1ЁЂЬиЕу:
flumeЪЧвЛИіЗжВМЪНЁЂПЩППЁЂКЭИпПЩгУЕФКЃСПШежОВЩМЏЁЂОлКЯКЭДЋЪфЕФЯЕЭГЁЃжЇГждкШежОЯЕЭГжаЖЈжЦИїРрЪ§ОнЗЂЫЭЗН,гУгкЪеМЏЪ§Он;ЭЌЪБ,FlumeЬсЙЉЖдЪ§ОнНјааМђЕЅДІРэ,ВЂаДЕНИїжжЪ§ОнНгЪмЗН(БШШчЮФБОЁЂHDFSЁЂHbaseЕШ)ЕФФмСІ
2ЁЂFlumeЕФПЩППад:
ЕБНкЕуГіЯжЙЪеЯЪБ,ШежОФмЙЛБЛДЋЫЭЕНЦфЫћНкЕуЩЯЖјВЛЛсЖЊЪЇЁЃ
FlumeЬсЙЉСЫШ§жжМЖБ№ЕФПЩППадБЃеЯ:
- end to end:ЪеЕНЪ§ОнagentЪзЯШНЋeventаДЕНДХХЬЩЯ,ЕБЪ§ОнДЋЫЭГЩЙІКѓ,дйЩОГ§;ШчЙћЪ§ОнЗЂЫЭЪЇАм,ПЩвджиаТЗЂЫЭЁЃ
- Store on failure:етвВЪЧscribeВЩгУЕФВпТд,ЕБЪ§ОнНгЪеЗНcrashЪБ,НЋЪ§ОнаДЕНБОЕи,Д§ЛжИДКѓ,МЬајЗЂЫЭ
- Besteffort:Ъ§ОнЗЂЫЭЕННгЪеЗНКѓ,ВЛЛсНјааШЗШЯ
3ЁЂFlumeЕФПЩЛжИДад:
ЪЙгУFileChannelФЃЪНдЫаа,ЛсНЋЪ§ОнВЩМЏЕФЪТМўГжОУЛЏдкБОЕиЮФМўЯЕЭГРя(адФмНЯВю)
4ЁЂFlumeЕФвЛаЉКЫаФИХФю:
| УћГЦ | ЫЕУї |
|---|---|
| Agent(ДњРэ) | ЪЙгУJVM дЫааFlumeЁЃУПЬЈЛњЦїдЫаавЛИіagent,ЕЋЪЧПЩвддквЛИіagentжаАќКЌЖрИіsourcesКЭsinksЁЃ |
| Client(ЮЏЭа) | ЩњВњЪ§Он,дЫаадквЛИіЖРСЂЕФЯпГЬЁЃ |
| Source(РДдД) | ДгClientЪеМЏЪ§Он,ДЋЕнИјChannelЁЃ |
| Sink(НгЪеЦї) | ДгChannelЪеМЏЪ§Он,дЫаадквЛИіЖРСЂЯпГЬЁЃ |
| Channel(ЭЈЕР) | СЌНг sources КЭ sinks ,РрЫЦвЛИіЖгСаЁЃ |
| Events(ЪТМў) | ПЩвдЪЧШежОМЧТМЁЂ avro ЖдЯѓЕШЁЃ |
5ЁЂВПЪ№РраЭ:
5.1 ЕЅвЛСїГЬ:
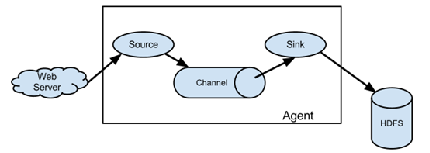
FlumeвдagentЮЊзюаЁЕФЖРСЂдЫааЕЅЮЛЁЃвЛИіagentОЭЪЧвЛИіJVMЁЃЕЅagentгЩSourceЁЂSinkКЭChannelШ§ДѓзщМўЙЙГЩЁЃ
5.2 ЖрДњРэСїГЬ:
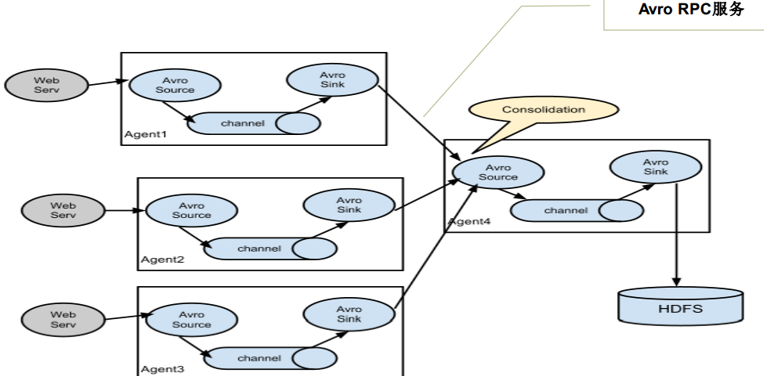
ПЩвдНЋЖрИіAgentЫГађСЌНгЦ№РД,НЋзюГѕЕФЪ§ОндДОЙ§ЪеМЏ,ДцДЂЕНзюжеЕФДцДЂЯЕЭГжаЁЃетЪЧзюМђЕЅЕФЧщПі,вЛАуЧщПіЯТ,гІИУПижЦетжжЫГађСЌНгЕФAgent
ЕФЪ§СП,вђЮЊЪ§ОнСїОЕФТЗОЖБфГЄСЫ,ШчЙћВЛПМТЧfailoverЕФЛА,ГіЯжЙЪеЯНЋгАЯьећИіFlowЩЯЕФAgentЪеМЏЗўЮёЁЃ

5.3 СїЕФКЯВЂ:
етжжЧщПігІгУЕФГЁОАБШНЯЖр,БШШчвЊЪеМЏWebЭјеОЕФгУЛЇааЮЊШежО, WebЭјеОЮЊСЫПЩгУадЪЙгУЕФИКдиМЏШКФЃЪН,УПИіНкЕуЖМВњЩњгУЛЇааЮЊШежО,ПЩвдЮЊУП
ИіНкЕуЖМХфжУвЛИіAgentРДЕЅЖРЪеМЏШежОЪ§Он,ШЛКѓЖрИіAgentНЋЪ§ОнзюжеЛуОлЕНвЛИігУРДДцДЂЪ§ОнДцДЂЯЕЭГ,ШчHDFSЩЯЁЃ
5.4 ЖрТЗИДгУСї:
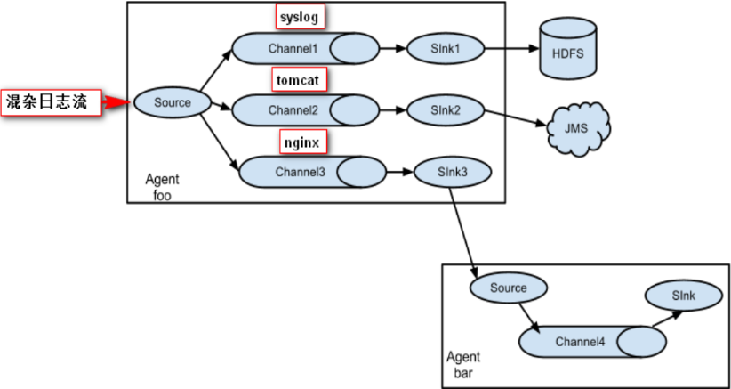
FlumeЛЙжЇГжЖрМЖСї,ЪВУДЖрМЖСї?РДОйИіР§зг,ЕБsyslog, java, nginxЁЂ tomcatЕШЛьКЯдквЛЦ№ЕФШежОСїПЊЪМСїШывЛИіagentКѓ,ПЩвдagentжаНЋЛьдгЕФШежОСїЗжПЊ,ШЛКѓИјУПжжШежОНЈСЂвЛИіздМКЕФДЋЪфЭЈЕРЁЃ
5.5 ИКдиЦНКт:
НЋChannelднДцЕФEventОљКтЕНЖдгІЕФЖрИіSinkзщМўЩЯ,ЖјУПИіSinkзщМўЗжБ№СЌНгЕНвЛИіЖРСЂЕФAgentЩЯЁЃ

6ЁЂFlumeзЅШЁШежОРраЭ
1. Avro SourceМрЬ§AvroЖЫПкНгЪеДгЭтВПAvroПЭЛЇЖЫЗЂЫЭРДЕФЪ§ОнСїЁЃШчЙћгыЩЯвЛВуAgentЕФ Avro Sink ХфКЯЪЙгУОЭзщГЩСЫвЛИіЗжВуЕФЭиЦЫНсЙЙ
| Ъєад | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channels | ЈC | гыSourceАѓЖЈЕФchannel,ЖрИігУПеИёЗжПЊ |
| type | ЈC | зщМўРраЭ,етИіЪЧ: avro |
| bind | ЈC | МрЬ§ЕФЗўЮёЦїУћhostnameЛђепip |
| port | ЈC | МрЬ§ЕФЖЫПк |
| threads | ЈC | ЩњГЩЕФзюДѓЙЄзїЯпГЬЪ§СП |
| selector.type | ПЩбЁжЕ:replicating Лђ multiplexing ,ЗжБ№БэЪО: ИДжЦЁЂЖрТЗИДгУ | |
| selector.* | channelбЁдёЦїЕФЯрЙиЪєад,ОпЬхЪєадИљОнЩшЖЈЕФ selector.type жЕВЛЭЌЖјВЛЭЌ | |
| interceptors | ЈC | ИУsourceЫљЪЙгУЕФРЙНиЦї,ЖрИігУПеИёЗжПЊ |
| interceptors.* | РЙНиЦїЕФЯрЙиЪєад | |
| compression-type | none | ПЩбЁжЕ: none Лђ deflate ЁЃетИіРраЭБиаыИњAvro SourceЯрЦЅХф |
| ssl | false | ЩшжУЮЊ true ПЩЦєгУSSLМгУм,ШчЙћЮЊtrueБиаыжИЖЈЯТУцЕФ keystore КЭ keystore-password ЁЃ |
| keystore | ЈC | SSLМгУмЪЙгУЕФJava keystoreЮФМўТЗОЖ |
| keystore-password | ЈC | Java keystoreЕФУмТы |
| keystore-type | JKS | Java keystoreЕФРраЭ. ПЩбЁжЕга JKS ЁЂ PKCS12 ЁЃ |
| exclude-protocols | SSLv3 | жИЖЈВЛжЇГжЕФавщ,ЖрИігУПеИёЗжПЊ,SSLv3ВЛЙмЪЧЗёХфжУЖМЛсБЛЧПжЦХХГ§ |
| ipFilter | false | ЩшжУЮЊtrueПЩЦєгУipЙ§ТЫ(nettyЗНЪНЕФavro) |
| ipFilterRules | ЈC | netty ipFilterЕФХфжУ(ВЮПМЯТУцЕФipFilterRulesЯъЯИНщЩмКЭР§зг) |
ХфжУЗЖР§:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
2. Spool:SpoolМрВтХфжУЕФФПТМЯТаТдіЕФЮФМў,ВЂНЋЮФМўжаЕФЪ§ОнЖСШЁГіРД
етИіSourceдЪаэФуАбвЊЪеМЏЕФЮФМўЗХШыДХХЬЩЯЕФФГИіжИЖЈФПТМЁЃЫќЛсНЋМрЪгетИіФПТМжаВњЩњЕФаТЮФМў,ВЂдкаТЮФМўГіЯжЪБДгаТЮФМўжаНтЮіЪ§ОнГіРДЁЃЪ§ОнНтЮіТпМЪЧПЩХфжУЕФЁЃдкаТЮФМўБЛЭъШЋЖСШыChannelжЎКѓЛсжиУќУћИУЮФМўвдЪОЭъГЩ(вВПЩвдХфжУГЩЖСЭъКѓСЂМДЩОГ§)ЁЃ
гыExec SourceВЛЭЌ,Spooling Directory SourceЪЧПЩППЕФ,МДЪЙFlumeжиаТЦєЖЏЛђБЛkill,вВВЛЛсЖЊЪЇЪ§ОнЁЃЭЌЪБзїЮЊетжжПЩППадЕФДњМл,жИЖЈФПТМжаЕФЮФМўБиаыЪЧВЛПЩБфЕФЁЂЮЈвЛУќУћЕФЁЃFlumeЛсздЖЏМьВтБмУтетжжЧщПіЗЂЩњ,ШчЙћЗЂЯжЮЪЬт,дђЛсХзГівьГЃ:
- ШчЙћЮФМўдкаДШыЭъГЩКѓгжБЛдйДЮаДШыаТФкШн,FlumeНЋЯђЦфШежОЮФМў(етЪЧжИFlumeздМКlogsФПТМЯТЕФШежОЮФМў)ДђгЁДэЮѓВЂЭЃжЙДІРэЁЃ
- ШчЙћдквдКѓжиаТЪЙгУвдЧАЕФЮФМўУћ,FlumeНЋЯђЦфШежОЮФМўДђгЁДэЮѓВЂЭЃжЙДІРэЁЃ
ЮЊСЫБмУтЩЯЪіЮЪЬт,ЩњГЩаТЮФМўЕФЪБКђЮФМўУћМгЩЯЪБМфДСЪЧИіВЛДэЕФАьЗЈЁЃ
| ЪєадУћ | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channels | ЈC | гыSourceАѓЖЈЕФchannel,ЖрИігУПеИёЗжПЊ |
| type | ЈC | зщМўРраЭ,етИіЪЧ: spooldir. |
| spoolDir | ЈC | Flume SourceМрПиЕФЮФМўМаФПТМ,ИУФПТМЯТЕФЮФМўЛсБЛFlumeЪеМЏ |
| fileSuffix | .COMPLETED | БЛFlumeЪеМЏЭъГЩЕФЮФМўБЛжиУќУћЕФКѓзКЁЃ1.txtБЛFlumeЪеМЏЭъГЩКѓЛсжиУќУћЮЊ1.txt.COMPLETED |
| deletePolicy | never | ЪЧЗёЩОГ§вбЭъГЩЪеМЏЕФЮФМў,ПЩбЁжЕ: never Лђ immediate |
| fileHeader | false | ЪЧЗёЬэМгЮФМўЕФОјЖдТЗОЖУћ(ОјЖдТЗОЖ+ЮФМўУћ)ЕНheaderжаЁЃ |
| fileHeaderKey | file | ЬэМгОјЖдТЗОЖУћЕНheaderРяУцЫљЪЙгУЕФkey(ХфКЯЩЯУцЕФfileHeaderвЛЦ№ЪЙгУ) |
| basenameHeader | false | ЪЧЗёЬэМгЮФМўУћ(жЛЪЧЮФМўУћ,ВЛАќРЈТЗОЖ)ЕНheader жа |
| basenameHeaderKey | basename | ЬэМгЮФМўУћЕНheaderРяУцЫљЪЙгУЕФkey(ХфКЯЩЯУцЕФbasenameHeaderвЛЦ№ЪЙгУ) |
| includePattern | ^.*$ | жИЖЈЛсБЛЪеМЏЕФЮФМўУће§дђБэДяЪН,ЫќИњЯТУцЕФignorePatternВЛГхЭЛ,ПЩвдвЛЦ№ЪЙгУЁЃШчЙћвЛИіЮФМўУћЭЌЪББЛетСНИіе§дђЦЅХфЕН,дђЛсБЛКіТд,ЛЛОфЛАЫЕignorePatternЕФгХЯШМЖИќИп |
| ignorePattern | ^$ | жИЖЈвЊКіТдЕФЮФМўУћГЦе§дђБэДяЪНЁЃЫќПЩвдИњ includePattern вЛЦ№ЪЙгУ,ШчЙћвЛИіЮФМўБЛ ignorePattern КЭ includePattern СНИіе§дђЖМЦЅХфЕН,етИіЮФМўЛсБЛКіТдЁЃ |
| trackerDir | .flumespool | гУгкДцДЂгыЮФМўДІРэЯрЙиЕФдЊЪ§ОнЕФФПТМЁЃШчЙћХфжУЕФЪЧЯрЖдФПТМЕижЗ,ЫќЛсдкspoolDirжаПЊЪМДДНЈ |
| consumeOrder | oldest | ЩшЖЈЪеМЏФПТМФкЮФМўЕФЫГађЁЃФЌШЯЪЧЁАЯШРДЯШзпЁБ(вВОЭЪЧзюдчЩњГЩЕФЮФМўзюЯШБЛЪеМЏ),ПЩбЁжЕга: oldest ЁЂ youngest КЭ random ЁЃЕБЪЙгУoldestКЭyoungestетСНжжбЁЯюЕФЪБКђ,FlumeЛсЩЈУшећИіЮФМўМаНјааЖдБШХХађ,ЕБЮФМўМаРяУцгаДѓСПЕФЮФМўЕФЪБКђПЩФмЛсдЫааЛКТ§ЁЃ ЕБЪЙгУrandomЪБКђ,ШчЙћвЛжБдкВњЩњаТЕФЮФМў,гавЛВПЗжРЯЮФМўПЩФмЛсКмОУВХЛсБЛЪеМЏ |
| pollDelay | 500 | FlumeМрЪгФПТМФкаТЮФМўВњЩњЕФЪБМфМфИє,ЕЅЮЛ:КСУы |
| recursiveDirectorySearch | false | ЪЧЗёЪеМЏзгФПТМЯТЕФШежОЮФМў |
| maxBackoff | 4000 | ЕШД§аДШыchannelЕФзюГЄЭЫБмЪБМф,ШчЙћchannelвбТњЪЕР§ЦєЖЏЪБЛсздЖЏЩшЖЈвЛИіКмЕЭЕФжЕ,ЕБгіЕНChannelExceptionвьГЃЪБЛсздЖЏвджИЪ§МЖдіМгетИіГЌЪБЪБМф,жБЕНДяЕНЩшЖЈЕФетИізюДѓжЕЮЊжЙЁЃ |
| batchSize | 100 | УПДЮХњСПДЋЪфЕНchannelЪБЕФsizeДѓаЁ |
| inputCharset | UTF-8 | НтЮіЦїЖСШЁЮФМўЪБЪЙгУЕФБрТы(НтЮіЦїЛсАбЫљгаЮФМўЕБзіЮФБОЖСШЁ) |
| decodeErrorPolicy | FAIL | ЕБДгЮФМўЖСШЁЪБгіЕНВЛПЩНтЮіЕФзжЗћЪБШчКЮДІРэЁЃ FAIL :ХзГівьГЃ,НтЮіЮФМўЪЇАм; REPLACE :ЬцЛЛЕєетаЉЮоЗЈНтЮіЕФзжЗћ,ЭЈГЃЪЧгУU+FFFD; IGNORE :КіТдЮоЗЈНтЮіЕФзжЗћЁЃ |
| deserializer | LINE | жИЖЈвЛИіАбЮФМўжаЕФЪ§ОнааНтЮіГЩEventЕФНтЮіЦїЁЃФЌШЯЪЧАбУПвЛааЕБзівЛИіEventНјааНтЮі,ЫљгаНтЮіЦїБиаыЪЕЯжEventDeserializer.BuilderНгПк |
| deserializer.* | НтЮіЦїЕФЯрЙиЪєад,ИљОнНтЮіЦїВЛЭЌЖјВЛЭЌ | |
| bufferMaxLines | ЈC | (вбЗЯЦњ) |
| bufferMaxLineLength | 5000 | (вбЗЯЦњ)УПааЕФзюДѓГЄЖШЁЃИФгУ deserializer.maxLineLength ДњЬц |
| selector.type | replicating | ПЩбЁжЕ:replicating Лђ multiplexing ,ЗжБ№БэЪО: ИДжЦЁЂЖрТЗИДгУ |
| selector.* | channelбЁдёЦїЕФЯрЙиЪєад,ОпЬхЪєадИљОнЩшЖЈЕФ selector.type жЕВЛЭЌЖјВЛЭЌ | |
| interceptors | ЈC | ИУsourceЫљЪЙгУЕФРЙНиЦї,ЖрИігУПеИёЗжПЊ |
| interceptors.* | РЙНиЦїЯрЙиЕФЪєадХфжУ |
ХфжУЗЖР§:
a1.channels = ch-1
a1.sources = src-1
a1.sources.src-1.type = spooldir
a1.sources.src-1.channels = ch-1
a1.sources.src-1.spoolDir = /var/log/apache/flumeSpool
a1.sources.src-1.fileHeader = true
3. Exec:EXECжДаавЛИіИјЖЈЕФУќСюЛёЕУдДЕФБфЛЏЁЃ
етИіsourceдкЦєЖЏЪБдЫааИјЖЈЕФUnixУќСю,ВЂЦкЭћИУНјГЬдкБъзМЪфГіЩЯСЌајЩњГЩЪ§Он(stderr аХЯЂЛсБЛЖЊЦњ,Г§ЗЧЪєад logStdErr ЩшжУЮЊ true )ЁЃ ШчЙћНјГЬвђШЮКЮдвђЭЫГі, дђsourceвВЛсЭЫГіВЂЧвВЛЛсМЬајЩњГЩЪ§ОнЁЃ злЩЯРДПДcat [named pipe]Лђtail -F [file]етСНИіУќСюЗћКЯвЊЧѓПЩвдВњЩњЫљашЕФНсЙћ,ЖјdateетжжУќСюПЩФмВЛЛс,вђЮЊЧАСНИіУќСю(tail КЭ cat)ФмВњЩњГжајЕФЪ§ОнСї,ЖјКѓеп(dateетжжУќСю)жЛЛсВњЩњЕЅИіEventВЂЭЫГіЁЃ
| Ъєад | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channels | ЈC | гыSourceАѓЖЈЕФchannel,ЖрИігУПеИёЗжПЊ |
| type | ЈC | зщМўРраЭ,етИіЪЧ: exec |
| command | ЈC | ЫљЪЙгУЕФЯЕЭГУќСю,вЛАуЪЧcat Лђепtail |
| shell | ЈC | ЩшжУгУгкдЫааУќСюЕФshellЁЃ Р§Шч / bin / sh -cЁЃ НіЪЪгУгквРРЕshellЙІФмЕФУќСю,ШчЭЈХфЗћЁЂКѓЭЫБъМЧЁЂЙмЕРЕШЁЃ |
| restartThrottle | 10000 | ГЂЪджиаТЦєЖЏжЎЧАЕШД§ЕФЪБМф(КСУы) |
| restart | false | ШчЙћжДааУќСюЯпГЬЙвЕє,ЪЧЗёжиЦє |
| logStdErr | false | ЪЧЗёЛсМЧТМУќСюЕФstderrФкШн |
| batchSize | 20 | ЖСШЁВЂЯђchannelЗЂЫЭЪ§ОнЪБЕЅДЮЗЂЫЭЕФзюДѓЪ§СП |
| batchTimeout | 3000 | ЯђЯТгЮЭЦЫЭЪ§ОнЪБ,ЕЅДЮХњСПЗЂЫЭEventЕФзюДѓЕШД§ЪБМф(КСУы),ШчЙћЕШД§СЫbatchTimeoutКСУыКѓЮДДяЕНвЛДЮХњСПЗЂЫЭЪ§СП,дђШдШЛжДааЗЂЫЭВйзїЁЃ |
| selector.type | replicating | ПЩбЁжЕ:replicating Лђ multiplexing ,ЗжБ№БэЪО: ИДжЦЁЂЖрТЗИДгУ |
| selector.* | channelбЁдёЦїЕФЯрЙиЪєад,ОпЬхЪєадИљОнЩшЖЈЕФ selector.type жЕВЛЭЌЖјВЛЭЌ | |
| interceptors | ЈC | ИУsourceЫљЪЙгУЕФРЙНиЦї,ЖрИігУПеИёЗжПЊ |
| interceptors.* | РЙНиЦїЯрЙиЕФЪєадХфжУ |
ХфжУЗЖР§:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
4. Multiport Syslog TCP Source
етЪЧвЛИідіЧПАцЕФ Syslog TCP Source ,ЫќИќаТЁЂИќПьЁЂжЇГжМрЬ§ЖрИіЖЫПкЁЃвђЮЊжЇГжСЫЖрИіЖЫПк,portВЮЪ§вбОИФЮЊСЫportsЁЃетИіSourceЪЙгУСЫApache mina(вЛИівьВНЭЈаХЕФПђМм,ЭЌnettyРрЫЦ)РДЪЕЯжЁЃ ЬсЙЉСЫЖдRFC-3164КЭаэЖрГЃМћЕФRFC-5424ИёЪНЯћЯЂЕФжЇГжЁЃ жЇГжУПИіЖЫПкХфжУВЛЭЌзжЗћМЏЁЃ
| Ъєад | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channels | ЈC | гыSourceАѓЖЈЕФchannel,ЖрИігУПеИёЗжПЊ |
| type | ЈC | зщМўРраЭ,етИіЪЧ:multiport_syslogtcp |
| host | ЈC | вЊМрЬ§ЕФhostnameЛђепIPЕижЗ |
| ports | ЈC | вЛИіЛђЖрИівЊМрЬ§ЕФЖЫПк,ЖрИігУПеИёЗжПЊ |
| eventSize | 2500 | НтЮіГЩEventЕФУПааЪ§ОнЕФзюДѓзжНкЪ§ |
| keepFields | none | ЪЧЗёБЃСєsyslogЯћЯЂЭЗжаЕФвЛаЉЪєадЕНEventжа,ПЩбЁжЕ all ЁЂnone ЛђздЖЈвхжИЖЈБЃСєЕФзжЖЮ,ШчЙћЩшжУЮЊall,дђЛсБЃСєPriority, Timestamp КЭHostnameШ§ИіЪєадЕНEventжаЁЃ вВжЇГжЕЅЖРжИЖЈБЃСєФФаЉЪєад(жЇГжЕФЪєадга:priority, version, timestamp, hostname),гУПеИёЗжПЊМДПЩЁЃЯждквбОВЛНЈвщЪЙгУ true КЭ false ,НЈвщИФгУ all КЭ none СЫЁЃ |
| portHeader | ЈC | ШчЙћХфжУСЫетИіЪєаджЕ,ЖЫПкКХЛсБЛДцЕНУПИіEventЕФheaderРяУцгУетИіЪєадХфжУЕФжЕЕБkeyЁЃетбљОЭПЩвддкРЙНиЦїЛђепchannelбЁдёЦїРяУцИљОнЖЫПкКХРДздЖЈвхТЗгЩEventЕФТпМЁЃ |
| charset.default | UTF-8 | НтЮіsyslogЪЙгУЕФФЌШЯБрТы |
| charset.port. | ЈC | еыЖдОпЬхФГвЛИіЖЫПкХфжУБрТы |
| batchSize | 100 | УПДЮЧыЧѓГЂЪдДІРэЕФзюДѓEventЪ§СП,ЭЈГЃгУетИіФЌШЯжЕОЭКмКУЁЃ |
| readBufferSize | 1024 | ФкВПMinaЭЈаХЕФЖСШЁЛКГхЧјДѓаЁ,гУгкадФмЕїгХ,ЭЈГЃгУФЌШЯжЕОЭКмКУЁЃ |
| numProcessors | (здЖЏЗжХф) | ДІРэЯћЯЂЪБЯЕЭГЪЙгУЕФДІРэЦїЪ§СПЁЃ ФЌШЯЪЧЪЙгУJava Runtime APIздЖЏМьВтCPUЪ§СПЁЃ MinaНЋЮЊУПИіМьВтЕНЕФCPUКЫаФЩњГЩ2ИіЧыЧѓДІРэЯпГЬ,етЭЈГЃЪЧКЯРэЕФЁЃ |
| selector.type | replicating | ПЩбЁжЕ:replicating Лђ multiplexing ,ЗжБ№БэЪО: ИДжЦЁЂЖрТЗИДгУ |
| selector.* | ЈC | channelбЁдёЦїЕФЯрЙиЪєад,ОпЬхЪєадИљОнЩшЖЈЕФ selector.type жЕВЛЭЌЖјВЛЭЌ |
| interceptors | ЈC | ИУsourceЫљЪЙгУЕФРЙНиЦї,ЖрИігУПеИёЗжПЊ |
| interceptors.* | РЙНиЦїЯрЙиЕФЪєадХф |
ХфжУЗЖР§:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = multiport_syslogtcp
a1.sources.r1.channels = c1
a1.sources.r1.host = 0.0.0.0
a1.sources.r1.ports = 10001 10002 10003
a1.sources.r1.portHeader = port
5. JSONHandler:НгЪмjsonИёЪНЪ§ОнЁЃ
етЪЧHTTP SourceЕФФЌШЯНтЮіЦї(handler),ИљОнЧыЧѓЫљЪЙгУЕФБрТыАбhttpЧыЧѓжаjsonИёЪНЕФЪ§ОнНтЮіГЩFlume
EventЪ§зщ(ВЛЙмЪЧвЛИіЛЙЪЧЖрИі,ЖМвдЪ§зщИёЪННјааДцДЂ),
ШчЙћЮДжИЖЈБрТы,ФЌШЯЪЙгУUTF-8БрТыЁЃетИіhandlerжЇГжUTF-8ЁЂUTF-16КЭUTF-32БрТыЁЃ
jsonЪ§ОнИёЪНШчЯТ
[{
"headers" : {
"timestamp" : "434324343",
"host" : "random_host.example.com"
},
"body" : "random_body"
},
{
"headers" : {
"namenode" : "namenode.example.com",
"datanode" : "random_datanode.example.com"
},
"body" : "really_random_body"
}]
дквЛИіPOSTЧыЧѓжаЗЂЫЭЕФЫљга Event ЪгЮЊвЛИіХњДІРэ,ВЂдквЛИіЪТЮёжаВхШыЕН channelЁЃ
| Ъєад | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channels | ЈC | гыSourceАѓЖЈЕФchannel,ЖрИігУПеИёЗжПЊ |
| type | зщМўРраЭ,етИіЪЧ: http | |
| port | ЈC | вЊМрЬ§ЕФЖЫПк |
| bind | 0.0.0.0 | вЊМрЬ§ЕФhostnameЛђепIPЕижЗ |
| handler | org.apache.flume.source.http.JSONHandler | ЫљЪЙгУЕФhandler,ашЬюаДhandlerЕФШЋЯоЖЈРрУћ |
| handler.* | ЈC | handlerЕФвЛаЉЪєадХфжУ |
| selector.type | replicating | ПЩбЁжЕ:replicating Лђ multiplexing ,ЗжБ№БэЪО: ИДжЦЁЂЖрТЗИДгУ |
| selector.* | channelбЁдёЦїЕФЯрЙиЪєад,ОпЬхЪєадИљОнЩшЖЈЕФ selector.type жЕВЛЭЌЖјВЛЭЌ | |
| interceptors | ЈC | ИУsourceЫљЪЙгУЕФРЙНиЦї,ЖрИігУПеИёЗжПЊ |
| interceptors.* | РЙНиЦїЯрЙиЕФЪєадХф | |
| enableSSL | false | ЩшжУЮЊtrueЦєгУSSL,HTTP SourceВЛжЇГжSSLv3авщ |
| excludeProtocols | SSLv3 | жИЖЈВЛжЇГжЕФавщ,ЖрИігУПеИёЗжПЊ,SSLv3ВЛЙмЪЧЗёХфжУЖМЛсБЛЧПжЦХХГ§ |
| keystore | keystore ЮФМўЕФЮЛжУ | |
| keystorePassword | Keystore ЕФУмТы |
6. HDFS Sink:ХфжУHadoopНгЪмЪ§ОнЁЃ
етИіSinkНЋEventаДШыHadoopЗжВМЪНЮФМўЯЕЭГ(вВОЭЪЧHDFS)ЁЃ ФПЧАжЇГжДДНЈЮФБОКЭађСаЮФМўЁЃ ЫќжЇГжСНжжЮФМўРраЭЕФбЙЫѕЁЃ ПЩвдИљОнаДШыЕФЪБМфЁЂЮФМўДѓаЁЛђEventЪ§СПЖЈЦкЙіЖЏЮФМў(ЙиБеЕБЧАЮФМўВЂДДНЈаТЮФМў)ЁЃ ЫќЛЙПЩвдИљОнEventздДјЕФЪБМфДСЛђЯЕЭГЪБМфЕШЪєадЖдЪ§ОнНјааЗжЧјЁЃ ДцДЂЮФМўЕФHDFSФПТМТЗОЖПЩвдЪЙгУИёЪНзЊвхЗћ,ЛсгЩHDFS SinkНјааЖЏЬЌЕиЬцЛЛ,вдЩњГЩгУгкДцДЂEventЕФФПТМЛђЮФМўУћЁЃ ЪЙгУДЫSinkашвЊАВзАhadoop, вдБуFlumeПЩвдЪЙгУHadoopЕФПЭЛЇЖЫгыHDFSМЏШКНјааЭЈаХЁЃ зЂвт, ашвЊЪЙгУжЇГжsync() ЕїгУЕФHadoopАцБО ЁЃ
| ЪєадУћ | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channel | ЈC | гы Sink СЌНгЕФ channel |
| type | ЈC | зщМўРраЭ,етИіЪЧ: hdfs |
| hdfs.path | ЈC | HDFSФПТМТЗОЖ(Р§Шч:hdfs://namenode/flume/webdata/) |
| hdfs.filePrefix | FlumeData | FlumeдкHDFSЮФМўМаЯТДДНЈаТЮФМўЕФЙЬЖЈЧАзК |
| hdfs.fileSuffix | ЈC | FlumeдкHDFSЮФМўМаЯТДДНЈаТЮФМўЕФКѓзК(БШШч:.avro,зЂвтетИіЁА.ЁБВЛЛсздЖЏЬэМг,ашвЊЯдЪНХфжУ) |
| hdfs.inUsePrefix | ЈC | Flumeе§дкаДШыЕФСйЪБЮФМўЧАзК,ФЌШЯУЛга |
| hdfs.inUseSuffix | .tmp | Flumeе§дкаДШыЕФСйЪБЮФМўКѓзК |
| hdfs.rollInterval | 30 | ЕБЧАЮФМўаДШыДяЕНИУжЕЪБМфКѓДЅЗЂЙіЖЏДДНЈаТЮФМў(0БэЪОВЛАДееЪБМфРДЗжИюЮФМў),ЕЅЮЛ:Уы |
| hdfs.rollSize | 1024 | ЕБЧАЮФМўаДШыДяЕНИУДѓаЁКѓДЅЗЂЙіЖЏДДНЈаТЮФМў(0БэЪОВЛИљОнЮФМўДѓаЁРДЗжИюЮФМў),ЕЅЮЛ:зжНк |
| hdfs.rollCount | 10 | ЕБЧАЮФМўаДШыEventДяЕНИУЪ§СПКѓДЅЗЂЙіЖЏДДНЈаТЮФМў(0БэЪОВЛИљОн Event Ъ§СПРДЗжИюЮФМў) |
| hdfs.idleTimeout | 0 | ЙиБеЗЧЛюЖЏЮФМўЕФГЌЪБЪБМф(0БэЪОНћгУздЖЏЙиБеЮФМў),ЕЅЮЛ:Уы |
| hdfs.batchSize | 100 | Яђ HDFS аДШыФкШнЪБУПДЮХњСПВйзїЕФ Event Ъ§СП |
| hdfs.codeC | ЈC | бЙЫѕЫуЗЈЁЃПЩбЁжЕ:gzip ЁЂ bzip2 ЁЂ lzo ЁЂ lzop ЁЂ ``snappy` |
| hdfs.fileType | SequenceFile | ЮФМўИёЪН,ФПЧАжЇГж: SequenceFile ЁЂ DataStream ЁЂ CompressedStream ЁЃ 1. DataStream ВЛЛсбЙЫѕЮФМў,ВЛашвЊЩшжУhdfs.codeC 2. CompressedStream БиаыЩшжУhdfs.codeCВЮЪ§ |
| hdfs.maxOpenFiles | 5000 | дЪаэДђПЊЕФзюДѓЮФМўЪ§,ШчЙћГЌЙ§етИіЪ§СП,зюЯШДђПЊЕФЮФМўЛсБЛЙиБе |
| hdfs.minBlockReplicas | ЈC | жИЖЈУПИіHDFSПщЕФзюаЁИББОЪ§ЁЃ ШчЙћЮДжИЖЈ,дђЪЙгУ classpath жа Hadoop ЕФФЌШЯХфжУЁЃ |
| hdfs.writeFormat | Writable | ЮФМўаДШыИёЪНЁЃПЩбЁжЕ: Text ЁЂ Writable ЁЃдкЪЙгУ Flume ДДНЈЪ§ОнЮФМўжЎЧАЩшжУЮЊ Text,Зёдђ Apache Impala(ЗѕЛЏ)Лђ Apache Hive ЮоЗЈЖСШЁетаЉЮФМўЁЃ |
| hdfs.callTimeout | 10000 | дЪаэHDFSВйзїЮФМўЕФЪБМф,БШШч:openЁЂwriteЁЂflushЁЂcloseЁЃШчЙћHDFSВйзїГЌЪБДЮЪ§діМг,гІИУЪЪЕБЕїИпетИіетИіжЕЁЃ(КСУы) |
| hdfs.threadsPoolSize | 10 | УПИіHDFS SinkЪЕР§ВйзїHDFS IOЪБПЊЦєЕФЯпГЬЪ§(openЁЂwrite ЕШ) |
| hdfs.rollTimerPoolSize | 1 | УПИіHDFS SinkЪЕР§ЕїЖШЖЈЪБЮФМўЙіЖЏЕФЯпГЬЪ§ |
| hdfs.kerberosPrincipal | ЈC | гУгкАВШЋЗУЮЪ HDFS ЕФ Kerberos гУЛЇжїЬх |
| hdfs.kerberosKeytab | ЈC | гУгкАВШЋЗУЮЪ HDFS ЕФ Kerberos keytab ЮФМў |
| hdfs.proxyUser | ДњРэУћ | |
| hdfs.round | false | ЪЧЗёгІНЋЪБМфДСЯђЯТЩсШы(ШчЙћЮЊtrue,дђгАЯьГ§ %t жЎЭтЕФЫљгаЛљгкЪБМфЕФзЊвхЗћ) |
| hdfs.roundValue | 1 | ЯђЯТЩсШы(аЁгкЕБЧАЪБМф)ЕФетИіжЕЕФзюИпБЖ(ЕЅЮЛШЁОігкЯТУцЕФ hdfs.roundUnit ) Р§зг:МйЩшЕБЧАЪБМфДСЪЧ18:32:01,hdfs.roundUnit = minute ШчЙћroundValue=5,дђЪБМфДСЛсШЁЮЊ:18:30 ШчЙћroundValue=7,дђЪБМфДСЛсШЁЮЊ:18:28 ШчЙћroundValue=10,дђЪБМфДСЛсШЁЮЊ:18:30 |
| hdfs.roundUnit | second | ЯђЯТЩсШыЕФЕЅЮЛ,ПЩбЁжЕ: second ЁЂ minute ЁЂ hour |
| hdfs.timeZone | Local Time | НтЮіДцДЂФПТМТЗОЖЪБКђЫљЪЙгУЕФЪБЧјУћ,Р§Шч:America/Los_AngelesЁЂAsia/Shanghai |
| hdfs.useLocalTimeStamp | false | ЪЙгУШеЦкЪБМфзЊвхЗћЪБЪЧЗёЪЙгУБОЕиЪБМфДС(ЖјВЛЪЧЪЙгУ Event header жаздДјЕФЪБМфДС) |
| hdfs.closeTries | 0 | ПЊЪМГЂЪдЙиБеЮФМўЪБзюДѓЕФжиУќУћЮФМўЕФГЂЪдДЮЪ§(вђЮЊДђПЊЕФЮФМўЭЈГЃЖМгаИі.tmpЕФКѓзК,аДШыНсЪјЙиБеЮФМўЪБвЊжиУќУћАбКѓзКШЅЕє)ЁЃШчЙћЩшжУЮЊ1,SinkдкжиУќУћЪЇАм(ПЩФмЪЧвђЮЊ NameNode Лђ DataNode ЗЂЩњДэЮѓ)КѓВЛЛсжиЪд,етбљОЭЕМжТСЫетИіЮФМўЛсвЛжББЃГжЮЊДђПЊзДЬЌ,ВЂЧвДјзХ.tmpЕФКѓзК;ШчЙћЩшжУЮЊ0,SinkЛсвЛжБГЂЪджиУќУћЮФМўжБЕНГЩЙІЮЊжЙ;ЙиБеЮФМўВйзїЪЇАмЪБетИіЮФМўПЩФмШдШЛЪЧДђПЊзДЬЌ,етжжЧщПіЪ§ОнЛЙЪЧЭъећЕФВЛЛсЖЊЪЇ,жЛгадкFlumeжиЦєКѓЮФМўВХЛсЙиБеЁЃ |
| hdfs.retryInterval | 180 | СЌајГЂЪдЙиБеЮФМўЕФЪБМфМфИє(Уы)ЁЃ УПДЮЙиБеВйзїЖМЛсЕїгУЖрДЮ RPC ЭљЗЕгк Namenode ,вђДЫНЋДЫЩшжУЕУЬЋЕЭЛсЕМжТ Namenode ЩЯВњЩњДѓСПИКдиЁЃ ШчЙћЩшжУЮЊ0ЛђИќаЁ,дђШчЙћЕквЛДЮГЂЪдЪЇАм,НЋВЛЛсдйГЂЪдЙиБеЮФМў,ВЂЧвПЩФмЕМжТЮФМўБЃГжДђПЊзДЬЌЛђРЉеЙУћЮЊЁА.tmpЁБЁЃ |
| serializer | TEXT | Event зЊЮЊЮФМўЪЙгУЕФађСаЛЏЦїЁЃЦфЫћПЩбЁжЕга: avro_event ЛђЦфЫћ EventSerializer.Builderinterface НгПкЕФЪЕЯжРрЕФШЋЯоЖЈРрУћЁЃ |
| serializer.* | ИљОнЩЯУц serializer ХфжУЕФРраЭРДИљОнашвЊЬэМгађСаЛЏЦїЕФВЮЪ§ |
ХфжУЗЖР§:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
7. File Roll Sink:ХфжУБОЕиЮФМўНгЪмЪ§ОнЁЃ
| Ъєад | ФЌШЯжЕ | НтЪЭ |
|---|---|---|
| channel | ЈC | гы Sink АѓЖЈЕФ channel |
| type | ЈC | зщМўРраЭ,етИіЪЧ: file_roll. |
| sink.directory | ЈC | Event НЋвЊБЃДцЕФФПТМ |
| sink.pathManager | DEFAULT | ХфжУЪЙгУФФИіТЗОЖЙмРэЦї,етИіЙмРэЦїЕФзїгУЪЧАДееЙцдђЩњГЩаТЕФДцДЂЮФМўУћГЦ,ПЩбЁжЕга: default ЁЂ rolltimeЁЃdefaultЙцдђ:prefix+ЕБЧАКСУыжЕ+ЁА-ЁБ+ЮФМўађКХ+ЁА.ЁБ+extension;rolltimeЙцдђ:prefix+yyyyMMddHHmmss+ЁА-ЁБ+ЮФМўађКХ+ЁА.ЁБ+extension;зЂ:prefix КЭ extension ШчЙћУЛгаХфжУдђВЛЛсИНДј |
| sink.pathManager.extension | ЈC | ШчЙћЩЯУцЕФ pathManager ЪЙгУФЌШЯЕФЛА,ПЩвдгУетИіЪєадХфжУДцДЂЮФМўЕФРЉеЙУћ |
| sink.pathManager.prefix | ЈC | ШчЙћЩЯУцЕФ pathManager ЪЙгУФЌШЯЕФЛА,ПЩвдгУетИіЪєадХфжУДцДЂЮФМўЕФЮФМўУћЕФЙЬЖЈЧАзК |
| sink.rollInterval | 30 | БэЪОУПИє30УыДДНЈвЛИіаТЮФМўНјааДцДЂЁЃШчЙћЩшжУЮЊ0,БэЪОЫљга Event ЖМЛсаДЕНвЛИіЮФМўжаЁЃ |
| sink.serializer | TEXT | ХфжУ Event ађСаЛЏЦї,ПЩбЁжЕга:text ЁЂ header_and_text ЁЂ avro_event ЛђепздЖЈвхЪЕЯжСЫ EventSerializer.Builder НгПкЕФађСаЛЏЦїЕФШЋЯоЖЈРрУћ.ЁЃ text жЛЛсАб Event ЕФ body ЕФЮФБОФкШнађСаЛЏ; header_and_text ЛсАб header КЭ body ФкШнЖМађСаЛЏЁЃ |
| batchSize | 100 | УПДЮЧыЧѓХњДІРэЕФ Event Ъ§ |
ХфжУЗЖР§:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = file_roll
a1.sinks.k1.channel = c1
a1.sinks.k1.sink.directory = /var/log/flume