHBT
---------- -------------------- -------------------- ---------------- -------------------- ----------
16 5.13167.0 2.34561.0 527629 06/20/2022 13:58:38 911687624
0 0.0.0 0.0.0 0 0
0 0.0.0 0.0.0 0 0
0 0.0.0 0.0.0 0 0
0 0.0.0 0.0.0 0 0
0 0.0.0 0.0.0 0 0
0 0.0.0 0.0.0 0 0
0 0.0.0 0.0.0 0 0
8 rows selected.
CPDRT列是检查点队列中的脏块数目;
CPODS列是on disk rba的scn ;
CPODT列是on disk rba的时间戳 ;
CPHBT列是心跳。
On disk RBA列是一个地址,on disk rba是current日志的最后一条日志的地址。就是我们目前数据库里面的所保存的最后一条日志的地址,logbuffer里面的很多日志还没有写到current里面去,但是logbuffer里面写进来的最后一条日志叫on disk rba。目前数据库里面的current redolog里面的所记录的最新的rba地址叫on disk rba。
如果想要把数据库刷到磁盘里去可以执行
alter system flush buffer_cache;
再次查询脏快数量就会变为0,检查点队列也为空了。
实例恢复
实例恢复或崩溃恢复:
? 原因是尝试打开一个数据库,该数据库中的文件在关闭
时没有进行同步
? 是自动执行的
? 使用重做日志组中存储的信息来同步文件
? 涉及到两个不同的操作:
– 前滚:数据文件还原到实例出现故障之前所处的状态。
– 回退:已执行但尚未提交的更改会返回到初始状态。
Oracle Database 10g 会从实例故障自动进行恢复。DBA 需要执行的操作就是正常启动实例。
实例会装载控制文件,然后尝试打开数据文件。如果发现数据文件在关闭时没有进行同步,
则使用重做日志组中包含的信息将数据文件前滚到关闭时的状态,然后回退所有未提交的
事务处理(因为还原表空间也已前滚)。