提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
对 Hadoop Spark Flink 这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
一、数据倾斜是什么?
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一task处理的的数据量或者时间显著多于其它部分,从而使得该部分的处理速度成为整个任务处理的瓶颈。简单来说数据倾斜就是key的分化严重不均。
二、数据倾斜发生的现象
1、绝大多数 task 执行得都非常快,但个别 task 执行极慢。比如,总共有 1000 个 task,997 个 task都在 1 分钟之内执行完了,但是剩余两三个 task 却要5倍,10倍,甚至给多时间才能完成。这种情况很常见。
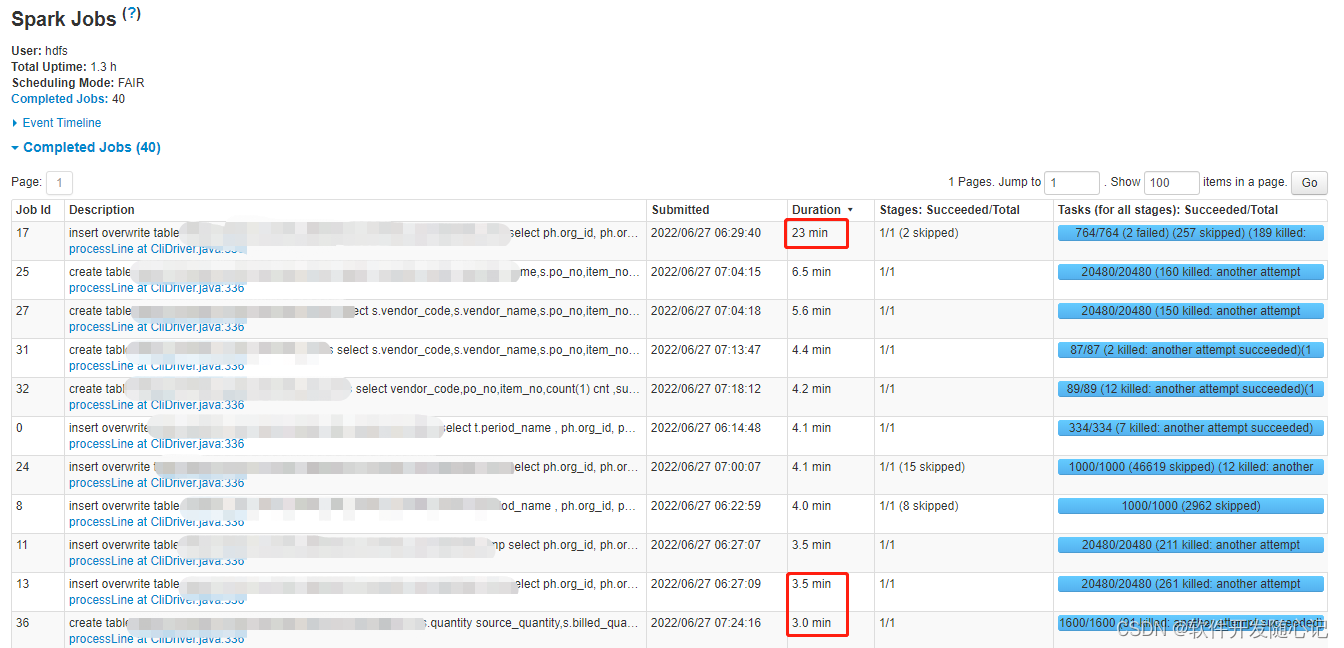
2、原本能够正常执行的 Spark 作业,某天突然报出 OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
三、数据倾斜发生原理
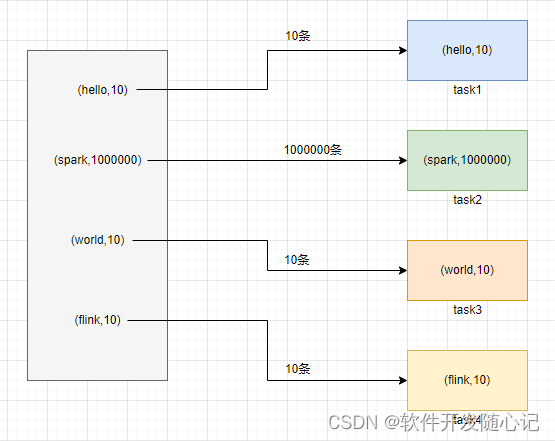
在进行 shuffle 的时候,必须将各个节点上相同的 key 拉取到某个节点上的一个 task 来进行处理,比如按照 key 进行聚合或 join 等操作。此时如果某个key 对应的数据量特别大的话,就会发生数据倾斜。比如大部分 key 对应 10 条数据,但是个别 key 却对应了 100 万条数据,那么大部分 task 可能就只会分配到 10 条数据,然后 1 秒钟就运行完了;但是个别 task 可能分配到了 100 万数据,要运行一两个小时。因此,整个 Spark 作业的运行进度是由运行时间最长的那个 task 决定的。
因此出现数据倾斜的时候,Spark 作业看起来会运行得非常缓慢,甚至可能因为某个 task 处理的数据量过大导致内存溢出。
四、数据倾斜产生场景
主要分为3类:
1、shuffle倾斜:
一般由shuffle算子导致,例如:count ,distinct ,avg ,min, max等aggregation操作和join倾斜(五大Join )。
在spark UI上可以看到整个作业(action/application)所有stage中Duration值最大,且有Shuffle Read,没有Input。
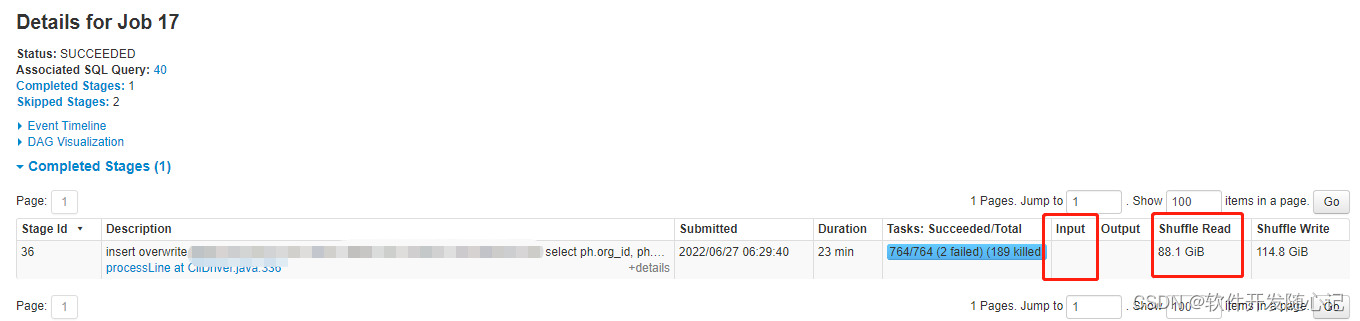
2、读倾斜:
源数据有倾斜(特别相同key多的场景),加上列式存储(相同的key只存储一次)。
在spark UI上可以看到整个作业(action/application)所有stage中Duration值最大,且有Input,没有Shuffle Read。

3、写倾斜:
一般distribute by 或者 partition over 或者 reparation 小 或者 并发低 造成最后只有几个task生产数据文件。
五、数据倾斜的危害
1、整体耗时过大(整个任务的完成由执行时间最长的那个Task决定)
2、应用程序可能异常退出(某个Task执行时处理的数据量远远大于正常节点,则需要的资源容易出现瓶颈,当资源不足,则应用程序退出)
3、资源闲置(处理等待状态的Task资源得不到及时的释放,处于闲置浪费状态)
六、数据倾斜的解决方案
1、过滤少数导致倾斜的 key
2、调整shuffle操作的并行度
set spark.sql.shuffle.partitions=1600;//默认200,可以按200、400、800、1600、3200…增加
3、小表广播
强制加上 broadcast hint 语法,即 /*+ broadcast(小表别名) */,将sortmergejoin转换为broadcastjoin
4、使用随机数和双重聚合
原有聚合SQL逻辑
select id,count(1) from tbl group by id ;
改成
现在聚合SQL逻辑
SELECT split(t2.new_id,'_')[0] AS id,sum(t2.cnt) AS cnt
FROM
(SELECT t1.new_id ,
count(1) AS cnt
FROM
(SELECT id,
value,
concat(id,
'_',cast(rand()*10000 as int)%3) AS new_id
FROM tbl) t1
GROUP BY new_id ) t2
GROUP BY split(t2.new_id,'_')[0];
5、倾斜key增加随机数进行独立join
1.适应场景:两个表表join,都大表,无法使用broadcast Join,但倾斜key 不多。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
2.解决 : 先拆分倾斜表的倾斜key,加上随机数形成临时表a1,倾斜表其他非倾斜部分形成临时a2表; 对于非倾斜表过滤倾斜key,扩容形成临时表b1,非倾斜表非倾斜key 形成b2然后a1和b1进行join(同时去掉随机数),a2和b2进行join,最后合并。
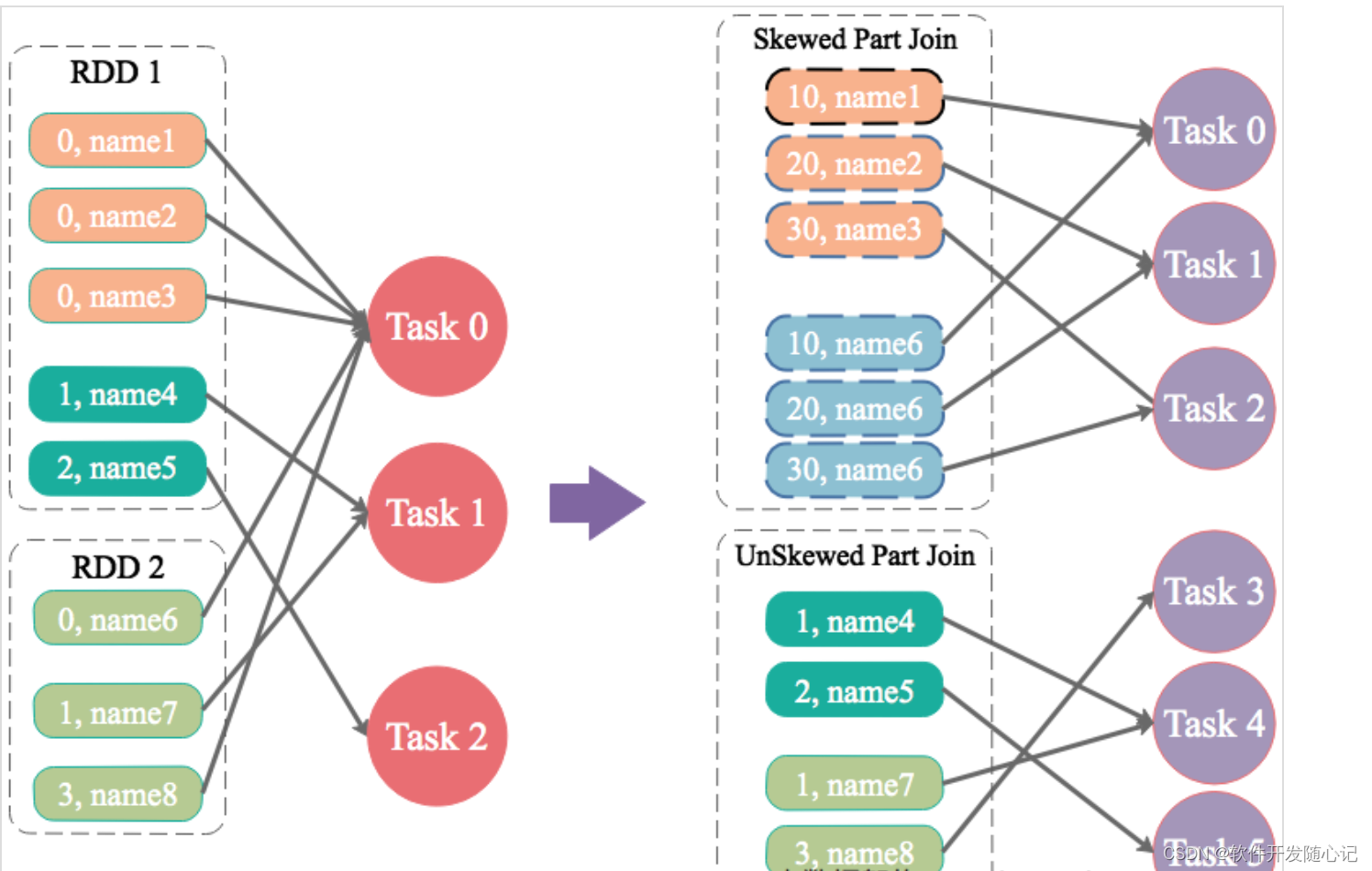
原有SQL逻辑
select t1.id,t2.value from t1 join t2 on t1.id=t2.id where t1.dt=20191001 ;
改成
优化后SQL逻辑
2个join一个union替代原来的join
--倾斜部分
select split(a.id,'_')[0],split(b.id,'_')[0],a.value,b.value from
(select concat(t1.id,'_',cast(rand()*10000 as int)%3) AS id,t2.value from t1 where t1.id in ('倾斜id列表')) a
join
( SELECT id, value,concat(id,'_',suffix) AS id FROM
(SELECT id, value , suffix FROM t2 Lateral View explode(array(0,1,2)) tmp AS suffix where t2.id in ('倾斜id列表')) tt
) b
on a.id=b.id
union all -- 最后合并倾斜和非倾斜部分
--非倾斜部分
select t1.id,t2.value from t1
join t2
on t1.id=t2.id
where t1.dt='20191001' and t1.id not in ('倾斜id列表') and t2.id not in ('倾斜id列表'); //非倾斜key
6、倾斜表随机数以及扩容表进行join
1.场景:两个表join,都是大表 但是其中一个表数据存在的倾斜Key比较多,另外一个数据集数据分布比较均匀。
2.解决:倾斜表全部数据打散,非倾斜表全部扩容,然后join,去掉前缀 。
原始A表的逻辑修改:
select id,value from A
改成
select id,value,concat(id,'_',cast(rand()*10000 as int)%3) as new_id from A
原始B表的逻辑修改:
select id,value from B
改成
select id,value,concat(id,'_',suffix) as new_id
from (
select id,value ,suffix
from B Lateral View explode(array(0,1,2)) tmp as suffix
)
Join逻辑修改==
select a.id, count(1) from
A a join B b
on a.id=b.id
改成
SELECT split(c.new_id,'_')[0] AS id, sum(cnt) AS cnt
FROM
(SELECT a.new_id,count(1) AS cnt
FROM
(SELECT id,value,concat(id,'_',cast(rand()*10000 as int )%3) AS new_id FROM t1) a
JOIN
( SELECT id, value,concat(id,'_',suffix) AS new_id FROM (SELECT id, value , suffix FROM t2 Lateral View explode(array(0,1,2)) tmp AS suffix ) tt ) b
ON a.new_id=b.new_id
) c
GROUP BY split(c.new_id,'_')[0]
7、SparkSQL自适应分区
开启自适应分区
set spark.sql.adaptive.enabled = true;
开启自动处理倾斜
set spark.sql.adaptive.skewJoin.enabled = true;
倾斜因子
set spark.sql.adaptive.skewJoin.skewedPartitionFactor =5;
8、使用Hive ETL预处理数据,在前置任务或表里进行处理。
总结
优化项是要不断尝试,不断调试,然后才能得出来一个可行的,有效的方法。
vicente.liu 2022-06-27
注:本文有引用其他文章及图片,如有侵权,请私信,然后删除。