ѧϰ����:https://www.bilibili.com/video/BV1cr4y1671t?p=1&vd_source=510ec700814c4e5dc4c4fda8f06c10e8
����ʼ�:https://www.cnblogs.com/meditation5201314/p/14882992.html#redis%E4%BA%94%E7%A7%8D%E5%9F%BA%E6%9C%AC%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B
�����ַ:https://gitee.com/empirefree/SpringBoot-summarize
��������Ϊ��ʦ������Ŀ���뽲��,����������ô��,��ʵ��ʦ���úܺõ�,��ȫ���Բ�������Ŀ,�Լ�����С��Ŀ�͵���ʹ�û���redis���С��ڸ�ƪ��ʱ����Ⱥ��canal��Щ��������,����Ϥ��¼��,�Ժ��õ�����˵
����Ŀ¼
🔥1. ����ƪ
1.1 ǰ��
����˵�CRedisѧϰ�ʼ�:https://www.cnblogs.com/meditation5201314/p/14882992.html
֮ǰѧ�����Redis,�����Ҹо�Redisѧ����,�������й�ȷ���Redisƪ��,�ŷ����Լ�ֻ������ѧ�˵����Ƥë,ʵ�ʸ����ݡ�ʵս������ԭ����û���˽�,��Ȼ������ǫѷǰ��ѽ��
1.2 ��������
1.2.1 String
setnx mykey 111
1.2.2 List
�Ƚ�ȥ�ĺ����,�ɿ���ջ,Ҳ����������
1.2.3 set
ֵ�����ظ�
1.2.4 Hash
key map
1.2.5 Zset
zset key score value
-- z1��������Ԫ��m2,����Ϊ2
zadd z1 2 m2
--���������1��ʼ���2��Ԫ��
zrevrange z1 1 2 withscores
-- ��ѯz1�����1000����С0��,0:ƫ����С�ڵ���1000��3��Ԫ��
zrevrangeByScore z1 1000 0 withscores limit 0 3
-- 1:����С���ϴη�����������3��Ԫ��(������ͬ������ظ�����)
zrevrangeByScore z1 �ϴη��������� 0 withscores limit 1 3
1.3 ���ӳ�
1.3.1 ���ӳ�����
1.jedis
2.SpringDataRedis:�ṩ��redisTemplate
1.3.2 RedisTempalte
1.3.2.1 ��������
1.�ڲ�ʵ����jdk���л�
2.��������:����SpringMVC������jackson-Binder֮������л�
🔥2. ʵսƪ
2.1. ���ŵ�¼(��)
? ֮ǰ�����ܶ���,���˼���дԭ����������
2.2. ���ݻ���
2.2.1 ��������
2.2.1.1 ������²���
- ����ɾ������
- ��α�֤��������ݿ�����һ����
- ������Ŀ:��������ݿ�ŵ�ͬһ��������
- �ֲ�ʽ����:TCC����
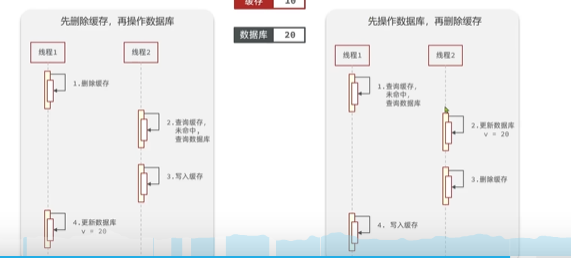
- �Ȳ������ݿ�or��ɾ������(����һ��ָ�����û�����,�̼Һ�̨�������ݵ����,��Ȼ,����������������߷ֲ�ʽ��ʵ��Ҳ��)
- ��ɾ����,�ٲ������ݿ�:A��ɾ��,B��Aδ����ǰ��ȡд�뻺��ͻ�д���������
- �Ȳ������ݿ�,�ٲ�������:A�Ȳ������ݿ�,B��A����ǰ��ȡ���ݿ�д�뻺��Ҳ���ȡ����������
- ��ʱ˫ɾ(����ǰɾ��,���¿����ʱ3~5��,Ȼ����ɾ):֮������ʱ����Ϊ�˱�֤Aɾ����������ݿ��δִ����,Bһ���ֶ�ȡ��������,Ȼ�������,����Ϊ�˱�֤Bִ����,�������������岻��,��������»��ǵ���������߷ֲ�ʽ�������˽��°ɡ�
2.2.1.2 �ֹ���/������
�ֹ��� + ����:��ʵ������һ����,�ʺϲ�������С�����(��Ϊ����������Ƶ������,���õ���CAS capare and swap������汾�Ż���2�ַ�ʽ)
������ + ����:ÿ�ζ�ȡǰ����
2.3 �ֲ�ʽ��
2.3.1 ��������
�ֲ�ʽ��:�ֲ�ʽϵͳ��Ⱥģʽ�¶��߳�֮�以��ɼ����һ������
2.3.2 Redissonԭ��
2.3.2.0 �ֲ�ʽ������
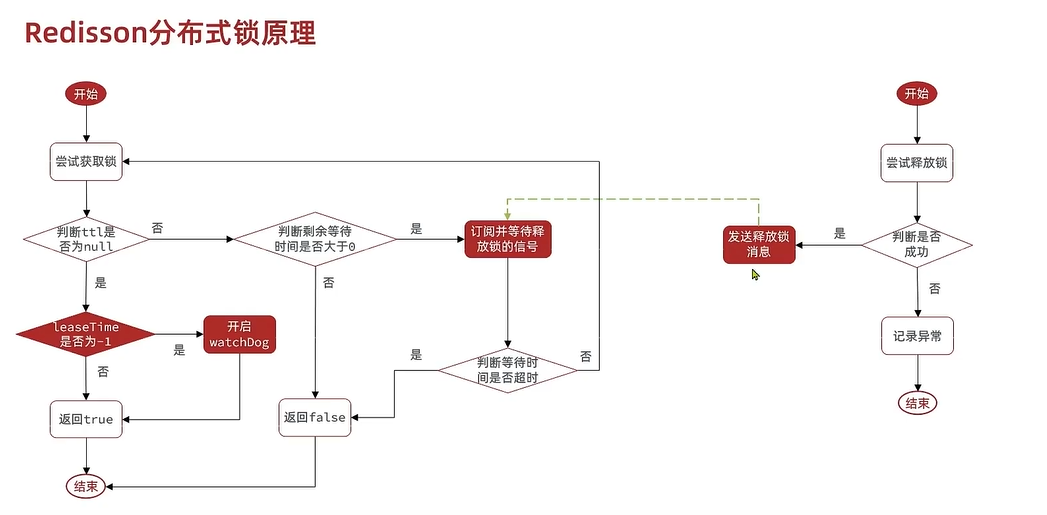
����setnx���µķֲ�ʽ������4������,��Redisson���Խ��:
1. ��������:setx�߳�ͬһ���߳̿����ظ���ȡͬһ����
1. ��������:setnt��ȡ��ֻ����һ��û������
1. ��ʱ�ͷ�:setnxҵ��ִ�й����ͻ��Զ���ɾ��������(��������㲻���ó�ʱʱ����������˵Ļ��Ǻ���keyֵһֱ����)
1. ����һ����:setnx��,����������,崻���ӿ�������,Ȼ���ⲿ��Ȼ�ܻ�ȡ��
2. Redisson��������
��ȡ��:
// �ж��Ƿ����,�ܻ�ȡ���ȡ
if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
//����threadid�ж����Dz����Լ���,��ȡ��������һ,Ȼ��������Ч��
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
//��������ȡʧ��
return redis.call('pttl', KEYS[1]);
? �ͷ���:
//���������=0,��ֱ���ͷ�
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then return nil;
end;
//�������������0,������Ч��,����һȻ�ء�����˵����==0,����ֱ��ɾ����������
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]); //ɾ�����ж���,��������ȡ��ʧ�����Ի��Ƶ��߳�ʹ��
return 1;
end;
return nil;
2.3.2.2 ��������
//��ȡ�����ͷ�����Դ������2����������
// tryLock��3������: ��ȡ���ȴ�ʱ��(Ĭ�ϲ��ȴ�) �ͷ���ʱ��, ʱ�䵥λ
boolean isLock = rLock.tryLock(1, 10, TimeUnit.SECONDS);
rLock.unlock();
1. ����
1. �߳�a��ִ��Lua�ű���ȡ��,��ȡ�ɹ�(Ĭ���ͷ���ʱ��30��)LUA�ű���֤��ͬ���߳�id��ȡ��**������**
1. �����������ͷ�ʱ��,��ִ�п��Ź�����ˢ�»���
2. ��û����,��Ĭ��ʹ�ÿ��ſ����ͷ�ʱ��30��,ִ�п��Ź�ˢ�»��ơ�
1. �ݹ�ÿ���ſ�ʱ�� / 3 = 10��ˢ�¸��߳�id����Ч��,��֤�˲���**��ʱ��ɾ��**(��ΪĬ��30���10���)
2. �߳�bִ��Lua�ű�ʧ��,���еȴ�ʱ��Ķ���,Ȼ�����»�ȡ��,�յ��˶��ľͰ��յȴ�ʱ���Ƿ�ʣ���������,û�յ�����ʱ�䵽�˾��˳�----��֤�˵ȴ�ʱ�����ȼ����,ʵ����**������**
2. ����
1. �ͷŶ�����Ϣ
2. ȡ�����Ź�
Redisson�ֲ�ʽ��
? 1.������:����hash �洢�߳�id���������
? 2.������:���÷������ĺ�ѭ���ȴ�ʵ��������(��֤�ڵȴ�ʱ����)
? 3.��ʱ��Լ:����watchDog,ÿ��һ��ʱ��(releaseTime / 3)����
? 4.����һ����:����multiLock��ȡȫ�����ڵ������ܳɹ�(�����˶�����ڵ�)
2.4 ��Ʒ��ɱ
2.4.1 ��������
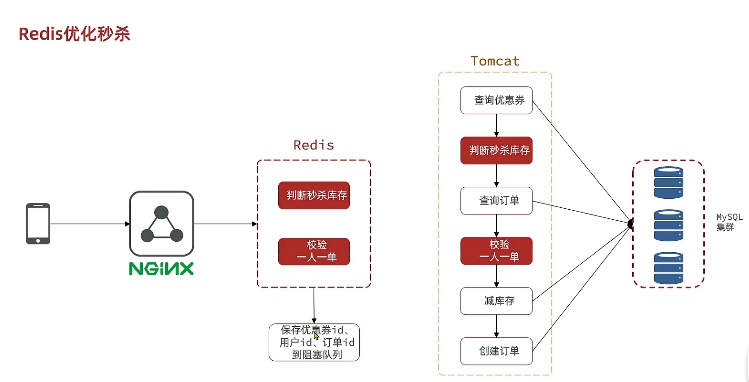
? 1��Redis��ɱ�ʸ��ж�(Lua�ű���֤ԭ����)�����������Ϣ����������
? 2���첽��������,�ۼ����
2.4.2 ��ɱ�ʸ�CLua�ű�
-- �жϿ�桢�ж��û��Ƿ��µ�,�ۼ����
-- ��ȡ������ȯid���û�id
local voucherId = ARGV[1]
local userId = ARGV[2]
local stockKey = 'seckill:stock:' .. voucherId
local orderKey = 'seckill:order:' .. voucherId
--
if(tonumber(redis.call('get', stockKey)) <= 0) then
return 1
end
if(redis.call("sismember", orderKey, userId) == 1) then
return 2
end
redis.call('incrby', stockKey, -1)
redis.call("sadd", orderKey, userId)
return 0
2.4.3 ��ɱ�µ��C���������첽ʵ��
? 0����ǰ�����������ж�ȡ
? 1��Redis�����ʸ��ж�,�����ʸ�ķ������
? 2���̳߳��첽��ȡ��������
(����:���������ǻ���jvm�ڴ����洢����,����崻�,�߲������ᵼ������������)
2.4.4 Redis-��Ϣ����
2.4.4.1 ��������
? �����Ϣ�Ķ���,˫������,����[LPush, BRPOP],��[Rpush, BLPOP]��Щʵ���������С�
2.4.4.2 List��Ϣ����
? �ŵ�:
1. ����Redis�洢,��������JVM�ڴ�
2. ����Redis���ݳ־û�
? ȱ��:
1. ��������Ϣ��ʧ
2. ֻ��֧�ֵ�������,���ö��������ʹ��
2.4.4.3 PubSub��Ϣ����
-- ����
publish order.q1.hello
--����
subscribe order.q1
--����: ֧��ͨ��� *0������ ?һ������ []�����ڲ�����
PSUBSCRIBE order.*
? ֧�ֶ�����,������
? ��֧�����ݳ־û�,��������Ϣ��ʧ,��Ϣ�ѻ�
2.4.4.4 Stream��Ϣ����
--����stream����,*��ʾ��redis������Ϣid
-- ����һ:�����ڶ����д�����,����������ȡȴ��ȡ���µ�,����ڸ���
xadd s1 * k1 v1
--�����
xlen s1
--��ȡһ��������Ϣ,��0��ʼ��ȡ
xread count 1 streams s1 0
--��ȡһ����Ϣ,�����¿�ʼ��ȡ,���õȴ�
xread count 1 block 0 streams s1 $
- ��Ϣ���ô���,�ɻ���,��������ȡ,�ɱ���������߶�ȡ
- ����ÿ�ζ�ȡ���µ�,����ڶ�ȡǰ��Ϣ©�������ǵķ���,��pubsub����
��Ϣ����:��Ϣ�ָ���ͬ��������ȥ
��Ϣ��ʶ:��������ǩ,��Ƕ������ĸ���Ϣ,����崻�����������ӱ�ʶ��ȡ(�����ͱ�������Ϣ©�����)
��Ϣȷ��:��Ϣ���ͺ�ᴦ��pending,������ɺ���XACKȷ��,Ȼ������Ƴ�����Ϣ
��Ϣ��ģʽ
? 1�����������������ȡ��Ϣ
? 2������������ȡ,��Ϣ�ɻ���
? 3��û����Ϣ©������,��Ϣ�ɻ���
-- 0������һ����Ϣ,$�������һ����Ϣ
-- >��ʾ��һ��δ���ѵ���Ϣ,"����"��ʾ�����ѵ�δȷ�ϵ���Ϣ. c1��ʾ����������
-- ���ж�:����ʧ��û�б�ȷ�ϵ���Ϣ����pengding-list,������һ��ָ���ǵ�һ��λ��,��һ��ָ�벻��������
--��stream��s1���뵽g1��,�ӵ�һ����ʼ
xgroup create s1 g1 0
xreadgroup group g1 c1 count 1 block 2000 streams s1 >
-- ������Ϣidȷ����Ϣ
xack s1 g1 1655878247936-0
--�鿴pending-list������ʱ����ڵ�10����Ϣ
xpending s1 g1 - + 10
--��ȡpending-list��δ��ȷ�ϵĵ�һ����Ϣ
xreadgroup group g1 c1 count 1 block 2000 streams s1 0
? [����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-WWIDBab1-1656671557221)(��/��/��/��/��/Roaming/Typora/typora-user-images/image-20220622145459299.png)]
ʵս
--MKSTREAM: �����������Զ�����
xgroup create stream.orders g1 0 MKSTREAM
--Lua�ű������ж����ݡ�����һ���߳�ѭ����ȡ��������,����ackȷ��
2.5 ҵ�����
2.5.1 ������
Redis��������id��keyֵ����,Ȼ��ͬ���������
2.5.2 ��ע����
? ��ÿ�ι�ע�û���,����follows-id��Ϊkey,����set��redis�й�ע���,Ȼ��ͬ���������
2.5.3 Feed��
2.5.3.1 ��������
? Feed��:�������û������û�����Ȥ�Ķ���
? 1.TimeLine:�������б�ɸѡ
? 2.��������:�����㷨����
2.5.3.2 ʵ�ַ���
? ��ģʽ:�û���ȡ�Լ���ע����Ϣ,���ǹ�ע̫�������ڴ�
? ��ģʽ:����ÿ�η����������Լ���ע����,�Լ���˿̫��Ҳ����ʵ
? ����ģʽ:�˷ֳɴ�V����ͨ��,��˿�ֳɻ�Ծ��˿�ͽ�ʬ��,��ͨ�˾����Լ���ע�˵���Ϣ,��ͨ�˾������Լ���Ϣ����˿
2.5.3.3 ������ҳ
? ���ڴ�ͳid��������ʱ�ᵼ�����ݲ���ˢ��,����ԭʼlimit offset����ȡ,����redis��sortset,����һ������score����֤��ȡ�̶���redis�оͲ���ʱ������Ϊscoer
2.5.3.4 ���̾���
? ����Geo�����������
2.5.3.5 �û�ǩ��
? �����ڿ���д�ÿ���û�ÿ��ǩ��������̫��,���Կ��Բ���bitλ���洢,ֻҪ��ʱ����Ϊkeyֵ,Ҳ���������ѯͳ������
2.5.3.6 PV/UV
? ͳ��PV,UV��Щ����ʹ��hyperloglog����Щ����
🔥3.��ƪ
3.1. �ֲ�ʽ����
3.1.1 RDB
? RDB:Ĭ��save�������̱���,bgsave��forkһ���ӽ��̽��б���
3.1.2 AOF
? AOF: ��¼ָ��,Ȼ���滻�ϸ�aof�ļ�
3.1.3 ���̻���
? �ֲ�ʽ����:���ʻ��������翪��,��Ⱥ���Թ���,������������
? ���̻���:���ʱ����ڴ��ٶȸ���,����������
3.1.4 Canal
? canal����ģ��salve��Redis-master��binlog��ȡ��slave���С�
? ÿ�����ݿ�������,canal�ͼ���Ȼ�������ݵ����ݿ���
3.2. ʵ�����
3.2.1 �������
? 1.key ����� [ҵ������]:[������]:[id]
2. ɾ��bigkey:����һ���߳��첽ɾ��ֵ
2. **����ʹ��hash�洢**,key����ʹ�������� %100����,fieldʹ��key,value(�ڴ�ռ�÷dz���,��Ϊʹ��zipList,Ĭ�ϲ�Ҫ����keyֵ500)
2. �������������:sadd,mset����
2. Redis�����ܴﵽ��w�����QPS,������Ҫ���Ⱥ��
3.2.2 �������Ż�
? 1.������Ҫ�����־û�����
? 2.���鿪��AOF�־û�
🔥4.ԭ��ƪ
4.1 ���ݽṹ
4.1.1 ��������
? Redis:�ײ���Cд��
4.1.2 ��̬�ַ���SDS
? Redis��key, value���Dz��õ��������ַ���SDS���洢,SDS�����Ǹ��ṹ��,�ֳ��ַ���ͷ(��¼�ַ�������)����(�洢��ʵ����)
4.1.3 IntSet
? int��set:����Ψһ����,�ڲ����ö��ֲ�ѯ��ѯ
4.1.4 Dict
? ��3�������:dictHashTable��ϣ��,dictEntry��ϣ���,dict�ֵ�
��ϣ�����ɾ���dicEntry����key, valueֵ
Dict�ֵ����2����ϣ��,�������ݺ�����,�ײ��������+���������hash��ͻ
(�ܽ�dict�ײ����hash��,��������͵���������ʵ��,���б���ľ���key, value��Entry��ֵ��,��ָ��������SDS����)
4.1.5 ZipList
? ѹ���б����������ڴ�ռ���б�,û��ʹ��ָ������,���Ǽ�¼���ϸ��ڵ�Ѱַ����Ϊ�������dict����ָ��ѡ��,�ڴ���Ƭ̫��,ָ���ֽ�ռ��̫�ࡣ
4.1.6 QuickList
? �ڵ�ΪzipList��˫������,������zipList��������������ڴ�ռ�,������ָ�����Ĺ����ڴ�ռ���ŵ㡣
4.1.7 SkipList���� *
? ����������,Ԫ�ذ���������,Ȼ����Ԫ��֮�����Ͻ���ָ��,��MySQL������������,�����������,CURDЧ��������һ��log(n)
4.1.8 RedisObject
? RedisObject������5����������,Ȼ��5��������뷽ʽ������������,zipList,quickList��Щ��(typerloglog,bitmap,bitmap�ײ�Ҳ����string,zset)
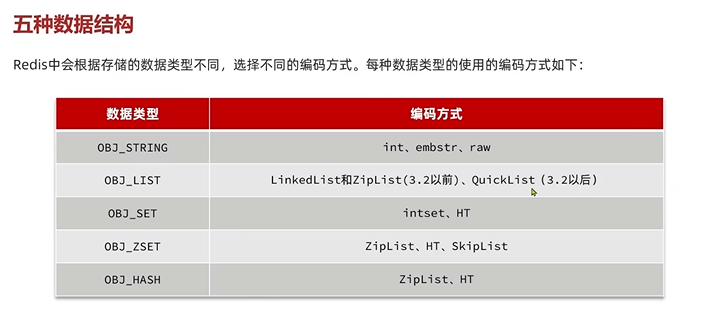
4.2 ����ģ��
4.2.1 IO��·����
? ���õ��߳�ͬʱ�����������Ϊselect,poll, epoll��
selectÿ�ζ�Ҫ�������������FD���û����ں˺�ʱ
epoll�ͰѾ����ļ�������FD��������,Ȼ��ÿ�ξͲ��ñ�������FD
4.2.2 ģ�ͱȽ�
? Ŀǰ����IO��·�����õıȽ϶�

4.2.3 Redis����ģ��
? Redis6.0֮�������˶��߳�,֮ǰ���ǵ��߳�
4.2.4 Redis����
? Redis�в���dict��¼��key��TTLʱ��
4.2.4.1 ����-ɾ������
1. ��������:ÿ�β���key,���ھ�ɾ��
1. ��������:���ڳ�ȡkey,���ھ�ɾ��
4.2.4.2 ��̭����
? 8�ֲ���:Ĭ�ϲ���̭�κ�key,�ڴ����˲�����д��������
