����Ŀ¼
ǰ��
Postgresql �Ĵ洢���� ��heap������,�����洢postgresql ���û�����ϵͳ�� �� ʵ������ �Լ� �������ݡ�
�˽�pg ��heap ������ײ����ϸ��,�ܹ��������Ǹ��õ��������� pg �Ķ�д �Լ� ��������·��
���� heap�������� Relation cache, WAL(xlog), CheckPoint, BufferPool ����ǿ��ص�,�Ͼ���һЩ���ƻ���˵�������Ϊ�˴��������ݶ����ڵ�,��heap �洢�������ǹ����������ڴ����ϵ������ṹ,���Դ���������̽��PG �ܹ���Ϊ�ṹ�� �� ȷ��
�����漰���� postgresql Դ����汾 REL_12_2
Heap�� �����ṹ
PG���ݿ�Ŀ¼
heap���洢���� �ǹ��������ݵ�һ��PG �����������ʵ�ʵĴ�����̬����ͨ��ֱ�Ӳ鿴pg�������� �ļ�ϵͳĿ¼������
������ʹ�� pg�� createdb �������һ�����ݿ�֮��,pg ���� $PGDATA/base Ŀ¼������һ���µ�Ŀ¼,�����洢��������õ� db �ı�����,pg ��ͬ���ݿ�֮������ȫ��������ġ�
����
$PGDATA�����dz�ʼ�� ���ݿ� �Լ� ʹ��pg_ctl���� pgʱָ�������ݴ��Ŀ¼��
$ ./bin/createdb testdb
$ cd $PGDATA
$ ls -l base
total 40
drwx------ 2 admin admin 4096 Jun 24 16:44 1
drwx------ 2 admin admin 4096 Jun 24 16:44 12708
drwx------ 2 admin admin 12288 Jun 25 17:16 12709
drwx------ 2 admin admin 12288 Jun 25 22:00 16384
���� 1, 12708, 12709 Ŀ¼��Ӧ�� ���ݿ����� initdb ��ʱ��Ԥ�ȴ����õ�ϵͳ���ݿ⡣�� 16384 ��ʱ���Ǵ��� testdb ʱ Ĭ�ϴ�����Ŀ¼��
����ͨ�� psql ���� testdb ����ȷ�� �������� pgĿ¼:
$./bin/psql testdb
psql (12.2)
Type "help" for help.
testdb=# select pg_relation_filepath('pg_class');
pg_relation_filepath
----------------------
base/16384/1259
(1 row)
�������������ӵ� testdb֮�� �鿴ijһ����������Ŀ¼,���� base/16384������ $PGDATAĿ¼�µ����ݿ�Ŀ¼,1259 �ļ���ʾ���� pg_class ������е����ݴ洢���ļ���
heap�� ʵ�ʵ������ļ�
ǰ�������ܹ�ͨ�� pg_relation_filepath ����ȷ��һ����ʵ������ �����������ļ���
���������ͬһ�����ݿ��д���һ���µı�,pg ��Ϊ�������������һ���洢�������ļ�,�� ���������һ������db �ڲ���Ψһ��ʶ oid ,���һ�洢�� pg_classϵͳ���ڲ�,������ pg_class �ڲ� select ���ҵ���relfilenode ���Ǹñ�ʵ�ʵ������ļ�����,����������ִ���� truncate ��ᱣ�� oid��������������һ���µ� relfilenode,Ҳ����һ���µ��ļ���
$ ./bin/psql testdb
testdb=# create table d (c1 int, c2 int, c3 int);
CREATE TABLE
testdb=# select pg_relation_filepath('d');
pg_relation_filepath
----------------------
base/16384/16430
(1 row)
testdb=# select relname, oid, relfilenode from pg_class where relname ='d';
relname | oid | relfilenode
---------+-------+-------------
d | 16430 | 16430
(1 row)
���Կ���ʵ�ʵ������ļ�(�յ�,��Ϊ���Dz�û������ڲ�������):
$ ls -l base/16384/16430
-rw------- 1 admin admin 0 Jun 25 22:46 base/16384/16430
Ȼ��������������ڲ����뼸������,���Կ���ʵ�ʵı��ļ��Ѿ���������:
testdb=# insert into d values(1, 11, 12);
INSERT 0 1
testdb=# insert into d values(2, 21, 22);
INSERT 0 1
testdb=# select * from d;
c1 | c2 | c3
----+----+----
1 | 11 | 12
2 | 21 | 22
(2 rows)
------------------------------------------------
$ ls -l base/16384/16430
-rw------- 1 admin admin 8192 Jun 25 22:46 base/16384/16430
������Dz鿴���� ���ݿ� 16384 ��Ŀ¼,���ܹ�����һЩ���ļ�Ϊǰ�� _fsm �Լ� _vm�ļ�,���Ƿֱ��ǹ��������� ���пռ�ӳ�� �Լ� �ɼ���ӳ��ij־û��ļ�,�ֱ����� Ϊ�����ݴӱ��ļ��з���洢�ռ� �Լ� �����д�������� ���ݿɼ��Լ��ġ�
heap�� ��������
һ�����������Ƿ���һ���ļ�,���������������Խ��Խ��,�ļ�Ҳ��Խ��Խ��,Ĭ�� �������ļ��������� 1G (�����ڱ��� pg ʱͨ��ָ�� --with-segsize ���� ���ļ��Ĵ�С����,����û��ͨ�� pgoptions ���ĵ�),����������ļ���С������1G,�������һ�� base/16384/16430.1 �ļ��������������ݵ�д��,�Դ����ơ�
���ļ��ڲ� ��ᱻ��Ϊһ����С�� page,����˵ block �������ݴ洢����,page �� block �������� pg �ڲ��������ṹ����������,�� os ������ �ڴ� page �� ���� block �Dz�һ����,���� pg ���ļ�����ɵ�λ ����ͳһ�� page���гƺ�,Ĭ��һ�� page ��С�� 8K(ͬ��,��Ҫ�ڱ����ʱ��ָ�� --with-blocksize �����б��)��
�������ļ���һ����page���,ÿһ��page�������Լ��ı��(block number) ����Ψһ��ʶһ��page��һ�� page �ڲ�������һ���� heaptuple ������Ԫ�����,������ʵ�ʵı������ݡ�
���ǿ���ͨ�����¼��� pg ������չ��� pageinspect �ṩ����չ�����������˽�һ��page����֯�ṹ �Լ� page �ڲ��� Ԫ���һЩ��Ϣ,����ͨ�� create extension pageinspect; ����extension��
������һЩ��Ϣ�Ľ���,�������ϸ����,�����ȼ�һ�¡�
-
�鿴��
d�� ��һ��page ��header��Ϣ,����page_header������ȡpage��header�ṹ,get_raw_page��ȡ ��d�� block number Ϊ0����һ���� pagetestdb=# SELECT * FROM page_header(get_raw_page('b', 0)); lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid -----------+----------+-------+-------+-------+---------+----------+---------+----------- 0/164D980 | 0 | 0 | 36 | 8096 | 8192 | 8192 | 4 | 0 (1 row) -
�鿴��
d�ĵ�һ�� page ��tuple��ϢSELECT * FROM heap_page_items(get_raw_page('d', 0));,����heap_page_items��ȡ page �ڲ�ÿһ��heaptupleԪ����Ŀ��Ϣ:testdb=# SELECT * FROM heap_page_items(get_raw_page('d', 0)) where lp < 5; lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data ----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+---------------------------- 1 | 8152 | 1 | 36 | 516 | 0 | 0 | (0,1) | 3 | 2304 | 24 | | | \x010000000b0000000c000000 2 | 8112 | 1 | 36 | 517 | 0 | 0 | (0,2) | 3 | 2304 | 24 | | | \x020000001500000016000000 3 | 8072 | 1 | 36 | 518 | 0 | 0 | (0,3) | 3 | 2304 | 24 | | | \x01000000300000001f000000 4 | 8032 | 1 | 36 | 518 | 0 | 0 | (0,4) | 3 | 2304 | 24 | | | \x02000000280000000e000000 (4 rows) -
�������� ����������һЩ,��һ��Ԫ�� t_data �ڲ��� attrs ��Ϣ:
testdb=# SELECT lp,lp_off, t_xmin, t_ctid, t_attrs FROM heap_page_item_attrs(get_raw_page('d', 0), 'd') where lp < 5; lp | lp_off | t_xmin | t_ctid | t_attrs ----+--------+--------+--------+--------------------------------------------- 1 | 8152 | 516 | (0,1) | {"\\x01000000","\\x0b000000","\\x0c000000"} 2 | 8112 | 517 | (0,2) | {"\\x02000000","\\x15000000","\\x16000000"} 3 | 8072 | 518 | (0,3) | {"\\x01000000","\\x30000000","\\x1f000000"} 4 | 8032 | 518 | (0,4) | {"\\x02000000","\\x28000000","\\x0e000000"} (4 rows)
�����������п��ԱȽ������ÿ������ݱ��ļ���һ��page �Լ� page�ڲ���Ӧ��Ԫ��ṹ,ӵ�зdz�����ֶ����� page �Լ� Ԫ��ṹ��������,����������ϸ��һ������page �Լ� Ԫ����ں˽ṹ��
heap���ṹ
���� pg Ϊʲô�����ļ����� heap table,��Ӧ��(��ȷ��)�� ����Ϊ �ڱ��ļ��е�ÿһ��page �ڲ��ռ�ķ����Ǵ��ļ�ĩβ���ļ���ͷ����,�е�����os �Ķ��ڴ�����Ǵӵ͵�ַ�ռ���ߵ�ַ�ռ�����,����ֱ�ӽ����ѱ��ļ���
�����ѱ��ļ� �ɶ�� page���,ÿһ��page��һ��Ψһ��ʶ�� block number,�������������� page �Լ����ڲ���heap tuple ������һЩ�ֶ�:
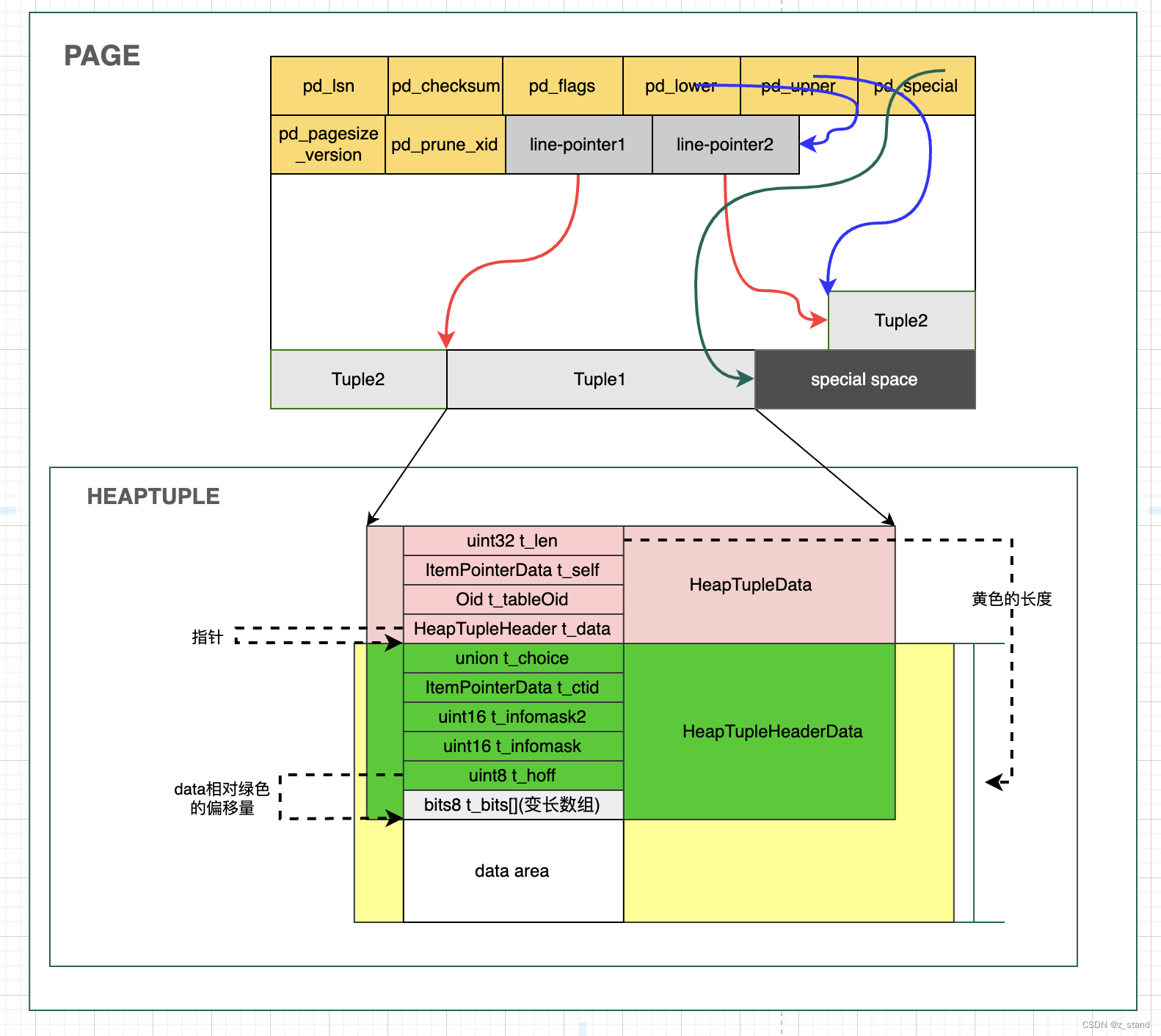
���� Page �Ĺؼ��ֶ�(header����)����:
pd_lsnһ��8byte�� unsigned int,�� pg�� WAL�ļ� xlog ���,Ψһ��ʶ��һ��д�뵽���page ������pd_checksum��ǰpage ��У���, uint16��pd_flags��ǰpage ��һЩflag��Ϣ,�����Ƿ��пյ�line pointer(���õ�Ԫ��ռ�),���ڲ���ÿһ��Ԫ���Ƿ����ɼ���,uint16��pd_lower��ʶ��ǰpage ���пռ����ʼƫ��λ�á�pd_upper��ʶ��ǰpage ���пռ�Ľ���ƫ��λ�á�pd_special����ռ�� ��ʼƫ��λ��,��һ�����������page�����һ��(����ͼ)��pd_pagesize_version��ʶpage��С�͵�ǰpage�汾��Ϣ��pd_prune_xid��ʶ��ҳ����Ի��յ� ���ϵ�Ԫ�� id.pd_linp����ͼ�е� line-pointer,�ɱ䳤�ȵ�����,��Ԫ��һһ��Ӧ,�����洢ÿһ��Ԫ���ڵ�ǰpage�ڲ�����ʼƫ�Ƶ�ַ��
���Կ�������pageheader ����ô����ֶξ���Ϊ�˹������ڲ���Ԫ�������ġ�
����ͨ�� SELECT * FROM page_header(get_raw_page('b', 0)); ������鿴 ���ŶԱ� b �����ݲ���,����page header�ı仯�����
�������tuple2,���� pd_lower �Լ� pd_upper ��ƫ�Ƶ�ַ,�� pd_lowerָ�� Ϊ tuple2 ������line-pointer ֮���λ��, �� pd_upper ָ��tuple2����ʼλ��(tuple2 �ǽ�����tuple1���з��õ�),ͬʱ����һ�¶�Ӧ��pd_lsn ��ָ�ꡣ
Page �ڲ��� heaptuple ��Ҫ��Ϊ��������:���� t_data ֮��� HeapTupleData,t_data Ҳ���� HeapTupleHeaderData,����һ���־��� ʵ�ʵ�data area��
-
HeapTupleData��Ҫ�ֶΰ���:len����tuple header-data + data-area �ij���;t_self��ʶ��ǰ tuple ������ page λ��(page��block-number �Լ� page�ڵ�offset),tableOid��ǰtuple �����ı� ��Ψһ��ʶ�� -
HeapTupleHeader t_data,������ݽṹ��Ҫ��������tuple�� header �ؼ���Ϣ�����ڲ����ֶ��� pg Ҫ��ʵ�ֵ���������ǿ���,��pg �ڲ�һ��Ԫ��Ŀɼ��Լ�� �Լ� MVCC ����ͨ��HeapTupleHeader�ڲ����ֶ�ʵ�ֵ�(���Ǻ�����Դ������������ϸ����),��Ҫ�ֶ�����:
a.union t_choice,�ڲ���Ҫ��t_heap����t_datum�����ֶΡ�t_heap����Ҫ�� �����ʶ�ֶ�,t_xmin��ʶ����Ԫ��ʱ������id;t_xmax��ʶ�Ե�ǰԪ����и���/ɾ�� ʱ������id, ���t_xmax������Ϊ0,���ʶû����������Ը�Ԫ�ؽ��� ���º�ɾ��;t_cid��ʶcommid id,��ֵ�ĺ����DZ�ʶ��ǰ����֮ǰ�ж��ٸ�sql ����;t_xvac��ʶִ�� vaccum full ������id��
b.t_ctidΨһ��ʶһ��Ԫ��,�����ǰԪ�鱻���»���ɾ��,��t_ctid ��ᱻ����Ϊ���µ�Ԫ�ص�t_ctid; ���� :# ��һ��Ԫ�� testdb=# SELECT lp,lp_off, t_xmin, t_ctid, t_attrs FROM heap_page_item_attrs(get_raw_page('c', 0), 'c'); lp | lp_off | t_xmin | t_ctid | t_attrs ----+--------+--------+--------+------------------------------- 1 | 8160 | 506 | (0,1) | {"\\x57040000","\\xae080000"} # ����,�ٴβ鿴t_ctid testdb=# update c SET l1 = 2; UPDATE 1 testdb=# SELECT lp,lp_off, t_xmin, t_ctid, t_attrs FROM heap_page_item_attrs(get_raw_page('c', 0), 'c'); lp | lp_off | t_xmin | t_ctid | t_attrs ----+--------+--------+--------+------------------------------- 1 | 8160 | 506 | (0,2) | {"\\x57040000","\\xae080000"} 2 | 8128 | 595 | (0,2) | {"\\x02000000","\\xae080000"} (2 rows)���Ժ����Եÿ��� ����Ԫ��� t_ctid ���ı�,��һ��Ԫ���t_ctid�����Ϊָ�����ʱ�������µ�Ԫ�顣
c.t_infomask2��ʶ��ǰԪ���ж��ٸ� attributes,���ж����С�ͬʱ,��ֵ��������һЩԪ�����͵� flags(Ԫ�鱻����?Ԫ������ʱ hot-updated / only-tuple ��)��
d.t_infomask�洢��Ԫ�������flag��Ϣ,���� ��ǰԪ���Ƿ��п���, �Ƿ��б䳤����,object-id ���Ƿ�Ϊ�յȡ�
e.t_hoff��ʶ����header + �����bitmap��ռ��ƫ��,�����ϲ�����t_hoff ����ʵ�ʵ�data_area ���ݡ�
f.t_bits,��һ���䳤�� bitmap����,������ʶ��ǰԪ��ijһ���Ƿ�Ϊ��,���統ǰԪ���ܹ�������,��t_bits ����Ϊ1111,���������Ϊ��,��t_bits ���ݱ��Ϊ1101;postgresql ������Ԫ���ڲ������еĸ���ΪMaxTupleAttributeNumber1664��,�������û�������������ΪMaxHeapAttributeNumber1600 ��,��Ԫ������������������в����ԭ����Ԫ���ڻ���Ϊ�û���ijһ���ɾ�����¶�����t_ctid ���� t_xmax ������������ -
data_arealen - header�� ʣ��Ȳ��ֶ����Ա�תΪ Ԫ�����������,Ҳ��������ͨ��SELECT lp,lp_off, t_xmin, t_ctid, t_attrs FROM heap_page_item_attrs(get_raw_page('c', 0), 'c');������ t_attrs ���֡�
�ж���������,�� t_attrs�о��ж���������,ÿһ������ �Ǵ���һ���е���ֵ,������16���Ʊ�ʾ������:x57040000��Ҫ����16λ���ں��������ɱ�ʾ,������ֵ��16������0x0000 0457��
����Ԫ�����ﻹ���зdz�����ֶ�,���д��������Ϊ�� pg ������ʵ�� ����Ƶġ�
�ܿ��� PG �ڲ���Ԫ�� update �� append ��ʽ��,������Ҫ����һ���µ�Ԫ��,��������Ҫ�����Ԫ��ľɰ汾�е�ijһЩ�ֶν��и���(t_xmax),������Ԫ�����ݲ����ڴ���,��������ֶ�Ҳ����ζ����Ҫ���ɵ�Ԫ����������и���,��������½�ΪƵ��Ҳ����ζ��������µ����ܲ�����ܺá�
��Ȼ,��������inplace-update�ĸ��·�ʽ,�Զ�������Ȼ���Ѻ�;����lsm-tree �Ĵ�append-only��ʽ�ĸ��³�����������������append д���������, ����û�и���ʱ������ʧ�����(���������update ��Ҫ��֮ǰ�汾�����Ͻ��и���,ʹ�� merge-operator,���ܱ�֤���±��������ܵ������ ������ ��������,��Ϊʵ�ʵ���ֵ�ϲ���������compaction ���� ����)
Heap ���Ķ�д��
�
heap����д�벢���ǽ�Ԫ�鹹��ò��뵽page֮��ֱ������,���ǽ�����Ԫ���page���Ϊ dirty,��ר�ŵ� checkpointer ���̽��� ������ buffer �� ˢ��,Ҳ�������ݲ���ʵʱ���̡�����һ���ԡ��ɿ��� ����,���ǻ�ͨ�� postgresql �� WAL���ϡ�
heapԪ��IJ���ջ����,�ϴ�ִ�е���INSERT ���:
main
PostmasterMain
ServerLoop
BackendStartup
BackendRun
PostgresMain
exec_simple_query # �ʷ�����/�����/�Ż���
PortalRun # �Ѿ�����ִ�мƻ�,��ʼִ��
PortalRunMulti
ProcessQuery # ִ�� DML
standard_ExecutorRun
ExecutePlan # ִ����
ExecProcNode # ѡ��ִ�к���
ExecModifyTable
ExecInsert
table_tuple_insert # ͨ�� default_table_access_methodѡ��ִ�к���
heapam_tuple_insert # ѡ���� heap access method.
heap_insert # ����Ԫ��
�� heapam_tuple_insert �л��ȴ� HeapTupleSlot ���õ�ʵ�ʵ�Ԫ������,������һ�� HeapTuple ����,������� HeapTuple ����û��header��Ϣ,���� ��� HeapTuple������������ heap_insert�С�
����������Ҫ��ע���� heap_insert ��θ���Ԫ�� �Լ� ��һ��Ԫ����뵽 ���ļ���page �С�
�����ڲ��� �����Ϊ���¼���:
- ��ʼ��Ԫ��ͷ
- �� Relation cache �л�ȡһ�� ���õ�page block-number
- �������ϵij�ͻ���(rw/ww)
- ��Ԫ����Ϣ���ӵ���� page��
- ��� page Ϊdirty
- д WAL
- ��� relation-cache �оɵ� tuple ���ڵ�buffer ʧЧ
��һ�� ��ʼ��Ԫ��ͷ
�ں��� heap_prepare_insert ֮��:
static HeapTuple
heap_prepare_insert(Relation relation, HeapTuple tup, TransactionId xid,
CommandId cid, int options)
{
...
tup->t_data->t_infomask &= ~(HEAP_XACT_MASK);
tup->t_data->t_infomask2 &= ~(HEAP2_XACT_MASK);
tup->t_data->t_infomask |= HEAP_XMAX_INVALID;
// xid �ǵ�ǰ����Ԫ��� transaction id,�����Ǹ��µ�������ǰ��˵�� t_xmin֮�С�
HeapTupleHeaderSetXmin(tup->t_data, xid);
// ���� t_cid,�� commid-id,������ʶ��ǰ�������֮ǰ�ж��ٸ� command.
HeapTupleHeaderSetCmin(tup->t_data, cid);
// ���� t_xmax,�� �Ե�ǰԪ�鷢��update ���� delete ������id,Ĭ����0.
HeapTupleHeaderSetXmax(tup->t_data, 0); /* for cleanliness */
// ���� t_tableOid Ϊ �� oid.
tup->t_tableOid = RelationGetRelid(relation);
...
// �����Ǵ������� �ϴ�Ԫ��ĵ����,����һ��Ԫ���ڲ�������������֮ǰ˵���������1664��,
// ���������ͨ�� toast ���ƽ��д�����
}
�ڶ��� ��ȡһ�� ���õ�page blk-num
�ڶ���,��relation cache �л�ȡһ�����õ� page,���ص������page��Ӧ��block number.
��һ�� pg ���ȸ��� heap-size ����һ��ʹ�õ� page����check,������һ�ε�page ʣ��ռ����㹻��ŵ�ǰ heaptuple ��, ��ֱ�ӽ���� page ��Ӧ��block-number ���ء�
�������,����Ҫ�� free-list-manager �в��ҿ��п��õ�page,Ҳ���Ƕ�ȡ �ʼ�������ݿ�Ŀ¼ʱ�ᵽ�� _fsm �ļ�,��� FSM Ҳû���㹻��page,��ͨ�� relation������ smgr �C storage manager �Ӵ����ļ�ϵͳ��ȡһ���ļ��ռ䡣
������õ��� ���õ� block-number ���ؼ��ɡ�
Buffer
RelationGetBufferForTuple(Relation relation, Size len,
Buffer otherBuffer, int options,
BulkInsertState bistate,
Buffer *vmbuffer, Buffer *vmbuffer_other)
{
...
// ǰ����������� ������һЩhup-size�ļ��,heapsize ���С�� MaxHeapTupleSize,
// ��ʾһ�����Է��䵽һ�����õ� page.
if (targetBlock == InvalidBlockNumber && use_fsm)
{
// ��ȡ���е�block number
// 1. �ȳ��Դ� FSM �л�ȡ,��ȡ����
// 2. �ٳ��� ���� smgr �Ӵ����ļ�ϵͳ�Ϸ���,���䲻��
// ��˵�����̿ռ䲻��,ֱ�ӷ��� -1��
targetBlock = GetPageWithFreeSpace(relation, len + saveFreeSpace);
...
}
loop:
// 1. �� targetBlock ��Ӧ��page �����ڴ���
// 2. ��һЩ buffer �Ŀɼ��Լ��
// 3. û������,���ȡ�� �ڴ��е�page,�����Ϊdirty
(�µ�page,������Ҫ����checkpointˢ��)
// 4. ���� block-number (������ʱbuffer)
while (targetBlock != InvalidBlockNumber)
{
...
/* lock other buffer first */
buffer = ReadBuffer(relation, targetBlock);
if (PageIsAllVisible(BufferGetPage(buffer)))
visibilitymap_pin(relation, targetBlock, vmbuffer);
LockBuffer(otherBuffer, BUFFER_LOCK_EXCLUSIVE);
LockBuffer(buffer, BUFFER_LOCK_EXCLUSIVE);
...
// ��ȡ page,������µ�,�������page Ϊdirty.
page = BufferGetPage(buffer);
if (PageIsNew(page))
{
PageInit(page, BufferGetPageSize(buffer), 0);
MarkBufferDirty(buffer);
}
// �ٴμ����� page ���ÿռ��㹻,�㹻��ֱ�ӷ���buffer.
pageFreeSpace = PageGetHeapFreeSpace(page);
if (len + saveFreeSpace <= pageFreeSpace)
{
/* use this page as future insert target, too */
RelationSetTargetBlock(relation, targetBlock);
return buffer;
}
...
}
...
}
������ ��ͻ���
�������ǽ��г�ͻ���,ֱ�ӵ��ú��� CheckForSerializableConflictIn(���ֵ������ WAL ���Ƶ�������һƪ,��������ʱ������չ��)��
���IJ� Ԫ��д�뵽page
�������͵����IJ���,�� Ԫ���������ӵ���ȡ����page ��,���ú��� RelationPutHeapTuple��
- ���� PageAddItem,��tuple �� t_data ���ݲ��� ���뵽page��,����page header��Ϣ,������ tuple ����page�� offnum.
- ��offnum �� buffer ���µ� tuple �� t_self�С��������ܹ���tuple ��ȷ�ϸ�tuple ���ڵ� block-number �Լ� pageƫ�Ƶ�ַ�ˡ�
void
RelationPutHeapTuple(Relation relation,
Buffer buffer,
HeapTuple tuple,
bool token)
{
...
// �õ������л�ȡ�� buffer ,Ҳ���� block-number,�õ���Ӧ��page.
/* Add the tuple to the page */
pageHeader = BufferGetPage(buffer);
// �ں� PageAddItem ���� PageAddItemExtended ���� �� tup �� data�������ӵ�page�С�
// ���� PageAddItemExtended ������,����� page�� header ��Ϣ:
// ���� pd_lower, pd_upper, line-pointer Ҳ���� pd_linp ��
// ���������һЩ��Ϣ֮��Ὣ tuple ����� t_data ��Ϣ memcpy ��page�С�
offnum = PageAddItem(pageHeader, (Item) tuple->t_data,
tuple->t_len, InvalidOffsetNumber, false, true);
...
// ��offnum �� buffer ���µ� tuple �� t_self��.
ItemPointerSet(&(tuple->t_self), BufferGetBlockNumber(buffer), offnum);
...
���岽 ���page Ϊdirty �Լ� checkpointer �����첽ˢ��ҳ
���岽 ����һ�� page �ı��,ǰ��ڶ���ʱ ��һ�����õ�page block-number �����л�Ϊһ���µ� page����ditry ���;�����update����,���߸������е�page,��ڶ��������diry������,�����Ǹ�������� tuple �����page,����Ҫ ͨ�� MarkBufferDirty(buffer); �Ը�page д�� dirty��ǡ�
��Ҫע����� ������,���� heap ���ļ���Ԫ�������Ѿ������,������ WAL д�� �Լ� invalid relation cache ������ѱ��ļ������ص�,��Ԫ������page ��ʵ��д����ͨ������� checkpoint ���̽���д��ġ�
���������һ���ܼIJ���,�Ȳ鿴�������ݵı��ļ�,����
pg_relation_filepath������ȷ�ϵ�ǰ����Ӧ�ľ����heap�ļ�,����ʹ�� ���Բο�ǰ�� �������ݿ�Ŀ¼������ֱ�� vim ����ļ�,�鿴����ʮ������, һ��ģʽ��:%!xxd,������ܿ���ʵ�ʵ�����:
������֮ǰ�����Ԫ��,ÿһ��Ԫ�������� attribute,�������ܿ����ܶ��Ԫ��,��һЩ��update������,��Ҫ�� vacuum ���̽��д�����
checkpointer ���� ��PG �ڶ��ӽ����е�һ��,���� ���ڴ��л�������ݽ�������,���� CLOG(����״������), ������,Relation map, snapshot , buffer pool ��ҳ(��̭ҳ)�ȡ�
checkpointer �ӽ������� postgresql ����ʱ��PostmasterMain ��ʼ�����ӽ��̡�
�����ջ����:
CheckpointerMain
CreateCheckPoint
CheckPointGuts
CheckPointBuffers
�ں��� CheckPointBuffers ��,����ͨ�� BufferSync �� buffer �е�����ͳһͨ�� posix write д�뵽����;��ͨ��ProcessSyncRequests �� bufferд���page ������·������ fsync��
������ �WAL
������ дWAL,����û��� postgresql.conf �ļ��������� wal_level=0, ���ر� WAL ���ܡ�ͬ��,��Ϊ wal ��Դ���� �� ��������ϵ�������,���Ա�ƪҲ��ʱ����������
���� ������ heap_insert֮��
/* XLOG stuff */
if (!(options & HEAP_INSERT_SKIP_WAL) && RelationNeedsWAL(relation))
{
...
}
Ӧ����9ϵ�汾����ǰ,PG��WAL ����ͬ�����̵�,����Ϊ�˷���IO����,�ָ���һ��wal-writer �ӽ���,����������д WAL������
���߲� Invalid relation-cache
�������ڶ�Ԫ����µij�����, ������Ԫ�����ڵ�page ������ relation-cache ֮��, ����Ҫ����relation-cache �����pageʧЧ,��Ϊ�����Ѿ������˱����
���� relation-cache �� catalog(ϵͳ��)��������ϸ����,����Ҳ��ӵ�зdz����ϸ�ڡ�
invalid �Ĵ�����:
void
CacheInvalidateHeapTuple(Relation relation,
HeapTuple tuple,
HeapTuple newtuple)
{
...
}
����,����heap_insert ������ִ�����ˡ�
���Կ��� PG Ϊ�˽�IO ���Ⱥ��ں�����������,����˺ܶ��ӽ��̽����첽IO����(���е�IO ���ȶ���ͨ�� smgr �洢����������),�������� PG �ں˴����ά���� �Լ� ������˵������Ϊ����ġ�
�ص����ǵ� �ѱ��ļ��е� page����,���� INSERT ������·�ϲ�����ֱ������,���Dz��뵽 �ڴ��ж�Ӧ�� pg page������,�� page ��һ�����,����ͨ�� checkpointer ���� ��ҳ���첽����(����fsync)��
��Ϊ���ǽ�����ʱ��û���ڱ����洴������,���Բ���Ԫ���ʱ�����������IJ��롣������Ǵ���������,����
ExecInsert-->table_tuple_insert�� ���� heap ��дpage���֮����Ҫִ��ExecInsertIndexTuples()���������IJ��롣
PostgreSQL find a kernel��s ��Fsync Bug��
�������һ�� pg ������Ϊ��һ�� �ں� fsync �� bug,������ۺ���Ȥ:
��2018���ʱ�� pg ����������һ�� ��os-�ں� fsync ��bug��,��ʱ�� os-kernel����, PG���� �Լ� ������ϵ�����ݿ��������ķз�����:)��
������ os-�ں˱����ڴ��� DRAM page���̵�ʱ��Ĭ����ͨ�� write-back ����,write-back��pd-flush �ں��߳�ˢ �ڴ���ҳʧ����(����osӲ������,�ڴ���ҳ�Ĵ洢��ʵ�� pg ��˵ �� checkpoint ˢ buffers �ĵ�һ����,ֻ�ǽ�buffers ���� д�뵽os�� page-cache��,�����Ż����fsycn),��ʱ�ں˶���������ҳ�Ĵ����������㡱(pg�����Ŀ�������������Ϊ��),Ȼ�� pg �� checkpointer ˢ buffers �ĵڶ����λ���� fsync,���ʱ����Ϊ�ں˱��� write-back ˢ�ڴ��ijһ����ҳ��ʧ�ܵ�,���ʱ�� fsync Ҳ�ᴦ��ʧ��,���Ƕ���PG��˵,�ڷ��� fsync ʧ�ܵ�ʱ������ fsync ʧ�ܵĴ������������,fsync��ʧ�ܷ��صĴ������ں�ȷʵû�������� write-back ʧ�ܵ���һЩ��ҳ,���� pg ���� fsync��ʱ�� �ں˷��سɹ��ˡ�
���ʱ�����������,��Ϊʧ�ܵ���һЩ��ҳ��һ������,��PG��˵,������Ϊ������ fsync �ɹ� ֮�����е����ݶ�һ�����ڴ�����,Ȼ����ʵ�� ��һЩ��ҳ���ݻ����ڴ���,����os �ϵ�ʲô��,��һЩ���ݾͶ���,Υ���� PG ��fsync ����������,���ڶ����ݵ����(�ȶ�������,��Ϊ����)��
����PG���� ��Ϊ �ں�Ӧ��Ϊ fsync ��һ���������ֳ����µ����⸺��,Ȼ���ں�������Ϊ��������fsync ���ѱ���,��Ϊ�к�̨write-back�߳���ִ�еĹ����� sync Ҳ�п���ʧ��,����PG �� checkpointer ���̵� smgr ��û�б������еĴ����ļ�fd(pg Ϊ�˱��� ���̴�fd �����ﵽ�ں�����,����ֻ�Ỻ��һ����fd���ڴ���Ż�),������Ҫ��ʱ���ȥ���´�fd,Ҳ����fsync ��ʱ�������Ҫ���´�һ�����ļ�,�ڴ�֮ǰ����Ҳ�ᷢ��һЩ os �� write-back ����,��������4.13 �����µ��ں˰汾 ���ᱨ��,�Ǵ��ļ�֮�����fsync ���ܻ�ɹ�,���ֳ����¸��ǻᶪ����,�ں˿�������Ϊ PG ������checkpoint ˢ��ҳ�Ļ���(д���ڴ�, ���´��ļ�fd ,����fsync )�����ͻ���� ����fsyncʱǰ�淢����ʧ��,���²����ڴ���ҳδ���̵������
�ں��������� PG �����������������õĽ���취���� ʹ�� DIO(direct io),Ҳ���� checkpointer ���̵�ʱ��Ҫ��дpage-cache������fsync��,ֱ�ӵ��� DIO����,���� DIO ��ζ������ os ��page-cache�ò���,���Ҷ� PG�� д��· ����˵�Ƿdz���(����������bug,����ɱ�̫����)��
����,���� PG�� commit ����fsync ʧ��֮�� ����panic(������ innodb �� wiredtiger Ҳ������ͬ���ĸ���),�ں�����Ҳ����һЩ����,������Ҫ���µ��ں˰汾�ϲ�����(DIO ��linux Ϊ���ݿ�Ӧ��ר�ſ�����һ�� io ����,��,���ں���˵ʡ�� ,������Ӧ����˵�ȶ��������������,���ݿ�����ľ��Ѿ����뵽���ں���,��Ϊ��Ҷ���Ҫ�õ�����,dio ������ʵ�����ô��û��̫��ľ�����;��Ȼ,���ѡ����ά�� page-cache Ҳ�ܴﵽЧ��,���Ƕ��� IO ��·�ĸ���û�о���������ʱ��ɱ���Ͷ��,���������������ں��������ȶ��Ժ�����;Ϊ��ӭ���û������ܵ����� �Լ� �����������ݿ�,��һ��Ƕ�Ĭ��ѡ���� buffer i/o)��
˵���е��,�����滹�ǻ���ϸ������� PG ���ֵ�bug,�����ܲ��ܸ��֡���Ҫ����,PG �����ļ��� PMC ��������� bug��ʱ�� �ᵽ kernel brain damage �Լ� 100% unreasonable,�� torvalds �Ը�����Ҫ���ֿ��ˡ� ���� torvalds û�в�������,��Ȼ���Գ�һ����ϡ�
�����ϸ�ڿ���ȥ����ֱ�ӿ�:
- �ʼ���������:The ��fsyncgate 2018�� mailing list thread
- �ں������� fsync bug ������ : LWN.net article ��PostgreSQL��s fsync() surprise��
- �ں�������һ�� block-layer �Ĵ��������� : LWN.net article ��Improved block-layer error handling��
- ����fsync �Ƿ�ȫ�� һƪ�о����� : Can Applications Recover from fsync Failures
��ȡ
��ȡ��· �� SELECT ��俪ʼ,���ȵ�ջ����:
main
PostmasterMain
ServerLoop
BackendStartup
BackendRun
PostgresMain
exec_simple_query # �ʷ�����/�����/�Ż���
PortalRun # �Ѿ�����ִ�мƻ�,��ʼִ��
PortalRunSelect # ִ�мƻ��� ��ѯ,����� insert��ִ�мƻ��Dz�һ����
standard_ExecutorRun
ExecutePlan
ExecProcNode
ExecScan
ExecScanFetch
SeqNext
table_scan_getnextslot
heap_getnextslot
���������� heap_getnextslot ������,�ú����ڲ�����Ϊ������:
- �Ӵ����϶�ȡ��Ӧ�� tuple ���ڵ�page ���ݵ��ڴ��С�
- ����ȡ������tuple ��䵽 ���Ա��û���ȡ����
TupleTableSlot���ݽṹ�С�
��һ�������� ���µĵ���ջ��,���ջ�ͨ�� ReadBuffer_common ����ʵ�ʵ� read io,�� ͨ�� PG smgr �洢���������д��̶�ȡ��
heap_getnextslot
heapgettup_pagemode
heapgetpage
ReadBufferExtended
ReadBuffer_common
�������� page ���� �� heapgetpage �����н��пɼ��Լ��,��һ������һЩ���� PG �ṩ�ĸ��뼶��Ĺ��������õĿɼ���,�ܹ���Ϊ��Ч�ö�һ��Ԫ��/Page �Ŀɼ��Խ����ж� ,�ж�����Ҫ������ HeapTupleSatisfiesVisibility �����С�
�ڵڶ�������,��Ҫ��һЩ���ݽṹ��Ա�ϵ����,ͨ������ ExecStoreBufferHeapTuple ����,��tuple Ԫ�� �Լ� tuple Ԫ�����ڵ� page ���뵽 TupleTableSlot ֮��,���ϲ�������ݽ������ظ��ͻ��ˡ�
����·��Ϊ workload �Ƚϵ�һ,�����˵�ܶ�,������ ��δӴ��̶�ȡ page �Լ� ��ζԶ������� page ����Ԥ�úõ� pg ����ɼ��Թ�����пɼ��Լ�� �������֡�
�ܽ�
��Ϊ��ƪ����Ҳֻ�ǵ�����ע PG �Ĵ洢���沿��,����PG ������ �Լ� ���ܱ߰���� wal-writer, �ɼ��Լ��,vacuum, checkpointer �Ȼ���û������,��Ϊ ����PG ��Ϊ �����д��뼶��Ĺ�ϵ�����ݿ�,��ÿһ��С����/��� ��ʵ�ֶ��зdz����ϸ��,����Ҫ��������ѧϰ��
��heap �������������, pg ��Ӧ���� �� io ���ȷָ,PG ������ֻ��Ҫרע��DML ������CPU ������,�� IO ���潻��ר�ŵĺ�̨����,�����ܸ�Ϊ�Ѻá�
��ΪIO ���ȶ����߳���˵���ڷ���,�� ������ PG �ļܹ���ź,����PG ����˶���̵�Ӧ�õ��ȼܹ�,ÿһ�� I/O �����ҹ��ܼ��е� �������ר�ŵ��ӽ��̽��е���,��Դ�����ʸ���,����չ�Ը�ǿ��
��Ȼ,���� DML �����˵,��������Ӱ�������� WAL д�������,�Ͼ� heaptuple ��д��Ҳ������д�ڴ���ѡ�WAL ��д��ҵ���Ҷ�û�в�̫��,���� group commit����̬,PG ���õ���Ԥ�ȷ����ÿһ�������ύ����� LSN, �����ò�ͬ�� �������ύд WAL��ʱ��дͬһ�����ļ��IJ�ͬ position��