聚合函数(统计函数)
SQL 允许对表中的数据进行计算,将表中每一列数据作为一个整体,进行纵向计算。
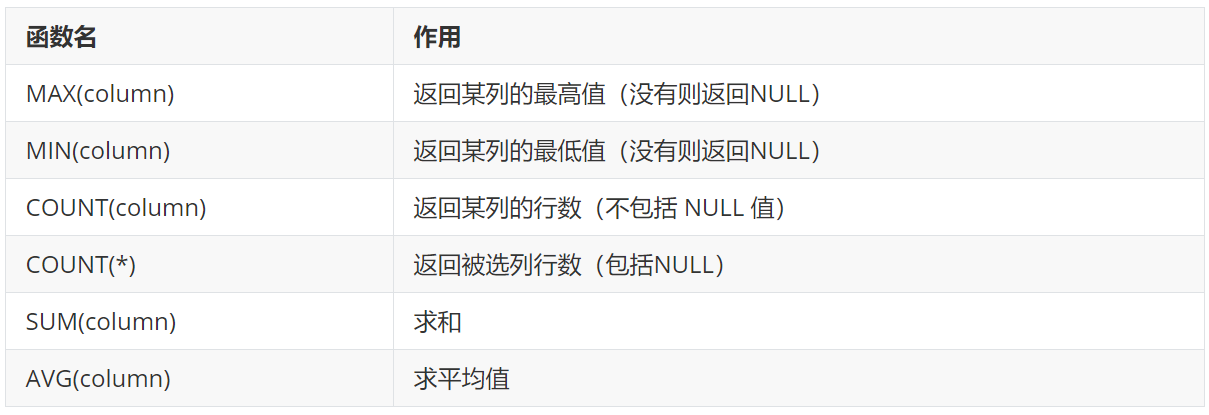
column 表示字段名,对某一字段进行某些操作
MAX、MIN、COUNT 不会对空值进行计算
COUNT(*) 返回所有列的行数,包含空值
其中 COUNT 函数可用于任何数据类型 (因为它只是记录行数),而 SUM 、AVG 函数都只能对数值类型做计算,MAX 和 MIN 可用于数值、字符串或是日期时间数据类型。
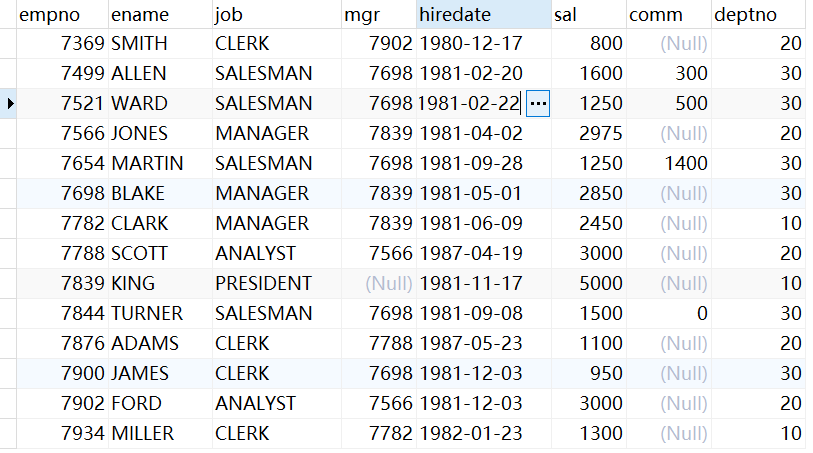
1.统计该企业员工数量?
SELECT COUNT(*) FROM emp;
注意 COUNT() 不会把空值计算在内
SELECT COUNT(mgr) FROM emp;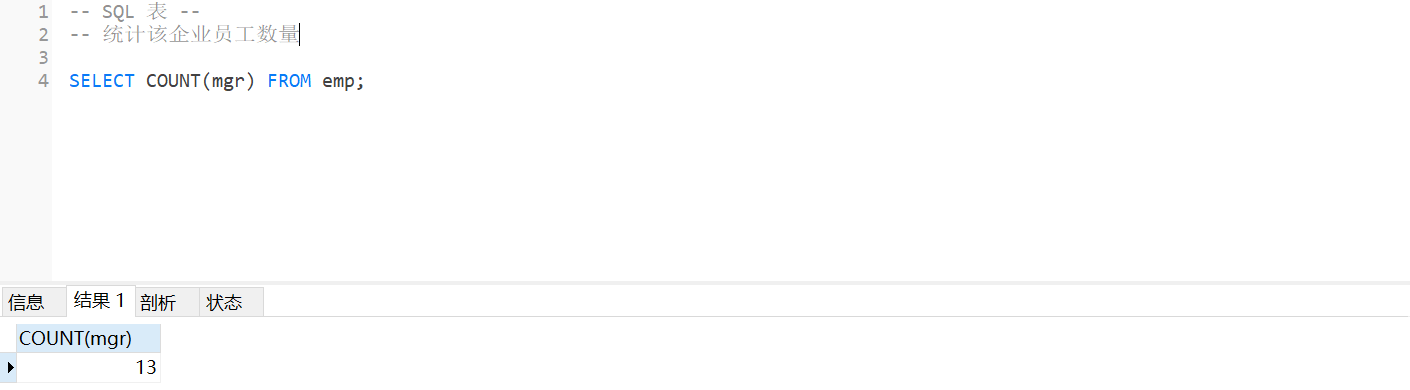
2.统计该企业员工的平均工资
SELECT AVG(sal) FROM emp;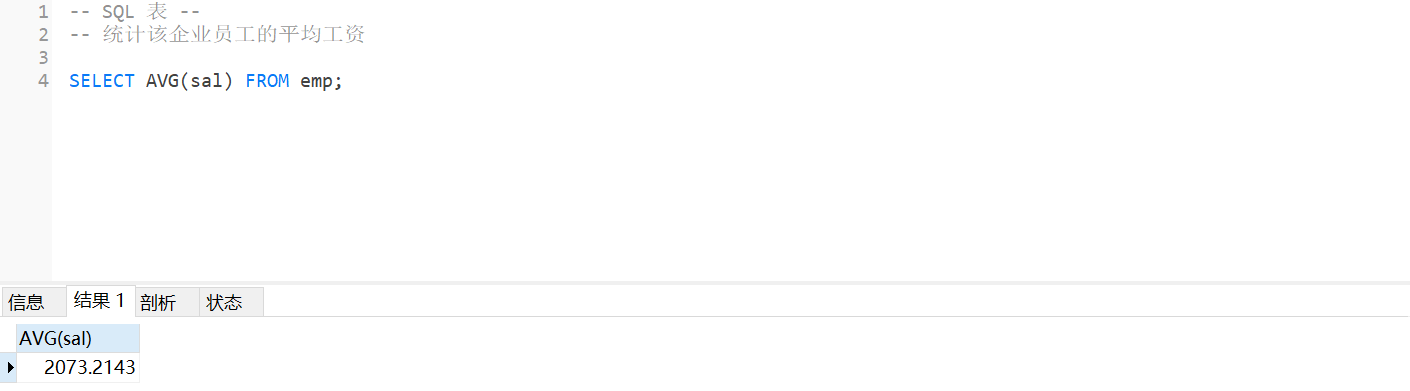
3.查询该企业员工的最高工资
SELECT MAX(sal) FROM emp;
4.查询该企业员工的最低工资
SELECT MIN(sal) FROM emp;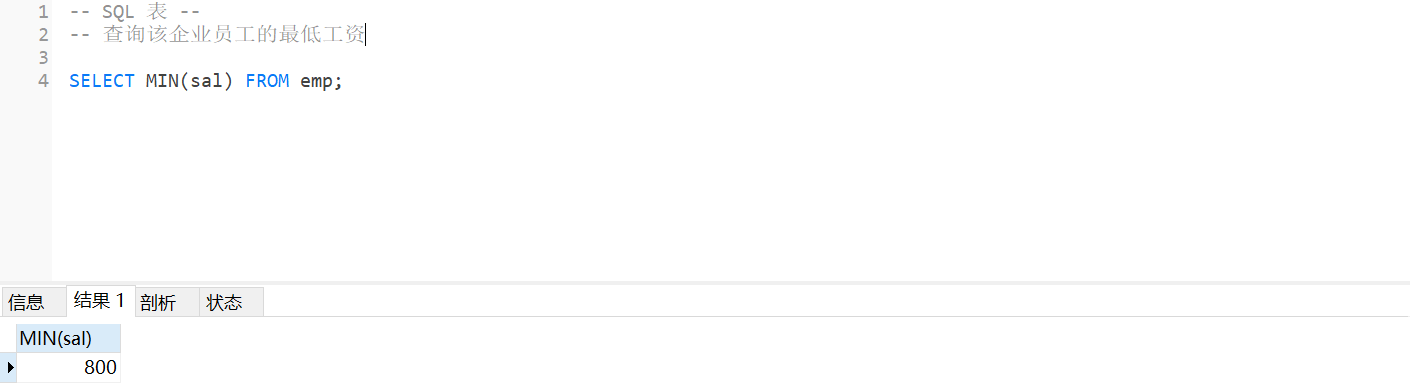
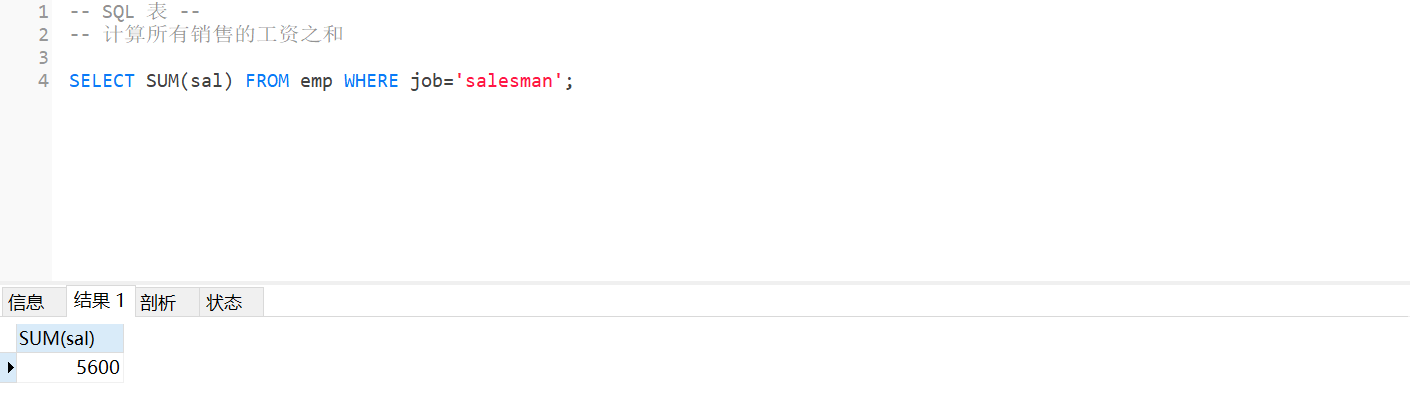
5.计算所有销售的工资之和
SELECT sal FROM emp WHERE job='salesman';
SELECT SUM(sal) FROM emp WHERE job='salesman';
分组查询
聚合函数实际上就是一些统计函数。
接下来我们来学习分组统计查询。
需要声明一点的是,虽然说统计函数一般是搭配分组查询,但是单独使用的情况一定是有的。例如:在做报表显示的时候基本的分页操作,一定要查询出全部的数据。
那么什么是分组呢?
分组这个概念在生活中其实是很常见的,比如有以下需求:
-
1.在一个班级之中,要求男女各一组进行辩论赛
-
2.在公司中,要求每个部门一组进行拔河比赛
对于第一个需求,假设存在学生表,那么在学生表之中一定会存在一个性别字段,性别只可能是男或者女。
而在公司之中,如果要进行部门分组,肯定需要一个部门列的内容存在重复。部门和员工是一对多的关系,一个部门对应多个员工。
分组只对数据有重复的字段才有意义,我们可以先查看 emp 表,找到可以分组的字段职位 job 和部门编号 deptno。
首先员工编号 empno 不能是重复的,如果重复了,就是同一个人,姓名 ename 一般也不会存在重复的
语法
GROUP BY 后面写上要对哪一个字段进行分组
HAVING 对分组之后对分组的数据进行筛选
WHERE 对分组之前的数据进行筛选
HAVING 对分组之后的数据进行筛选
SELECT 分组字段/聚合函数 FROM 表名 [WHERE 条件] GROUP BY 分组字段 [HAVING 分组后条件];查询需求
1.统计出每个工作岗位的人数,输出所有的工作岗位,然后对它进行分组,多个重复的算是一组里面,最后对每一组统计岗位里面有多少人
SELECT job,COUNT(*) FROM emp GROUP BY job;
2.统计出每种职位的最低和最高工资
-- 统计出每种职位
SELECT job FROM emp GROUP BY job;
SELECT job,MIN(sal),MAX(sal) FROM emp GROUP BY job;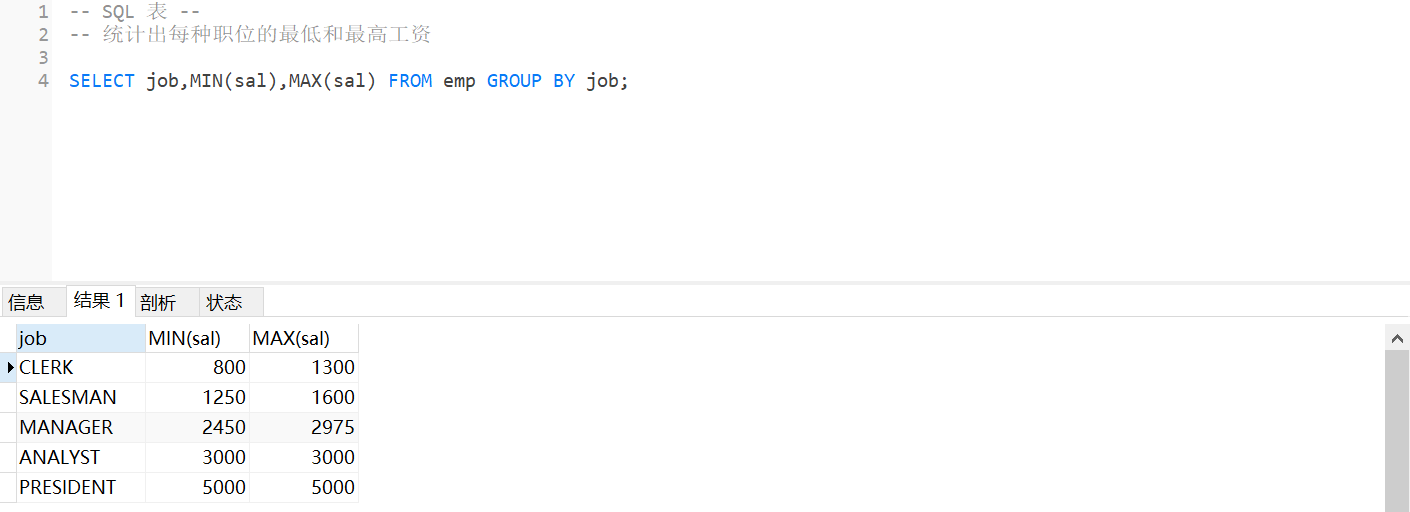
以上两个查询就实现了分组的基本操作,而且这些代码都按照标准格式进行了编写。可是在分组之中,个人认为最麻烦的地方就是在于分组操作的若干限制。
注意事项
1.如果一个查询之中(不存在GROUP BY子句),那么在SELECT子句之中只允许出现统计函数,其他任何字段都不允许出现。
有统计函数的时候,其他任何字段都不允许出现。
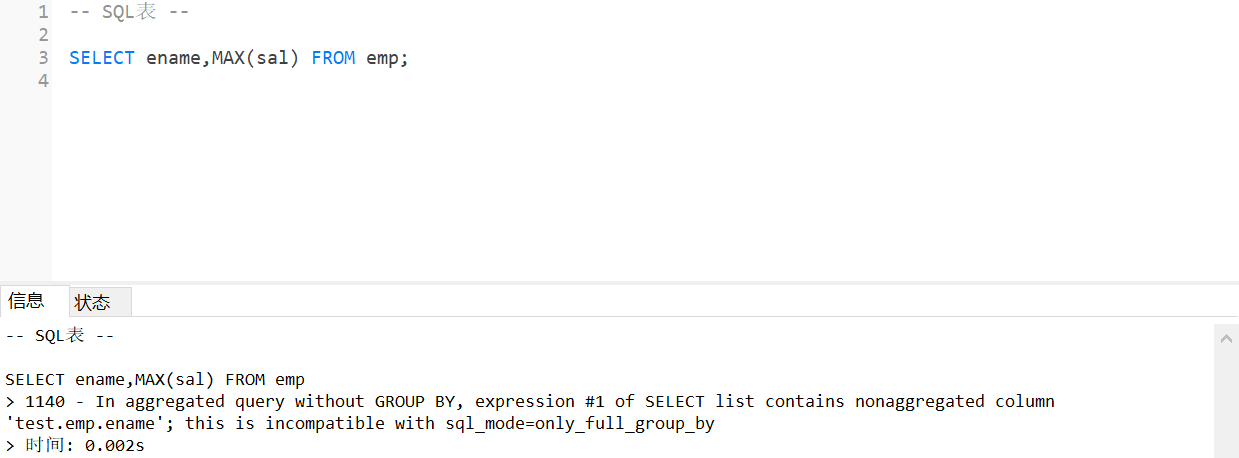
#错误的语句
SELECT ename,COUNT(job) FROM emp;
#正确的语句
SELECT COUNT(job) FROM emp;2.在统计查询之中(存在GROUP BY子句),SELECT子句之中只允许出现统计函数和分组字段(GROUP BY之后定义的字段),其他的任何字段都不允许出现。

#错误的语句
SELECT ename,COUNT(job) FROM emp GROUP BY job;
#正确的语句
SELECT deptno,COUNT(job) FROM emp GROUP BY job;在以后进行分组操作的时候,本着一个原则:GROUP BY子句之中允许出现的字段才是SELECT子句中允许出现的字段。
查询需求
1.显示不同职位薪资少于1500的人数
-- 显示不同职位
SELECT job FROM emp GROUP BY job;
-- 显示不同职位的人数
SELECT job,COUNT(*) FROM emp GROUP BY job;
-- 显示不同职位薪资少于1500的人数
SELECT job,COUNT(*) FROM emp WHERE sal<1500 GROUP BY job;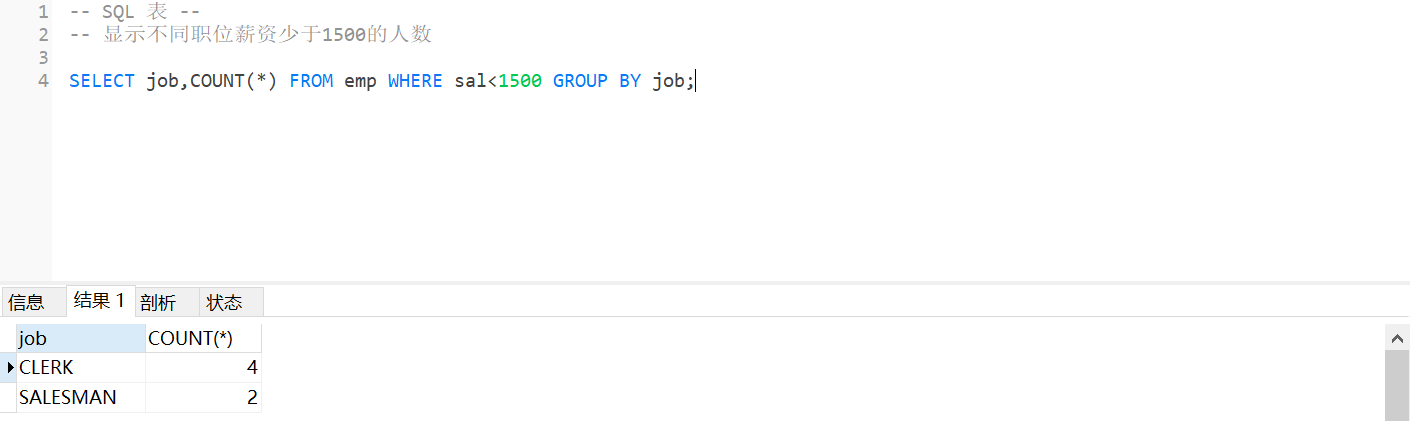
2.多加一个限制条件,只显示人数大于 2 的,其实就是第 1 题的结果再进行一个筛选
SELECT job,COUNT(*) FROM emp WHERE sal<1500 GROUP BY job HAVING COUNT(*)>2;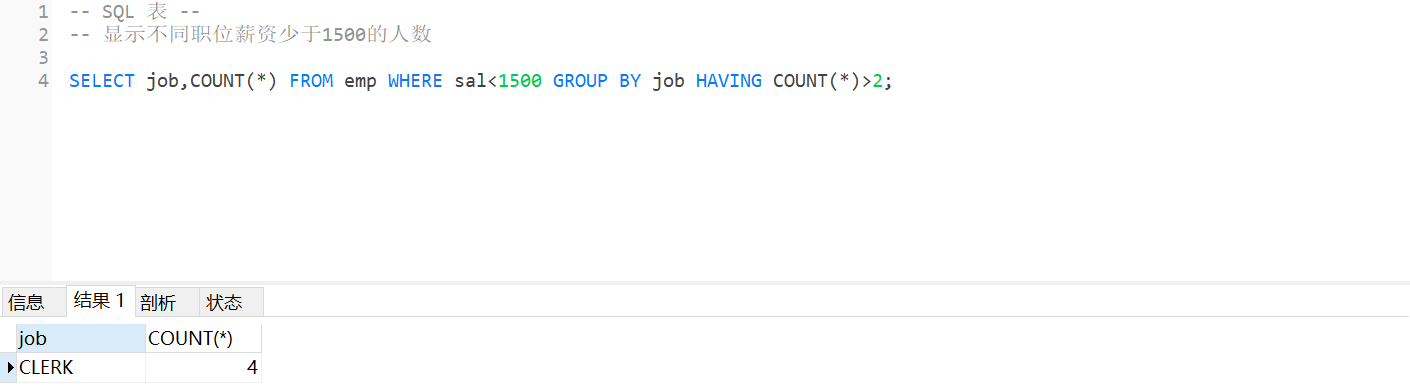
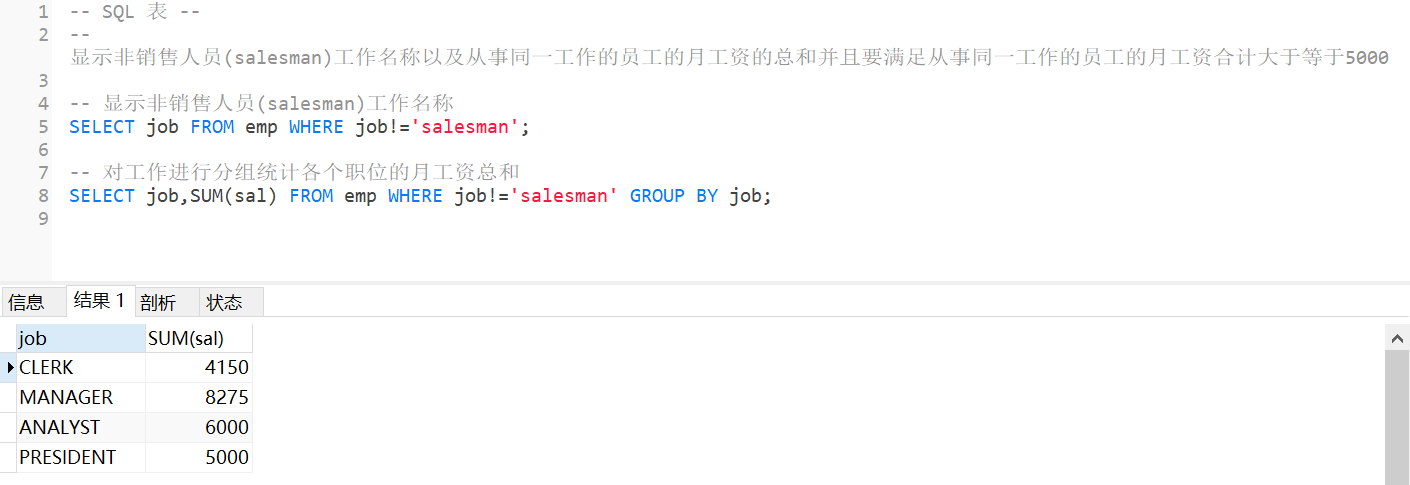
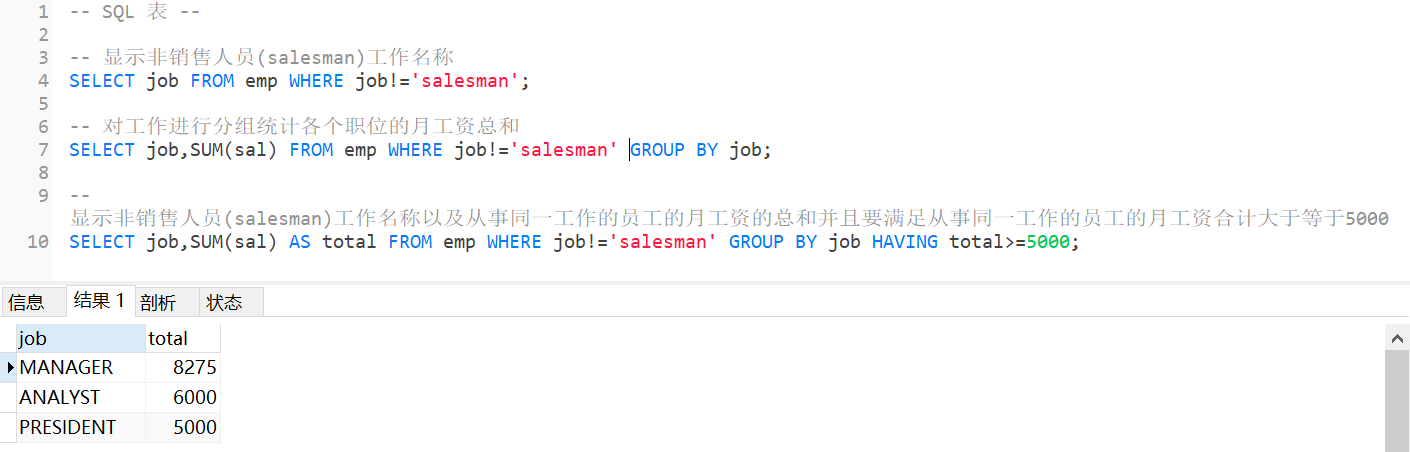
3.显示非销售人员(salesman)工作名称以及从事同一工作的员工的月工资的总和,并且要满足从事同一工作的员工的月工资合计大于等于5000
SELECT job FROM emp WHERE job!='salesman';
SELECT job,SUM(sal) FROM emp WHERE job!='salesman' GROUP BY job;
SELECT job,SUM(sal) AS total FROM emp WHERE job!='salesman' GROUP BY job HAVING total>=5000;

WHERE和HAVING区别
-
WHERE:是在分组之前使用(可以没有GROUP BY),不允许使用统计函数。
-
HAVING:是在分组之后使用(必须结合GROUP BY),允许使用统计函数。
?