��������Ҫ�˽����Hadoop��̬�е�HDFS,ʲô��HDFS��?
�����Hadoop����������ҫ�������Ļ�,��ôHDFS�Ĺ����ء��ͺñ����ǵĵ�ȯ,ֻ�����Ǯ��,�黨�ܲ��յ���,��ʱ��HDFS�����þͷ��ӳ�����,�����̨�ͻ������Ǯת��Ϊ��ȯ�ϴ���ȥ,���������ǵ������Dz��ǻ�������ء�

Hadoop��̬֮HDFS
1.HDFS����
1.1 HDFS��������������
1)HDFS��������
����������Խ��Խ��,��һ������ϵͳ�治�����е�����,��ô�ͷ��䵽����IJ���ϵͳ�����Ĵ�����,���Dz����������ά��,������Ҫһ��ϵͳ��������̨�����ϵ��ļ�,����Ƿֲ�ʽ�ļ�����ϵͳ��HDFSֻ�Ƿֲ�ʽ�ļ�����ϵͳ�е�һ�֡�
2)HDFS����
HDFS(Hadoop Distributed File System),����һ���ļ�ϵͳ,���ڴ洢�ļ�,ͨ��Ŀ¼������λ�ļ�;���,���Ƿֲ�ʽ��,�ɺܶ��������������ʵ���书��,��Ⱥ�еķ������и��ԵĽ�ɫ��
HDFS��ʹ�ó���:�ʺ�һ��д��,��ζ����ij�����һ���ļ�����������д��ر�֮��Ͳ���Ҫ�ı䡣
1.2 HDFS��ȱ��
�ŵ�
1)���ݴ���
- �����Զ���������������ͨ�����Ӹ�������ʽ,�����Ⱥ�ݴ��ԡ�

- ijһ��������ʧ֮��,�������Զ��ָ���

2)�ʺϴ���������
- ���ݹ�ģ:�ܹ��������ݹ�ģ�ﵽGB,TB,������PB��ģ�����ݡ�
- �ļ���ģ:�ܹ����������ģ���ϵ��ļ�����,�����൱֮��
3)�ɹ��������ۻ�����,ͨ���ั������,���Ⱥ�ɿ��ԡ�
ȱ��
1)���ʺϵ���ʱ���ݷ���,������뼶�Ĵ洢����,���������ġ�
2)����Ч�ĶԴ���С�ļ����д洢��
- �洢����С�ļ��Ļ�,��ռ��NameNode�������ڴ����洢�ļ�Ŀ¼�Ϳ���Ϣ����������Դ���˷��Ƿdz����ص�,��ΪNameNode���ڴ����������
- С�ļ��洢��Ѱַʱ��ᳬ����ȡʱ��,Υ���˵�ʱHDFS�����Ŀ�ꡣ
3)��֧�ֲ���д��,�ļ��漴�ġ�
- һ���ļ�ֻ����һ��д,����������߳�ͬʱ��
- ��֧������append(��),��֧���ļ�������ġ�

1.3HDFS��ɼܹ�
HDFS ��һ������ Master/Slave �ܹ���һ�� HDFS ��Ⱥ����һ�� NameNode,����һ�� Master Server,���������ļ�ϵͳ�������ռ�,�Լ����ڿͻ��˶��ļ��ķ��ʡ�һ�� HDFS ��Ⱥ��������� DataNode,�����洢���ݡ�
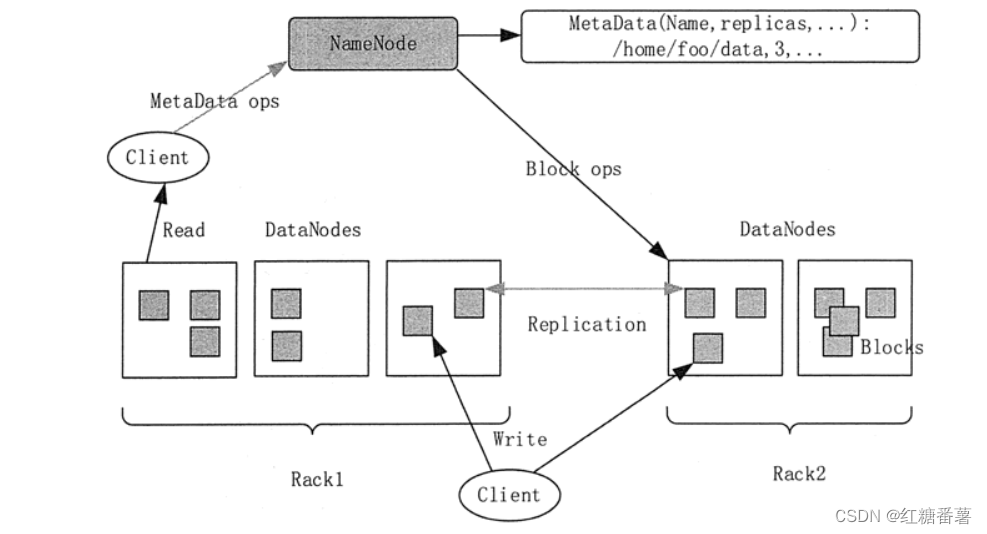
HDFS ����Ⱪ¶һ���ļ�ϵͳ�����ռ�,�������û��������ļ�����ʽ���д洢�����ڲ�,һ���ļ����ֳɶ���鲢����Щ�鱻�洢��һ�� DataNode �ϡ�
1)NameNode
�ļ���Ԫ���ݲ��ü���ʽ�洢��������� NameNode ���С�NameNode ����ִ���ļ�ϵͳ�����ռ�IJ���,���ԡ��رա��������ļ���Ŀ¼��NameNode ͬʱҲ�������ݿ�ӳ�䵽��Ӧ�� DataNode �С�
2) DataNode
DataNode ���ļ�ϵͳ�Ĺ�����㡣���Ǹ�����Ҫ�洢���������ݿ�,���Ҷ����� NameNode �����������洢�Ŀ���б����ļ����ݿ鱾���洢�ڲ�ͬ�� DataNode ����,DataNode ���Էֲ��ڲ�ͬ�����ϡ�
DataNode ��������ļ�ϵͳ�ͻ��˷����Ķ�/д����DataNode ͬʱҲ������� NameNode ��ָ�����������ݿ�Ĵ�����ɾ�����ơ�
3)Client
HDFS �� Client ��ֱ���� NameNode �� DataNode �Ի�ȡ�ļ���Ԫ��Ϣ�����ݡ�HDFS ��Ⱥ�� Client ��ֱ�ӷ��� NameNode �� DataNode,������ݻ�ֱ�Ӵ� NameNode ���� DataNode ���͵��ͻ��ˡ�
NameNode �� DataNode ���DZ����Ϊ����ͨ PC �����е���������HDFS ���� Java ����ʵ�ֵ�,�κ�֧�� Java ���ԵĻ������������� NameNode ���� DataNode��Java ���Ա����Ŀ���ֲ����ζ�� HDFS ���Ա��㷺�ز����ڲ�ͬ�Ļ����ϡ�
һ�����͵IJ������,��Ⱥ�е�һ̨ר�û������� NameNode,��Ⱥ�е���������ÿ̨����һ�� DataNode ʵ�����üܹ������ų���ͬһ̨���������ж�� DataNode ʵ���Ŀ���,����ʵ�ʵIJ����к��ٻ���ô����
��һ NameNode ����Ƽ���ؼ��˼�Ⱥ��ϵͳ�ܹ�,��ʹ������ HDFS Ԫ���ݵ��ٲúʹ洢���ɵ�һ NameNode ������,���������ݲ�һ���Ե����⡣
���������ļܹ�Ҳ�ǹ������������,��л���������顣

1.4HDFS�ļ����С(�����ص�)
HDFS�е��ļ����������Ƿֿ�洢(Block),��Ĵ�С����ͨ�����ò���(dfs.blocksize)���涨��,Ĭ�ϴ�С��Hadoop2.x/3.x����128M,��1.x�汾����64M��
2)���Ѱַʱ��ԼΪ100ms,�����ҵ�Ŀ��block��ʱ��Ϊ10ms��
3)Ѱַʱ��Ϊ����ʱ���1%ʱ,��Ϊ���״̬��(ר��)
���,����ʱ��=100ms/0.01=1000ms=1s
4)��Ŀǰ���̵Ĵ��������ձ�Ϊ100MB/S��
����Ϊʲô�ļ��첻������̫СҲ��������̫����?

(1)HDFS�Ŀ�����̫С,������Ѱַʱ��,�����һֱѰ�ҿ�Ŀ�ʼλ�á�
(2)��������õ�̫��,�Ӵ��̴������ݵ�ʱ������Դ��ڶ�λ����鿪ʼλ�������ʱ��,���³����ڴ����������ʱ,���ú�����
����HDFS�Ŀ��С������Ҫȡ���ڴ��̵Ĵ������ʡ�
2.HDFS�Ķ�д����(���Էdz���Ҫ)
HDFS ���ļ����ʻ���Ϊ��ʽ���ʻ���,��ͨ�� API ���ļ���ij�����ݿ�֮��,����˳���ȡ����д��ij���ļ������� HDFS �д��ڶ����ɫ,�Ҷ�Ӧ��Ӧ�ó�����ҪΪһ��д�롢��ζ�ȡ�ij���,��������д�ķ�ʽ�нϴ�ͬ����/д�������ɿͻ��˷���,�����ɿͻ��˽����������̵Ŀ���,NameNode �� DataNode ���DZ���ʽ��Ӧ��
��ȡ����
�ͻ��˷����ȡ����ʱ,������ NameNode �������ӡ�
���ӽ�����ɺ�,�ͻ��˻������ȡij���ļ���ijһ�����ݿ顣NameNode ���ڴ��н��м���,�鿴�Ƿ��ж�Ӧ���ļ����ļ���,��û����֪ͨ�ͻ��˶�Ӧ�ļ������ݿ鲻����,������֪ͨ�ͻ��˶�Ӧ�����ݿ������Щ������֮�ϡ�
�ͻ��˽��յ���Ϣ֮��,���Ӧ�� DataNode ����,����ʼ�������ݴ��䡣�ͻ��˻�ѡ�����������һ���������ݽ��ж�������
��ͼ 1 ��ʾ,��ȡ�ļ��ľ���������¡�
-
�ͻ��˵��� DistributedFileSystem �� Open() �������ļ���
-
DistributedFileSystem �� RPC ���ӵ� NameNode,�����ȡ�ļ������ݿ����Ϣ;NameNode �����ļ��IJ��ֻ���ȫ�����ݿ��б�;����ÿ�����ݿ�,NameNode ���᷵�ظ����ݿ鸱���� DataNode ��ַ;DistributedFileSystem ���� FSDataInputStream ���ͻ���,������ȡ���ݡ�
-
�ͻ��˵��� FSDataInputStream �� Read() ������ʼ��ȡ���ݡ�
-
FSInputStream ���ӱ�����ļ���һ�����ݿ������� DataNode,��������������ʽ��ȡ����;�ͻ��˶�ε��� Read(),ֱ���������ݿ����λ�á�
-
FSInputStream���ӱ�����ļ���һ�����ݿ������� DataNode,����ȡ���ݡ�
-
���ͻ��˶�ȡ���������ݿ�����ݺ�,���� FSDataInputStream �� Close() ������
HDFS��ȡ����
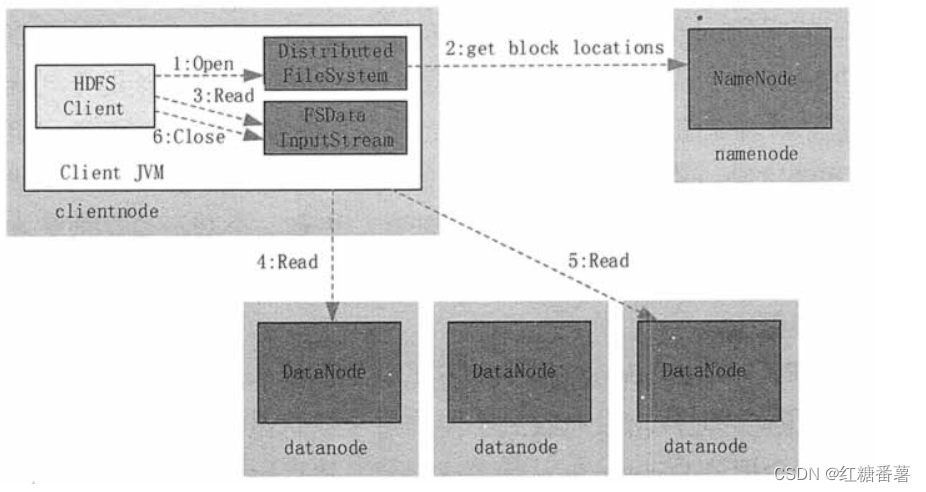
ͼ 1 HDFS ��ȡ����
�ڶ�ȡ���ݵĹ�����,����ͻ����������ݽ��ͨ��ʱ���ִ���,�������Ӱ��������ݿ����һ�����ݽ�㡣ʧ�ܵ����ݽ�㽫����¼,�����Ժ������ӡ�
�����
д���ļ��Ĺ��̱ȶ�ȡ��Ϊ����,�ڲ������κ��쳣�����,�ͻ����� HDFS д�����ݵ�������ͼ 2 ��ʾ,���岽�����¡�
HDFS �����
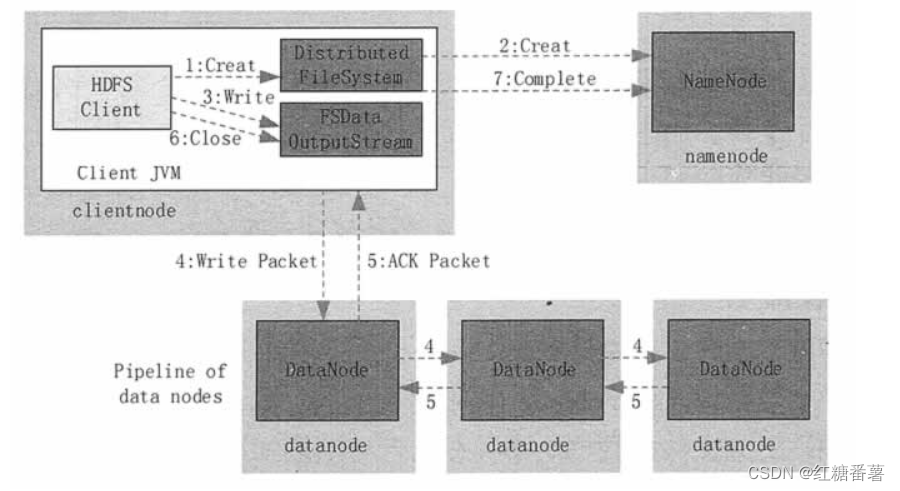
ͼ 2 HDFS ��ȡ����
-
�ͻ��˵��� DistribuedFileSystem �� Create() �����������ļ���
-
DistributedFileSystem �� RPC ���� NameNode,�������ļ�ϵͳ�������ռ��д���һ���µ��ļ�;NameNode ����ȷ���ļ�ԭ��������,���ҿͻ����д����ļ���Ȩ��,Ȼ�����ļ�;DistributedFileSystem ���� FSOutputStream ���ͻ�������д���ݡ�
-
�ͻ��˵��� FSOutputStream �� Write() ����,���Ӧ���ļ�д�����ݡ�
-
���ͻ��˿�ʼд���ļ�ʱ,FSOutputStream �Ὣ�ļ��зֳɶ���ְ�(Packet),��д����Ȳ������ݶ��С�FSOutputStream �� NameNode �������������ļ��������ݿ�����ɸ� DataNode,��Щ DataNode �γ�һ���������ܵ���
�����еķְ�����������ݰ�,�����������ܵ��еĵ�һ�� DataNode����һ�� DataNode �����ݰ������ڶ��� DataNode,�ڶ��� DataNode �����ݰ����͵������� DataNode������,���ݰ��������ܵ��ϵĸ��� DataNode��
-
Ϊ�˱�֤���� DataNode �����ݶ���ȷ��,���յ����ݵ� DataNode Ҫ�����߷���ȷ�ϰ�(ACK Packet)��ȷ�ϰ������������ܵ��������,���������ܵ����ξ������� DataNode,�����շ����ͻ��ˡ����ͻ����յ�Ӧ��ʱ,������Ӧ�ķְ����ڲ��������Ƴ���
-
����ִ�е� (3)~(5)��,ֱ������ȫ��д�ꡣ
-
���� FSOutputStream �� Close() ����,�����е����ݿ�д���������ܵ��е����ݽ��,���ȴ�ȷ�Ϸ��سɹ������ͨ�� NameNode ���д�롣
3.NameNode��SecondaryNameNode
3.1 NN��2NN��������
˼��:NameNode�е�Ԫ�����Ǵ洢�������?
�����ȼ���һ��,����洢��NameNode�ڵ�Ĵ�����,��Ϊ������Ҫ�����������,������Ӧ�ͻ�����,��Ȼ��Ч�ʹ��͡����,Ԫ������Ҫ������ڴ��С������ֻ�����ڴ���,һ���ϵ�,Ԫ���ݶ�ʧ,������Ⱥ���������ˡ���˲����ڴ����б���Ԫ���ݵ�FsImage��
�����ֻ�����µ�����,�����ڴ��е�Ԫ���ݸ���ʱ,���ͬʱ����FsImage,�ͻᵼ��Ч�ʹ���,�����������,�ͻᷢ��һ��������,һ��NameNode�ڵ�ϵ�,�ͻ�������ݶ�ʧ�����,����Edits�ļ�(ֻ�����Ӳ���,Ч�ʺܸ�)��ÿ��Ԫ�����и��»�������Ԫ����ʱ,���ڴ��е�Ԫ���ݲ��ӵ�Edits�С�����,һ��NameNode�ڵ�ϵ�,����ͨ��FsImage��Edits�ĺϲ�,�ϳ�Ԫ���ݡ�
����,�����ʱ���������ݵ�Edits��,�ᵼ�¸��ļ����ݹ���,Ч�ʽ���,����һ���ϵ�,�ָ�Ԫ������Ҫ��ʱ����������,��Ҫ���ڽ���FsImage��Edits�ĺϲ�,������������NameNode�ڵ����,�ֻ�Ч�ʹ��͡����,����һ���µĽڵ�SecondaryNamenode,ר������FsImage��Edits�ĺϲ���
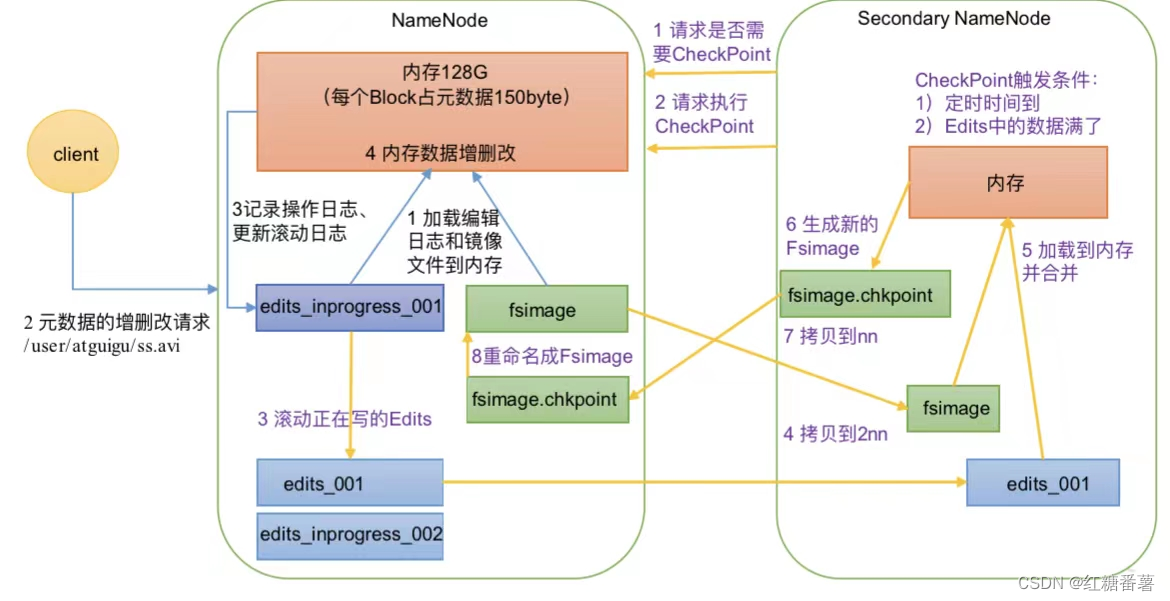
1)��һ��:NameNode����
(1)��һ������NameNode��ʽ����,����Fsimage��Edits�ļ���������� ��һ������,ֱ�Ӽ��ر༭��־�;����ļ����ڴ档
(2)�ͻ��˶�Ԫ���ݽ�����ɾ�ĵ�����
(3)NameNode��¼������־,���¹�����־��
(4)NameNode���ڴ��ж�Ԫ���ݽ�����ɾ�ġ�
2)�ڶ���:Secondary NameNode����
(1)Secondary NameNodeѯ��NameNode�Ƿ���ҪCheckPoint��ֱ�Ӵ� ��NameNode�Ƿ�������
(2)Secondary NameNode����ִ��CheckPoint��
(3)NameNode��������д��Edits��־��
(4)������ǰ�ı༭��־�;����ļ�������Secondary NameNode��
(5)Secondary NameNode���ر༭��־�;����ļ����ڴ�,���ϲ���
(6)�����µľ����ļ�fsimage.chkpoint��
(7)����fsimage.chkpoint��NameNode��
(8)NameNode��fsimage.chkpoint����������fsimage��
4.����HDFS�Ŀͻ�����Linux�����ֲ�����ʽ
HDFS �ļ����������ַ�ʽ:һ���������з�ʽ,Hadoop �ṩ��һ���� Linux �ļ��������Ƶ������й���;��һ���� Java API,������ Hadoop �� Java ��,���ñ�̵ķ�ʽ���� HDFS ���ļ���
���������� Linux ����ϵͳ�й��� HDFS �ļ������ij���������,������������ Hadoop �ṩ�� Java API ���л������ļ�����,�Լ����� Web ����鿴���� HDFS �ķ�����
HDFS ��������
�� Linux �������ն�,����ʹ�������й��߶� HDFS ���в�����ʹ����Щ�����п������ HDFS �ļ����ϴ������غ���,�����Բ鿴�ļ���Ϣ����ʽ�� NameNode �ȡ�
HDFS �����е�ͳһ��ʽ���¡�
hadoop fs -cmd <args>
����,cmd�Ǿ�����ļ���������,��һ����Ŀ�ɱ�IJ�����
- �����ļ���Ŀ¼
HDFS ��һ��Ĭ�Ϲ���Ŀ¼ /usr/ U S E R , �� �� , USER,����, USER,����,USER�ǵ�¼�û���,�� root����Ŀ¼�����Զ�����,��Ҫִ�� mkdir �������
hadoop fs -mkdir /usr/root
ʹ�� Hadoop ������put�������ļ� README.txt �ϴ��� HDFS��
hadoop fs -put README.txt
ע��,���������������һ��������:��.��,����ζ�Űѱ����ļ��ϴ���Ĭ�ϵĹ���Ŀ¼��,������ȼ������´��롣
hadoop fs -put README.txt /user/root
- �����ļ�
�����ļ���ָ�� HDFS �л�ȡ�ļ�,����ʹ�� Hadoop �� get �������,�������ļ�û�� README.txt �ļ�,����Ҫ�� HDFS ��ȡ��,����ִ���������
hadoop fs -get README.txt
����ִ���������
hadoop fs -get README.txt /usr/root/README.txt
- ɾ���ļ�
Hadoop ɾ���ļ�������Ϊrm������,Ҫɾ���ӱ����ļ��ϴ��� HDFS �� README.txt,����ִ���������
hadoop fs -rm README.txt
- �����ļ�
�����ļ������� HDFS �е��ļ�����,����ʹ�� Hadoop �е�cat�������,Ҫ���� README.txt ������,����ִ���������
hadoop fs -cat README.txt
����,Hadoop ��cat��������Ҳ����ʹ�ùܵ����ݸ� UNIX ����� head,����ֻ��ʾ�ļ���ǰһǧ���ֽڡ�
hadoop fs -cat README.txt | head
Hadoop Ҳ֧��ʹ��tail����鿴���һǧ�ֽڡ�����,Ҫ���� README.txt ���һǧ���ֽ�,����ִ���������
hadoop fs -tail README.txt
- ������
���� HDFS �������,���Ը��õ��˽��ʹ�� Hadoop ������û�����ִ��hadoop fs����ȡ���ð汾 HDFS ��һ�������������,Ҳ����ʹ��help����ʾij������������÷������������
����,Ҫ�˽�ls����,��ִ���������
hadoop fs -help ls
HDFS �� Web ����
�����ú� Hadoop ��Ⱥ֮��,�û�����ͨ�� Web ����鿴 HDFS ��Ⱥ��״̬,�Լ����� HDFS,���ʵ�ַ���¡�
http://[NameNodeIP]:50070
����,[NameNodeIP]Ϊ HDFS ��Ⱥ�� NameNode �� IP ��ַ����¼��,�û����Բ鿴 HDFS ����Ϣ��
��ͼ 1 ��ʾ,ͨ�� HDFS NameNode �� Web ����,�û����Բ鿴 HDFS �и������ķֲ���Ϣ,��� NameNode �ϵĴ洢����¼����־,�Լ�����ij�� DataNode ��ij���ļ������ݡ�
ͨ�� HDFS �� Web ����,�����Բ鿴������Ⱥ�Ĵ���������,HDFS �Ѿ�ʹ�õĴ洢�ռ���,�� HDFS �Ѿ�ʹ�õĴ洢�ռ���,HDFS ʣ��Ĵ洢�ռ�������Ϣ,�Լ��鿴��Ⱥ�еĻ�������崻��������
ͼ 2 ��ʾ��һ�� DataNode ����Ϣ,����̵�����,ÿ����̵�ʹ������ȡ�ͨ�� Web �����еġ�Utilities������Browse the file system�����Բ鿴��ǰ HDFS ��Ŀ¼�б�,�Լ�ÿ��Ŀ¼�������Ϣ,��������Ȩ�ޡ���������ڡ��ļ�ӵ���ߡ�Ŀ¼��С�ȡ�
��һ��,�û�������ͨ�� Web ����鿴�ļ�����Ϣ,��ͼ 3 ��ʾ���û��������Բ鿴�ļ���Ȩ�ޡ���С����Ϣ,�����Բ鿴���ļ���ÿ�����ݿ����ڵ����ݽ�㡣
��Ϊÿһ���ļ����Ƿֳɺö����ݿ��,ÿ�����ݿ����� 3 ������,��Щ���ݿ�ĸ���ȫ���ֲ�����ڶ�� DataNode ��,�����û���������ͳ�ļ�ϵͳ�����������ļ���HDFS Web ������û��ṩ��һ�����㡢ֱ�۵ز鿴 HDFS �ļ���Ϣ�ķ�����ͨ�� Web ������ɵ����в���,������ͨ�� Hadoop �ṩ��������ʵ�֡�
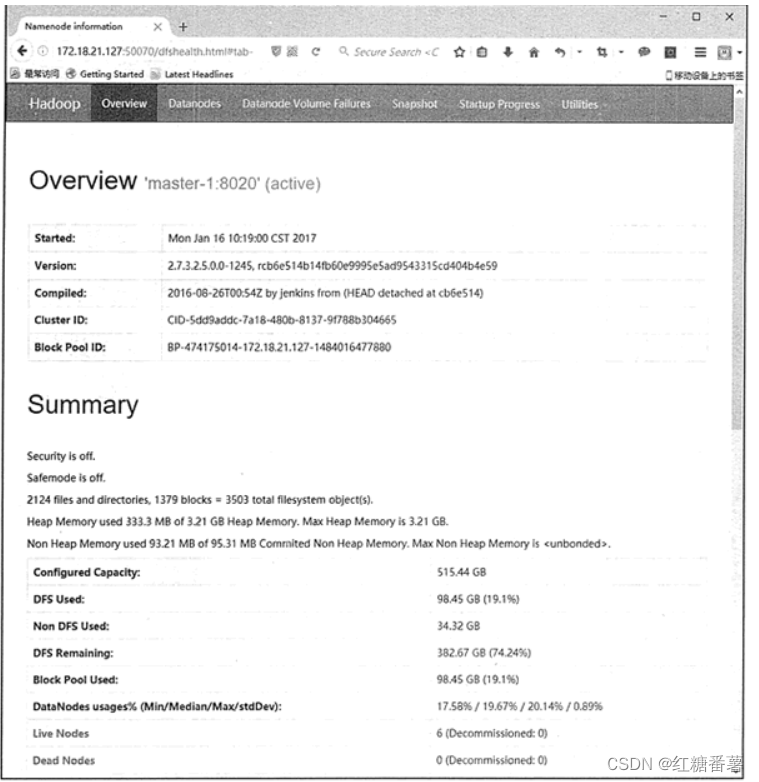
HDFS NameNode��WEB����
ͼ 1 HDFS NameNode��WEB����
HDFS DataNode��WEB����
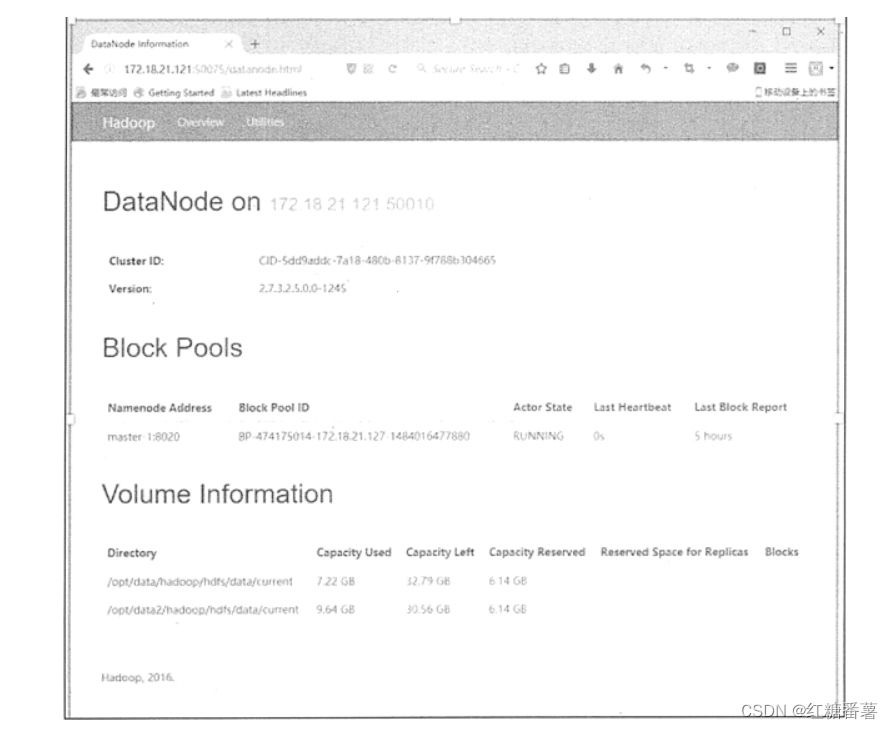
ͼ 2 HDFS NameNode��WEB����
HDFS�ļ�����
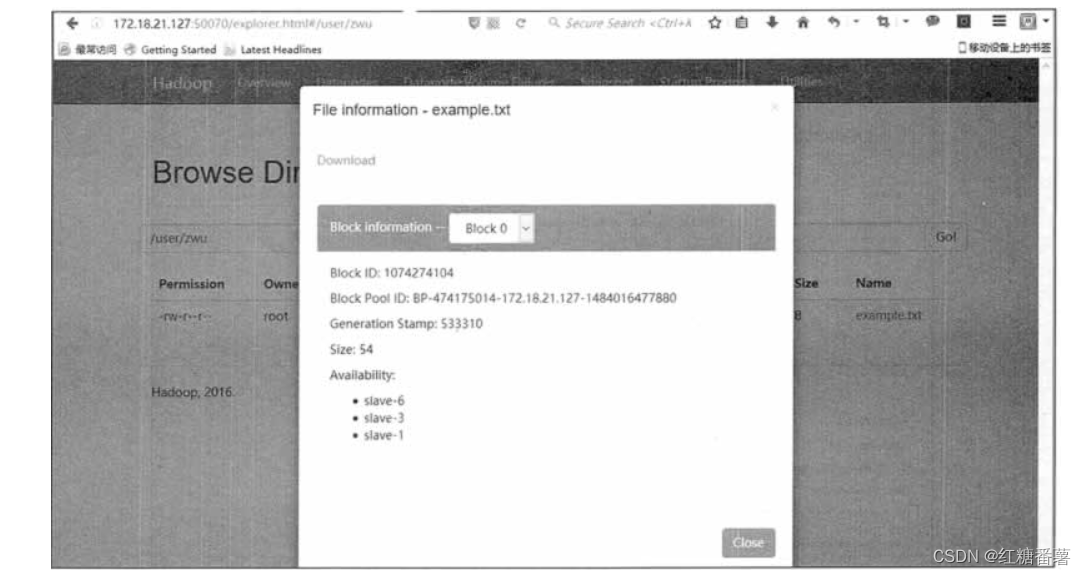
ͼ 3 HDFS�ļ�����
HDFS �� Java API
HDFS ��Ƶ���ҪĿ���ǶԺ������ݽ��д洢,Ҳ����˵�������ܹ��洢�ܴ������ļ���
HDFS ����Щ�ļ��ָ�֮��,�洢�ڲ�ͬ�� DataNode ��,HDFS �ṩ��ͨ��Java API �� HDFS ������ļ����в����Ĺ���,���ݿ��� DataNode �ϵĴ��λ��,���ڿ�������˵�����ġ�
ʹ�� Java API ������ɶ� HDFS �ĸ��ֲ���,���½��ļ���ɾ���ļ�����ȡ�ļ����ݵȡ����潫���� HDFS ���õ� Java API ������ʵ����
�� HDFS �е��ļ�������Ҫ�漰���¼����ࡣ
| ���� | ���� |
|---|---|
| org.apache.hadoop.con.Configuration | ����Ķ����װ�˿ͻ��˻��߷����������á� |
| org.apache.hadoop.fs.FileSystem | ����Ķ�����һ���ļ�ϵͳ����,�����øö����һЩ���������ļ����в����� |
| org.apache.hadoop.fs.FileStatus | ����������ͻ���չʾϵͳ���ļ���Ŀ¼��Ԫ����,��������ļ���С�����С��������Ϣ�������ߡ���ʱ��ȡ� |
| org.apache.hadoop.fs.FSDatalnputStream | ������ HDFS �е�������,���ڶ�ȡ Hadoop �ļ��� |
| org.apache.hadoop.fs.FSDataOutputStream | ������ HDFS �е������,����д Hadoop �ļ�; |
| org.apache.hadoop.fs.Path | �������ڱ�ʾ Hadoop �ļ�ϵͳ�е��ļ�����Ŀ¼��·���� |
��������ͨ��һ��ʵ����˵����ζ��ļ����о��������
1. ��ȡ�ļ�ϵͳ
/**
* ��ȡ�ļ�ϵͳ
* @author Tim
*/
public static FileSystem getFileSystem(){
// ��ȡ�����ļ�
Configuration conf = new Configuration();
// �ļ�ϵͳ
FileSystem fs = null;
String hdfsUri = HDFSUri;
if(StringUtils.isBlank(hdfsUri)){
// ����Ĭ���ļ�ϵͳ,�����Hadoop��Ⱥ������,ʹ�ô˷�����ֱ�ӻ�ȡĬ���ļ�ϵͳ
try{
fs = FileSystem.get(conf);
}catch(IOException e){
logger.error("",e);
}
}else{
// ����ָ�����ļ�ϵͳ,����ڱ��ز���,��Ҫʹ�ô˷�����ȡ�ļ�ϵͳ
try{
URI uri = new URI(hdfsUri.trim());
fs = FileSystem.get(uri,conf);
}catch(URISyntaxException | IOExeption e){
logger.error("",e);
}
}
return fs;
}
2. �����ļ�Ŀ¼
/**
* �����ļ�Ŀ¼
* @author Tim
*/
public static void mkdir(String path){
try{
// ��ȡ�ļ�ϵͳ
FileSystem fs = getFileSystem();
String hdfsUri = HDFSUri;
if(StringUtils.isNotBlank(hdfsUri)){
path = hdfsUri + path;
}
// ����Ŀ¼
fs.mkdirs(new Path(path));
// �ͷ���Դ
fs.close();
}catch(IllegalArgumentException | IOException e){
logger.error("",e);
}
}
3. ɾ���ļ������ļ�Ŀ¼
/**
* ɾ���ļ������ļ�Ŀ¼
* @author Tim
*/
public static void rmdir(String path){
try{
// ���� FileSystem ����
FileSystem fs = getFileSystem();
String hdfsUri = HDFSUri;
if(StringUtils.isNotBlank(hdfsUri)){
path = hdfsUri + path;
}
// ɾ���ļ������ļ�Ŀ¼
fs.delete(new Path(path),true);
// �ͷ���Դ
fs.close();
}catch(IllegalArgumentException | IOException e){
logger.error("",e);
}
}
4. ���ļ��ϴ��� HDFS
/**
* ���ļ��ϴ��� HDFS
* @author Tim
*/
public static void copyFileToHDFS(boolean delSrc,boolean overwrite,String srcFile,String destPath){
// Դ�ļ�·���� Linux �µ�·��
Path srcPath = new Path(srcFile);
// Ŀ��·��
String hdfsUri = HDFSUri;
if(StringUtils.isNotBlank(hdfsUri)){
destPath = hdfsUri + destPath;
}
Path dstPath = new Path(destPath);
// ʵ���ļ��ϴ�
try{
// ��ȡ FileSystem ����
FileSystem fs = getFileSystem();
fs.copyFromLocalFile(srcPath,dstPath);
fs.copyFromLocalFile(delSrc,overwrite,srcPath,dstPath);
// �ͷ���Դ
fs.close();
}catch(IOException e){
logger.error("",e);
}
}
5. �� HDFS �����ļ�
/**
* �� HDFS �����ļ�
* @author Tim
*
*/
public static void getFile(String srcFile,String destPath){
// Դ�ļ�·��
String hdfsUri = HDFSUri;
if(StringUtils.isNotBlank(hdfsUri)){
srcFile = hdfsUri + srcFile;
}
Path srcPath = new Path(srcFile);
// Ŀ��·���� Linux �µ�·��
Path dstPath = new Path(destPath);
try{
// ��ȡFileSystem����
FileSystem fs = getFileSystem();
// ����HDFS�ϵ��ļ�
fs.close();
}catch(IOException e){
logger.error("",e);
}
}
PS:
���ڸ�����IJ�����������ô����,�н������˽�Ż�������Ŷ,��ӭ����֧�֡�
